







文章目录
- 网络结构
1.1 Darknet-53网络结构
1.2 YOLOV3网络结构 - 输出特征图预测解码
2.1 Anchor
2.2 位置偏移
2.3 置信度:
2.4 类别预测- 训练策略与损失函数
3.1 训练策略
3.2 损失函数
3.2.1 目标定位损失
3.2.2 目标置信度损失
3.2.3 目标分类损失
- 训练策略与损失函数
- 实战流程
4.1 数据准备——COCO2014目标检测数据集
4.2train.py
4.3 数据读取
4.4 模型定义
4.5 NMS非极大值抑制(Non-Maximum Suppression)
4.5.1 Hard-NMS
4.5.2 Merge-NMS
4.5.3 Merge-NMS in YOLOV3
参考:
论文地址:https://arxiv.org/abs/1804.02767
文章代码地址:https://github.com/eriklindernoren/PyTorch-YOLOv3
项目二:血细胞的目标检测:https://download.csdn.net/download/Jason_Honey2/42551830
1. 网络结构
1.1 Darknet-53网络结构
YOLOV3采用Darknet-53作为网络backbone,因为网络中有53个convolutional layers,所以叫做Darknet-53 (2 + 1 ∗ 2 + 1 + 2 ∗ 2 + 1 + 8 ∗ 2 + 1 + 8 ∗ 2 + 1 + 4 ∗ 2 + 1 = 53 2 + 12 + 1 + 22 + 1 + 82 + 1 + 82 + 1 + 42 + 1 = 532+1∗2+1+2∗2+1+8∗2+1+8∗2+1+4∗2+1=53) 按照顺序数,最后的Connected是全连接层也算卷积层,一共53个)。每个卷积层后都会跟一个BN层和一个LeakyReLU)层。下图按照输入尺寸为256256给出Darknet-53的结构图:

1.2 YOLOV3网络结构
yolov3在三个不同尺寸的特征图上进行目标预测,下图以输入尺寸为416*416为例,选取尺寸分别为52,26,13三个尺寸的特征图进行目标预测。


- 输出特征图预测解码
上面简单介绍了输出特征图255个通道的由来,这里再次详细介绍一下:
255 = 3 × ( 4 + 1 + 80 ) 255 =3 \times (4+1+80)
255=3×(4+1+80)
2.1 Anchor
每个输出分辨率均采用3种尺寸的默认anchor,如下图所示;

2.2 位置偏移

疑问:每个网格的默认anchor中心点以网格中心点还是网格左上角点?



3.2.2 目标置信度损失

3.2.3 目标分类损失

4. 实战流程
4.1 数据准备——COCO2014目标检测数据集
按照博客最上方代码地址中的README.md中教程下载并准备数据,最终形式如下:
1. images:
train2014
*.jpg val2014
*.jpg labels:
train2014
*.json val2014
*.json
紧接着依据教程生成训练和验证图片列表并存储为txt格式:
/Users/data/coco/images/val2014/COCO_val2014_000000000164.jpg
/Users/data/coco/images/val2014/COCO_val2014_000000000192.jpg
/Users/data/coco/images/val2014/COCO_val2014_000000000283.jpg
...
4.2 train.py
大多数训练代码一般包含六个模块:
参数配置
数据读取
模型定义与初始化(涵盖损失函数、优化器定义)
训练(包含net(img, target)、loss.backward())
验证(包含net(img, target)、NMS、评价指标)
checkpoint保存
以上六个模块中重点是数据读取与模型定义(损失函数)以及NMS和评价指标的理解。整个train.py如下所示:
from __future__ import division
from models import *
from utils.logger import *
from utils.utils import *
from utils.datasets import *
from utils.parse_config import *
from test import evaluate
from terminaltables import AsciiTable
import os
import sys
import time
import datetime
import argparse
import torch
from torch.utils.data import DataLoader
from torchvision import datasets
from torchvision import transforms
from torch.autograd import Variable
import torch.optim as optim
if __name__ == "__main__":
# -------------------- 参数配置 -------------------- #
parser = argparse.ArgumentParser()
parser.add_argument("--epochs", type=int, default=100, help="number of epochs")
parser.add_argument("--batch_size", type=int, default=16, help="size of each image batch")
parser.add_argument("--gradient_accumulations", type=int, default=2, help="number of gradient accums before step")
parser.add_argument("--model_def", type=str, default="config/yolov3.cfg", help="path to model definition file")
parser.add_argument("--data_config", type=str, default="config/coco.data", help="path to data config file")
parser.add_argument("--pretrained_weights", type=str, help="if specified starts from checkpoint model")
parser.add_argument("--n_cpu", type=int, default=8, help="number of cpu threads to use during batch generation")
parser.add_argument("--img_size", type=int, default=416, help="size of each image dimension")
parser.add_argument("--checkpoint_interval", type=int, default=1, help="interval between saving model weights")
parser.add_argument("--evaluation_interval", type=int, default=1, help="interval evaluations on validation set")
parser.add_argument("--compute_map", default=False, help="if True computes mAP every tenth batch")
parser.add_argument("--multiscale_training", default=True, help="allow for multi-scale training")
opt = parser.parse_args()
print(opt)
logger = Logger("logs")
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
os.makedirs("output", exist_ok=True)
os.makedirs("checkpoints", exist_ok=True)
# Get data configuration
data_config = parse_data_config(opt.data_config)
train_path = data_config["train"]
valid_path = data_config["valid"]
class_names = load_classes(data_config["names"])
# -------------------- 模型定义与初始化 -------------------- #
# Initiate model
model = Darknet(opt.model_def).to(device)
model.apply(weights_init_normal)
# If specified we start from checkpoint
if opt.pretrained_weights:
if opt.pretrained_weights.endswith(".pth"):
model.load_state_dict(torch.load(opt.pretrained_weights))
else:
model.load_darknet_weights(opt.pretrained_weights)
# -------------------- 数据加载 -------------------- #
# Get dataloader
dataset = ListDataset(train_path, augment=True, multiscale=opt.multiscale_training)
dataloader = torch.utils.data.DataLoader(
dataset,
batch_size=opt.batch_size,
shuffle=True,
num_workers=opt.n_cpu,
pin_memory=True,
collate_fn=dataset.collate_fn,
)
optimizer = torch.optim.Adam(model.parameters())
metrics = [
"grid_size",
"loss",
"x",
"y",
"w",
"h",
"conf",
"cls",
"cls_acc",
"recall50",
"recall75",
"precision",
"conf_obj",
"conf_noobj",
]
for epoch in range(opt.epochs):
# -------------------- 训练 -------------------- #
model.train()
start_time = time.time()
for batch_i, (_, imgs, targets) in enumerate(dataloader):
batches_done = len(dataloader) * epoch + batch_i
imgs = Variable(imgs.to(device))
targets = Variable(targets.to(device), requires_grad=False)
loss, outputs = model(imgs, targets)
loss.backward()
if batches_done % opt.gradient_accumulations:
# Accumulates gradient before each step
optimizer.step()
optimizer.zero_grad()
# ----------------
# Log progress
# ----------------
log_str = "\n---- [Epoch %d/%d, Batch %d/%d] ----\n" % (epoch, opt.epochs, batch_i, len(dataloader))
metric_table = [["Metrics", *[f"YOLO Layer {i}" for i in range(len(model.yolo_layers))]]]
# Log metrics at each YOLO layer
for i, metric in enumerate(metrics):
formats = {m: "%.6f" for m in metrics}
formats["grid_size"] = "%2d"
formats["cls_acc"] = "%.2f%%"
row_metrics = [formats[metric] % yolo.metrics.get(metric, 0) for yolo in model.yolo_layers]
metric_table += [[metric, *row_metrics]]
# Tensorboard logging
tensorboard_log = []
for j, yolo in enumerate(model.yolo_layers):
for name, metric in yolo.metrics.items():
if name != "grid_size":
tensorboard_log += [(f"{name}_{j+1}", metric)]
tensorboard_log += [("loss", loss.item())]
logger.list_of_scalars_summary(tensorboard_log, batches_done)
log_str += AsciiTable(metric_table).table
log_str += f"\nTotal loss {loss.item()}"
# Determine approximate time left for epoch
epoch_batches_left = len(dataloader) - (batch_i + 1)
time_left = datetime.timedelta(seconds=epoch_batches_left * (time.time() - start_time) / (batch_i + 1))
log_str += f"\n---- ETA {time_left}"
print(log_str)
model.seen += imgs.size(0)
# -------------------- 验证 -------------------- #
if epoch % opt.evaluation_interval == 0:
print("\n---- Evaluating Model ----")
# Evaluate the model on the validation set
precision, recall, AP, f1, ap_class = evaluate(
model,
path=valid_path,
iou_thres=0.5,
conf_thres=0.5,
nms_thres=0.5,
img_size=opt.img_size,
batch_size=8,
)
evaluation_metrics = [
("val_precision", precision.mean()),
("val_recall", recall.mean()),
("val_mAP", AP.mean()),
("val_f1", f1.mean()),
]
logger.list_of_scalars_summary(evaluation_metrics, epoch)
# Print class APs and mAP
ap_table = [["Index", "Class name", "AP"]]
for i, c in enumerate(ap_class):
ap_table += [[c, class_names[c], "%.5f" % AP[i]]]
print(AsciiTable(ap_table).table)
print(f"---- mAP {AP.mean()}")
# -------------------- checkpoint保存 -------------------- #
if epoch % opt.checkpoint_interval == 0:
torch.save(model.state_dict(), f"checkpoints/yolov3_ckpt_%d.pth" % epoch)
4.3 数据读取
下方的代码经过了详细注释,这里主要介绍一下经过数据加载的几个功能:
图片读取并转换为Tensor;
label读取并处理(只要图片经过了几何变化,label中的bbox也要相应的变化);
label的batch拼接,这里单独实现了collate_fn函数告诉dataloader把所有batch中的所有bbox拼接在一起;
多尺度训练,每隔10个batch就随机改变输入尺寸,因为是全卷积网络,支持不同尺寸的输出,但是同一batch内部还是要保持尺寸一致。
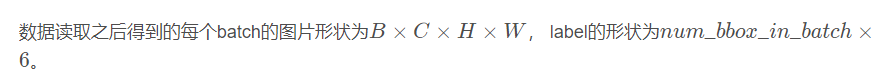
class ListDataset(Dataset):
def __init__(self, list_path, img_size=416, augment=True, multiscale=True, normalized_labels=True):
"""
:param list_path: 图片路径列表
:param img_size: 输入尺寸
:param augment: 是否采用数据扩充
:param multiscale: 多尺度训练
:param normalized_labels: label中定位参数均是归一化之后的值,此参数设置为True则按照图片尺寸对定为参数进行放缩。
"""
# 获取图片列表
with open(list_path, "r") as file:
self.img_files = file.readlines()
# 获取label列表
self.label_files = [
path.replace("images", "labels").replace(".png", ".txt").replace(".jpg", ".txt")
for path in self.img_files
]
self.img_size = img_size
self.max_objects = 100
self.augment = augment
self.multiscale = multiscale
self.normalized_labels = normalized_labels
self.min_size = self.img_size - 3 * 32
self.max_size = self.img_size + 3 * 32
self.batch_count = 0
def __getitem__(self, index):
# -------------------- image读取并处理 ------------------- #
img_path = self.img_files[index % len(self.img_files)].rstrip()
# Extract image as PyTorch tensor
img = transforms.ToTensor()(Image.open(img_path).convert('RGB'))
# Handle images with less than three channels
if len(img.shape) != 3:
img = img.unsqueeze(0)
img = img.expand((3, img.shape[1:]))
_, h, w = img.shape
h_factor, w_factor = (h, w) if self.normalized_labels else (1, 1) # h_factor, w_factor用来对label中的定位参数进行缩放
# Pad to square resolution
img, pad = pad_to_square(img, 0) # pad中存放图像上下左右填充的尺寸,这也要相应的拿来对label中的定位参数进行修改
_, padded_h, padded_w = img.shape
# -------------------- label读取并处理 ------------------- #
label_path = self.label_files[index % len(self.img_files)].rstrip()
targets = None
if os.path.exists(label_path):
boxes = torch.from_numpy(np.loadtxt(label_path).reshape(-1, 5))
# 45 0.479492 0.688771 0.955609 0.595500
# 类别编号、中心点x坐标、中心点y坐标,矩形框宽度和矩形框高度(矩形框坐标为归一化之后的信息)
# Extract coordinates for unpadded + unscaled image
x1 = w_factor * (boxes[:, 1] - boxes[:, 3] / 2) # 左上角x
y1 = h_factor * (boxes[:, 2] - boxes[:, 4] / 2) # 左上角y
x2 = w_factor * (boxes[:, 1] + boxes[:, 3] / 2) # 右下角x
y2 = h_factor * (boxes[:, 2] + boxes[:, 4] / 2) # 右下角y
# Adjust for added padding(pad之后的坐标)
x1 += pad[0]
y1 += pad[2]
x2 += pad[1]
y2 += pad[3]
# Returns (x, y, w, h) 到了这里,bbox的定位参数再次被转换为归一化的参数
boxes[:, 1] = ((x1 + x2) / 2) / padded_w
boxes[:, 2] = ((y1 + y2) / 2) / padded_h
boxes[:, 3] *= w_factor / padded_w
boxes[:, 4] *= h_factor / padded_h
# 这里bbox只占到5维,这里的6多出来的一个值用于标识batch_index
# 因为图片经过batch之后尺寸为(batch, c, h, w), 而同一batch不同图片的bbox数目可能不一致,导致无法拼接为(batch, num_bbox, 5)
# 所以直接多用一个维度存放batch_index,label就被处理成(num_bbox_in_batch, 6)
targets = torch.zeros((len(boxes), 6))
targets[:, 1:] = boxes
# Apply augmentations
if self.augment:
if np.random.random() < 0.5:
img, targets = horisontal_flip(img, targets) # 只包含水平翻转扩充
return img_path, img, targets
def collate_fn(self, batch):
paths, imgs, targets = list(zip(*batch))
# Remove empty placeholder targets
targets = [boxes for boxes in targets if boxes is not None]
# Add sample index to targets, 这里就是给6个维度第0维填充batch_index
for i, boxes in enumerate(targets):
boxes[:, 0] = i
targets = torch.cat(targets, 0)
# Selects new image size every tenth batch
# 每隔10个batch,改变输入图像尺寸,即多尺度训练
if self.multiscale and self.batch_count % 10 == 0:
self.img_size = random.choice(range(self.min_size, self.max_size + 1, 32))
# Resize images to input shape
imgs = torch.stack([resize(img, self.img_size) for img in imgs])
self.batch_count += 1
return paths, imgs, targets
def __len__(self):
return len(self.img_files)
4.4 模型定义
本YOLO代码使用配置文件来构建网络,即 cfg 配置文件一块块地描述了网络架构,然后读取该配置文件并解析,从而来搭建网络结构。这一块的代码就不做过多介绍,具体网络结构与1.2节中一样,搭积木就行。经过此网络之后,得到三个分辨率分支的特征输出,每个分支的输出尺寸为b a t c h × 255 × N × N batch \times 255 \times N \times Nbatch×255×N×N。
重点是接下来的YOLO Layer,其中主要实现以下几个功能:
依据网络预测的偏移量和放缩量修改默认anchor;
build_targets: 利用目标真值生成每个anchor(每个像素处3个)对应的置信度、类别、中心偏移量、宽高放缩量真值;
损失函数计算;
评价指标计算;
class YOLOLayer(nn.Module):
"""Detection layer"""
def __init__(self, anchors, num_classes, img_dim=416):
super(YOLOLayer, self).__init__()
self.anchors = anchors
self.num_anchors = len(anchors)
self.num_classes = num_classes
self.ignore_thres = 0.5
self.mse_loss = nn.MSELoss()
self.bce_loss = nn.BCELoss()
self.obj_scale = 1
self.noobj_scale = 100
self.metrics = {}
self.img_dim = img_dim
self.grid_size = 0 # grid size
def compute_grid_offsets(self, grid_size, cuda=True):
self.grid_size = grid_size # 输入特征图尺寸
g = self.grid_size
FloatTensor = torch.cuda.FloatTensor if cuda else torch.FloatTensor
self.stride = self.img_dim / self.grid_size # 输入图像尺寸/输入特征图尺寸=下采样步长
# grid_x, grid_y记录了当前特征图网格每个像素点的x,y坐标
self.grid_x = torch.arange(g).repeat(g, 1).view([1, 1, g, g]).type(FloatTensor)
self.grid_y = torch.arange(g).repeat(g, 1).t().view([1, 1, g, g]).type(FloatTensor)
# 将默认anchors的尺寸(相对于原图尺寸)放缩到当前特征图对应的尺寸
self.scaled_anchors = FloatTensor([(a_w / self.stride, a_h / self.stride) for a_w, a_h in self.anchors])
# 缩放后anchors的宽-高
self.anchor_w = self.scaled_anchors[:, 0:1].view((1, self.num_anchors, 1, 1))
self.anchor_h = self.scaled_anchors[:, 1:2].view((1, self.num_anchors, 1, 1))
def forward(self, x, targets=None, img_dim=None):
# Tensors for cuda support
FloatTensor = torch.cuda.FloatTensor if x.is_cuda else torch.FloatTensor
LongTensor = torch.cuda.LongTensor if x.is_cuda else torch.LongTensor
ByteTensor = torch.cuda.ByteTensor if x.is_cuda else torch.ByteTensor
self.img_dim = img_dim
num_samples = x.size(0)
grid_size = x.size(2)
prediction = (
x.view(num_samples, self.num_anchors, self.num_classes + 5, grid_size, grid_size)
.permute(0, 1, 3, 4, 2) # (batch, anchors=3, grid-size, grid-size, (x,y,w,h,conf)+80)
.contiguous()
)
# Get outputs
x = torch.sigmoid(prediction[..., 0]) # 对应2.2节图右侧公式中的sigmoid(t_x) (batch, anchors, width, height)
y = torch.sigmoid(prediction[..., 1]) # 对应2.2节图右侧公式中的sigmoid(t_y) (batch, anchors, width, height)
w = prediction[..., 2] # 对应2.2节图右侧公式中的 t_w (batch, anchors, width, height)
h = prediction[..., 3] # 对应2.2节图右侧公式中的 t_h (batch, anchors, width, height)
pred_conf = torch.sigmoid(prediction[..., 4]) # 对应2.3节中的sigmoid置信度解码 (batch, anchors, width, height)
pred_cls = torch.sigmoid(prediction[..., 5:]) # 对应2.4节中的sigmoid类别预测解码 (batch, anchors, width, height, 80)
# If grid size does not match current we compute new offsets
if grid_size != self.grid_size:
self.compute_grid_offsets(grid_size, cuda=x.is_cuda)
# Add offset and scale with anchors
pred_boxes = FloatTensor(prediction[..., :4].shape) # (batch, anchors, width, height, 4)
pred_boxes[..., 0] = x.data + self.grid_x # 相当于2.2节中图右侧(b_x) (batch, anchors, width, height)
pred_boxes[..., 1] = y.data + self.grid_y # 相当于2.2节中图右侧(b_y) (batch, anchors, width, height)
pred_boxes[..., 2] = torch.exp(w.data) * self.anchor_w # 相当于2.2节中图右侧(b_w) (batch, anchors, width, height)
pred_boxes[..., 3] = torch.exp(h.data) * self.anchor_h # 相当于2.2节中图右侧(b_h) (batch, anchors, width, height)
# (batch, anchors*width*height, 85) 中间三个维度被结合起来,代表整张图模型一共预测出了这么多anchors,每个anchor有85个预测值
output = torch.cat(
(
pred_boxes.view(num_samples, -1, 4) * self.stride, # 将预测anchor的尺寸重新放大到原图尺寸
pred_conf.view(num_samples, -1, 1),
pred_cls.view(num_samples, -1, self.num_classes),
),
-1)
# --------------------------------------------------------------- #
# 至此,已经得到了(预测框中心点x,y,预测框宽,高,预测框置信度,预测框类别) #
# 注意,网络实际预测的是anchors中心点x,y偏移量,anchors宽、高放缩量 #
# 上面的代码就是在默认anchors的基础上加上这些预测偏移量 #
# ------------------------------------------------------------- #
if targets is None:
return output, 0
else:
iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf = build_targets(
pred_boxes=pred_boxes,
pred_cls=pred_cls,
target=targets,
anchors=self.scaled_anchors,
ignore_thres=self.ignore_thres,
)
# Loss : Mask outputs to ignore non-existing objects (except with conf. loss)
loss_x = self.mse_loss(x[obj_mask], tx[obj_mask]) # 仅计算有目标的anchor的x偏移量损失
loss_y = self.mse_loss(y[obj_mask], ty[obj_mask]) # 仅计算有目标的anchor的y偏移量损失
loss_w = self.mse_loss(w[obj_mask], tw[obj_mask]) # 仅计算有目标的anchor的w放缩量损失
loss_h = self.mse_loss(h[obj_mask], th[obj_mask]) # 仅计算有目标的anchor的h放缩量损失
loss_conf_obj = self.bce_loss(pred_conf[obj_mask], tconf[obj_mask]) # 计算有目标的anchor的置信度损失
loss_conf_noobj = self.bce_loss(pred_conf[noobj_mask], tconf[noobj_mask]) # 计算无目标的anchor的置信度损失
# 两个置信度损失加权和,无目标anchor置信度损失权重大,表示希望模型能够非常自信预测出该anchor没有目标
loss_conf = self.obj_scale * loss_conf_obj + self.noobj_scale * loss_conf_noobj
loss_cls = self.bce_loss(pred_cls[obj_mask], tcls[obj_mask]) # 仅计算有目标的anchor的分类损失
total_loss = loss_x + loss_y + loss_w + loss_h + loss_conf + loss_cls
# Metrics
cls_acc = 100 * class_mask[obj_mask].mean() # 有目标区域的类别预测准确度
conf_obj = pred_conf[obj_mask].mean() # 有目标区域的置信度准确度
conf_noobj = pred_conf[noobj_mask].mean() # 无目标区域的置信度准确度
conf50 = (pred_conf > 0.5).float() # 置信度大于0.5的anchor值为1,小于0.5的anchor值为0
iou50 = (iou_scores > 0.5).float() # iou大于0.5的anchor值为1,小于0.5的anchor值为0
iou75 = (iou_scores > 0.75).float() # iou大于0.75的anchor值为1,小于0.75的anchor值为0
detected_mask = conf50 * class_mask * tconf # 当前anchor被检测到说明(1)当前anchor却有目标且预测置信度>0.5 (2)类别预测正确
# ----------------------------------------- #
# TP: IoU>0.5的检测框数量 #
# FP: IoU<=0.5的检测框 #
# FN: 没有检测到的GT的数量 #
# ---------------------------------------#
precision = torch.sum(iou50 * detected_mask) / (conf50.sum() + 1e-16) # Precision: TP / (TP + FP)
recall50 = torch.sum(iou50 * detected_mask) / (obj_mask.sum() + 1e-16) # Recall: TP / (TP + FN)
recall75 = torch.sum(iou75 * detected_mask) / (obj_mask.sum() + 1e-16) # Recall: TP / (TP + FN)
self.metrics = {
"loss": to_cpu(total_loss).item(),
"x": to_cpu(loss_x).item(),
"y": to_cpu(loss_y).item(),
"w": to_cpu(loss_w).item(),
"h": to_cpu(loss_h).item(),
"conf": to_cpu(loss_conf).item(),
"cls": to_cpu(loss_cls).item(),
"cls_acc": to_cpu(cls_acc).item(),
"recall50": to_cpu(recall50).item(),
"recall75": to_cpu(recall75).item(),
"precision": to_cpu(precision).item(),
"conf_obj": to_cpu(conf_obj).item(),
"conf_noobj": to_cpu(conf_noobj).item(),
"grid_size": grid_size,
}
return output, total_loss
build_targets
def build_targets(pred_boxes, pred_cls, target, anchors, ignore_thres):
"""
:param pred_boxes: (batch, anchors, width, height, 4)
:param pred_cls: (batch, anchors, width, height, 80)
:param target: (num_objects, 6(batch_index, class, x, y, w, h))
:param anchors: (3(anchors), 2(w, h))
:param ignore_thres: 0.5
"""
ByteTensor = torch.cuda.ByteTensor if pred_boxes.is_cuda else torch.ByteTensor
FloatTensor = torch.cuda.FloatTensor if pred_boxes.is_cuda else torch.FloatTensor
nB = pred_boxes.size(0) # batch
nA = pred_boxes.size(1) # anchors=3
nC = pred_cls.size(-1) # 类别数
nG = pred_boxes.size(2) # 当前特征图尺寸
# Output tensors
obj_mask = ByteTensor(nB, nA, nG, nG).fill_(0) # (batch, anchors, width, height)
noobj_mask = ByteTensor(nB, nA, nG, nG).fill_(1) # (batch, anchors, width, height)
class_mask = FloatTensor(nB, nA, nG, nG).fill_(0) # (batch, anchors, width, height)
iou_scores = FloatTensor(nB, nA, nG, nG).fill_(0) # (batch, anchors, width, height)
tx = FloatTensor(nB, nA, nG, nG).fill_(0) # (batch, anchors, width, height)
ty = FloatTensor(nB, nA, nG, nG).fill_(0) # (batch, anchors, width, height)
tw = FloatTensor(nB, nA, nG, nG).fill_(0) # (batch, anchors, width, height)
th = FloatTensor(nB, nA, nG, nG).fill_(0) # (batch, anchors, width, height)
tcls = FloatTensor(nB, nA, nG, nG, nC).fill_(0) # (batch, anchors, width, height, num_classes)
# Convert to position relative to box
target_boxes = target[:, 2:6] * nG # 目标anchor定位参数真值,并将其从归一化的值放大到当前特征图对应的尺寸 (num_objects, 4)
gxy = target_boxes[:, :2] # 目标anchor中心x,y真值 (num_objects, 2)
gwh = target_boxes[:, 2:] # 目标anchor宽、高真值 (num_objects, 2)
# Get anchors with best iou
ious = torch.stack([bbox_wh_iou(anchor, gwh) for anchor in anchors]) # 3个默认anchors与所有目标anchors真值的iou (3, num_objects)
best_ious, best_n = ious.max(0) # 获取3个默认anchor中与每个目标anchors最为匹配那个anchor的iou及其index (num_objects)
# Separate target values
b, target_labels = target[:, :2].long().t() # 当前目标anchor所属batch_index, 当前目标anchor所属类别
gx, gy = gxy.t() #
gw, gh = gwh.t()
gi, gj = gxy.long().t() # 目标anchor中心点向下取整,也就是获取目标anchor所属网格,由该网格预测该目标
# ------------------------ #
# b : (num_objects) #
# best_n : (num_objects) #
# gx : (num_objects) #
# gy : (num_objects) #
# gw : (num_objects) #
# gh : (num_objects) #
# gi : (num_objects) #
# gj : (num_objects) #
# ------------------------ #
# Set masks
obj_mask[b, best_n, gj, gi] = 1 # obj_mask填充, 该mask指示每个目标的位置
noobj_mask[b, best_n, gj, gi] = 0 # noobjmask填充,该mask指示没有目标的位置
# Set noobj mask to zero where iou exceeds ignore threshold
# 当默认anchor与目标anchor的iou大于指定阈值,则认为这里存在目标
for i, anchor_ious in enumerate(ious.t()):
noobj_mask[b[i], anchor_ious > ignore_thres, gj[i], gi[i]] = 0
# Coordinates
tx[b, best_n, gj, gi] = gx - gx.floor() # 3.2.1节中g^x的计算,即目标anchor与与之匹配的默认anchor的中心点x偏移量
ty[b, best_n, gj, gi] = gy - gy.floor() # 3.2.1节中g^y的计算,即目标anchor与与之匹配的默认anchor的中心点y偏移量
# Width and height
tw[b, best_n, gj, gi] = torch.log(gw / anchors[best_n][:, 0] + 1e-16) # 3.2.1节中g^w的计算,即目标anchor与与之匹配的默认anchor的宽度缩放值
th[b, best_n, gj, gi] = torch.log(gh / anchors[best_n][:, 1] + 1e-16) # 3.2.1节中g^h的计算,即目标anchor与与之匹配的默认anchor的高度缩放值
# One-hot encoding of label
tcls[b, best_n, gj, gi, target_labels] = 1 # 目标anchor的one-hot类别真值
# Compute label correctness and iou at best anchor
class_mask[b, best_n, gj, gi] = (pred_cls[b, best_n, gj, gi].argmax(-1) == target_labels).float() # 目标anchor对应的预测anchor是否预测正确
iou_scores[b, best_n, gj, gi] = bbox_iou(pred_boxes[b, best_n, gj, gi], target_boxes, x1y1x2y2=False) # 目标anchor与预测anchor的iou值
tconf = obj_mask.float() # 有目标的区域置信度为1,没有目标的区域置信度为0
return iou_scores, class_mask, obj_mask, noobj_mask, tx, ty, tw, th, tcls, tconf
4.5 NMS非极大值抑制(Non-Maximum Suppression)
目标检测的过程中在同一目标的位置上会产生大量的候选框,这些候选框相互之间可能会有重叠,此时我们需要利用非极大值抑制找到最佳的目标边界框,消除冗余的边界框。

4.5.1 Hard-NMS
最常见的NMS指的就是Hard-NMS,其流程如下:
根据置信度得分对anchor列表进行排序;
选择置信度最高的anchor添加到最终输出列表中(置信度最大认为其有目标的可能性就越大),将其从anchor列表中删除;
计算置信度最高的anchor与其它anchor的IoU;
删除IoU大于阈值的anchor(因为IoU较大,重叠较多,可能是同一目标,故而舍弃);
重复上述过程,直至anchor列表为空。
4.5.2 Merge-NMS
在Hard-NMS的基础上,增加位置平滑策略(重叠anchors位置信息求解加权平均值作为最终结果),使框的位置更加精确。
4.5.3 Merge-NMS in YOLOV3
def non_max_suppression(prediction, conf_thres=0.5, nms_thres=0.4):
"""
Removes detections with lower object confidence score than 'conf_thres' and performs
Non-Maximum Suppression to further filter detections.
prediction: shape (B, anchors, 85)
Returns detections with shape:
(x1, y1, x2, y2, object_conf, class_score, class_pred)
"""
# From (center x, center y, width, height) to (x1, y1, x2, y2)
prediction[..., :4] = xywh2xyxy(prediction[..., :4])
output = [None for _ in range(len(prediction))]
for image_i, image_pred in enumerate(prediction):
# Filter out confidence scores below threshold
image_pred = image_pred[image_pred[:, 4] >= conf_thres]
# If none are remaining => process next image
if not image_pred.size(0):
continue
# Object confidence times class confidence
score = image_pred[:, 4] * image_pred[:, 5:].max(1)[0]
# Sort by it
image_pred = image_pred[(-score).argsort()]
class_confs, class_preds = image_pred[:, 5:].max(1, keepdim=True)
detections = torch.cat((image_pred[:, :5], class_confs.float(), class_preds.float()), 1)
# Perform non-maximum suppression
keep_boxes = []
while detections.size(0):
large_overlap = bbox_iou(detections[0, :4].unsqueeze(0), detections[:, :4]) > nms_thres
label_match = detections[0, -1] == detections[:, -1]
# Indices of boxes with lower confidence scores, large IOUs and matching labels
invalid = large_overlap & label_match
weights = detections[invalid, 4:5]
# Merge overlapping bboxes by order of confidence
detections[0, :4] = (weights * detections[invalid, :4]).sum(0) / weights.sum()
keep_boxes += [detections[0]]
detections = detections[~invalid]
if keep_boxes:
output[image_i] = torch.stack(keep_boxes)
return output
参考:
https://zhuanlan.zhihu.com/p/76802514
https://blog.csdn.net/qq_37541097/article/details/81214953
https://blog.csdn.net/qq_33270279/article/details/103721790















 6443
6443











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









