







TOC
1 生成模型以及隐变量模型角度理解
(1) 生成模型是什么都东西?
生成模型的一般定义:给定从真实分布 p ( x ) p(x) p(x)采样得到的数据 x ∼ p ( x ) x\sim p(x) x∼p(x),训练得到一个由 θ \theta θ控制逼近真实分布的 p θ ( x ) p_\theta(x) pθ(x),则称 p θ ( x ) p_\theta(x) pθ(x)为生成模型。
(2) 隐变量模型是什么?为什么要用隐变量模型呢?
但实际上我们并不好逼近 p ( x ) p(x) p(x):1)首先是它的分布过于复杂,而神经网络往往只能拟合一些简单分布;2)其次我们也并不清楚 p ( x ) p(x) p(x)到底是什么分布。从 x x x下手不好下手,那么我们可以从更好下手的 z z z下手,我们有 p ( x ) = ∫ p ( x ∣ z ) p ( z ) d z p(x) = \int p(x|z)p(z)dz p(x)=∫p(x∣z)p(z)dz,其中 p ( z ) p(z) p(z)可以是任意我们指定的分布,这样我们就可以通过中间变量,或者说隐变量 z z z去间接求出真实分布了,而这样的模型又叫做隐变量模型。
(3) 如何去度量模型呢?
我们已知 p ( z ) p(z) p(z)【因为是我们自定义的一种分布】,那么只要让神经网络去拟合 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z)即可,度量拟合好坏的指标可以是他们之间的KL散度,既 K L ( p ( x ∣ z ) ∣ ∣ p θ ( x ∣ z ) ) KL(p(x|z)||p_\theta(x|z)) KL(p(x∣z)∣∣pθ(x∣z)),但实际上这个也不好求,因为必须要遍历所有的z,而且并不是所有z都有对应的x的。
根据联合分布
p
(
x
,
z
)
=
p
(
x
∣
z
)
p
(
z
)
p(x,z)=p(x|z)p(z)
p(x,z)=p(x∣z)p(z),我们也可以去求该分布的KL散度,因为
p
(
z
)
p(z)
p(z)是先验分布,所以求该KL散度也等价于拟合了
p
(
x
∣
z
)
p(x|z)
p(x∣z)了。
K
L
(
p
(
x
,
z
)
∣
∣
p
θ
(
x
,
z
)
)
=
∫
∫
p
(
x
,
z
)
l
o
g
p
(
x
,
z
)
p
θ
(
x
,
z
)
d
z
d
x
=
∫
p
(
x
)
∫
p
(
z
∣
x
)
l
o
g
p
(
x
)
p
(
z
∣
x
)
p
θ
(
x
,
z
)
d
z
d
x
=
E
x
∼
p
(
x
)
[
∫
p
(
z
∣
x
)
l
o
g
p
(
x
)
p
(
z
∣
x
)
p
θ
(
x
,
z
)
d
z
]
=
E
x
∼
p
(
x
)
[
l
o
g
p
(
x
)
∫
p
(
z
∣
x
)
d
z
+
∫
p
(
z
∣
x
)
l
o
g
p
(
z
∣
x
)
p
θ
(
x
,
z
)
d
z
]
\begin{aligned} KL(p(x,z)||p_\theta(x,z)) &=\int\int p(x,z)log\frac{p(x,z)}{p_\theta(x,z)}dzdx\\ &= \int p(x)\int p(z|x)log\frac{p(x)p(z|x)}{p_\theta(x,z)}dzdx\\ &= E_{x\sim p(x)}[\int p(z|x)log\frac{p(x)p(z|x)}{p_\theta(x,z)}dz] \\&= E_{x\sim p(x)}[logp(x)\int p(z|x)dz + \int p(z|x)log\frac{p(z|x)}{p_\theta(x,z)}dz] \end{aligned}
KL(p(x,z)∣∣pθ(x,z))=∫∫p(x,z)logpθ(x,z)p(x,z)dzdx=∫p(x)∫p(z∣x)logpθ(x,z)p(x)p(z∣x)dzdx=Ex∼p(x)[∫p(z∣x)logpθ(x,z)p(x)p(z∣x)dz]=Ex∼p(x)[logp(x)∫p(z∣x)dz+∫p(z∣x)logpθ(x,z)p(z∣x)dz]
对于第一项,
∫
p
(
z
∣
x
)
d
z
=
1
\int p(z|x)dz=1
∫p(z∣x)dz=1,所以有
E
x
∼
p
(
x
)
[
l
o
g
p
(
x
)
]
=
C
E_{x\sim p(x)}[logp(x)]=C
Ex∼p(x)[logp(x)]=C(因为p(x)是我们的训练集,相当于固定了,那么求期望当然也是常数)
所以我们有
L
=
K
L
(
p
(
x
,
z
)
∣
∣
p
θ
(
x
,
z
)
)
−
C
=
E
x
∼
p
(
x
)
[
∫
p
(
z
∣
x
)
l
o
g
p
(
z
∣
x
)
p
θ
(
x
,
z
)
d
z
]
L = KL(p(x,z)||p_\theta(x,z))-C=E_{x\sim p(x)}[\int p(z|x)log\frac{p(z|x)}{p_\theta(x,z)}dz]
L=KL(p(x,z)∣∣pθ(x,z))−C=Ex∼p(x)[∫p(z∣x)logpθ(x,z)p(z∣x)dz]
最小化
L
L
L,相当于最小化
K
L
(
p
(
x
,
z
)
∣
∣
p
θ
(
x
,
z
)
)
KL(p(x,z)||p_\theta(x,z))
KL(p(x,z)∣∣pθ(x,z)); 也可以理解为最大化
−
L
-L
−L,那么
−
L
-L
−L被称为变分下限(ELBO)。对
L
L
L再进行推导:
L = E x ∼ p ( x ) [ ∫ p ( z ∣ x ) l o g p ( z ∣ x ) p θ ( x , z ) d z ] = E x ∼ p ( x ) [ ∫ p ( z ∣ x ) l o g p ( z ∣ x ) p ( z ) p θ ( x ∣ z ) d z = E x ∼ p ( x ) [ − ∫ p ( z ∣ x ) l o g p θ ( x ∣ z ) d z + ∫ p ( z ∣ x ) l o g p ( z ∣ x ) p ( z ) d z ] = E x ∼ p ( x ) [ E x ∼ p ( z ∣ x ) [ − l o g p θ ( x ∣ z ) ] ] + E x ∼ p ( x ) [ K L ( p ( z ∣ x ) ∣ ∣ p ( z ) ) ] \begin{aligned} L &= E_{x\sim p(x)}[\int p(z|x)log\frac{p(z|x)}{p_\theta(x,z)}dz] \\ &= E_{x\sim p(x)}[\int p(z|x)log\frac{p(z|x)}{p_(z)p_\theta(x|z)}dz\\ &= E_{x\sim p(x)}[-\int p(z|x)logp_\theta(x|z)dz+ \int p(z|x)log\frac{p(z|x)}{p(z)} dz]\\ &= E_{x\sim p(x)}[E_{x\sim p(z|x)}[-logp_\theta(x|z)]] + E_{x\sim p(x)}[KL(p(z|x)||p(z))] \end{aligned} L=Ex∼p(x)[∫p(z∣x)logpθ(x,z)p(z∣x)dz]=Ex∼p(x)[∫p(z∣x)logp(z)pθ(x∣z)p(z∣x)dz=Ex∼p(x)[−∫p(z∣x)logpθ(x∣z)dz+∫p(z∣x)logp(z)p(z∣x)dz]=Ex∼p(x)[Ex∼p(z∣x)[−logpθ(x∣z)]]+Ex∼p(x)[KL(p(z∣x)∣∣p(z))]
对于第一项,是在最小化对数似然函数 − l o g p θ ( x ∣ z ) -logp_\theta(x|z) −logpθ(x∣z),也就是在最大化 l o g p θ ( x ∣ z ) logp_\theta(x|z) logpθ(x∣z),该似然函数叫做decoder。
对于第二项,可见引入了真实后验分布 p ( z ∣ x ) p(z|x) p(z∣x),并且希望真实后验分布尽可能逼近先验分布 p ( z ) p(z) p(z),这样就能使得采样的 z z z放入decoder中可以更好地生成图像。我们也需要神经网络去拟合 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x),而 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x)又叫encoder。
至此我们有了隐变量模型的大体框架:用神经网络拟合函数 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x)和 p θ ( x ∣ z ) p_\theta(x|z) pθ(x∣z),使得最小化 L L L(也就是最大化对数似然函数 l o g p θ ( x ∣ z ) logp_\theta(x|z) logpθ(x∣z)以及使得先验分布更接近于真实后验分布,这样就能使得先验分布采样的 z z z能和真实的 x x x对应起来)。
(4) 为什么可以用KL散度作为优化目标呢?
实际上KL散度和极大似然估计本质上是等价的,我们再对
−
L
-L
−L进行变形:
−
L
=
C
−
K
L
(
p
(
x
,
z
)
∣
∣
p
θ
(
x
,
z
)
)
=
E
x
∼
p
(
x
)
[
∫
p
(
z
∣
x
)
l
o
g
p
θ
(
x
,
z
)
p
(
z
∣
x
)
d
z
]
=
E
x
∼
p
(
x
)
[
∫
p
(
z
∣
x
)
l
o
g
p
θ
(
x
)
p
θ
(
z
∣
x
)
p
(
z
∣
x
)
d
z
]
=
E
x
∼
p
(
x
)
[
l
o
g
p
θ
(
x
)
]
−
K
L
(
p
(
z
∣
x
)
∣
∣
p
θ
(
z
∣
x
)
)
\begin{aligned} -L &= C-KL(p(x,z)||p_\theta(x,z))\\ &= E_{x\sim p(x)}[\int p(z|x)log\frac{p_\theta(x,z)}{p(z|x)}dz]\\ &= E_{x\sim p(x)}[\int p(z|x)log\frac{p_\theta(x)p_\theta(z|x)}{p(z|x)}dz]\\ &= E_{x\sim p(x)}[logp_\theta(x)] -KL(p(z|x)||p_\theta(z|x)) \end{aligned}
−L=C−KL(p(x,z)∣∣pθ(x,z))=Ex∼p(x)[∫p(z∣x)logp(z∣x)pθ(x,z)dz]=Ex∼p(x)[∫p(z∣x)logp(z∣x)pθ(x)pθ(z∣x)dz]=Ex∼p(x)[logpθ(x)]−KL(p(z∣x)∣∣pθ(z∣x))
第一项就是对数似然,而第二项是大于等于0的数,所以对数似然大于等于变分下限 − L -L −L。严格来说,该KL散度不可能取到0,因为对变分下限优化的目的是让 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x)与 p ( z ) p(z) p(z)相近,而 p ( z ∣ x ) p(z|x) p(z∣x)与 p ( z ) p(z) p(z)再形式上不宜与,所以后面的VAE或者扩散模型,损失函数是没有办法真的训练一个最大似然的。
(5)学习过程中比较懵逼的地方
模型优化的目标之一是 p θ ( z ∣ x ) p_\theta(z|x) pθ(z∣x)与 p ( z ) p(z) p(z)更接近,为什么上面的优化公式没有体现呢?或者体现在哪个地方我没看出来。
解释如下:

2 自编码器AE
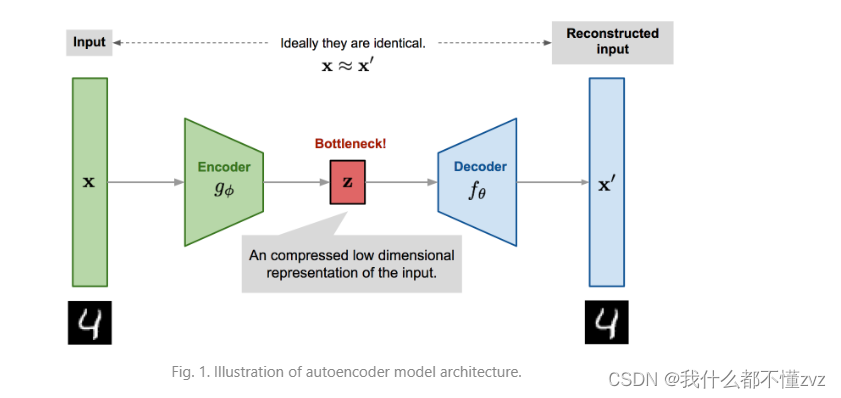
2.1 简单理解AE
通过encoder对数据的维度进行压缩,然后通过decoder升维,得到 x ′ x' x′, x ′ x' x′存在的价值就是试图让他和 x x x相同,那么我们便可以理解为encoder压缩提取的特征真的是最本质的特征。
简单用MSE Loss来构成重建损失:
L
A
E
(
θ
,
ϕ
)
=
1
n
∑
i
=
1
n
(
x
i
−
f
(
g
(
x
i
)
)
)
2
L_{AE}(\theta,\phi)=\frac{1}{n}\sum_{i=1}^n(x_i-f(g(x_i)))^2
LAE(θ,ϕ)=n1i=1∑n(xi−f(g(xi)))2
2.2 概率角度理解AE
AE的思想就是隐变量 z z z和 x x x能唯一对应,编码器和解码器的降维和升维相当于高维空间和低维流形之间的映射,属于单隐变量模型(diffusion是多隐变量模型),且隐变量空间连续。
因为唯一对应,所以我们可以认为真实后验分布 p ( z ∣ x ) = δ ( z − C ( x ) ) p(z|x)=\delta(z-C(x)) p(z∣x)=δ(z−C(x)), 右式是狄拉克函数,这里的含义是 z z z和 C ( x ) C(x) C(x)唯一对应, C C C即为编码器encoder。 C θ ( x ) C_\theta(x) Cθ(x)可以以很简单的用神经网络拟合。
关于似然函数用神经网络去拟合高斯分布 p θ ( x ∣ z ) = N ( G θ ( z ) , σ 2 ) p_\theta(x|z)=N(G_\theta(z),\sigma^2) pθ(x∣z)=N(Gθ(z),σ2), G G G为decoder,方差设置为定值,所以最后我们用输出的均值替代输出 x x x,也就解决了采样问题。
由第一部分我们可以得到 L = E x ∼ p ( x ) [ E x ∼ p ( z ∣ x ) [ − l o g p θ ( x ∣ z ) ] ] + E x ∼ p ( x ) [ K L ( p ( z ∣ x ) ∣ ∣ p ( z ) ) ] L=E_{x\sim p(x)}[E_{x\sim p(z|x)}[-logp_\theta(x|z)]] + E_{x\sim p(x)}[KL(p(z|x)||p(z))] L=Ex∼p(x)[Ex∼p(z∣x)[−logpθ(x∣z)]]+Ex∼p(x)[KL(p(z∣x)∣∣p(z))]
第一项可以化简为均方根误差
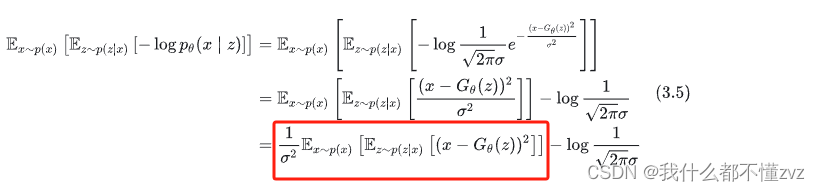
而第二项可以化简为一个与
x
,
θ
x,\theta
x,θ无关的常数

3 变分自编码器VAE
Auto-Encoder的思想是
x
x
x和
z
z
z是唯一对应的,但生成的本质实际上是一个分布映射到另一个分布,我们不可能将分布里的所有数据点都一一对应上,所以就会出现下面这张图出现的情况(李宏毅ML18讲),当分布中某一个点没有对应到观测样本,并且我们的模型通常都不是线性的,所以很多地方其实是不可知会生成什么图像的。
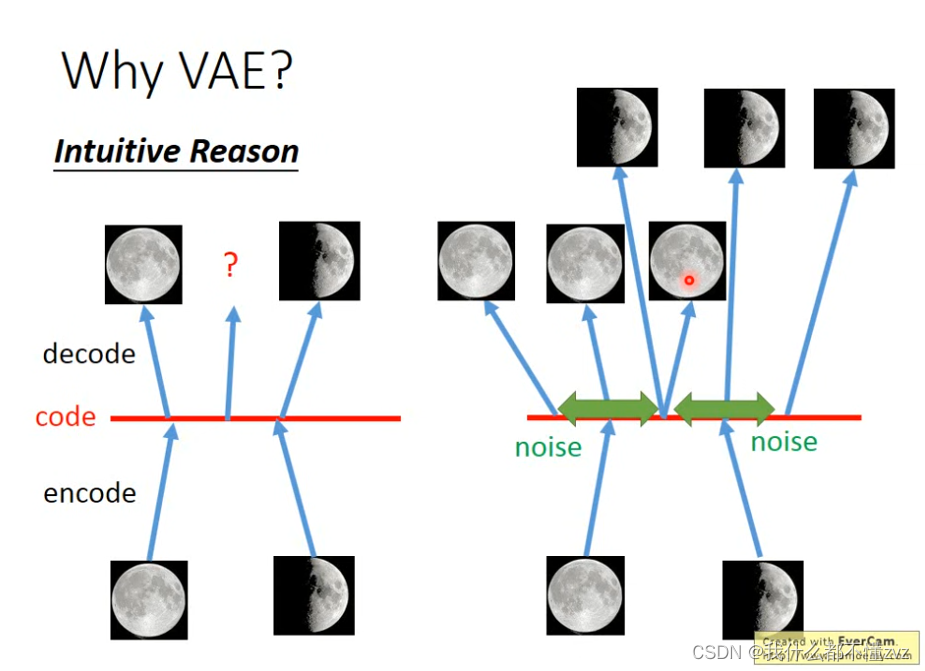
3.1 理解VAE
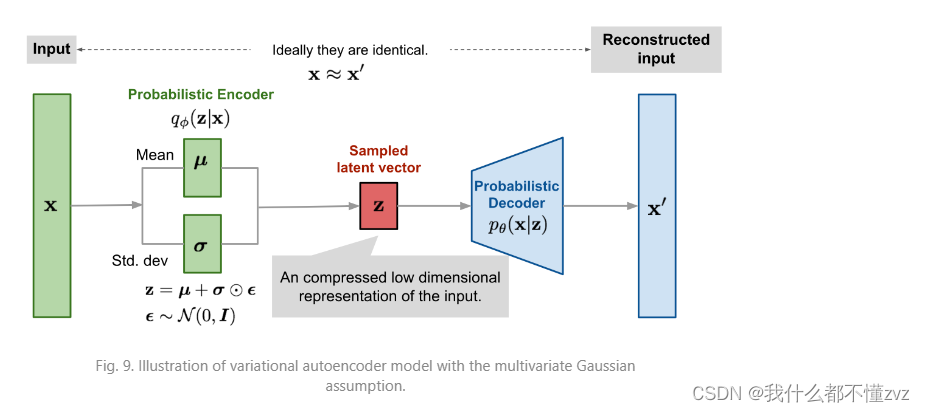
1) VAE和AE的不同点是什么?
VAE则是加上了一层噪声,使得噪声的分布内都能生成同一张图像,这样原本没有对应上的点此时会变成两个分布的重叠部分,生成的图像则会根据两个重叠程度生成合理的图。更本质的理解就是,VAE中每个 x x x对应着随机变量 z z z,也就是对应着一个分布而不是对应确定值。
2) VAE两种不同视角
若根据混合高斯模型理论,任意复杂的分布 p ( x ) p(x) p(x)均可以由多个高斯分布去进行拟合,既 p ( x ) = ∫ z p ( z ) p ( x ∣ z ) d z p(x)=\int_z p(z)p(x|z)dz p(x)=∫zp(z)p(x∣z)dz , 其中 p ( z ) p(z) p(z)可以理解为对应的高斯分布的权值, p ( x ∣ z ) p(x|z) p(x∣z)理解为该 z z z的条件下,对应的高斯分布。
若根据隐变量模型, z z z为隐变量,则 p ( x ) p(x) p(x)可以通过边际化联合概率求得,既 p ( x ) = ∫ z p ( x , z ) d z p(x)=\int_zp(x,z)dz p(x)=∫zp(x,z)dz,再由乘法公式 p ( x , z ) = p ( x ) p ( z ∣ x ) = p ( z ) p ( x ∣ z ) p(x,z)=p(x)p(z|x)=p(z)p(x|z) p(x,z)=p(x)p(z∣x)=p(z)p(x∣z)代入。
我们的目标是最大化似然函数 ∑ i = 1 N l o g p ( x ) = ∑ i = 1 N l o g ∫ z p ( x , z ) d z \sum_{i=1}^Nlogp(x)=\sum_{i=1}^Nlog\int_zp(x,z)dz ∑i=1Nlogp(x)=∑i=1Nlog∫zp(x,z)dz,但积分是很难求的。但我们可以用更简单的形式去等价替代。
3.1.1 证据下界(Evidence Lower Bound, ELBO)
ELBO的名字来源是因为 p ( x ) p(x) p(x)在贝叶斯公式里 p ( z ∣ x ) = p ( x ∣ z ) p ( z ) p ( x ) p(z|x)=\frac{p(x|z)p(z)}{p(x)} p(z∣x)=p(x)p(x∣z)p(z)是证据(evidence),所以叫ELBO。 首先要明确的是: encoder用 q ϕ q_\phi qϕ表示,decoder用 p θ p_\theta pθ表示, q ϕ ( z ) q_\phi(z) qϕ(z)记为 z z z的概率密度函数。
我们推导:
l
o
g
p
(
x
)
=
l
o
g
∫
z
p
θ
(
x
,
z
)
d
z
=
l
o
g
∫
z
q
ϕ
(
z
)
p
θ
(
x
,
z
)
q
ϕ
(
z
)
d
z
=
l
o
g
E
z
∼
q
ϕ
(
z
)
[
p
θ
(
x
,
z
)
q
ϕ
(
z
)
]
≥
E
z
∼
q
ϕ
(
z
)
[
l
o
g
p
θ
(
x
,
z
)
q
ϕ
(
z
)
]
=
∫
z
q
ϕ
(
z
)
l
o
g
p
θ
(
x
,
z
)
d
z
−
∫
z
q
ϕ
(
z
)
l
o
g
q
ϕ
(
z
)
d
z
=
E
z
∼
q
ϕ
(
z
)
[
l
o
g
p
θ
(
x
,
z
)
]
−
E
z
∼
q
ϕ
(
z
)
[
l
o
g
q
ϕ
(
z
)
]
=
L
(
q
,
θ
)
\begin{aligned} logp(x) &= log\int_zp_\theta(x,z)dz\\ &=log\int_zq_\phi(z)\frac{p_\theta(x,z)}{q_\phi(z)}dz\\ &=logE_{z\sim q_\phi(z)}[\frac{p_\theta(x,z)}{q_\phi(z)}]\\ &\geq E_{z\sim q_\phi(z)}[log\frac{p_\theta(x,z)}{q_\phi(z)}]\\ &=\int_zq_\phi(z)logp_\theta(x,z)dz-\int_zq_\phi(z)logq_\phi(z)dz\\ &= E_{z\sim q_\phi(z)}[logp_\theta(x,z)] - E_{z\sim q_\phi(z)}[logq_\phi(z)]\\ &= L(q,\theta) \end{aligned}
logp(x)=log∫zpθ(x,z)dz=log∫zqϕ(z)qϕ(z)pθ(x,z)dz=logEz∼qϕ(z)[qϕ(z)pθ(x,z)]≥Ez∼qϕ(z)[logqϕ(z)pθ(x,z)]=∫zqϕ(z)logpθ(x,z)dz−∫zqϕ(z)logqϕ(z)dz=Ez∼qϕ(z)[logpθ(x,z)]−Ez∼qϕ(z)[logqϕ(z)]=L(q,θ)
其中不等式是根据詹森不等式(琴生不等式)推导出来的,这样我们就可以得到ELBO,记为
L
(
q
,
θ
)
L(q,\theta)
L(q,θ)
由前面的乘法公式,我们可得联合分布有两种表达形式,既
p
(
x
,
z
)
=
p
(
x
)
p
(
z
∣
x
)
=
p
(
z
)
p
(
x
∣
z
)
p(x,z)=p(x)p(z|x)=p(z)p(x|z)
p(x,z)=p(x)p(z∣x)=p(z)p(x∣z)
p
(
z
)
,
p
(
z
∣
x
)
p(z),p(z|x)
p(z),p(z∣x)分别为z的先验和后验概率
先代入第一种形式
p
(
x
,
z
)
=
p
(
x
)
p
(
z
∣
x
)
p(x,z)=p(x)p(z|x)
p(x,z)=p(x)p(z∣x)(省略期望下标
z
∼
q
ϕ
(
z
)
z\sim q_\phi(z)
z∼qϕ(z)):
L
(
q
,
θ
)
=
E
[
l
o
g
p
(
x
)
]
+
E
[
l
o
g
p
θ
(
z
∣
x
)
]
−
E
[
l
o
g
q
ϕ
(
z
)
]
=
E
[
l
o
g
p
(
x
)
]
−
K
L
(
q
ϕ
(
z
)
∣
∣
p
θ
(
z
∣
x
)
)
=
l
o
g
p
(
x
)
−
K
L
(
q
ϕ
(
z
)
∣
∣
p
θ
(
z
∣
x
)
)
\begin{aligned} L(q,\theta) &= E[logp(x)]+E[logp_\theta(z|x)]-E[logq_\phi(z)] \\ &=E[logp(x)] - KL(q_\phi(z)||p_\theta(z|x))\\ &= logp(x) - KL(q_\phi(z)||p_\theta(z|x)) \end{aligned}
L(q,θ)=E[logp(x)]+E[logpθ(z∣x)]−E[logqϕ(z)]=E[logp(x)]−KL(qϕ(z)∣∣pθ(z∣x))=logp(x)−KL(qϕ(z)∣∣pθ(z∣x))
第一项由于
p
θ
(
x
)
p_\theta(x)
pθ(x)与隐变量
z
z
z无关所以可以省略掉期望,由第一项得,这里是最大化对数似然; 由第二项得,这里是最小化
q
ϕ
(
z
)
q_\phi(z)
qϕ(z)和
p
θ
(
z
∣
x
)
p_\theta(z|x)
pθ(z∣x)的KL散度,也就是
l
o
g
p
(
x
)
=
L
(
q
,
θ
)
+
K
L
(
q
ϕ
(
z
)
∣
∣
p
θ
(
z
∣
x
)
)
logp(x)=L(q,\theta)+KL(q_\phi(z)||p_\theta(z|x))
logp(x)=L(q,θ)+KL(qϕ(z)∣∣pθ(z∣x))
只要我们能够将后验
p
θ
(
z
∣
x
)
p_\theta(z|x)
pθ(z∣x)和
q
ϕ
(
z
)
q_\phi(z)
qϕ(z)互相逼近,那么证据下界也就等价于似然函数,那么最大化ELBO等价于最大化似然函数。
我们代入第二种形式
由以上可知,当
p
θ
(
z
∣
x
)
p_\theta(z|x)
pθ(z∣x)和
q
ϕ
(
z
)
q_\phi(z)
qϕ(z)互相逼近时,ELBO等价于似然函数,所以我们这里设
q
ϕ
(
z
)
=
q
ϕ
(
z
∣
x
)
=
p
θ
(
z
∣
x
)
q_\phi(z)=q_\phi(z|x)=p_\theta(z|x)
qϕ(z)=qϕ(z∣x)=pθ(z∣x) (为了区分所以设置为
q
(
z
∣
x
)
q(z|x)
q(z∣x))
L
(
q
,
θ
)
=
E
[
l
o
g
p
(
z
)
]
+
E
[
l
o
g
p
θ
(
x
∣
z
)
]
−
E
[
l
o
g
q
(
z
)
]
=
E
[
l
o
g
p
(
z
)
]
+
E
[
l
o
g
p
θ
(
x
∣
z
)
]
−
E
[
l
o
g
q
ϕ
(
z
∣
x
)
]
=
E
[
l
o
g
p
θ
(
x
∣
z
)
]
−
K
L
(
q
ϕ
(
z
∣
x
)
∣
∣
p
(
z
)
)
\begin{aligned} L(q,\theta) &= E[logp(z)]+E[logp_\theta(x|z)]-E[logq(z)]\\ &= E[logp(z)]+E[logp_\theta(x|z)]-E[logq_\phi(z|x)]\\ &= E[logp_\theta(x|z)]- KL(q_\phi(z|x)||p(z)) \end{aligned}
L(q,θ)=E[logp(z)]+E[logpθ(x∣z)]−E[logq(z)]=E[logp(z)]+E[logpθ(x∣z)]−E[logqϕ(z∣x)]=E[logpθ(x∣z)]−KL(qϕ(z∣x)∣∣p(z))
第一项,
p
θ
(
x
∣
z
)
p_\theta(x|z)
pθ(x∣z)可以看作时由
z
z
z生成
x
x
x,也就是decoder; 由于
z
z
z为随机变量(某种分布),所以需要对
z
z
z求期望,而求期望则需要用到后验
q
(
z
∣
x
)
q(z|x)
q(z∣x),后验相当于encoder;
第二项,是
q
ϕ
(
z
∣
x
)
q_\phi(z|x)
qϕ(z∣x)和
p
(
z
)
p(z)
p(z)的KL散度,KL散度大于等于0,而这里要最大化ELBO,所以要最小化KL散度,也就是让这两个分布更接近,这里相当于约束项。
代入的两项可以得到的信息
由代入后验
p
θ
(
x
∣
z
)
p_\theta(x|z)
pθ(x∣z)我们可以得知,我们可以用最大化ELBO来代替最大化似然函数,前提是
K
L
(
q
ϕ
(
z
)
∣
∣
p
θ
(
z
∣
x
)
)
→
0
KL(q_\phi(z)||p_\theta(z|x))\rightarrow 0
KL(qϕ(z)∣∣pθ(z∣x))→0,也就是z的概率密度函数和z的后验概率相近。
由代入条件概率
p
θ
(
z
∣
x
)
p_\theta(z|x)
pθ(z∣x)我们可以得知,ELBO包含了
p
θ
(
x
∣
z
)
p_\theta(x|z)
pθ(x∣z)以及
q
ϕ
(
z
∣
x
)
q_\phi(z|x)
qϕ(z∣x),且有约束项
K
L
(
q
ϕ
(
z
∣
x
)
∣
∣
p
(
z
)
)
KL(q_\phi(z|x)||p(z))
KL(qϕ(z∣x)∣∣p(z))来使得上面的前提成立,也就是z的概率密度函数和z的先验密度相近,此处z的概率密度函数等同于z的后验概率,也就是确保确定值
x
x
x通过神经网络后计算出来的随机变量
z
z
z所处的分布,和先验分布
p
(
z
)
p(z)
p(z)等价,这样由
z
z
z生成
x
x
x就确保真实。
3.1.2 Encoder和Decoder
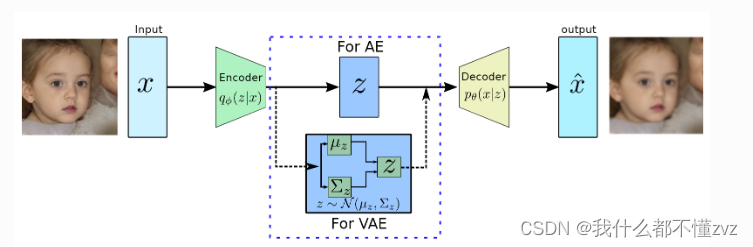
z
z
z是一个随机变量,在VAE中假设
z
z
z服从高斯分布,既先验
P
(
Z
)
∼
N
(
0
,
1
)
P(Z)\sim N(0,1)
P(Z)∼N(0,1)
3.1.2.1 Encoder
既然
p
(
z
)
p(z)
p(z)服从高斯分布,那么后验
q
ϕ
(
z
∣
x
)
q_\phi(z|x)
qϕ(z∣x)也服从高斯分布,但均值和方差
μ
ϕ
,
Σ
ϕ
\mu_\phi,\Sigma_\phi
μϕ,Σϕ是未知的。 且
Z
Z
Z是一个随机变量,不能由确定变量
x
x
x直接通过神经网络预测得到,所以通过预测均值和方差间接预测随机变量
z
z
z。既
μ
ϕ
(
x
)
=
e
n
c
o
d
e
r
(
x
)
Σ
ϕ
(
x
)
=
e
n
c
o
d
e
r
(
x
)
\mu_\phi(x)=encoder(x)\\ \Sigma_\phi(x) = encoder(x)
μϕ(x)=encoder(x)Σϕ(x)=encoder(x)
那么如何衡量两者的好坏呢?预测均值和方差相当于预测分布,所以使用KL散度来衡量好坏,且两个高斯分布的KL散度是有已知公式的,如下
K
L
(
N
(
μ
ϕ
,
Σ
ϕ
)
∣
∣
N
(
0
,
1
)
)
=
1
2
(
σ
ϕ
2
+
μ
ϕ
−
1
−
l
o
g
σ
ϕ
2
)
KL(N(\mu_\phi,\Sigma_\phi)||N(0,1))=\frac{1}{2}(\sigma_\phi^2+\mu_\phi-1-log\sigma^2_\phi)
KL(N(μϕ,Σϕ)∣∣N(0,1))=21(σϕ2+μϕ−1−logσϕ2)
直觉上理解就是,当均值为0,方差为1时,此项会最小,所以约束其方差为1。
3.1.2.1 Decoder
条件概率
p
θ
(
x
∣
z
)
p_\theta(x|z)
pθ(x∣z)是从随机变量
z
z
z通过decoder生成随机变量
x
x
x,同理随机变量是不可以直接生成的,所以也通过让神经网络预测均值和方差的方法,只不过这里将方差设置为一个常数(大多数方法也会如此实现),所以只是预测均值即可。既
μ
σ
=
d
e
c
o
d
e
r
(
z
)
\mu_\sigma=decoder(z)
μσ=decoder(z)
但是这个期望是没有办法直接解析求得的,因为后验概率
q
ϕ
(
z
∣
x
)
q_\phi(z|x)
qϕ(z∣x)有一个神经网络的存在,而求期望就是求积分。但可以通过马尔可夫链方式求解近似,就是从后验概率分布随机采样很多个
z
z
z代入求均值,既
E
z
∼
q
ϕ
(
z
∣
x
)
[
l
o
g
p
θ
(
x
∣
z
)
]
=
1
L
∑
i
=
1
L
[
l
o
g
p
θ
(
x
∣
z
i
)
]
E_{z\sim q_\phi(z|x)}[log p_\theta(x|z)] = \frac{1}{L}\sum_{i=1}^L[logp_\theta(x|z^i)]
Ez∼qϕ(z∣x)[logpθ(x∣z)]=L1i=1∑L[logpθ(x∣zi)]
L
L
L为超参数,根据经验这里设置为1,但是
z
z
z的采样也是一个随机过程,既
z
∼
N
(
μ
ϕ
,
Σ
ϕ
)
z\sim N(\mu_\phi,\Sigma_\phi)
z∼N(μϕ,Σϕ),是不可导的(因为同一个输入可能有不同输出),所以VAE作者这里使用参数重整化的方法,从
N
(
0
,
1
)
N(0,1)
N(0,1)采样标准高斯噪声, 然后通过神经网络预测均值和方差,将噪声乘以方差的开根,再加上均值,得到
z
z
z。
3.1.3 汇总
根据高斯公式:
p
θ
(
x
∣
z
)
=
−
1
2
e
x
p
(
(
x
−
μ
θ
)
2
)
\begin{aligned} p_\theta(x|z) &= -\frac{1}{2}exp((x-\mu_\theta)^2) \end{aligned}
pθ(x∣z)=−21exp((x−μθ)2)
所以ELBO公式有:
L
(
p
,
θ
)
=
E
[
l
o
g
p
θ
(
x
∣
z
)
]
−
K
L
(
q
ϕ
(
z
∣
x
)
∣
∣
p
(
z
)
)
=
−
1
L
∑
i
=
1
L
(
x
−
μ
θ
)
2
−
(
σ
ϕ
2
+
μ
ϕ
−
1
−
l
o
g
σ
ϕ
2
)
\begin{aligned} L(p,\theta) &= E[logp_\theta(x|z)]- KL(q_\phi(z|x)||p(z))\\ &= -\frac{1}{L}\sum_{i=1}^L(x-\mu_\theta)^2-(\sigma_\phi^2+\mu_\phi-1-log\sigma^2_\phi) \end{aligned}
L(p,θ)=E[logpθ(x∣z)]−KL(qϕ(z∣x)∣∣p(z))=−L1i=1∑L(x−μθ)2−(σϕ2+μϕ−1−logσϕ2)
3.2 概率角度理解
VAE认为一个 x x x对应一个分布,这个分布又能采样一个点生成 z z z,然后通过解码器生成 x x x。设先验分布标准高斯分布 N ( 0 , I ) N(0,I) N(0,I),真实后验分布为 p ( z ∣ x ) = N ( μ , σ 2 ) p(z|x) =N(\mu,\sigma^2) p(z∣x)=N(μ,σ2)的高斯分布,其中 μ = C ( x ) \mu=C(x) μ=C(x),其中 C C C为encoder,用神经网络拟合就是 p θ ( z ∣ x ) = N ( C θ ( x ) , σ 2 ) p_\theta(z|x)=N(C_\theta(x),\sigma^2) pθ(z∣x)=N(Cθ(x),σ2)。
又回到之前推导的公式 L = E x ∼ p ( x ) [ E x ∼ p ( z ∣ x ) [ − l o g p θ ( x ∣ z ) ] ] + E x ∼ p ( x ) [ K L ( p ( z ∣ x ) ∣ ∣ p ( z ) ) ] L=E_{x\sim p(x)}[E_{x\sim p(z|x)}[-logp_\theta(x|z)]] + E_{x\sim p(x)}[KL(p(z|x)||p(z))] L=Ex∼p(x)[Ex∼p(z∣x)[−logpθ(x∣z)]]+Ex∼p(x)[KL(p(z∣x)∣∣p(z))]
第一项的推导和之前一样可以推导为均方根误差
第二项的推导为:
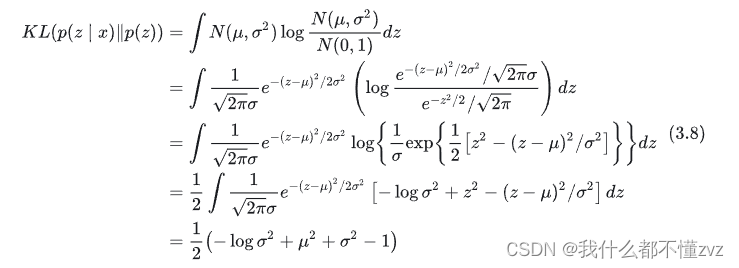
这也是3.1 给出的那个约束的loss。
所以AE和VAE的区别就是后验分布和先验分布的假设,AE是将后验分布假设为
p
(
z
∣
x
)
=
δ
(
z
−
C
(
x
)
)
p(z|x)=\delta(z-C(x))
p(z∣x)=δ(z−C(x)),且将先验分布假设为
p
(
z
)
=
1
D
p(z)=\frac{1}{D}
p(z)=D1。 VAE则假设为高斯分布(实际上会使用重参数技巧,采样自正态分布)

4 VQVAE
参考:
[1] https://lilianweng.github.io/posts/2018-08-12-vae/
[2] https://zhuanlan.zhihu.com/p/640000410
[3] https://github.com/SingleZombie/DL-Demos/tree/master/dldemos/VQVAE
[4] https://www.spaces.ac.cn/archives/6760
[5] https://zhuanlan.zhihu.com/p/633744455
4.1 AE、VAE和VQVAE
已知AE由输入 x x x,经过encoder得到确定值 z z z,再经过decoder还原 x ′ x' x′, x 、 z x、z x、z是一一对应的,所以严格来说,AE并不是生成模型,而是一个数据压缩模型。AE无法做到生成任务是因为 z z z的分布是不规则的(既我们不能知道 z z z服从什么分布)。
VAE就是对AE的一种改进,通过约束 z z z满足正态分布,这样解码器就认得编码器编码出的向量,也就能实现生成任务。注意,AE和VAE生成的都是连续变量。
VAE生成的图像质量并不高,VQVAE的作者认为VAE不好的原因是因为编码器生成的连续变量,而如果生成的是离散变量那么生成的图像质量会更好。比如画一个人,他是男(0)或者是女(1),我们可以用离散的向量进行编码,而不是连续向量(0.7为男,0.3为女)。
VQVAE采用NLP里的embedding的思想,embedding可以看作是特殊的连续向量,将编码器输出的变量 z z z与嵌入空间(embedding space, codebook)使用K最邻近算法(距离使用均方根差,然后使用argmin找到与该向量距离最小的索引)找出最接近的嵌入向量索引,然后根据索引用该嵌入向量替代原来的编码器的输出。
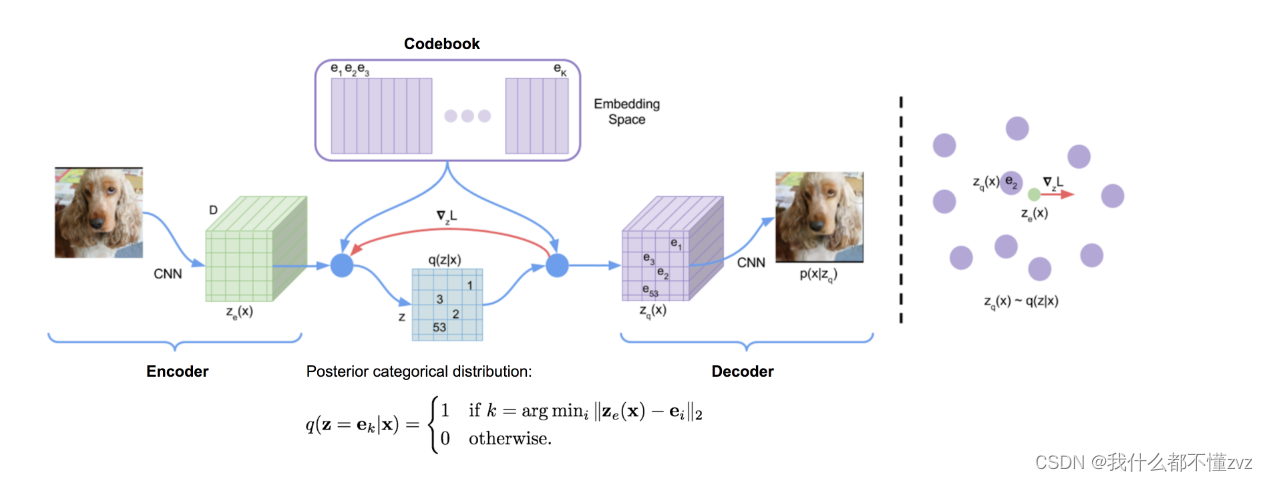
现有的问题就是:
- VAE约束 z z z满足正态分布形式,VQVAE又尝试将 z z z离散化,这样又会丢失掉编码空间的规范性,而离散化变量是不容易采样的,离散化后VQVAE不就不能生成图像了嘛?素嘟,VQVAE实际上是一个AE,只不过其编码出来的是离散的变量,VQVAE不是一个生成模型,他是一个图像压缩模型,而生成模型是其他的生成模型(pixelCNN、diffussion(构成stabe diffusion)等)
现在尝试理解以下问题:
- 如何输出离散变量?
- 如何优化encoder、decoder?
- 如何优化codebook(不是fixed,而是trainable的)
4.2 输出离散变量
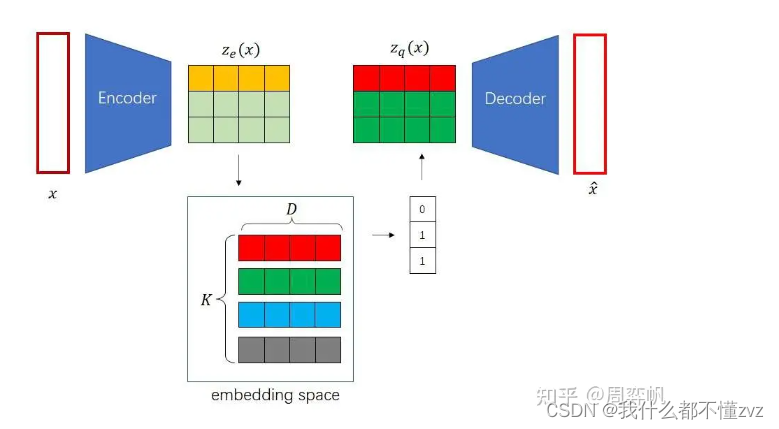
假设输入 x x x为 [B,C,N,N], 编码器encoder的输出 z z z为 [B,D,M,M] , codebook的尺寸为 [K,D],表示有K个嵌入向量,每个嵌入向量的维度为D。在计算距离时,先让 z z z和codebook扩维(好使用广播机制),既让 z z z 变为 [B,1,D,M,M], 而 codebook变为 [1,K,D,1,1], 然后使用均方根差计算距离,并在第二维(K)使用argmin 找到每个 z z z 对应嵌入向量最小距离的索引,然后得到索引之后我们就可以找到codebook中替代原编码输出的 z q z_q zq了。索引的尺寸为 [B,M,M] 既每个输出都对应一个嵌入向量索引,少了D维是因为这就是嵌入向量的深度。所以 z q z_q zq的尺寸为 [B,D,M,M]
4.3 优化encoder和decoder
argmin是一个离散的操作,所以是不可导的。在AE中,我们的reconstrucion loss为:
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
)
∣
∣
2
L = || x- decoder(z)||^2
L=∣∣x−decoder(z)∣∣2
VQVAE中变为:
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
p
)
∣
∣
2
L = ||x-decoder(z_p)||^2
L=∣∣x−decoder(zp)∣∣2
而这项损失的梯度是不能传导到encoder的,因为
z
z
z到
z
p
z_p
zp之间的变化是离散的。
VQVAE这里使用一种叫Straight-Through Estimator的方法,既设计函数:
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
−
s
g
(
z
p
−
z
)
)
∣
∣
2
L = ||x-decoder(z-sg(z_p - z))||^2
L=∣∣x−decoder(z−sg(zp−z))∣∣2
sg表示stop-gradient函数,在前向传播时为sg(x)=x,在反向传播时为0,也就是前向传播还是这么用,反向传播就用了,直接把求得的梯度去给encoder使用。
所以前向传播时:
x
−
d
e
c
o
d
e
r
(
z
p
)
x-decoder(z_p)
x−decoder(zp) , 反向传播时
L
=
∣
∣
x
−
d
e
c
o
d
e
r
(
z
)
∣
∣
2
L=||x-decoder(z)||^2
L=∣∣x−decoder(z)∣∣2
在pytorch中很容易实现:
l = x - decoder(z - (zp-z).detach())
4.4 优化codebook
由前面提到,codebook也是可训练的,那么codebook优化的目标是什么呢? codebook优化的目标应该是: 尽可能使得codebook中的每一个嵌入向量都能尽可能表示编码器输出的每一类。比如[青年]这个的嵌入向量应该能表示14-48岁的所有编码器输出。
同样使均方根误差来计算,且使用sg函数将loss分成两部分,并配置不一样的权值(作者认为codebook应该学习的比encoder快,原论文参数为
β
=
1
,
α
=
0.5
\beta=1, \alpha=0.5
β=1,α=0.5,实验可知,
β
∈
(
0.1
,
2
)
\beta\in(0.1,2)
β∈(0.1,2)结果都差不多。
L
e
=
β
∣
∣
s
g
(
z
)
−
z
p
∣
∣
2
+
α
∣
∣
z
−
s
g
(
z
p
)
∣
∣
2
L_e = \beta||sg(z)-z_p||^2+\alpha||z-sg(z_p)||^2
Le=β∣∣sg(z)−zp∣∣2+α∣∣z−sg(zp)∣∣2
第一项又叫VQ(vector quantisation)误差,主要作用是优化codebook; 第二项又叫专注(commitment)误差,主要作用是使encoder输出不要偏离codebook太远。
4.5 小结
至此,VQVAE的思想就简单理解了。
5 参考
[1] https://zhuanlan.zhihu.com/p/611466195
[2] https://lilianweng.github.io/posts/2018-08-12-vae/
[3] https://www.youtube.com/watch?v=8zomhgKrsmQ
[4] https://www.zhangzhenhu.com/aigc/变分自编码器.html















 2万+
2万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









