







介绍
计算机视觉(CV)是人工智能的一部分,它使计算机能够分析和理解视觉信息,包括图像和视频。它超越了简单的“看到”图像,而是教会计算机根据它们看到的东西做出决定。
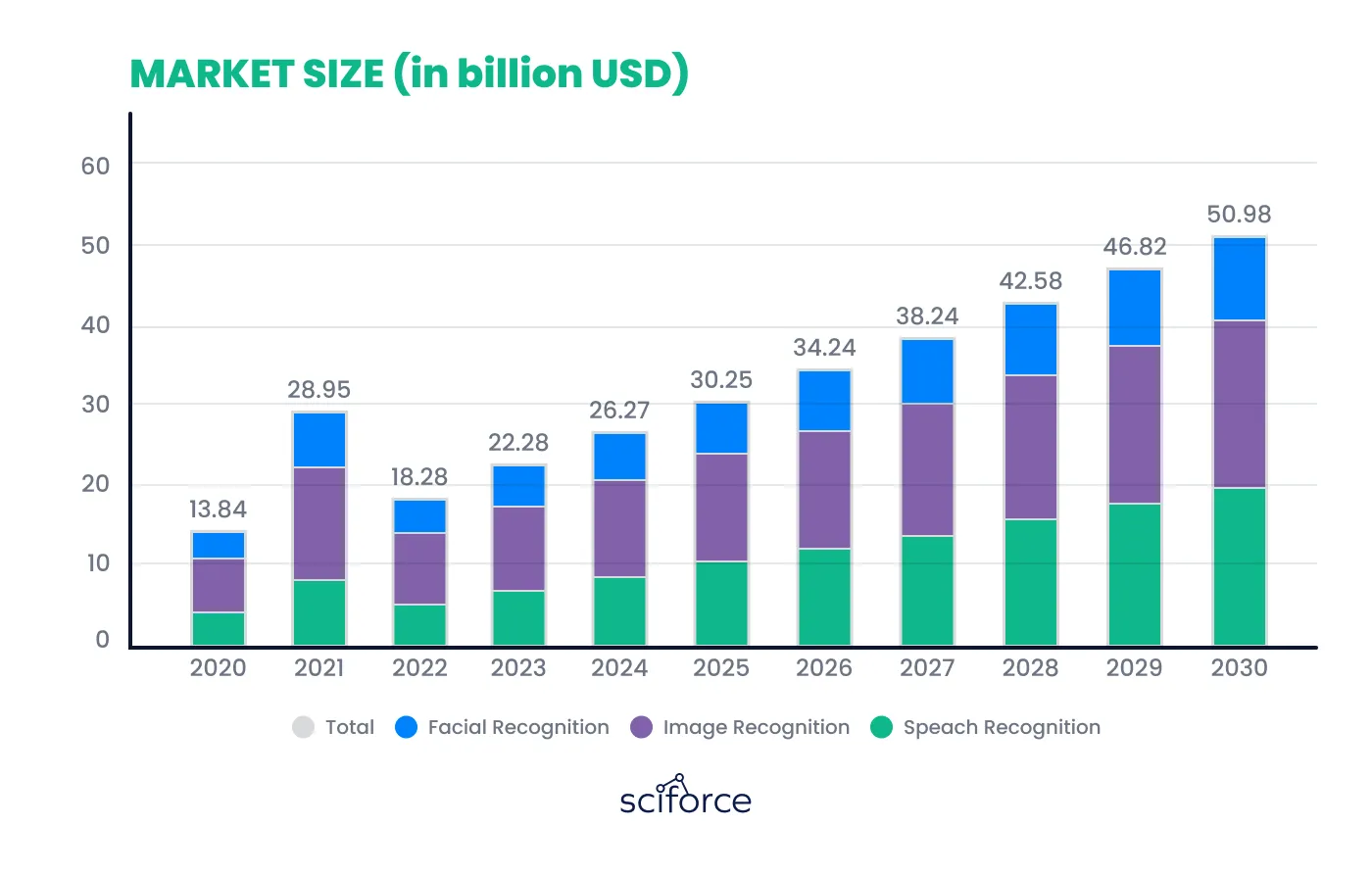
人工智能驱动的计算机视觉市场正经历快速增长,从2023年的220亿美元增长到预期的2023年的220亿美元500亿美元到2030年,2024-2030年CAGR将达到21.4%。
这项技术模仿人类的视觉,但使用复杂的算法、大量数据和相机工作得更快。计算机视觉系统可以快速分析大面积上的数千种物品,或者检测人眼看不见的微小缺陷。
这种能力已经在很多领域得到了应用——这就是我们今天要讨论的内容!
计算机视觉是如何工作的?
计算机视觉使机器能够根据视觉信息进行解释和决策。它应用先进的方法来处理和分析图像和视频,使计算机能够识别对象并做出相应的响应。本节解释了计算机视觉中的关键过程和技术,强调了它如何将视觉数据转化为实际见解。
捕捉视觉数据
教授计算机看东西的第一步是准确捕捉和准备视觉数据:

- 数据采集
视觉数据由充当物理世界和数字分析系统之间的纽带的摄像机和传感器捕获。他们收集从图像到视频的各种视觉输入,为训练 CV 算法提供原材料。通过将现实世界的视觉效果转换为数字格式,它们使计算机视觉能够分析和理解环境。
- 预处理
预处理涉及细化视觉数据以进行最佳分析。这包括将图像大小调整为一致的尺寸、标准化亮度和对比度以及应用颜色校正以实现准确的颜色表示。这些调整对于确保数据均匀性和提高图像质量以进行进一步处理至关重要。
图像处理和分析
第二阶段包括识别和隔离特定的图像特征,以识别模式或对象。
- 特征提取
此步骤的重点是检测图像中的不同元素,例如边缘、纹理或形状。通过分析这些特征,计算机视觉系统可以识别图像的各个部分,并正确识别感兴趣的对象和区域。
- 模式识别
该系统使用识别出的特征将其与现有模板进行匹配,通过对象的独特特征和学习模式来识别对象。此过程可以对图像中的各种元素进行分类和标记,帮助系统准确地解释和理解视觉信息。
机器学习
第三阶段是机器学习,增强系统解释视觉数据并与之交互的能力。
- 监督学习
训练模型通过从示例中学习,使用标记数据来识别和分类图像。模型通过理解数据中的模式并将其应用于未知对象来学习预测图像的正确标签。
- 无监督学习
允许计算机视觉模型通过查找数据中的自然分组或模式来排序和理解没有标签的图像。这有助于处理大量没有标签的图像集、检测异常和分割图像。它使模型能够发现不寻常的图像或根据视觉特征对它们进行分类,从而增强它们对视觉数据的自主解释。
- 深度学习和神经网络
创建多层神经网络,学习大量数据中的复杂模式,如图像识别、NLP和高精度预测分析。卷积神经网络(CNN)更进一步ÿ
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1194
1194

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









