







机器学习模型的复杂性和规模不断增长,分布式训练变得比以往任何时候都更加重要。训练具有数千亿参数的大型语言模型( LLMs )将是机器学习基础设施面临的挑战。与传统的分布式计算框架不同的地方在于GPU的分布式训练需要将数据传递给GPU芯片等物理硬件层。GPU设备之间会进行频繁、大规模的数据交换以进行高效训练,今天将揭开分布式训练的神秘面纱。
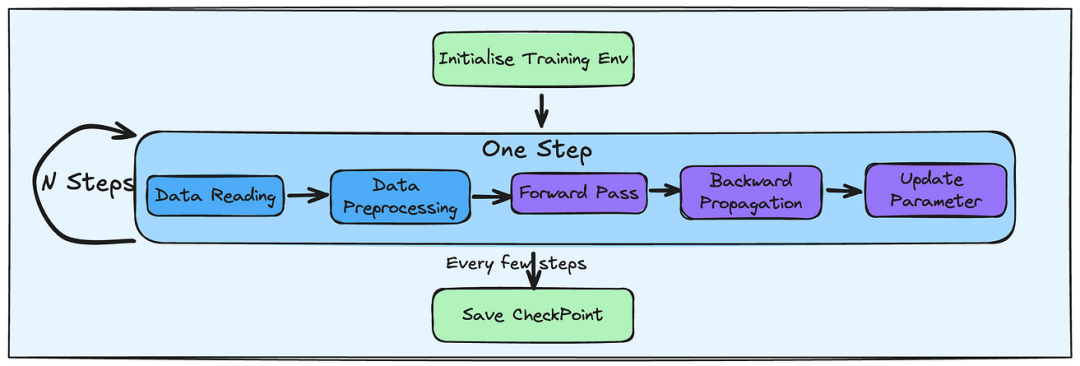
上图为基本的机器学习训练框架,数据准备占据1/3,训练占据1/3,将中间版本进行保存以及调整参数占据1/3。在模型的训练过程中,若读者拥有多片GPU,那么如何让这些GPU同时工作,目前有数据并行,模型并行以及管道并行。

数据并行
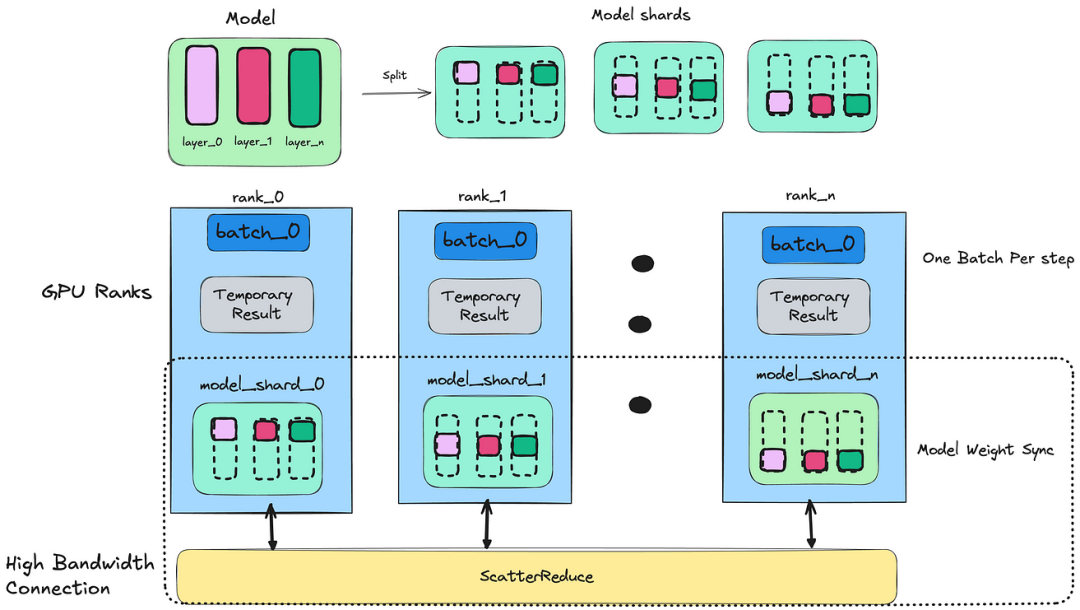
数据并行是跨多个 GPU 扩展模型训练最常用的方法之一。在这种方法中,每个GPU设备都需要存储全尺寸模型并处理不同批次的训练数据。除了存储模型和训练数据之外,每个GPU设备还保存临时结果,其中包括前向传播输出和梯度下降结果。
每个副本完成前向传递阶段后, NCCL All Reduce<白话ZeRO>会跨GPU节点同步模型参数,确保模型更新就像单个节点处理过所有批次数据。
ZeRO数据并行<白话ZeRO>是对传统数据并行的增强,旨在减少 GPU内存使用。与每个GPU存储完整模型不同,ZeRO跨GPU分割模型参数。这种方法仍然是数据并行的一种形式,因为每一层的张量计算不会跨GPU分割。GPU负责持久化模型分片,并可以在完成必要的计算后丢弃它们。
这种方法显着减少了内存消耗,使得可以在相同的硬件上训练更大的模型。PyTorch 提供完全分片数据并行 ( FSDP ),它将模型参数、优化器状态和跨分布式数据并行 ( DDP ) 等级的梯度进行分片,因此进一步减少内存消耗。

模型并行
数据并行简单直接,同时可以将训练分布在多GPU。特别大的模型而言,即便仅仅加载大型模型的单层也会对GPU的内存带来很大的压力。
在单GPU上训练模型时,若模型超过GPU内存,则训练过程中需要频繁地通过HostToDevice操作在主机内存和GPU内存之间不断地交换模型参数。这种频繁的I/O操作会导致GPU空闲,从而拖累了整个训练过程。
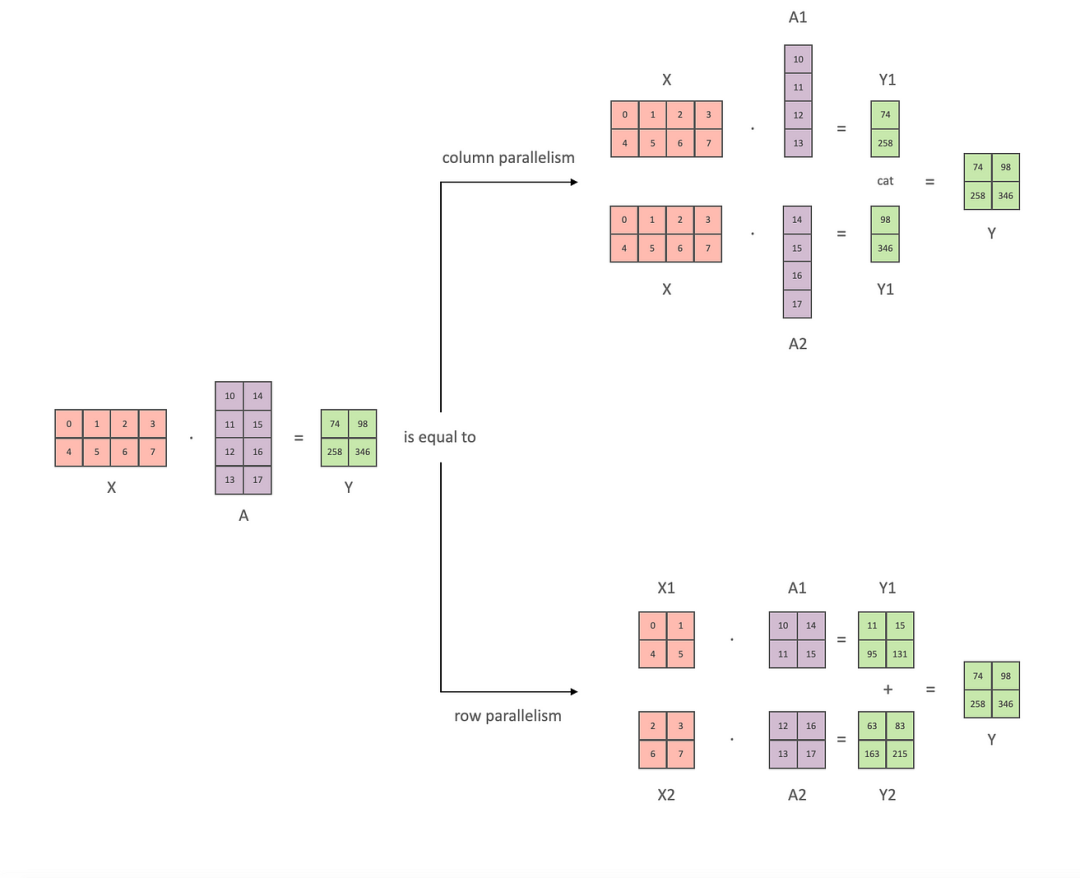
张量并行是模型并行的一种,模型参数被分割到多个GPU,从而实现并行计算。模型参数具备矩阵运算特点,可以切分按行或按列划分,允许每个 GPU独立执行乘法操作。最终通过将不同的GPU计算的子结果合并就可以得到最终的运算结果,也可以充分的利用所有的GPU设备。下图很直观的展示将矩阵分割,两路并行计算。

管道并行
除了数据并行和张量并行之外,管道并行可以进一步提高训练期间的GPU利用率。在管道并行性中,模型根据其层被分为块,允许前向传播和后向传播分布在不同的GPU上。这种方法可能会导致GPU出现空闲等待时间。
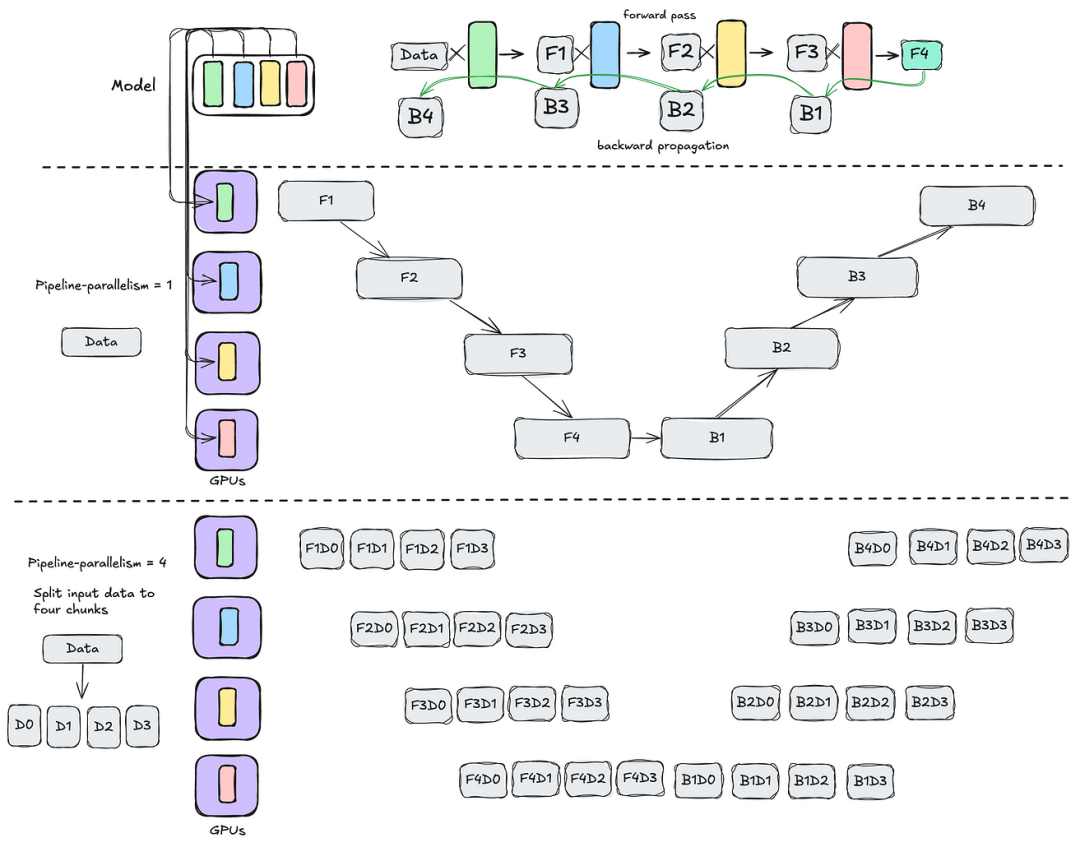
若模型足够小,单个GPU能够搞定,则可以使用数据并行将其扩展到多个节点。随着模型大小的增加,可能需要张量并行才能将模型分布到单个节点内的多个 GPU 上。如果模型变得更大,可以在同一节点内应用张量并行,而在不同节点之间使用管道并行。
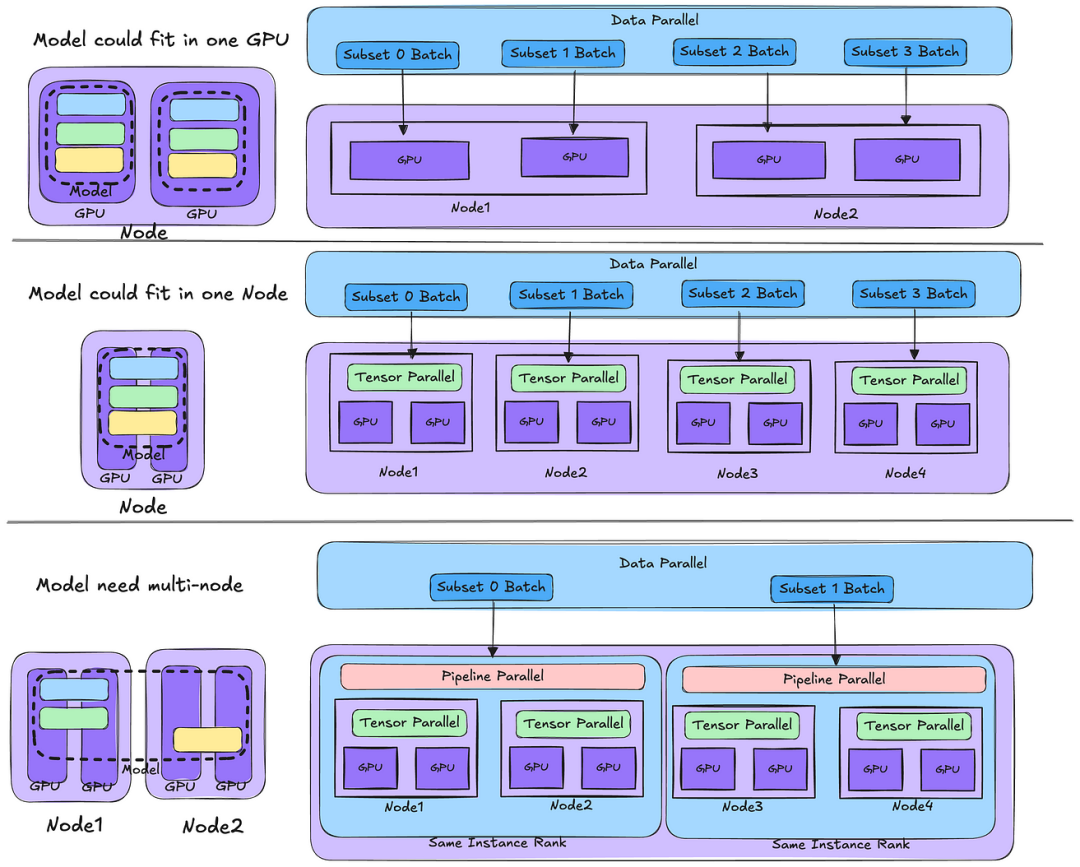
当然需要确保参与管道并行的节点位于同一网络等级内以实现最佳 I/O 性能至关重要。对于读者而言,小编建议先从数据并行入手,熟悉和感受下分布式训练方法。目前随着分布式计算越发的成熟,涌现出许多流行的训练框架,例如PyTorch Distributed Data Parallel ( DDP )、 DeepSpeed和Megatron-LM ,这些框架都提供并行方法的实现。















 956
956

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









