







大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
Transformer变体
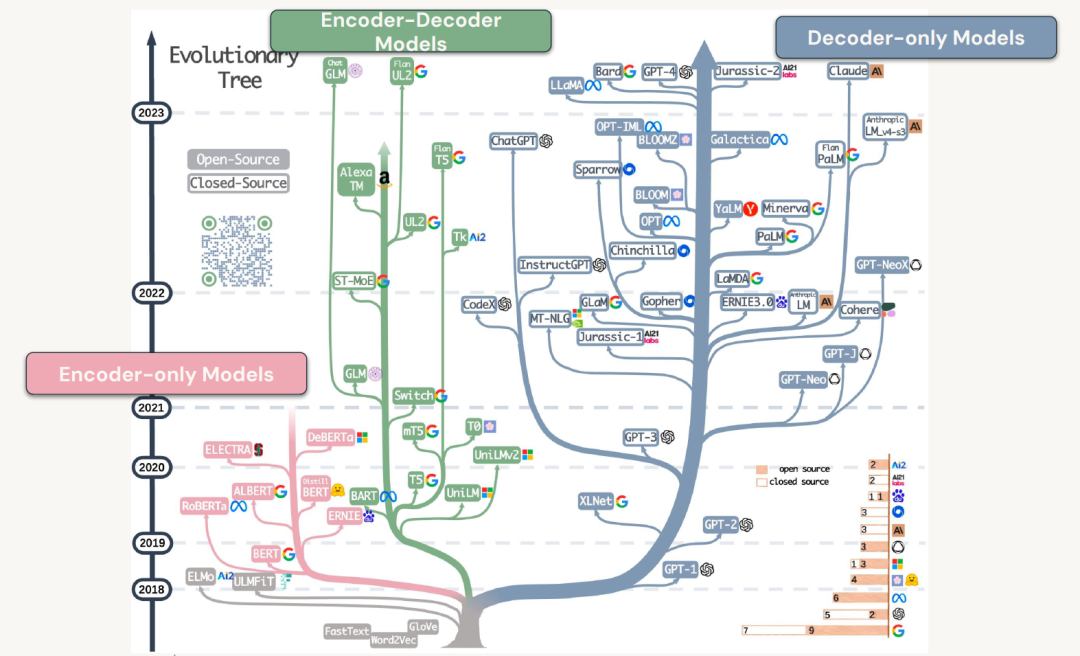
Encoder-Decoder 模型
Google在编码器-解码器模型领域的流行并非偶然。在最初的Transformer论文《Attention is all you need》中,Google的研究人员提出了一种基于编码器-解码器架构的方法,原因是他们想在英语和德语之间进行机器翻译。目标是输入一系列英语标记,并在最后输出翻译后的德语序列。他们实现这一目标的方法是采用一系列编码器块,因此这些将是我们到目前为止所看到的常规Transformer块,他们将放入英语标记,对其进行转换并按照我们所看到的方式准备它们。
Transformer块在处理完输入序列后,会生成一系列不同的向量,这些向量实际上是用于所谓的“交叉注意力”机制的。
简单来说,交叉注意力机制关注的是解码器部分在模型中如何利用这些向量来进行后续的处理。现在,这种方法的工作方式是,模型首先查看它作为解码器端生成的单词,然后当我们移动到需要交叉注意的点时,它会比较它所生成的单词在其Transformer块的中间,并从事物的编码器端查看交叉注意向量。我们将了解注意力如何获取这些不同类型的向量并将它们组合在一起,但是您可以将其视为编码器首先获取英语并将其实转换为某种丰富的向量,然后使用这些向量丰富向量并了解德语单词与要翻译的英语单词的关系。
因此,编码器-解码器模型通常采用一种类型的语言任务并将其转换为不同类型的语言。这可能是翻译或转换,也可能是介于两者之间的某种中间形式,例如从英语或某种自然语言获取输入并将其输出为代码语言,或者可能是一种编程语言到另一种编程语言。
总而言之,编码器解码器模型有许多不同的用例,它们基于交叉注意力的概念,稍后当我们讨论注意力时,我们将更深入地探讨什么是交叉注意力以及如何使用它机制详细。但本质上,编码器的作用是为解码器提供额外的信号源,以便解码器能够完成给定的任务,并且在反向传播期间,它学会依赖来自编码器的信号来完成其任务。
Encoder模型
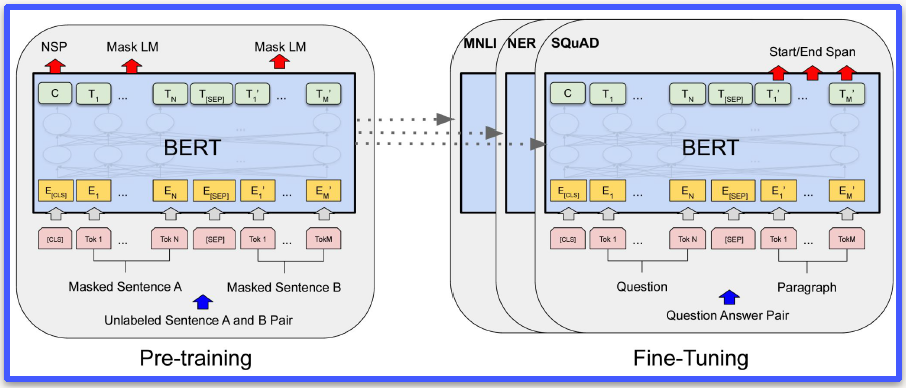
在最初的Transformer发布几年后,Google还生产了第二个Transformer架构,这就是Transformer或BERT的双向编码表示。
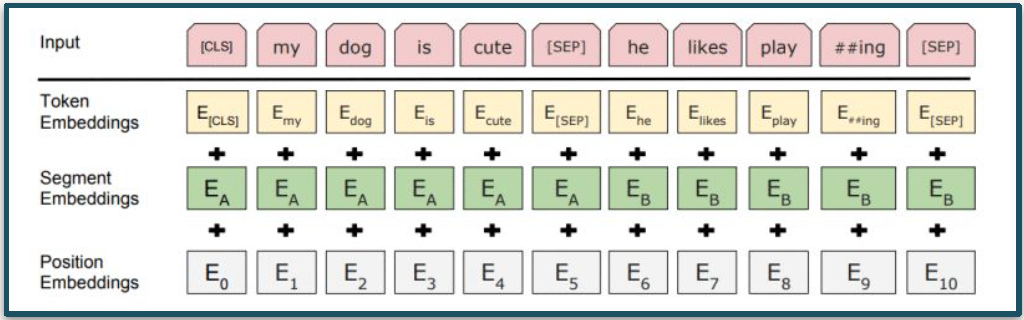
Bert发布了一些新的创新,其中之一是分段嵌入,因此您可以使用变量[SEP]将一个句子分开,然后放入第二个序列或第二个句子,Bert将能够比较两者。他们训练BERT的方式也不同,因为他们会故意将不同的单词掩盖[MASK]到句子中让模型学习空白的单词。

BERT在微调方面非常出色,并且已经被使用并且仍然主导着不同类型自然语言处理的许多最先进的技术。BERT非常适合问答、命名实体识别以及其他更传统的自然语言处理任务。BERT至今仍在使用,并且比我们通常在新闻中看到的一些较大模型要轻量得多。
Decoder 模型
最流行和最知名的版本是GPT。GPT全名是Generative Pre-training Transformer,顾名思义,这类Transformer可以生成新单词。您可能听说过“生成式人工智能”这个流行术语,而GPT就是这个流行词的由来。仅解码器模型的整体目标是尝试根据当前正在处理的序列来预测下一个单词。
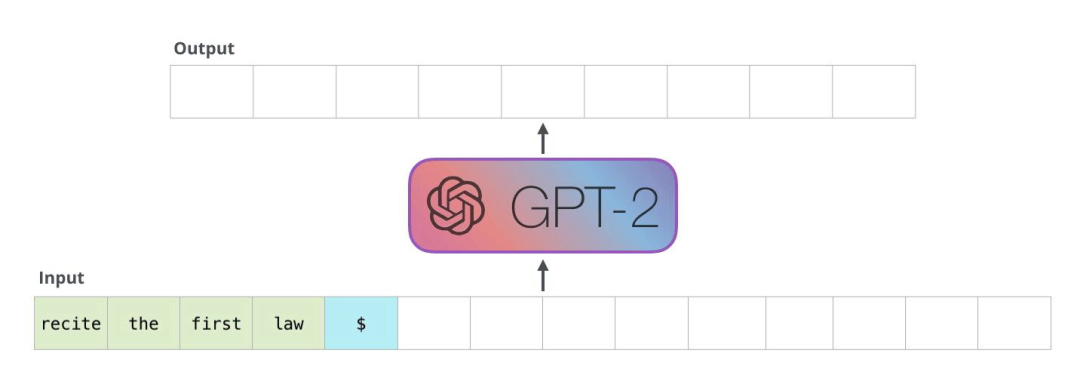
在GPT中,它将吸收所有正在处理和丰富的向量,并使用Transformer块末尾的分类softmax层来尝试预测下一个标记或下一个单词。我们已经看到了大量基于这些GPT或基于解码器的模型的应用程序,您可能会熟悉ChatGPT、Bard、Claude、LLama、MPT等等。
关键变量
为了更好的继续后面的学习,请熟悉下面反复出现的关键变量,使得后面的阅读更加流畅。当碰到一个全新的模型,可以从下面表格的多个维度去解读。

词汇量:它指的是Transformer在训练过程中能够识别的不同标记的数量,这些标记组合起来就能形成新的单词。
模型大小:它是Transformer中的一个核心变量,它通常与模型的规模大小有关。在后续的内容中,我们会讨论到参数的数量,但在这里需要强调的是,嵌入的维度或者说模型的大小是决定模型参数数量的关键因素之一。因为Transformer内部的许多矩阵运算和神经网络的规模都直接依赖于模型或嵌入的维度大小。
序列或上下文的长度:它对运行Transformer所需的计算资源有着重大影响。我们可以看到,上下文长度已经从最初的GPT模型的512个标记,发展到了像Claude这样的新模型支持的数十万个标记。在深入了解模型的内部结构时,还需要关注注意力头的数量,这将在下一节中详细讨论。注意力头的数量是多注意力机制中的一个关键部分。
中间或内部前馈网络的大小:它与Transformer中的前馈神经网络的中间层或隐藏层紧密相关。这些前馈网络占据了Transformer中所有学习参数的大约66%。而层数的多少也同样重要,它决定了Transformer模型中包含的Transformer块的数量。
模型训练的批量大小:虽然Transformer本质上是一个深度学习模型,但你会发现在实际应用中有很多不同的情况。例如,在这类模型的训练中,一个epoch可能只包含一个批次,或者批量大小仅有一两个样本,这并不罕见。而且,Transformer模型训练时使用的tokens数量可以达到数百万、数十亿甚至数万亿,这在深度学习领域是前所未有的。















 1373
1373

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









