










- 简介
=========
最近对大模型这部分内容比较感兴趣,作者最早接触大模型是22年下半年的时候。当时觉得非常amazing,并认为这是一个颠覆性的工作,目前随着开源大模型的逐渐变多。我觉得我们得学习并了解这些基础知识,以便后续在工作中可以学习并使用。在深度学习中,微调是一种重要的技术,用于改进预训练模型的性能。除了微调ChatGPT之外,还有许多其他预训练模型可以进行微调。以下是一些微调预训练模型的方法:
·微调所有层:将预训练模型的所有层都参与微调,以适应新的任务。
·微调顶层:只微调预训练模型的顶层,以适应新的任务。
·冻结底层:将预训练模型的底层固定不变,只对顶层进行微调。
·逐层微调:从底层开始,逐层微调预训练模型,直到所有层都被微调。
·迁移学习:将预训练模型的知识迁移到新的任务中,以提高模型性能。这种方法通常使用微调顶层或冻结底层的方法。
目前来说,我们常用的方法一般是前三种。简单来说模型的参数就类比于,一个在大学学习到所有专业的知识的大学生,基于过往的学习经验以及对生活中的一些事情,已经有了属于自己的一套学习方法思维逻辑。而微调则是一个大学生毕业后从事某一种行业的工作,那他就要开始学习工作上的内容,来产出工作的成果。下面我们就来介绍一些常用的微调方法。
1. Fine tuning
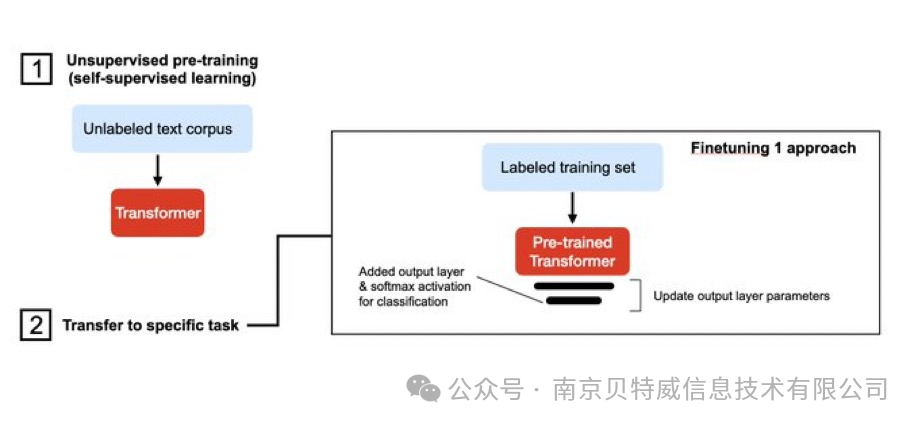
Fine tuning是一种在自然语言处理(NLP)中使用的技术,用于将预训练的语言模型适应于特定任务或领域。Fine tuning的基本思想是采用已经在大量文本上进行训练的预训练语言模型,然后在小规模的任务特定文本上继续训练它。
经典的Fine tuning方法包括将预训练模型与少量特定任务数据一起继续训练。在这个过程中,预训练模型的权重被更新,以更好地适应任务。所需的Fine-tuning量取决于预训练语料库和任务特定语料库之间的相似性。如果两者相似,可能只需要少量的Fine tuning。如果两者不相似,则可能需要更多的Fine tuning。
- Prompt tuning
参数高效性微调方法中实现最简单的方法还是Prompt tuning(也就是我们常说的P-Tuning),固定模型前馈层参数,仅仅更新部分embedding参数即可实现低成本微调大模型
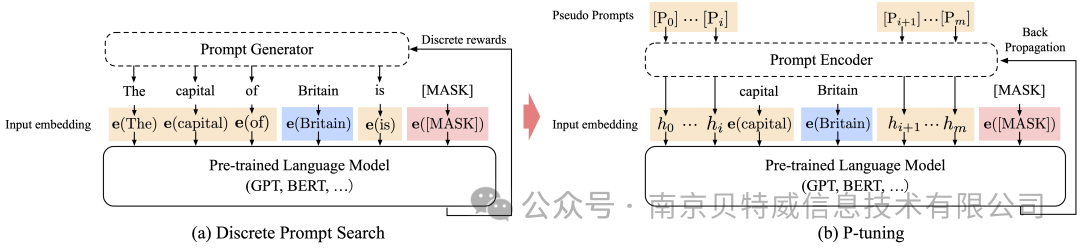
经典的Prompt tuning方式不涉及对底层模型的任何参数更新。相反,它侧重于精心制作可以指导预训练模型生成所需输出的输入提示或模板。主要结构是利用了一个prompt encoder(BiLSTM+MLP),将一些pseudo prompt先encode(离散token)再与input embedding进行拼接,同时利用LSTM进行 Reparamerization 加速训练,并引入少量自然语言提示的锚字符(Anchor,例如Britain)进一步提升效果。然后结合(capital,Britain)生成得到结果,再优化生成的encoder部分。但是P-tuning v1有两个显著缺点:任务不通用和规模不通用。在一些复杂的自然语言理解NLU任务上效果很差,同时预训练模型的参数量不能过小。
2. Prefix Tuning
如果分析 P-tuning,那不得不提到prefix-tuning技术,相对于fine-tuning,在调节模型的过程中只优化一小段可学习的continuous task-specific vector(prefix)而不是整个模型的参数。
Prefix Tuning针对不同的模型结构有设计不同的模式,以自回归的模型为例,不再使用token去作为前缀,而是直接使用参数作为前缀,比如一个l×d的矩阵P作为前缀,但直接使用这样的前缀效果不稳定,因此使用一个MLP层重参数化,并放大维度d**,除了在embedding层加入这个前缀之外,还在其他的所有层都添加这样一个前缀。最后微调时只调整前缀的参数,大模型的参数保持不变**。保存时只需要为每个任务保存重参数的结果即可。 
3. P-tuning v2
V2版本主要是基于P-tuning和prefix-tuning技术,引入Deep Prompt Encoding和Multi-task Learning等策略进行优化的。
实验表明,仅精调0.1%参数量,在330M到10B不同参数规模LM模型上,均取得和Fine-tuning相比肩的性能 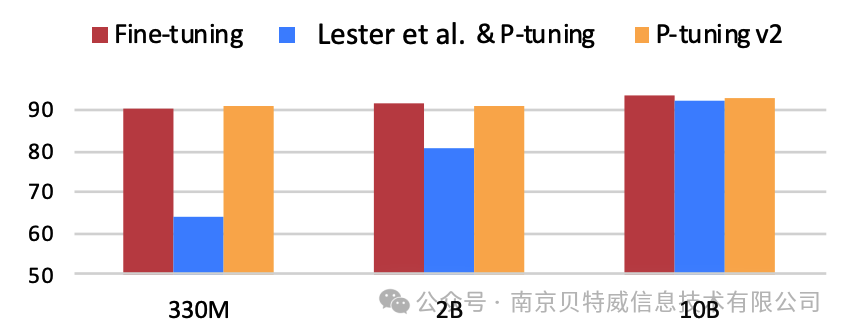 下面是v1和v2框架对比,我们可以看到右侧的p-tuning v2中,将continuous prompt加在序列前端,并且每一层都加入可训练的prompts。在左图v1模型中,只将prompt插入input embedding中,会导致可训练的参数被句子的长度所限制。此外P-Tuning v2还包括以下改进:
下面是v1和v2框架对比,我们可以看到右侧的p-tuning v2中,将continuous prompt加在序列前端,并且每一层都加入可训练的prompts。在左图v1模型中,只将prompt插入input embedding中,会导致可训练的参数被句子的长度所限制。此外P-Tuning v2还包括以下改进:
·移除了Reparamerization加速训练方式;
·采用了多任务学习优化:基于多任务数据集的Prompt进行预训练,然后再适配的下游任务。
·舍弃了词汇Mapping的Verbalizer的使用,重新利用[CLS]和字符标签,跟传统finetune一样利用cls或者token的输出做NLU,以增强通用性,可以适配到序列标注任务。 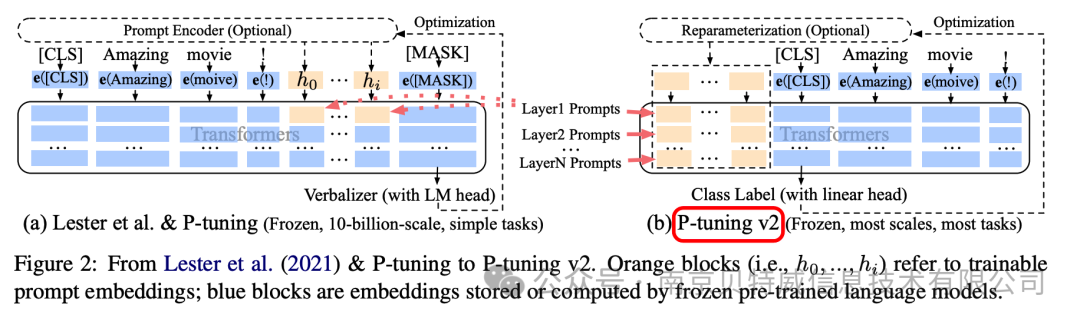 总而言之,P-tuning v2就是将Prefix-tuning应用到NLU任务上的一种方法。同时由于P-tuning v2每层插入了token,增大模型训练的改变量,所以更加适用于小一点的模型。
总而言之,P-tuning v2就是将Prefix-tuning应用到NLU任务上的一种方法。同时由于P-tuning v2每层插入了token,增大模型训练的改变量,所以更加适用于小一点的模型。
4. Lora
Lora的本质就是对所有权重矩阵套了一层“壳”,这些壳会对原来的预训练权重矩阵进行加减使其更加适合下游任务,即实现微调。他的假设前提是预训练语言模型具有低的"内在维度",因此认为在模型适配下游任务的过程中,权重更新也应该具有低的“内在秩”。
在对大语言模型进行微调的公式可以简化为下面的公式
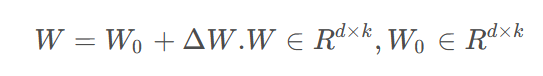
其中W是微调微调过后的矩阵权重(是大语言模型中的对应的稠密层,一般这些矩阵都是满秩的),W0 是预训练的权重,ΔW是通过微调而更新的梯度。将上面的ΔW做一些变换,将他变成两个矩阵相乘
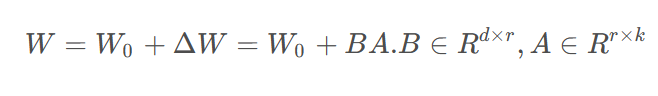
在里面引入了秩r,r<<min(d,k),在训练过程中lora会冻结预训练权重W0**,只训练A和B,减少了需要训练的参数的量,一般来讲,对于lora微调模型来讲r设置的越大其微调效果会越好**。
LoRA算法的核心思想是,将原始矩阵A分解为两个低秩矩阵X和Y的乘积形式,即A=X⋅Y。具体地,LoRA算法会首先对原始矩阵进行SVD分解,得到矩阵A=UΣVT,其中U和V分别是AAT和 ATA的特征向量矩阵,Σ是奇异值矩阵。然后,LoRA算法会取U的前k列和V的前k行,得到低秩矩阵X=U(:,1:k)和Y=V(1:k,:),其中k是预设的参数,表示矩阵A的秩。最后,LoRA算法将近似矩阵Ak=X⋅Y作为原始矩阵A的近似,即Ak≈A。 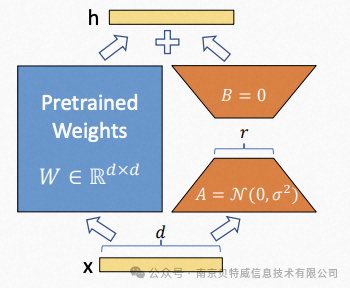
最终我们得到的一个权重文件会是各层的BA,在推理时是需要计算一下W=W0+BA,就可以得到最终需要的微调之后的模型权重,该方法的好处如下所示
1.减少了需要推理的参数量
2.相较于添加adapter层的方式去微调模型,因为他并没有在模型中添加额外的层,只是在原来的权重上进行权重的加减,微调前后模型的推理时间不变
3.因为他最后生成的权重是各层的BA,并没有改变原模型的权重参数,所以其结果相当于一个插件,可以即插即用,可以为多个不同的微调任务生成各自的lora微调权重值,也方便存储。
一般在使用lora去对模型卫星微调的时候需要注意的参数就两个:r和lora_target_modules 。前者决定了lora微调时构造的矩阵的秩的大小(这里也可以简单的理解为矩阵B和A的大小),以及在大语言模型中应用的不同模块。后者模块的具体名称需要依据不同的模型去决定。
5. RLHF–人类反馈强化学习
RLHF 的思想就是使用强化学习的方式直接优化带有人类反馈的语言模型。RLHF 使得在一般文本数据语料库上训练的语言模型能和复杂的人类价值观对齐。
RLHF 是一项涉及多个模型和不同训练阶段的复杂概念,一般会分为三步,这也是一个生成自己大模型所必需的。
第一步是 supervised-fintuning,即使用上文提到的数据集进行模型微调,预训练一个语言模型 (LM) 。
第二步是训练一个奖励模型,它通过对于同一个 prompt 的不同输出进行人工排序,聚合问答数据并训练一个奖励模型 (Reward Model,RM) ;
第三步则是用强化学习算法(RL) 方式微调 LM。
下面我们直接应用抱抱脸网站的内容
Step 1. 预训练语言模型
首先,我们使用经典的预训练目标训练一个语言模型。对这一步的模型,OpenAI 在其第一个流行的 RLHF 模型 InstructGPT 中使用了较小版本的 GPT-3; Anthropic 使用了 1000 万 ~ 520 亿参数的 Transformer 模型进行训练;DeepMind 使用了自家的 2800 亿参数模型 Gopher。
这里可以用额外的文本或者条件对这个 LM 进行微调,例如 OpenAI 对 “更可取” (preferable) 的人工生成文本进行了微调,而 Anthropic 按 “有用、诚实和无害” 的标准在上下文线索上蒸馏了原始的 LM。这里或许使用了昂贵的增强数据,但并不是 RLHF 必须的一步。由于 RLHF 还是一个尚待探索的领域,对于” 哪种模型” 适合作为 RLHF 的起点并没有明确的答案。 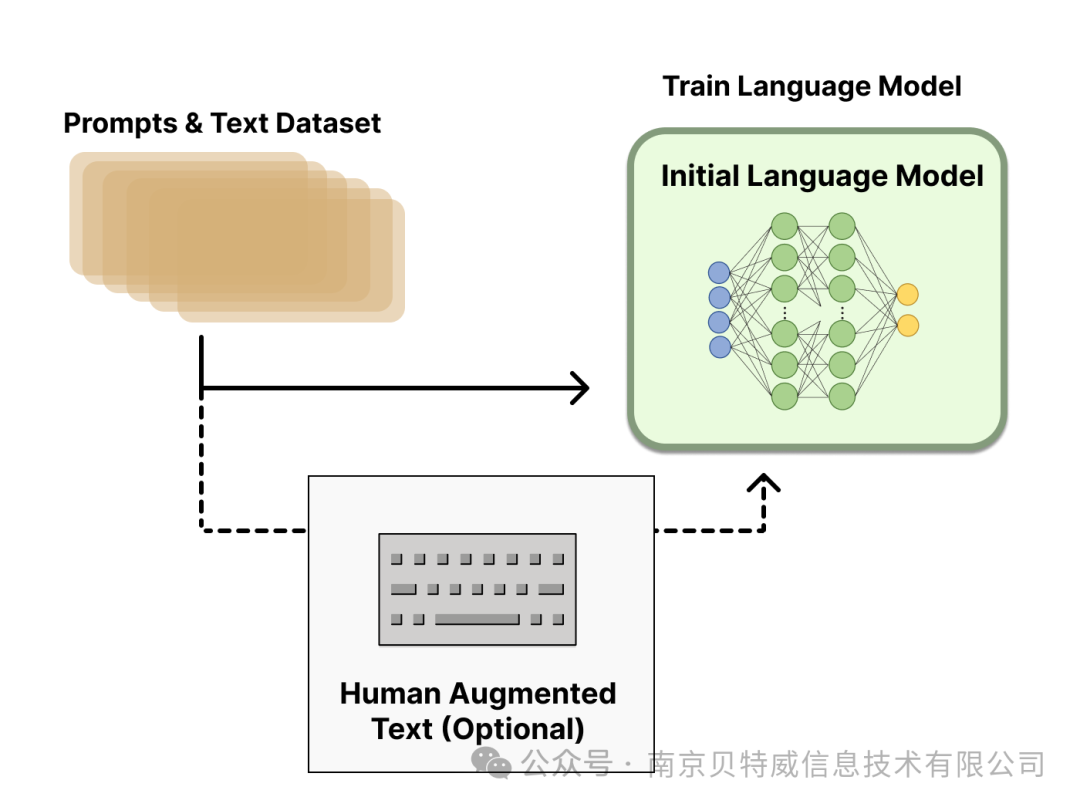 接下来,我们会基于 LM 来生成训练 奖励模型 (RM,也叫偏好模型) 的数据,并在这一步引入人类的偏好信息。
接下来,我们会基于 LM 来生成训练 奖励模型 (RM,也叫偏好模型) 的数据,并在这一步引入人类的偏好信息。
Step 2. 训练奖励模型
**RM 的训练是 RLHF 区别于旧范式的开端。这一模型接收一系列文本并返回一个标量奖励,数值上对应人的偏好**。我们可以用端到端的方式用 LM 建模,或者用模块化的系统建模 (比如对输出进行排名,再将排名转换为奖励) 。这一奖励数值将对后续无缝接入现有的 RL 算法至关重要。
关于模型选择方面,RM 可以是另一个经过微调的 LM,也可以是根据偏好数据从头开始训练的 LM。例如 Anthropic 提出了一种特殊的预训练方式,即用偏好模型预训练 (Preference Model Pretraining,PMP) 来替换一般预训练后的微调过程。因为前者被认为对样本数据的利用率更高。但对于哪种 RM 更好尚无定论。
关于训练文本方面,RM 的提示 - 生成对文本是从预定义数据集中采样生成的,并用初始的 LM 给这些提示生成文本。Anthropic 的数据主要是通过 Amazon Mechanical Turk 上的聊天工具生成的,并在 Hub 上 可用,而 OpenAI 使用了用户提交给 GPT API 的 prompt。
关于训练奖励数值方面,这里需要人工对 LM 生成的回答进行排名。起初我们可能会认为应该直接对文本标注分数来训练 RM,但是由于标注者的价值观不同导致这些分数未经过校准并且充满噪音。通过排名可以比较多个模型的输出并构建更好的规范数据集。 对具体的排名方式,一种成功的方式是对不同 LM 在相同提示下的输出进行比较,然后使用 Elo 系统建立一个完整的排名。这些不同的排名结果将被归一化为用于训练的标量奖励值。
这个过程中一个有趣的产物是目前成功的 RLHF 系统使用了和生成模型具有 不同 大小的 LM (例如 OpenAI 使用了 175B 的 LM 和 6B 的 RM,Anthropic 使用的 LM 和 RM 从 10B 到 52B 大小不等,DeepMind 使用了 70B 的 Chinchilla 模型分别作为 LM 和 RM) 。一种直觉是,偏好模型和生成模型需要具有类似的能力来理解提供给它们的文本。 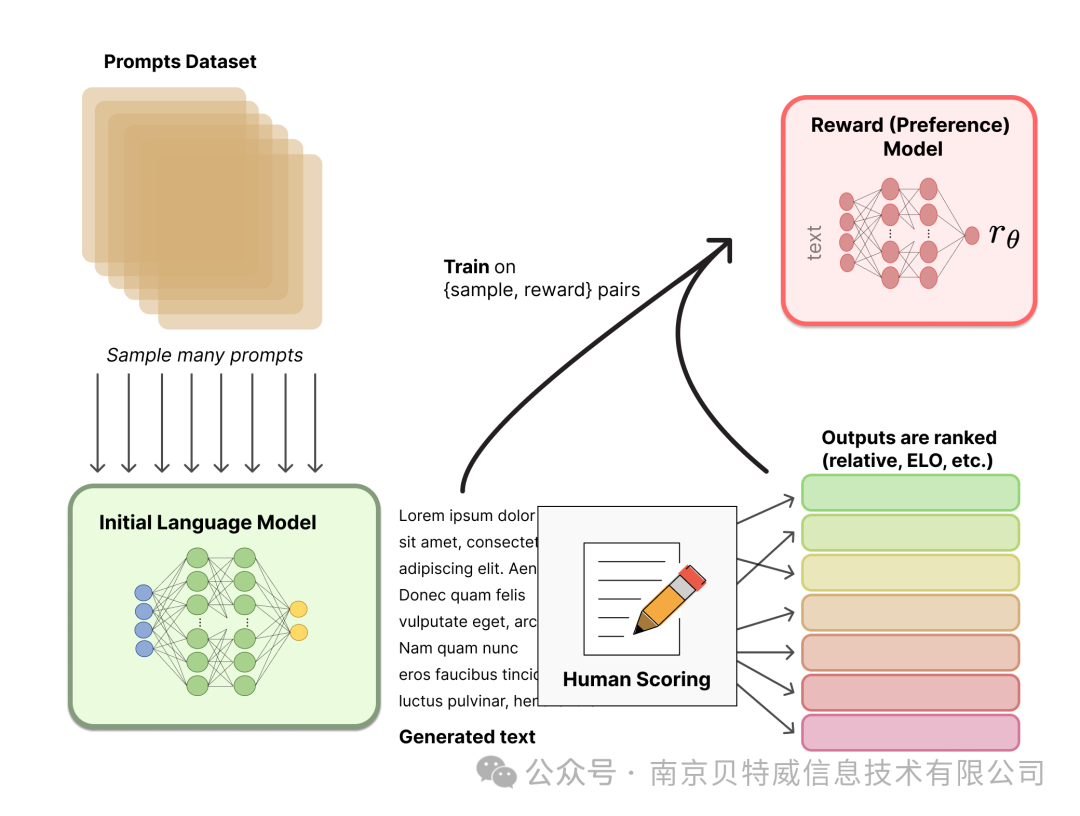 接下来是最后一步:利用 RM 输出的奖励,用强化学习方式微调优化 LM。
接下来是最后一步:利用 RM 输出的奖励,用强化学习方式微调优化 LM。
Step 3. 用强化学习微调
长期以来出于工程和算法原因,人们认为用强化学习训练 LM 是不可能的。而**目前多个组织找到的可行方案是使用策略梯度强化学习 (Policy Gradient RL) 算法、近端策略优化 (Proximal Policy Optimization,PPO) 微调初始 LM 的部分或全部参数**。因为微调整个 10B~100B+ 参数的成本过高 (相关工作参考低秩适应 LoRA 和 DeepMind 的 Sparrow LM) 。PPO 算法已经存在了相对较长的时间,有大量关于其原理的指南,因而成为 RLHF 中的有利选择。
事实证明,RLHF 的许多核心 RL 进步一直在弄清楚如何将熟悉的 RL 算法应用到更新如此大的模型。
让我们首先将微调任务表述为 RL 问题。首先,该 策略 (policy) 是一个接受提示并返回一系列文本 (或文本的概率分布) 的 LM。这个策略的 行动空间 (action space) 是 LM 的词表对应的所有词元 (一般在 50k 数量级) ,观察空间 (observation space) 是可能的输入词元序列,也比较大 (词汇量 ^ 输入标记的数量) 。奖励函数 是偏好模型和策略转变约束 (Policy shift constraint) 的结合。
最后根据 PPO 算法,我们按当前批次数据的奖励指标进行优化 (来自 PPO 算法 on-policy 的特性) 。PPO 算法是一种信赖域优化 (Trust Region Optimization,TRO) 算法,它使用梯度约束确保更新步骤不会破坏学习过程的稳定性。DeepMind 对 Gopher 使用了类似的奖励设置,但是使用 A2C (synchronous advantage actor-critic) 算法来优化梯度。 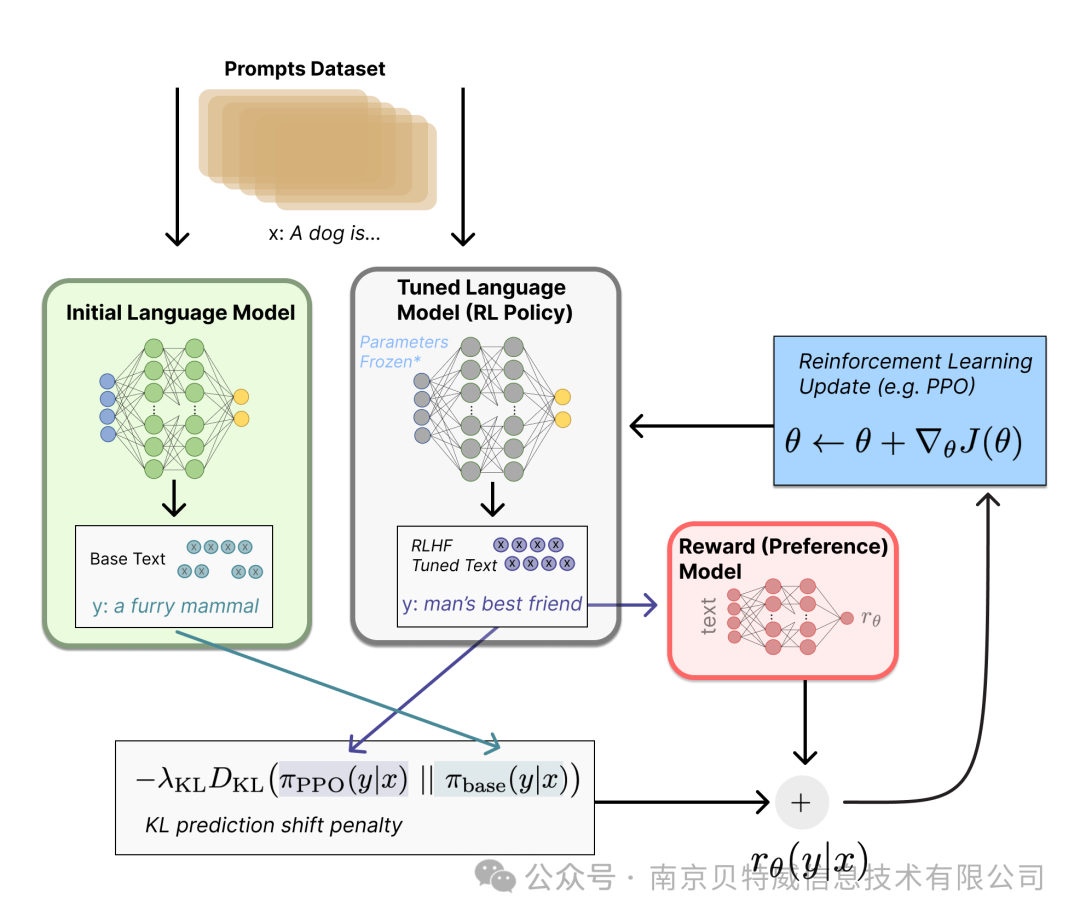
6. DeepSpeed ZeRO----零冗余优化
Deepspeed是微软的大规模分布式训练工具。专门用于训练超大模型。其具有的3D 并行同时解决了训练万亿参数模型的两个基本挑战:显存效率和计算效率。因此,DeepSpeed 可以扩展至在显存中放下最巨大的模型,而不会牺牲速度。
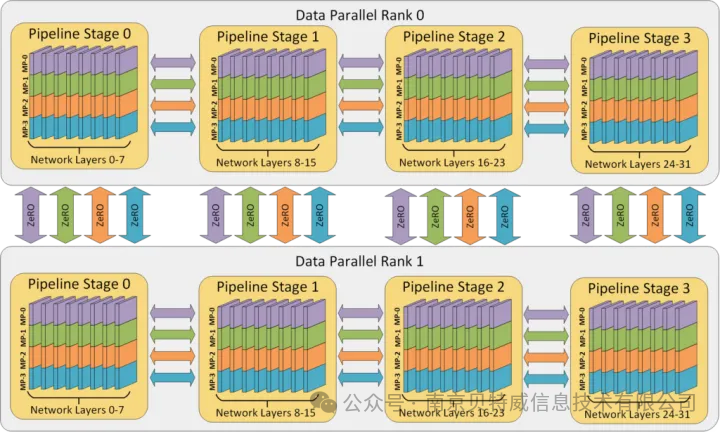 然后使用DeepSpeed+Zero的结合方式就可以实现全参数的微调。当然,使用DeepSpeed进行full finetuning,对于显存要求较高,且训练较慢。但这个无疑是一个比较好的办法,因为DeepSpeed ZeRO-2主要用于训练,因为它的功能对推理没有用。但是当DeepSpeed发展到ZeRO-3后,也可用于推理,因为它允许在多个GPU上加载大型模型,这在单个GPU上是不可能的。
然后使用DeepSpeed+Zero的结合方式就可以实现全参数的微调。当然,使用DeepSpeed进行full finetuning,对于显存要求较高,且训练较慢。但这个无疑是一个比较好的办法,因为DeepSpeed ZeRO-2主要用于训练,因为它的功能对推理没有用。但是当DeepSpeed发展到ZeRO-3后,也可用于推理,因为它允许在多个GPU上加载大型模型,这在单个GPU上是不可能的。
在Python中,Accelerate[7]库提供了简单的 API,使我们可以在任何类型的单节点或分布式节点(单CPU、单GPU、多GPU 和 TPU)上运行,也可以在有或没有混合精度(fp16)的情况下运行。
这里是我用 Accelerator 和 DeepSpeedPlugin 做个示例,这里需要提前知道梯度累积步骤 gradient_accumulation_steps 和 梯度累积计算
AI大模型学习福利
作为一名热心肠的互联网老兵,我决定把宝贵的AI知识分享给大家。 至于能学习到多少就看你的学习毅力和能力了 。我已将重要的AI大模型资料包括AI大模型入门学习思维导图、精品AI大模型学习书籍手册、视频教程、实战学习等录播视频免费分享出来。
因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
一、全套AGI大模型学习路线
AI大模型时代的学习之旅:从基础到前沿,掌握人工智能的核心技能!

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
二、640套AI大模型报告合集
这套包含640份报告的合集,涵盖了AI大模型的理论研究、技术实现、行业应用等多个方面。无论您是科研人员、工程师,还是对AI大模型感兴趣的爱好者,这套报告合集都将为您提供宝贵的信息和启示。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
三、AI大模型经典PDF籍
随着人工智能技术的飞速发展,AI大模型已经成为了当今科技领域的一大热点。这些大型预训练模型,如GPT-3、BERT、XLNet等,以其强大的语言理解和生成能力,正在改变我们对人工智能的认识。 那以下这些PDF籍就是非常不错的学习资源。

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
四、AI大模型商业化落地方案

因篇幅有限,仅展示部分资料,需要点击下方链接即可前往获取
2024最新版CSDN大礼包:《AGI大模型学习资源包》免费分享
作为普通人,入局大模型时代需要持续学习和实践,不断提高自己的技能和认知水平,同时也需要有责任感和伦理意识,为人工智能的健康发展贡献力量。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









