







 本文提出了一种新的理论框架,关注数据重叠对学习影响,通过定义有效样本个数来平衡长尾数据集的损失函数。实验表明,这种方法在CIFAR、ImageNet和iNaturalist等数据集上改善了模型性能,特别是在处理尾类时。
本文提出了一种新的理论框架,关注数据重叠对学习影响,通过定义有效样本个数来平衡长尾数据集的损失函数。实验表明,这种方法在CIFAR、ImageNet和iNaturalist等数据集上改善了模型性能,特别是在处理尾类时。
日期:2023/12/18
论文:Class-Balanced Loss Based on Effective Number of Samples
链接:CBLoss
会议:CVPR2019
目录
1 Abstract
- 在本工作中,发现随着样本数量增多,新增数据附带的benefit可能会有所减少(因为新增数据的features可能与原有数据的features存在重叠关系,加了也白给)
- 提出了一种新的理论框架来衡量数据重叠:将每个样本与小邻域关联而不是与单个样本关联;这里的关键不是去理解什么是小邻域,而是去理解它是如何衡量数据重叠。
- 定义了Effective number of samples: E n = ( 1 − β n ) / ( 1 − β ) E_n=(1-\beta^n)/(1-\beta) En=(1−βn)/(1−β),其中 β ∈ [ 0 , 1 ) \beta\in[0,1) β∈[0,1)是个超参数。使用样本有效个数去re-balance 损失函数。
- 在long-tailed CIFAR, ImageNet, iNaturalist数据集上都表现得很好
2 Introduction
长尾学习中最常见的两种策略就是:1)re-sampling ; 2)re-weighting
- re-sampling分为过采样和欠采样。过采样可能会引入大量重叠的样本,会降低训练并且导致模型过拟合;欠采样可能会导致丢失一些重要的样本,从而在特征学习中学不到什么好东西。
- re-weighting最直观的做法就是根据每个类样本个数的倒数对loss进行一个权值重新分配,但是性能不见得好;随后又提出了更smoothed的方法,用类频率的开方根的倒数来进行权值重新分配 ;不管怎么样,这里的核心问题都是:how can we design a better class-balanced loss that is applicable to a diverse array of datasets?
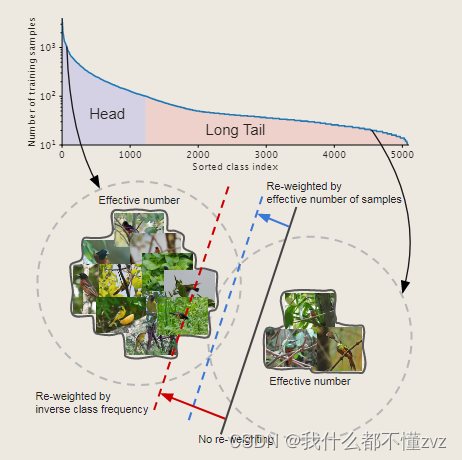
- 黑色实线为no re-weighting的情况,可以发现对于尾类,模型区分困难;
- 红色虚线为使用类频率为倒数re-weighting的情况,可以发现其实它的分类效果也不咋的;
- 蓝色虚线就是使用effective number of samples进行re-weighting的情况,可以发现他能有效区分两个类
通过以上观察可以发现,”数据越多越好“的说法其实是片面的,因为数据之间存在信息重叠,随着样本数据量增加,模型从数据中提取的margin benefit会减少。基于此,本文提出使用有效样本个数作为平衡权重加到损失函数中。值得注意的是,这个方法与模型和损失都是正交的。
3 Effective Number of Samples
3.1 Data sampling as random covering
1) S:特征空间中所有可能的数据集合
2) N:S的体积(N>=1)
类似于random covering problem,每次从S中采样一个数据(该数据被认为是N=1的subset),直到采样到的数据(很多个subset)能表达S为止(coverage of S)。3)expected total volume of sampled data(期望体积):与数据个数有关的值,上界为N
定义1: Effective Number: samples的有效个数等于samples的期望体积

- 为了简化问题,规定:每次采样会有 p 的概率与之前的样本完全重叠;会有1-p的概率与之前的样本完全不重叠
3.2 Mathematical Formulation
公式推导
命题1: Effective Number:
E
n
=
1
−
β
n
1
−
β
,其中
β
=
N
−
1
N
E_n=\frac{1-\beta^n}{1-\beta},其中\beta=\frac{N-1}{N}
En=1−β1−βn,其中β=NN−1
归纳演绎推导以上公式:
1)当n=1时,很明显
E
n
=
1
E_n=1
En=1
2)当n-1时假设成立,当n时,有
p
=
E
n
−
1
/
N
p=E_{n-1}/N
p=En−1/N,这里的
p
p
p是说有这么大的概率可能会抽到与之前数据重叠的数据。则期望体积如下(期望公式
E
=
∑
p
∗
f
(
x
)
E=\sum{p*f(x)}
E=∑p∗f(x),其中f(x)表示可能性)
E
n
=
p
E
n
−
1
+
(
1
−
p
)
(
E
n
−
1
+
1
)
=
1
+
N
−
1
N
E
n
−
1
E_n = pE_{n-1}+(1-p)(E_{n-1}+1)=1+\frac{N-1}{N}E_{n-1}
En=pEn−1+(1−p)(En−1+1)=1+NN−1En−1
公式意思是有p的概率可能重叠,那么期望体积就不变;有1-p的概率不重叠,那么期望体积+1;然后算期望,代入p就得到以上结果。再代入命题1和
β
\beta
β,得
E
n
=
1
−
β
n
1
−
β
E_n = \frac{1-\beta^n}{1-\beta}
En=1−β1−βn
推导结束
理解
E
n
E_n
En,N和
β
\beta
β以及n的关系
根据几何级数(等比数列求和公式哈哈)
E
n
=
1
−
β
n
1
−
β
=
∑
j
=
1
n
β
j
−
1
E_n=\frac{1-\beta^n}{1-\beta}=\sum_{j=1}^n\beta^{j-1}
En=1−β1−βn=j=1∑nβj−1
其中
j
j
j表示第
j
j
j个样本,整个表示第
j
j
j个样本贡献了
β
j
−
1
\beta^{j-1}
βj−1给有效个数。当我们给n极限的时候,有
N
=
lim
n
→
∞
∑
j
=
1
n
β
j
−
1
=
1
1
−
β
N=\lim_{n \to \infty}\sum_{j=1}^n\beta^{j-1}=\frac{1}{1-\beta}
N=n→∞limj=1∑nβj−1=1−β1
所以可以推导
E
n
,
β
和
N
E_n,\beta和N
En,β和N的关系:
- 若 β = 0 \beta=0 β=0也就是N=1,那么 E n = 1 E_n=1 En=1
- 若
β
=
1
\beta=1
β=1也就是
N
→
∞
N\to\infty
N→∞,那么
E
n
→
n
E_n\to n
En→n,这也可以由下面的极限推导求得(大一高数)
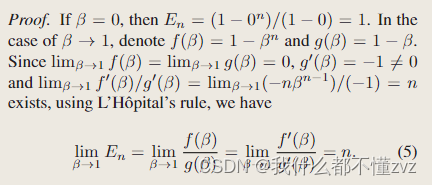
3.3 思考啥意思V1
N N N代表的意义在我看来就是数据集 S S S中有多少个原型(prototype),也就是完全不重叠的数据(or 特征);比如 N = 1 N=1 N=1,说明 S S S中仅有一个原型,那么该数据集中所有数据只用这么一个原型就可以表示。当 N → ∞ N\to\infty N→∞,说明 S S S中有无数个原型(当然不可能),那么该数据集所有数据都是一个独立的原型,所以计算出来的 E n = n E_n=n En=n,说明有效个数有n个(n个数据是原型)
4 Class-Balanced Loss
各种定义如下:
y : label类别, y ∈ { 1 , 2... , C } y\in\{1,2...,C\} y∈{1,2...,C}
x : input输入
p : 模型预测概率 p = [ p 1 , p 2 . . . p c ] T , 且 p i ∈ [ 0 , 1 ] p=[p_1,p_2...p_c]^T,且p_i\in[0,1] p=[p1,p2...pc]T,且pi∈[0,1]
L ( p , y ) L(p,y) L(p,y): 损失函数
对于类别 i 的effective number: E n i = ( 1 − β i n i ) / ( 1 − β i ) E_{n_i}=(1-\beta^{n_i}_i)/(1-\beta_i) Eni=(1−βini)/(1−βi),其中 n i n_i ni是类i的样本个数
这里呢,不同的类都应该是有一个 N i N_i Ni或者说 β i \beta_i βi的,因为不同类的不重叠特征或者说原型肯定不一样嘛,但是经验上来说如果每个类都要设一个难度是非常大的。故本文设置 N i = N , β = ( N − 1 ) / N N_i=N,\beta=(N-1)/N Ni=N,β=(N−1)/N, 也就是让所有类的N都一样。
使用Effective number来re-weighting,通用公式如下:
C
B
(
p
,
y
)
=
1
E
n
y
L
(
p
,
y
)
=
1
−
β
1
−
β
n
y
L
(
p
,
y
)
CB(p,y) = \frac{1}{E_{n_y}}L(p,y)=\frac{1-\beta}{1-\beta^{n_y}}L(p,y)
CB(p,y)=Eny1L(p,y)=1−βny1−βL(p,y)
其中,
n
y
n_y
ny为label y的数据个数
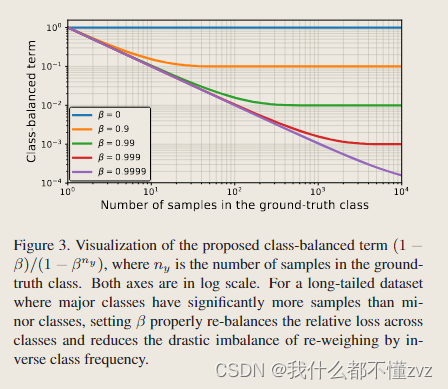
- 由图可见,当 β = 0 \beta=0 β=0的时候就是一个no re-weighting Loss;当 β = 1 \beta=1 β=1的时候,就是使用class frequency作为倒数re-weighting的 Loss。
4.1 CB Softmax CELoss
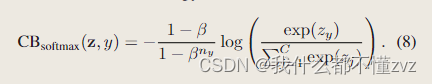
4.2 CB Sigmoid CELoss

4.3 CB Focal Loss
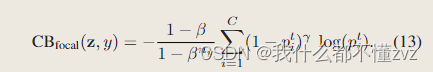
5 Experiment
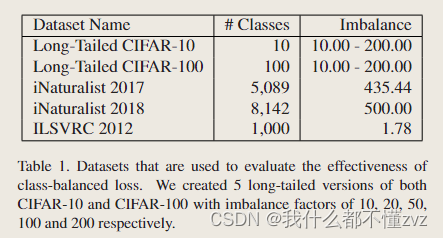
数据集
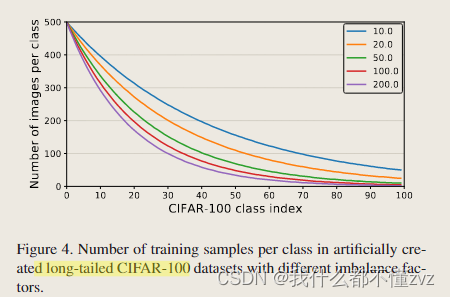
- 不同imbalance factor下的各个类的样本个数
loss比较
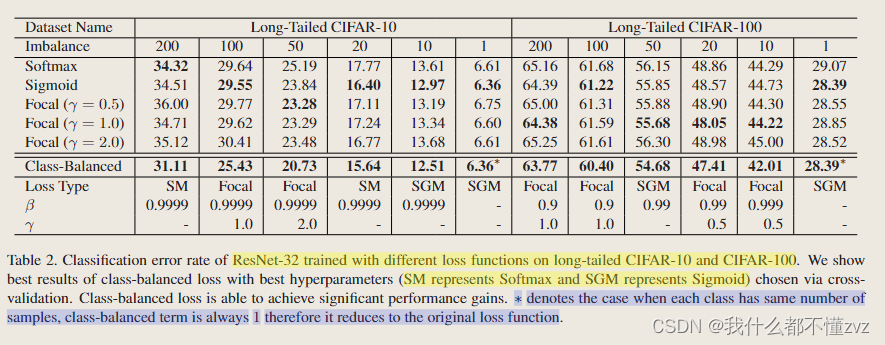
- 加上CB,错误率还是有显著下降的。
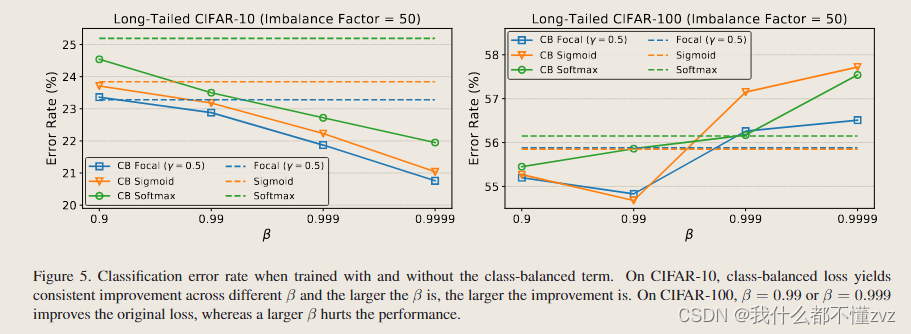
- 探讨不同 β \beta β的影响,左图一直下降可能是因为数据集太简单
有效个数和数据集各个类个数
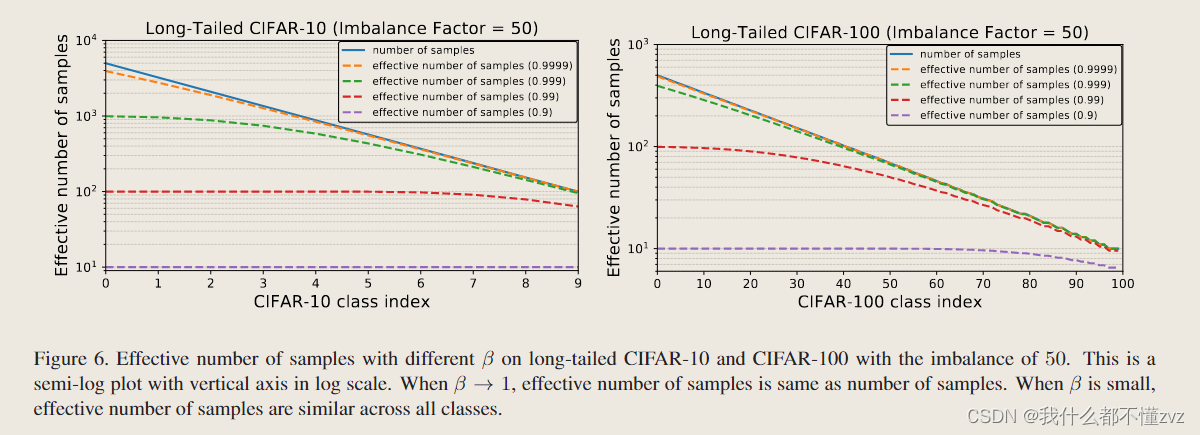
- β = 1 \beta=1 β=1的时候,有效个数相当于各个类的个数; β = 0.9 \beta=0.9 β=0.9其实感觉没多大分出来;
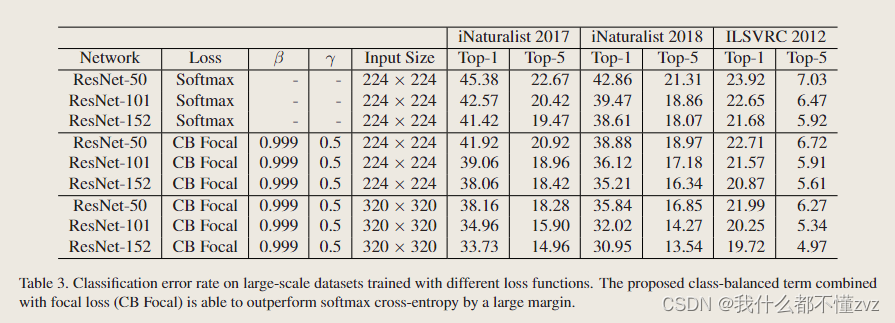
模型、loss和图像尺寸
两类数据集上的训练epochs
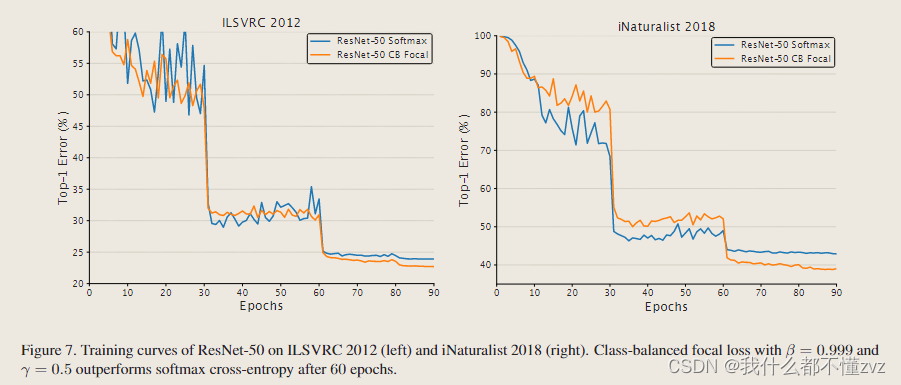
- 收敛速度慢,但是最后还是好一点。速度慢应该就是分配了更多权重给尾类,尾类特征更难学习,而头类其实是有更多特征的。
6 代码
github 参考链接: CBFocal loss

















 4990
4990

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









