








大模型技术论文不断,每个月总会新增上千篇。本专栏精选论文重点解读,主题还是围绕着行业实践和工程量产。若在某个环节出现卡点,可以回到大模型必备腔调或者LLM背后的基础模型新阅读。而最新科技(Mamba,xLSTM,KAN)则提供了大模型领域最新技术跟踪。若对于具身智能感兴趣的请移步具身智能专栏。技术宅麻烦死磕AI架构设计。
近年来,Transformer 模型作为自然语言处理领域的重要里程碑,为语言建模等任务带来了显著的进展。然而,最近出现的诸如Mamba的状态空间模型SSM表现出了令人瞩目的潜力,尤其是在小到中等规模的情况下甚至在某些情况下表现出了超越 Transformer 的性能。
这些新型模型的出现为带来了全新的思路和可能性,通过对结构化半可分离矩阵的各种分解方法的理论研究,可以将状态空间模型SSM与注意力机制Attention的变种进行紧密关联,进而提出一种状态空间对偶SSD的理论框架。
状态空间对偶使得研究人员设计一种新的架构 (Mamba-2),其核心层是对 Mamba(选择性SSM)进行改进,速度提高了2-8倍,同时在语言建模方面能够保持对Transformers的压力。

概览
Mamba-2的关键点在于结构化状态空间对偶性,简称SSD。它主要涉及到如下的关键点:
-
SSD模型是一个特定的层,有点类似S4,、S5或者注意力层,它可以合并到深度神经网络中的某一层。
-
SSD框架是这个模型的通用推理框架
-
SSD算法是一种比以前的SSM系列更高效计算的算法(层),相对于S4 Layer和S5 Layer
我想读者应该要学会接受层这个概念,每个层里面封装了一段数据处理的逻辑。很多的深度的神经网络都是将一个一个的块(或者层)叠加和组合,产生很多奇妙的化学反应。
SSD最大的作用在于将SSM和各种注意力变体联系了起来。

SSD模型的矩阵A与多头SSM
先来看看Mamba-1的算法:
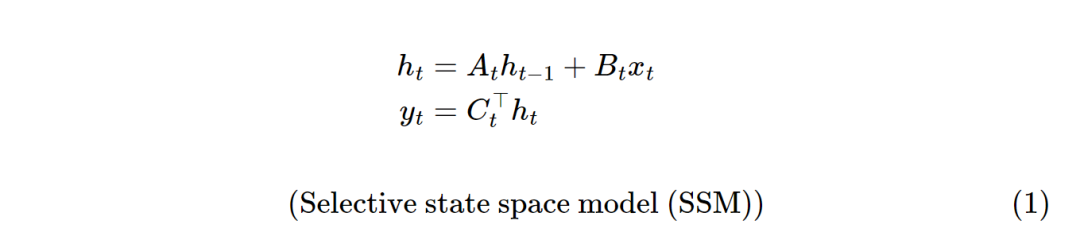
其中xt为t时刻的输入,yt为t时刻的输出。定义的 𝑥∈𝑅𝑇→𝑦∈𝑅𝑇映射。将 𝑥𝑡和𝑦𝑡视为标量,将隐藏状态ℎ𝑡视为𝑁长的一维向量,其中𝑁是一个独立的超参数,称为状态大小、状态维数或状态扩展因子。
选择性状态空间模型SSM允许 (𝐴,𝐵,𝐶)矩阵参数随时间变化,这里张量 𝐶的形状为𝐶∈𝑅(𝑇,𝑁),张量A的形状为𝐴∈𝑅(𝑇,𝑁,𝑁),张量B的形状为B∈𝑅(𝑇,𝑁)。<可以理解为T*N的矩阵>
为了让计算更加的高效,一般而言结构化SSM通常采用对角矩阵来构造𝐴 。在这种情况下的矩阵𝐴,其实只要存储𝑁×𝑁矩阵的对角线元素就可以了。那么𝐴可以简化为𝐴∈𝑅(𝑇,𝑁)。
Mamba-2的SSD层只做了一个小的修改:它将对角线矩阵𝐴进一步限制为“矩阵I乘以标量”,也就说矩阵𝐴的对角线元素必须都是相同的值,其余的元素都为0。在这种情况况下,可以只用𝑇表示,也可以识别为𝐴t。因为它是一个标量,所以也可以表示为at。
SSM的基本方程仅针对单维输入x∈RT 定义。若 X∈R(T,P) ,有P个单独的通道,那么就可以对每个通道使用相同的动态参数矩阵(ABC),这就是SSM单头模型的定义。P一般称之为头部的维度。
下面的图展示了SSM和Transformer的head的概念。左边每个维度都对应一个独立的SSM(p=1),而右边则是Transformer的多头注意力<忘记了可以温习一下!>
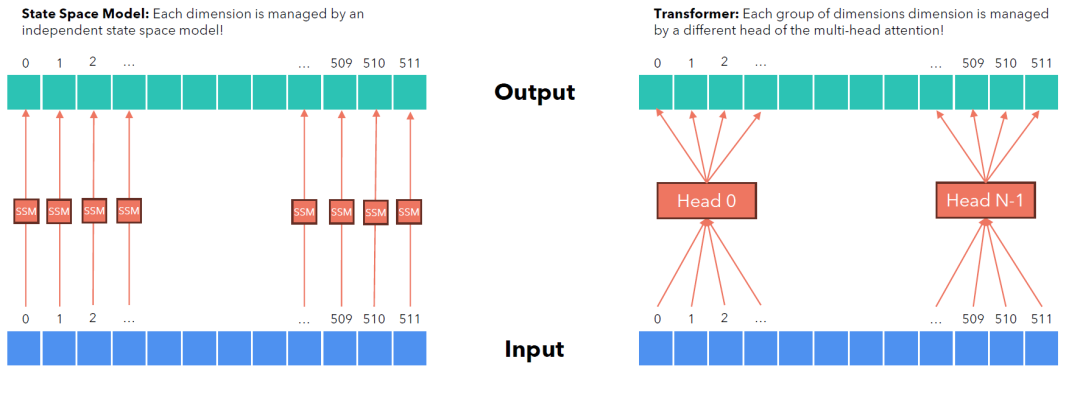
多个头完全可以独立构建,在研究论文中,它采用了一个单头来研究。其实扩展到多头也是一样的原理,在 Mamba-2,P的取值和Transformer保持一致,为64或者128。一个单头有P通道,按照这个尺寸可以扩展到d_model维度。
所以选择性的SSM模型可以用如下的式子表示:
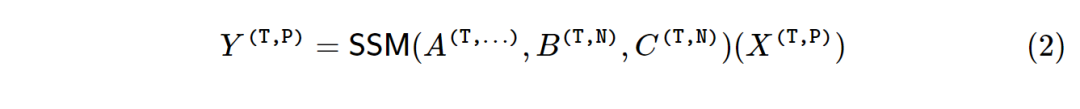
看过Mamba专栏的读者都会发现,矩阵A在不同的SSM有不同的构造方法, 从结构化、对角化到标量不断地进化着。

SSD模型
按照这个式子,再假设A为标量(I矩阵乘以一个标量),那么SSM怎么来表示呢。下来定义一个矩阵L,这里的ai为输入相关的标量

然后定义M为
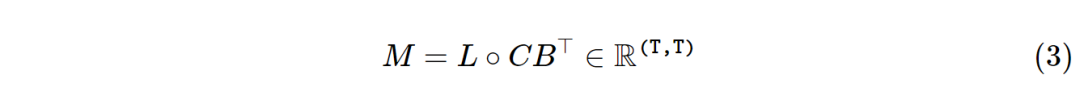
最后, M通过基本矩阵乘法对将一维输入映射到一维输出的序列变换进行编码。x∈RT→y∈RT ,或者说y=Mx,和之前式1是一样的。
对于式子三, 重命名(C,B,X)↦(Q,K,V),可以得到:
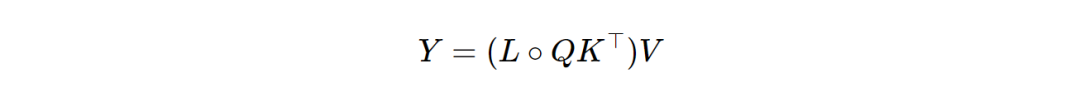
是不是很眼熟,这个公式和注意力机制很相似,事实上,如果全部at=1 ,那么L就是下三角形的因果掩码,公式三等价于因果注意力。<不熟悉的回头去温习下。>
那么SSD的这种构造方法如何成为SSM和Attention的桥梁呢?

SSD拉手SSM
所谓的“对偶性”Duality是指在方程中定义的两个模型,式1在对标量恒等式结构画At的情况下,实际上是式3完全相同的模型。
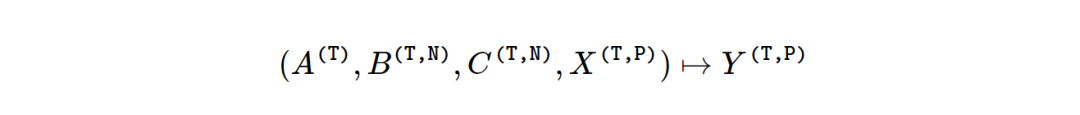
与以前的 SSM 相比,SSD与Mamba 的核心层几乎相同,但在循环A矩阵上具有更多的结构。
1) Mamba-1 S6在A上使用对角线结构,而Mamba-2 SSD在A上使用标量次恒等式结构。
2) Mamba-1的head尺寸为P=1,即所有通道完全由单独的SSM独立控制(见上图),而Mamba-2的head尺寸为P>1 ,默认情况下P=64。
3) 通过A限制标量-时间-恒等式的对角线结构,递归中的动态参数(SSM(ABC))在状态空间的所有的输入N元素之间共享,也在给定head的所有P 通道中共享。
换言之,单个SSM head具有总状态大小为P×N, 都由Mamba-1中的单独控制,而在Mamba-2中则由单个共享递归控制。
进行这些的主要动机还是在于效率。那么共享动态参数SSM(ABC)会不会对性能有所损伤。
在Mamba中引入选择性(例如A ,取决于输入X )的主要原因之一是让 SSM 能够控制是记住还是忽略特定信息。若这些信息应该被忽略,那么整个状态可以一起忽略它。因此,若动态参数SSM(ABC)在所有功能之间共享,应该也不是不可以,不过还需要观察。

SSD拉手注意力机制
与标准注意力机制相比,SSD也只有两个区别,其一,softmax 规范化被丢弃。其二,在乘法中使用了单独的元素掩码矩阵。第一个差异其实在线性RNN已经解释过了。<可以链接回去温习!>
第二个区别是 SSD 与标准线性注意力的区别:
刚才推导的式子中多出来一个掩码矩阵L,导致标准注意力分数〈Qi,Kj〉会因权重的问题而减弱。
毕竟:
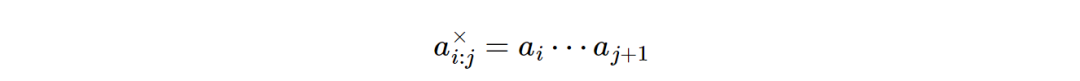
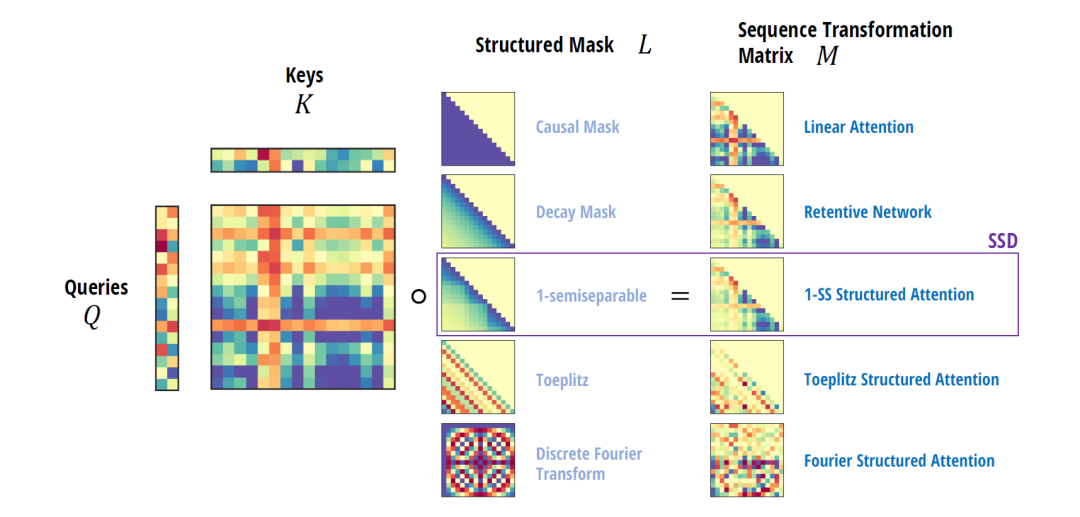
不过通过不同的掩码矩阵L,利用Structured Masked Attention(SMA)。如下图所示,可以构造出很多经典的注意力。
在继续下篇之前,建议读者回去温习下Mamba,然后再继续攀登Mamba-2。















 1792
1792











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









