






前言
1. SD能做什么
最基本的功能是:文生图(text-to-image)
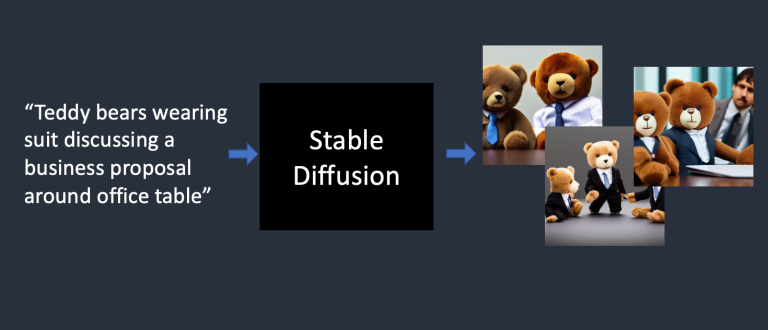
SD以文字提示为输入,输出与提示相配的图像
2. 扩散模型
SD属于扩散模型。扩散模型是一类生成式模型,它们被设计用于生成与训练数据类似的新数据。
扩散模型为什么叫“扩散”模型呢?因为模型生成数据的过程类似物理上的扩散。下面以训练生成🐱🐕图片的扩散模型为例,介绍训练过程。
2.1 正向扩散
正向扩散(Forward Diffusion)是🐱/🐕图片转为无特点的噪声图的过程,从噪声图是看不出最初是🐱还是🐕的。
像一滴墨掉进一杯水,不一会儿就会慢慢扩散,将自己随机分布到水中,就难以辨认出最初墨滴在边缘、中心还是别的哪里了。

一张🐱图经过正向扩散,变成随机噪声
2.2 逆向扩散
而**逆向扩散(Reverse Diffusion)**则从无意义的噪声图中复原出🐱或🐕,是正向扩散的“倒放”。
技术上,每次扩散包括两步:漂移(drift)和随机运动(random motion)。逆向扩散的漂移要么朝着复原出🐱的方向要么朝着复原出🐕的方向,而不会是一个中间值。
3. 逆向扩散怎么实现
逆向扩散这个idea无疑是聪明优雅的。但价值千金的难题是:它怎么实现?
3.1 训练noise predictor
为了将扩散过程逆过来,我们需要知道一张图被添加了多少噪声。这可以通过训练一个模型预测图上的噪声程度来实现,noise predictor在SD中是由一个U-Net模型(一种全卷积神经网络)实现的。训练过程分4步:
- 取一张训练图,比如一张🐱图
- 生成一张噪声图
- 将噪声图以不同强度叠加到训练图上来破坏训练图像。
- 教噪声预测器告诉我们添加了多少噪声
这是通过调整强度并显示正确数值来实现的。

每一步中叠加更多噪声,让noise predictor估计每一步图像中的噪声
经过训练,我们得到了能预测图中添加噪声量多少的noise predictor。
3.2 逆向扩散步骤
有了noise predictor,我们用它实现逆向扩散。
- 生成一个完全随机的图像,并要求noise predictor告诉我们噪声
- 从原始图像中减去预测的噪声
重复1.和2.几次,就获得🐱或🐕的图像。
我们暂时还不能控制复原出的图片是🐱还是🐕,控制输出可以通过加条件来实现。
4. Stable Diffusion
现在有一个坏消息。刚刚所说的不是SD的工作方式。扩散过程是在图像空间进行的。这在计算上慢到难以接受,而且在任何单个的GPU上都跑不了。512*512的RGB图在786,432维的空间。我们需要为一张图指定的值太太太多。
Google的Imagen和Open AI的DALL-E是像素级的扩散模型,它们有一些加速的技巧但还不够。
而Stable Diffusion正是为解决图像扩散模型的速度难题而设计的。
4.1 表征(Latent)扩散模型
Stable Diffusion是一个表征扩散模型。它首先把图像压缩到表征空间,以避免在高维的图像空间进行操作。这就快多了。
4.2 图像表征和复原
_图像到表征_和_表征到图像_的转换是通过VAE(Variational Autoencoder)来实现的。
VAE包括encoder和decoder两部分。
encoder将图片压缩为较低维度的表征,decoder从表征中复原图片。
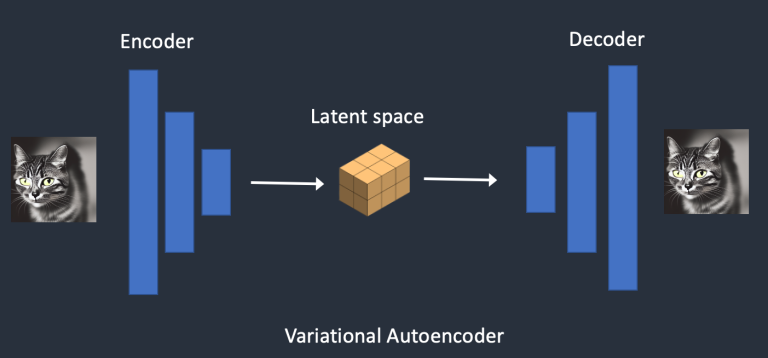
VAE实现图像与表征的相互转换
- 为什么使用表征是可行的
VAE为何可以将图像压缩为表征而不会丢失信息?这是因为是自然图像不是随机的。他们的规律性很高:比如脸遵循眼睛,鼻子,脸颊和嘴巴之间的特定空间关系。狗有四条腿,有特殊的形态。
换句话说,图像的高维度是人为的,有很多冗余信息。自然图像可以轻松地压缩到较小的潜在空间中,而不会丢失任何信息。这称为机器学习中的manifold hypothesis。
4.3 SD的训练
Stable Diffusion中对512*512的RGB图像的表征是4*64*64的。得到表征后,之前说的扩散过程都在表征空间进行。所以训练时,我们生成的噪声不是噪声图而是一个表征空间的随机tensor,这个tersor再和图像的表征进行不同程度的叠加,以训练noise predictor并进行逆向扩散(逆向扩散sampling和samplers: 详见link)。逆向扩散步骤如下:
- 生成一个随机矩阵作为图像表征。
- noise predictor估计这个矩阵的噪声,从图像表征中减去估计的噪声。
(重复2.直到特定的采样步骤) - VAE的解码器将图像表征转换为最终图像
4.4 图像分辨率
图像分辨率在图像表征的shape上有体现,这也是生成大图会耗费更多显存和时间的原因。表征的大小是图片大小的1/48(768*512的RGB图像的表征是4*96*64的)。
StableDiffusion v1是在512*512的图像上微调的,因此生成比512*512的更大的图会出现重复的物体(比如,两个脑袋(with solution)))。
- 生成大图
如果一定要生成大图,需要至少保证宽/高中的一个是512,再用AI upscaler提高分辨率。
4.5 VAE file
VAE file用于Stable Diffusion v1中,以改善眼睛和面部。它们是经过进一步微调的VAE decoder,该模型可以绘制更精细的细节。
(之前提到的假说并非完全正确。将图像压入潜在空间确实会丢失信息,因为原始VAE没有恢复细节。取而代之的是,VAE file中的decoder负责绘制精美的细节。)
5. 条件控制(Conditioning)
上述对Stable Diffusion的理解还不完整。怎么通过文本提示来控制出图呢?
这就需要Conditioning,其目的是引导noise predictor,以便预测的噪声从图像中减掉后能得出我们想要的东西。
5.1 文本条件(text-to-image)
下图是文本提示(text prompt)被处理并喂给noise predictor的过程。Tokenizer先把提示中的每个词切分出来作为token。每个token会被转化为一个768维的embedding。随后embedding被送入
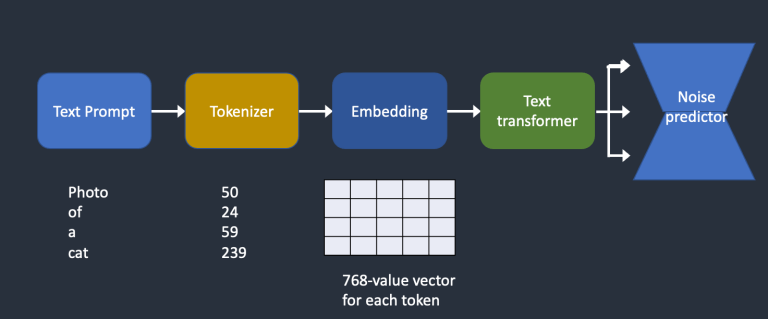
将文本提示特征化,并送入noise predictor以控制文本生成
这里直接将该软件分享出来给大家吧~需要的可以点击👇小卡片领取

1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的stable diffusion资料我已经打包好,需要的点击下方插件,即可前往免费领取!


















 4941
4941

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









