







YOLOv3&v4目标检测算法详解及预训练模型使用与自己训练模型
一、YOLO简介
YOLO是目前比较流行的目标检测算法,结构简单但是功能强大。有了它,你就能成功检测出许多目标物体。本文主要介绍YOLO v3和v4及其模型使用方法,下面给出源码地址:
GitHub地址链接:https://github.com/AlexeyAB/darknet
YOLO官网:https://pjreddie.com/darknet/yolo/
更详细的内容请看原论文:
[1] Joseph Redmon, Ali Farhadi. YOLOv3: An Incremental Improvement.
[2] Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao. YOLOv4: Optimal Speed and Accuracy of Object Detection.

二、YOLO v3
**YOLO(You only look once)**是目前比较流行的实时目标检测算法,结构简单但是功能强大。YOLO v3以v1和v2为基础做出了一些改进,主要有:网络结构调整为53个卷积层,称为darknet-53;利用多尺度特征进行对象检测;对象分类使用logistics回归等。
YOLO3借鉴了残差网络结构,形成更深的网络层次,以及多尺度检测,提升了mAP及小物体检测效果。如果采用COCO mAP50做评估指标,YOLO3的表现相当惊人,如下图所示,在精确度相当的情况下,YOLOv3的速度是其它模型的3、4倍。

三、YOLO v4
YOLO v4在v3的基础上又有了大量的改进,包括:提出了一种高效而强大的目标检测模型;验证了SOTA的Bag-of Freebies 和Bag-of-Specials方法的影响;改进了SOTA的方法,使它们更有效,更适合单GPU训练等。
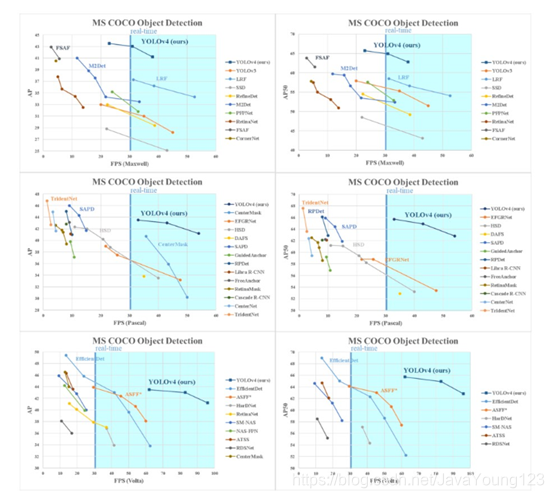
与众多目标检测算法比较起来,YOLO v4在速度和准确性方面都有很好的优势,如下图所示:
四、预训练模型使用(基于Darknet的GPU版本)
通过GPU运行有许多的优势,所以这里只介绍基于Darknet框架的GPU版本的方法,请小伙伴们自行安装好CUDA和cuDNN。darknet在深度学习方面有许多优势,包括:
(1)darknet完全由C语言实现,没有任何依赖项,而且可以使用OpenCV,但只是用其来显示图片、为了更好的可视化。
(2)darknet支持CPU和GPU,使用GPU计算效果更佳,速度更快。
如果是检测视频,那么还需要安装好OpenCV。
我的配置:Win10+CUDA10.1+cuDNN7.6.4+OpenCV3.4.1
1.下载项目
请点击这里进入Github下载项目
2.在Windows 10上通过Visual Studio 2017编译
①找到并打开darknet.vcxproj,将里面两处含有**“CUDA”片段的代码改成相应的版本,我改为10.1**。(如果你的CUDA版本不是10.1,那么请改成对应的版本)
②打开darknet.sln,选择文件属性,删除CUDA C/C++中的;compute_75,sm_75。
③在visual studio 2017中编译环境设置为Release x64,然后点击“生成”按钮。编译成功的话,在x64文件夹中就会出现darknet.exe文件。
3.使用Command命令行运行
使用基于darknet框架的YOLO算法预训练模型(基于COCO训练集训练得到),需要配置weights文件和cfg文件。在实验中,我使用的是YOLO v3和YOLO v4算法,所以需要下载好yolov3.weights和yolov4.weights文件并放在x64文件夹下。(weights文件在GitHub上可以下载)
①检测视频:使用command命令打开\build\darknet\x64文件夹,输入命令darknet.exe detector demo cfg/coco.data cfg/yolov4.cfg yolov4.weights test.mp4 -out_filename res.avi即可对视频进行目标检测并保存结果。将命令中的yolov4换成yolov3即可使用yolov3的模型。
②检测图像:输入命令darknet.exe detector test cfg/coco.data cfg/yolov4.cfg yolov4.weights dog.jpg -thresh 0.25。如果使用的是v3,将v4改成v3即可。保存检测结果:darknet.exe detector test cfg/coco.data yolov4.cfg yolov4.weights -ext_output dog.jpg
下面是v3检测结果:

v4检测结果:

对比可以发现,v4比v3支持更多的目标种类,准确率也更高
五、自己训练模型(使用GPU)
我使用的数据集是PASCAL VOC 2007 training dataset中挑选的39张图像,基于YOLO v4算法的预训练模型训练了自己的模型。主要步骤如下:
**①在YOLO v4预训练模型的基础上,修改相关参数。**在yolo-obj.cfg中,根据自己训练模型的需要,修改batch、subdivisions、max_batches、steps、width、height、classes、filters 等参数的值。在我训练的模型中,目标检测的种类设定为car和person两类,所以classes=2,filter=21。
**②选定自己的数据集,并对目标进行标记。**我选择PASCAL VOC 2007 training dataset中39张含有car和person的图像作为自己的数据集。然后,用YOLO mark对图像中的目标(car和person)进行标记,在图像对应的txt文件中生成目标的class、x_center、y_center、width和height。
**③训练模型。**用command命令行输入darknet.exe detector train data/obj.data yolo-obj.cfg yolov4.conv.137命令,将会开始自动训练模型。整一个训练过程是在GPU上进行的,可以加快计算速度。迭代次数设置为6000次,每迭代1000次会保存一次训练结果,在迭代计算6000次后训练结束。
**④测试模型。**训练结束后,使用生成的权重文件测试图像。输入命令darknet.exe detector test data/obj.data yolo-obj.cfg yolo-obj_1000.weights进行测试。
训练的时间取决于电脑的性能,随缘吧~
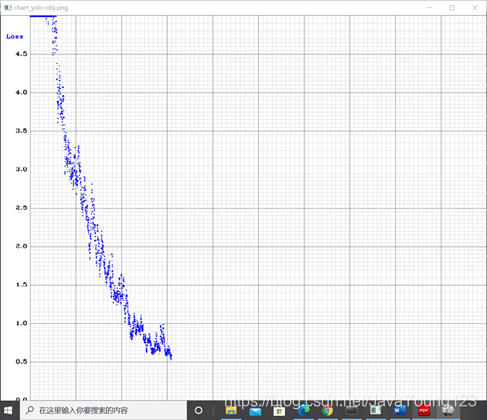
这是我的损失函数,迭代了2000次:
由于我只设置了person和car两类目标,所以只能检测出人和车。下面是迭代2000次的测试结果:

改进训练方法:
①增加迭代次数。迭代次数通常等于classes(检测种类)*2000,但最少不应该少于6000。适当的增加迭代次数可以改进模型,但是同时要防止过拟合。
②增加训练集数量。检测的每个对象-训练数据集中必须至少有一个相似的对象,它们具有大致相同的形状:形状,对象的侧面,相对大小,旋转角度,倾斜度,照明度。最好是有2000或以上张图像。
③合理标记对象。标记对象的最佳方法是:仅标记对象的可见部分,或标记对象的可见和重叠部分,或标记比整个对象多一点(有一点间隙)。
④修改模型参数。在.cfg文件中设置flag random = 1通过对Yolo进行不同分辨率的训练,或是增加.cfg文件中的网络分辨率(height= 608,width= 608或任何32的倍数)
更详细的内容请看GitHub!

















 4521
4521

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









