







日期:2023/12/18
论文:Long-Tailed Recognition by Mutual Information Maximization between Latent Features and Ground-Truth Labels
链接:GML
会议:ICML 2023(The International Conference on Machine Learning)
目录
0 一些不懂的知识点的小结(边看边记✍)
- logit adjustment (莫非就是re-weighting?)
- mutual information(MI) 互信息
- likelihood 似然函数
- isotropic Gaussian 各向同性高斯分布
- kernel density estimation with Gaussian kernels 高斯核密度估计
- Gaussian mixture likelihood 高斯混合似然
- Kernel Density Estimation
- teacher-student 策略
- 余弦相似度分类器(对比学习中的)
1 Abstract
对比学习尽管在很多representation learning tasks上有普遍不错的表现,但是在长尾数据集上就不咋滴。许多研究人员尝试将对比学习和logic adjustment技术结合来解决此问题,但这种组合是临时的(ad-hoc)且没有理论解释。
本文有几个点:
- 发现了对比学习在长尾任务上表现不好的普遍原因:他们都尝试最大化潜在特征和输入数据之前的互信息(mutual information)。而GT是没有参与到这个最大化过程的,所以没有办法解决类别不平衡问题。
- 再者,本文将长尾识别任务解释为最大化潜在特征和GT之间的互信息。
这种方法天衣无缝地整合了对比学习和logit adjustment,衍生出了一个Loss叫高斯混合似然损失(GML),可以在很多个长尾数据集上表现出SOTA性能。
2 Introduction
- 本文尝试提出最大化 latent features和 GT labels之间的互信息,用GT labels替换了原始的input data,这样则考虑到了类的分布,有助于解决长尾问题。
- 提出了一种通用的loss,包括潜在特征的似然(a likelihood of latent feature, 也就是在给定类的情况下,某个特征出现的概率)以及类的先验项(a prior of classes term,既每个类出现的概率)
- 不同方法下也会有不同的建模:
1) 平衡数据集的softmax CE loss使用各向同性的高斯分布来建模似然
2) 不平衡数据集的logit adjustment也使用各向同性的高斯分布来建模似然
3) 假设数据集平衡的监督对比学习基于采样的高斯核密度估计来估计似然
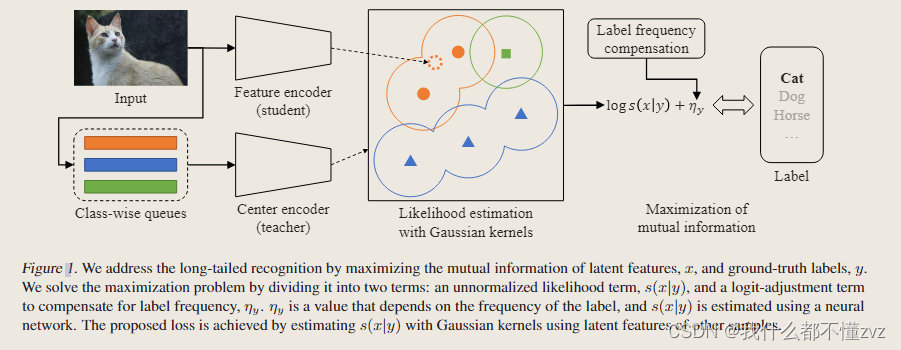
- 这里假设数据集是class-imbalance的,并且KDE使用高斯核会自然地导致一个高斯混合模型的似然,所以叫GML Loss(不懂关联?)
- 使用MOCO中的队列来存储contrast samples,不同的是这里使用class-wise queues。因为长尾学习中尾类数据较少,较少的尾类数据不能生成高斯混合。且如果使用单一queue的话,queue就会被头类占主导;class-wise queues是说各个类都有一个单独的queue,允许模型为每个类分别学习和存储特征。(高斯混合、queue的长度?)
- 并且使用了teacher-student 策略,不同于MoCo的动量编码器,这里使用预训练好的teacher encoder去生成contrast samples
2 Related Work
2.1 长尾识别
Rebalancing dataset
效果不好
Normalized Classifier
长尾数据集上训练出来的分类器通常存在的权值的偏差,这个问题可以通过归一化分类层的权重来缓解。文章1提出通过解耦特征学习和分类器(分开训练)的方法来归一化权重。先是instance-based sampling去采样实例而不考虑类别,共同训练网络;然后使用class-balanced sampling的策略采样数据去再对分类器进行训练。文章2提出使用余弦相似度分类器而不是点乘分类器,仅通过相对角度来绕过有偏权重的问题。
本文采用余弦相似度作为分类器。
3 Proposed Method
互信息(Mutual Information,ML)衡量两个随机变量共享信息的量,它衡量的是知道一个变量后另一个变量不确定性减少的程度。理论上,互信息可以利用变量的联合分布和边缘分布计算得到,如
I
(
X
;
Y
)
=
D
K
L
(
P
(
X
,
Y
)
;
P
(
X
)
P
(
Y
)
)
I(X;Y)=D_{KL}(P(X,Y);P(X)P(Y))
I(X;Y)=DKL(P(X,Y);P(X)P(Y))。但是一般数据都是高维的,对高维数据计算这些很难,所以深度学习中直接计算互信息很难,更别说引入了很多非线性了。通常的办法是使用以下公式来最大化互信息的下界,从而达到最大化互信息的效果,公式如下
I
(
X
;
Y
)
≥
E
[
1
K
∑
i
=
1
K
l
o
g
e
x
p
f
(
x
i
,
y
i
)
1
K
∑
j
=
1
K
e
x
p
f
(
x
i
,
y
j
)
]
I(X;Y) \ge E[\frac{1}{K}\sum_{i=1}^Klog\frac{expf(x_i,y_i)}{\frac{1}{K}\sum_{j=1}^Kexpf(x_i,y_j)}]
I(X;Y)≥E[K1i=1∑KlogK1∑j=1Kexpf(xi,yj)expf(xi,yi)]
这个公式和infoNCE loss很像,但是infoNCE loss通过一批正负样本对来计算,而上式可以说是一个通用形式。
3.2 MI Maximization between latent features and GT labels
之前工作最大化互信息的两个变量分别是潜在特征和输入数据,所以他们是类别无关的,对于长尾任务来说就不太好。本工作使用GT labels代替输入数据,但这样就导致损失函数不再是对比损失函数了(对比损失函数是指两个样本的对比,距离的度量),下面是一步步推导怎么还原对比损失的。
Logit Adjustment
用潜在特征的集合代替上式的
X
X
X,用GT labels代替上式的
Y
Y
Y,取
K
K
K为整个训练数据集的大小,
i
i
i表示第
i
i
i个样本,
C
C
C表示是所有类的集合,
η
c
=
l
o
g
p
(
c
)
\eta_c=logp(c)
ηc=logp(c)表示一个logit adjustment term。那么上式中的
1
K
∑
i
,
j
=
1
k
\frac{1}{K}\sum^k_{i,j=1}
K1∑i,j=1k就相当于一个求期望的操作了。故可以写为下式
E
i
l
o
g
e
x
p
f
(
x
i
,
y
i
)
E
j
e
x
p
f
(
x
i
,
y
j
)
=
E
i
l
o
g
e
x
p
f
(
x
i
,
y
i
)
∑
c
∈
C
e
x
p
f
(
x
i
,
y
j
)
p
(
c
)
=
E
i
l
o
g
e
x
p
f
(
x
i
,
y
i
)
+
η
y
i
∑
c
∈
C
e
x
p
f
(
x
i
,
y
j
)
+
η
c
−
η
y
i
\begin{aligned} &E_ilog\frac{expf(x_i,y_i)}{E_jexpf(x_i,y_j)}=E_ilog\frac{expf(x_i,y_i)}{\sum_{c\in C} expf(x_i,y_j)p(c)}\\ &=E_ilog\frac{expf(x_i,y_i)+\eta_{y_i}}{\sum_{c\in C} expf(x_i,y_j)+\eta_c}-\eta_{y_i} \end{aligned}
EilogEjexpf(xi,yj)expf(xi,yi)=Eilog∑c∈Cexpf(xi,yj)p(c)expf(xi,yi)=Eilog∑c∈Cexpf(xi,yj)+ηcexpf(xi,yi)+ηyi−ηyi
分子 E j e x p f ( x i , y j ) = ∑ c ∈ C e x p f ( x i , c ) p ( c ) E_jexpf(x_i,y_j)=\sum_{c\in C}expf(x_i,c)p(c) Ejexpf(xi,yj)=∑c∈Cexpf(xi,c)p(c)是一个标准的期望表达式,然后再引入 η \eta η就得到包含logit adjustment term的lower bound
高斯核密度估计方法简单了解
Kernel density estimation, KDE 是一种估计未知概率密度函数的非参数方法
假设有数据集{x1,x2…xn},核密度估计(kernel density estimation)就是
f
^
(
x
)
=
1
n
∑
i
=
1
n
K
h
(
x
−
x
i
)
\hat f(x)=\frac{1}{n}\sum_{i=1}^nK_h(x-x_i)
f^(x)=n1∑i=1nKh(x−xi),其中
K
h
(
⋅
)
K_h(\cdot)
Kh(⋅)表示核函数,每个点给出了
x
与
x
i
x与x_i
x与xi的相对距离,从而估计出不同
x
i
x_i
xi时x出现的概率。
若为高斯核,高斯核(Gaussian kernel) 公式为 K h ( x ) = 1 2 π h e x p ( − x 2 2 h 2 ) K_h(x) = \frac{1}{\sqrt{2\pi}h}exp(\frac{-x^2}{2h^2}) Kh(x)=2πh1exp(2h2−x2),其中h为带宽参数,用于影响平滑性; x x x通常表示 x 与 x i x与x_i x与xi的距离。
故高斯核密度估计公式为
f
^
(
x
)
=
1
n
∑
i
=
1
n
1
2
π
h
e
x
p
(
−
(
x
−
x
i
)
2
2
h
2
)
\hat f(x)=\frac{1}{n}\sum_{i=1}^n \frac{1}{\sqrt{2\pi}h}exp(\frac{-(x-x_i)^2}{2h^2})
f^(x)=n1i=1∑n2πh1exp(2h2−(x−xi)2)
通俗来说就是,核密度估计通过比对
x
x
x和所有的
x
i
x_i
xi的距离计算它们的相似度,再根据不同的带宽
h
h
h控制平滑度,从而得到估计得概率密度(or概率质量)
L2 Normalization
L2归一化是指使用L2范数来归一化向量的各个值,举个例子,比如
z
y
=
[
3
,
4
]
z_y=[3,4]
zy=[3,4],那么
∣
∣
z
y
∣
∣
2
=
3
2
+
4
2
=
5
||z_y||_2=\sqrt{3^2+4^2}=5
∣∣zy∣∣2=32+42=5,使用L2归一化之后
z
y
′
=
[
3
/
5
,
4
/
5
]
z_y'=[3/5,4/5]
zy′=[3/5,4/5],此时计算出来的L2范数为1
所以L2归一化后:
- L2范数为1,既 ∣ ∣ z y ′ ∣ ∣ 2 = 1 ||z_y'||_2=1 ∣∣zy′∣∣2=1
- L2归一化后,就是将各个向量长度或大小标准化为1,从而只保留方向信息
本文正则化遵循SimCLR,其中m表示分类器那边的
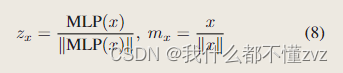
Gaussian Mixture Likelihood Loss
先定义
s
(
x
∣
y
)
=
e
x
p
f
(
x
,
y
)
s(x|y)=expf(x,y)
s(x∣y)=expf(x,y), 其中s表示未归一化的潜在特征的似然(似然 likelihood是指给定观测数据的情况下,计算参数的的函数;而概率是给定参数的情况下,计算事件发生的概率;这里潜在特征的似然就是给定真实标签的情况下,计算潜在特征的函数)
接下来就是使用类似于高斯核密度估计的方法取估计s(x|y),这里s(x|y)可以理解为已知一系列y,求得y下的对x的概率密度,但我们这使用的不是x和y。KDE的核心思想是对于每一个 z y z_y zy,计算其与查询点 z x z_x zx之间的相似度,并用这些相似度的和来估计 s ( x ∣ y ) s(x|y) s(x∣y),也就是似然,也就是概率密度
其中 z x z_x zx表示L2归一化后的队列特征,特征既 f ( w x + θ ) f(wx+\theta) f(wx+θ), Z y Z_y Zy表示L2归一化后的y类的对比特征的集合, τ g \tau_g τg表示GML loss的温度参数。 Z y Z_y Zy的意义就是归一化相似度, Z y Z_y Zy包含的是L2归一化后的不同的 z y z_y zy,所以 z y z_y zy的L2范数为1,但其L1范数可能不是1(不是很明白为什么能归一化)。
−
∣
∣
z
x
−
z
y
∣
∣
2
2
/
(
2
τ
g
)
=
z
x
⋅
z
y
/
τ
g
−
1
/
τ
g
-||z_x-z_y||_2^2/(2\tau_g)=z_x\cdot z_y/\tau_g -1/\tau_g
−∣∣zx−zy∣∣22/(2τg)=zx⋅zy/τg−1/τg
首先计算
z
x
与
z
y
z_x与z_y
zx与zy欧氏距离的平方,
∣
∣
z
x
−
z
y
∣
∣
2
2
=
[
(
∣
z
x
−
z
y
∣
)
2
]
1
2
∗
2
=
∣
∣
z
x
∣
∣
2
+
∣
∣
z
y
∣
∣
2
−
2
z
x
z
y
=
2
−
2
z
x
z
y
||z_x-z_y||_2^2=[(|z_x-z_y|)^2]^{\frac{1}{2}*2}=||z_x||^2+||z_y||^2-2z_xz_y=2-2z_xz_y
∣∣zx−zy∣∣22=[(∣zx−zy∣)2]21∗2=∣∣zx∣∣2+∣∣zy∣∣2−2zxzy=2−2zxzy,上式省略掉后半部分。将计算出来的距离度量代入,并省略掉不必要的部分,根据高斯核密度估计,得到
s
(
x
∣
y
)
=
e
x
p
f
(
x
,
y
)
=
1
∣
∣
Z
y
∣
∣
∑
z
y
∈
Z
y
e
x
p
(
z
x
⋅
z
y
/
τ
g
)
s(x|y)=expf(x,y) =\frac{1}{||Z_y||}\sum_{z_y\in Z_y}exp(z_x\cdot z_y/\tau_g)
s(x∣y)=expf(x,y)=∣∣Zy∣∣1zy∈Zy∑exp(zx⋅zy/τg)
可以比对得到
1
∣
∣
Z
y
∣
∣
\frac{1}{||Z_y||}
∣∣Zy∣∣1和
τ
g
\tau_g
τg分别就是高斯核密度估计中的
1
n
\frac{1}{n}
n1和h的嘴替。
由此可得带回到上面的式子,得到高斯似然损失函数GML

其中
y
y
y类表示对应于潜在特征
z
x
z_x
zx所在的类别,下面的
c
c
c类是所有类别
3.3 Training with GML loss
Class-wise Queues for Contrast Samples
GML loss在每个类别上都需要至少一个样本,那么使用MoCo的方法并不能保证队列中包含了所有类的样本,所以使用multiple class-wise queues,既为每个类别都创建一个队列,然后队列的长度于类频率乘以一个预设的常数呈正比(那么尾类的长度应该小于头类队列长度?常数不可能是负数,长度不为负数)。
这里摆出了一个Eq.6, 是队列最小长度,所有对比样本和所有类别的L1范数和c类的预测概率的一个啥,不明觉厉。

Teacher–Student Strategy
MoCo使用过时的动量编码器生成对比样本传入到queue代替掉旧的对比样本。
本工作中,使用class-wise queue,更新频率应该是和类在训练集的比例成正比的。所以尾类数据的队列应该有更长的更新频率,并且队列中的老样本是通过高度过时的编码器生成的(因为更新频率长所以队列的头的样本是由高度过时的编码器生成的,但是尾类队列不应该很短吗???)。因此提出使用预训练教师编码器来生成对比样本(那样编码器就冻住了?)。
Training Procedure
本工作也可以看作是一个监督工作,所以将预先分类也加入到网络中,同时训练骨干网络和分类器。分类器使用以下损失函数而不用对比损失函数:

总结来说就是:
- 根据类频率计算 η \eta η
- 和余弦相似度分类器一起,使用 L c l s L_{cls} Lcls去训练教师网络(作为一个对比学习特征提取器)
- 使用 L c l s 和 L G M L L_{cls}和L_{GML} Lcls和LGML同时去训练分类器和学习网络
4 Experiments
4.1 数据集
1)ImageNet-LT
2)iNaturalist 2018
3)CIFAR-10-LT and CIFAR-100-LT
4)ADE20K
分割数据集
4.3 Long-tail recongnition

- 使用ResNeXt-50 作为相同的backbone和进行相同epochs的训练,证实了提出的方法的有效性
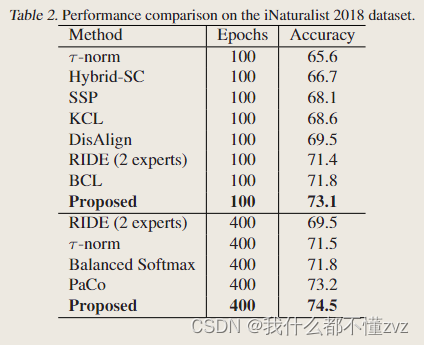
- 使用相同的ResNet50作为backbone
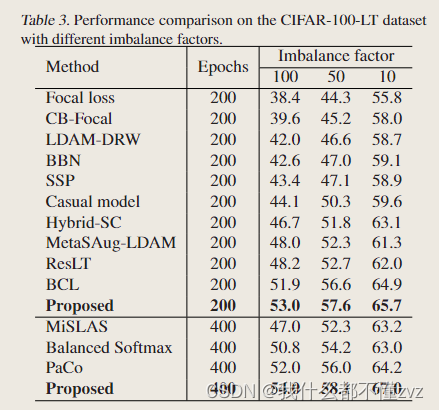
- ResNet-32 作为backbone
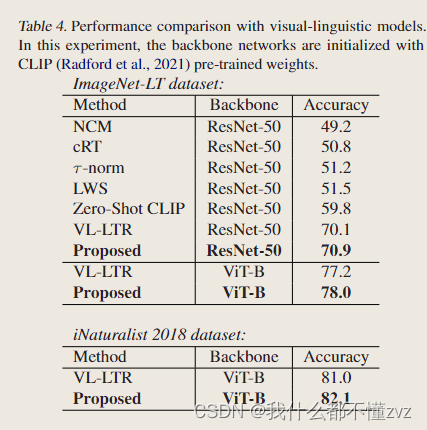
- 和视觉语言模型的对比,使用CLIP的预训练权重
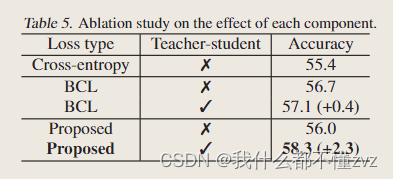
- BCL没有queue,所以是否使用教师学生策略对他来说提升的性能不大
- 教师学生策略对于有队列的提升的性能大,因为解决了过时编码器的问题。
- 提出的损失也是有提升的,但没有教师学生策略提升空间不大。
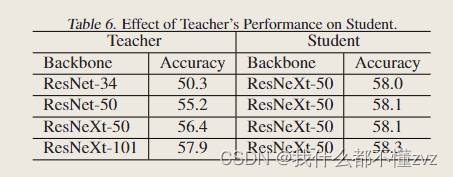
- 四个骨干网络训练相同的epochs(90),可以发现无论教师网络精度如何,都不会影响学生网络
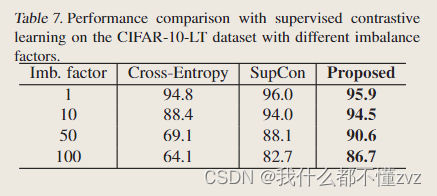
- 随着不平衡因数的提高,监督对比学习也不行
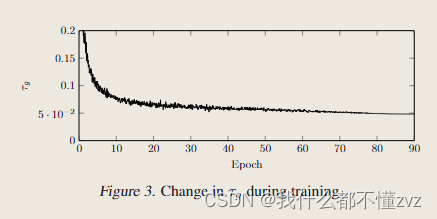
- 可训练温度系数随着训练收敛,也会收敛到0.05,和MoCo的0.07差不多。实验发现这个对模型性能提升帮助不大。















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









