







一、前言
本人毕业实习和毕业设计的题目为“福建省高校专家专业领域分类算法的设计与研究”,目的是将福建省一本高校官网上公开的教师简历进行分类,分类到各个学科领域中去。相比于平常玩玩的编程,这个项目算是完成度比较高了,于是我决定写一篇博客,记录下来。如果有误欢迎指正。 (●ω●)
这个项目本质上是一个文本分类问题,数据是教师简历文本,标签是学科领域。
经过一番调研,我决定用Word2Vec作为词向量的预训练模型,TextCNN做文本分类的模型。
二、理论基础
1. 文本处理技术
在了解Word2Vec模型之前,需要先搞懂文本处理技术中的一些常见概念。
词:
词是承载语义的最基本的单元,这个大家都懂。但要注意在不同的语系,文本的表示方法不同,从而导致词的划分也不同。
比如在英文和法文中,词与词之间是通过空格分隔开来的。
但对于中文和日文,词与词之间没有天然的分割符,需要通过语义确定词与词的分隔。
分词:
文本处理的分词的指的是把文本中每一个词给分隔开。
例如:
“I like sport” --> “I”,“like”,“sport”
“我喜欢运动” --> “我”,“喜欢”,“运动”
英文文本可以直接通过空格分隔开词汇,只需写一些简单的代码即可完成。
中文文本分词需要使用算法分隔,相关算法和软件包已经做的很成熟了,可以直接调用,无需了解分词算法的内部原理。
词表示:
文本在计算机中是以字为单位,以字符编码的格式存储的。
比如UTF-8编码中:
“我喜欢运动” --> “我喜欢运动”
“我” --> “我”,“喜欢” --> “喜欢”,“运动” --> “运动”
如果要用这种方法用来表示词,会出现词编码长度不固定的情况,不利于算法处理,所以要定义一种定长的编码方式来表示词。
通常是用固定长度的向量来表示词,比如这种表示:
独热编码:
“我” --> [1, 0, 0, ...... ],“喜欢” --> [0, 1, 0, ...... ],“运动” --> [0, 0, 1, ...... ]
用一个0和1组成的向量表示词,且向量中只有一个1,向量中1的位置不同表示不同词。如果是计算机相关专业的人应该清楚,这种编码方式叫做独热编码。这种编码有个明显的缺点,如果词的个数非常多时,向量设置的长度会非常大,会到达几万甚至几十万的长度,存储效率和处理效率会很低。
现在常用的词表示方法使用连续的数值向量表示:
分布式编码:
“我” --> [1.3412248 , 2.0234 , 0.28718153, ...... ],
“喜欢” --> [0.08882073, -1.9455205 , 0.07233624, ...... ],
“运动” --> [0.7758509 , -0.22903536, -1.3623129, ...... ]
用连续的数值向量表示词,理论上可以表示出无穷多个词,而且向量的长度可以设置的很小,通常在几百的长度以内,存储效率和处理效率都比较高,通常将这种表示方式称为词向量。
语料库:
可以看做是现实中使用的语言材料,以电子的形式保存下来的文本数据库。例如网页新闻,电子邮件,文字聊天记录等。
词典:
本质上是一个查找表,存储着词和对应的词向量。通常配合一些数据结构算法,实现输入一个词,输出这个词的词向量。
词典中的词汇是通过一个语料库中所有的词进行统计得到的,仅仅包含该语料库中出现的词,并不会包括语言中出现的所有词(数量超级大)。通常就将未在词典中的词当做同一个词——“未知词”,所有“未知词”只对应一个全零的词向量。
下图是一个词典的图例,其中<unk>代表着“未知词”。

2. Word2Vec词向量模型
Word2Vec 是 Google 于2013年开源推出的一个用于获取词向量的工具包。简单高效,被开发者广泛使用,是文本处理领域中经典的一个模型。Word2Vec的论文在此,不过论文中没有介绍算法细节,让人看的一头雾水,不建议阅读。如果想要理解算法原理,建议阅读Word2Vec的源码,不过Google官网上的代码链接失效了,可以去看Github上的一份存档。
如果你想快速应用Word2Vec到项目中去,完全可以跳过原理细节的了解,因为Word2Vec的软件包已经很完善了,只需一个语料库,设置一些基本参数,就可以训练出想要的词向量模型了。
由于Word2Vec的算法原理有些复杂,只言片语无法解释清楚,这里贴上一篇皮果提博主写的 Word2Vec的数学原理详解。说实话,我并没有搞懂Word2Vec的数学原理,但是在花了两周时间仔细阅读了Word2Vec源码后,能够基本了解算法流程和思想。以下是我的一些理解,希望对你们了解Word2Vec有帮助。
Word2Vec的作用:
Wor2Vec是一个语言模型,可以通过学习语料库中词语分布特征,来获得每个词对应的词向量,学习到的词向量具有语义特征。
词向量如何体现语义特征?举个例子,如果两个词的含义越接近,那么其对应词向量间的余弦相似度就大。反之余弦相似度越大的词,它们的含义越接近。
这里贴上我自己训练的Word2Vec的效果,分别打印出“计算机”和“化学”两个词的相似词和每个相似词的余弦相似度:
>>> model.similar_by_word('计算机')
[('人工智能', 0.6347100734710693),
('电子', 0.6297334432601929),
('软件', 0.6222725510597229),
('算法', 0.6189445853233337),
('计算', 0.5747603178024292),
('信息技术', 0.5709293484687805),
('机械设计', 0.5686125755310059),
('自动化', 0.566336452960968),
('计算机辅助', 0.5552766919136047),
('软件工程', 0.5523335933685303)]
>>> model.similar_by_word('化学')
[('物理化学', 0.6472294330596924),
('分析化学', 0.6273697018623352),
('有机化学', 0.607236385345459),
('高分子', 0.6032062768936157),
('无机化学', 0.5997181534767151),
('催化', 0.5842633247375488),
('生物', 0.5606042146682739),
('能源', 0.5453063249588013),
('电化学', 0.5426709651947021),
('材料', 0.5399788022041321)]
Word2Vec的原理(个人看法):
理解Word2Vec为什么能学习到语义特征,需要先了解文本中的上下文关系。
比如这样一句话:
“中国____踢得真是太烂了”
我们可以通过上下文的已知词,判断中间空白处的未知词为“男足”。这就是一种利用上下文关系去判断中间词的方法。
所以就可以建立一个模型,对这种关系进行学习:将上下文的词作为训练数据,中心词作为正样本标签,随机取一些其他的词作为负样本标签(Negative Sampling),这样就把问题转化成了一个二分类问题(我的想法,不一定准确),就可以用机器学习的方法对语料库文本数据进行学习了。
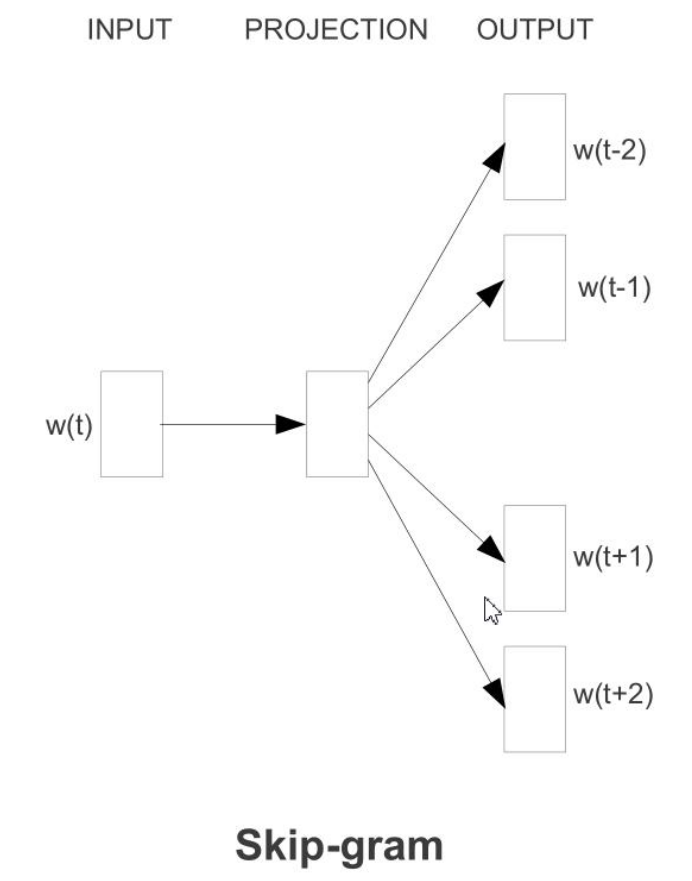
Word2Vec就是利用这样的原理,建立了一个浅层的神经网络,通过学习上下文和中心词的关系,不断优化词向量参数,达到学习语义的目的。在Word2Vec中,利用上下文去预测中心词的模型称为CBOW模型,模型图例如下:

那为什么Word2Vec可以学习到一个词的相似词呢?让我们看以下这个例子:
在一个语料库中,可能有这些句子:
“中国 男篮 打的太差了”
“中国 男排 打的太烂了”
这些句子跟“中国____踢得真是太烂了”有着相似的上下文,因为语料库文本数据的分布有着“相似的上下文有相似的中心词”的规律,模型就会学习到这个规律。所以在相似上下文的情况下,就会得出“男足”,“男篮”,“男排”这些词是相似词的结论。
类似的,也可以通过中心词去预测上下文,这在Word2Vec中称为Skip-gram模型:
3. TextCNN模型
这是一个将卷积神经网络(CNN)应用到文本分类领域上的端到端模型,论文在此,这篇论文值得一读。TextCNN是文本分类领域的一个经典模型,不同版本的开源代码有很多,这里我附上一个基于Pytorch的TextCNN代码。
如果了解过计算机视觉领域,应该比较清楚CNN处理图像的流程,大致就是Conv + ReLU + Pooling + Full Connect,其实CNN用于文本分类的流程与此相似。
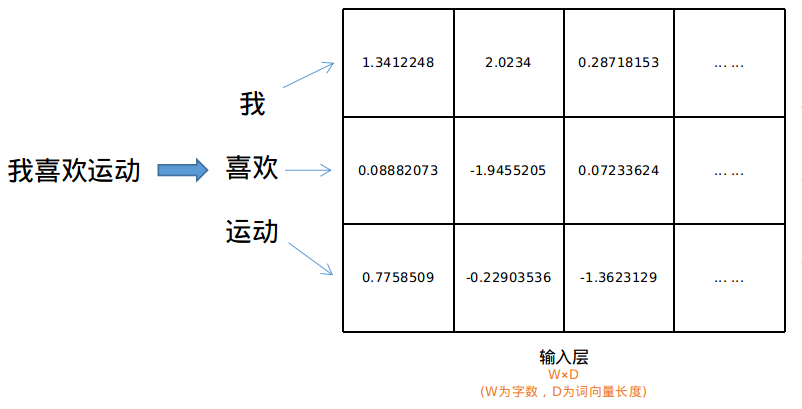
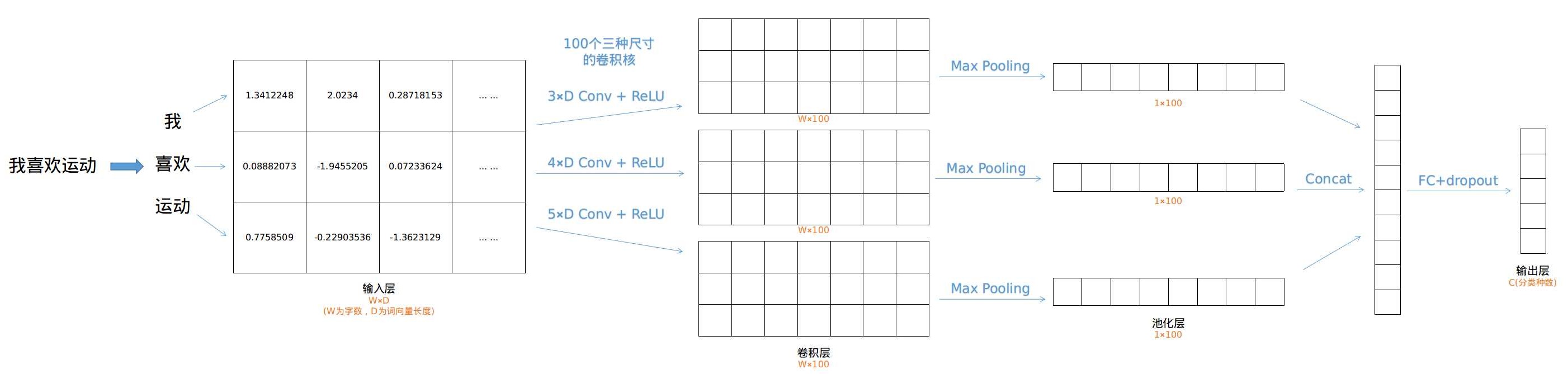
第一步,将文本转化为2D矩阵的形式。
对于中文来说,先将连续的文本分词处理,得到由词构成的一维向量。
再利用上文介绍的词典将词转化为词向量,这里词典中的词向量可以用随机值初始化,或者利用一个训练好的Word2Vec词向量模型初始化。
一维向量就转化为了2D矩阵。
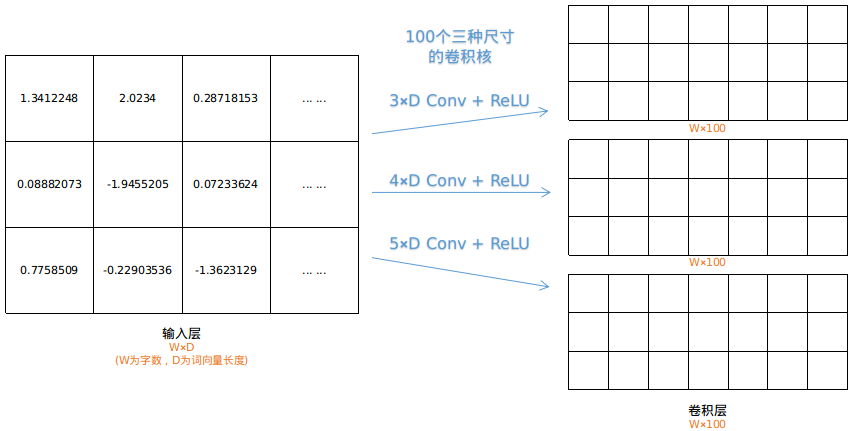
第二步,对2D矩阵进行卷积操作
在图像处理中卷积核通常是正方形的,但在TextCNN中,使用的卷积核是3×D,4×D,5×D这样的长方形卷积核,而且是对输入层同时使用这三种尺寸的卷积核,每种尺寸的卷积核有100个,总共300个卷积核。
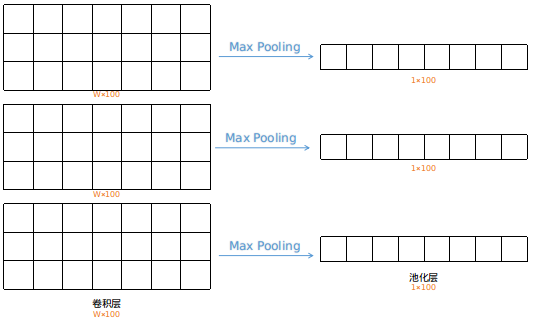
第三步,对卷积层进行Max Pooling操作
在图像处理中的池化窗口是正方形的二维窗口,但在TextCNN中,池化操作是一维的,相当于对每列数据进行MaxPooling。
第四步,对三个层进行拼接,最后进行全连接和dropout操作
拼接是将三个层的结构进行首尾相连,拼成一个层,然后进行全连接和dropout操作,产生输出层,最终可以使用softmax计算各个分类标签的概率。
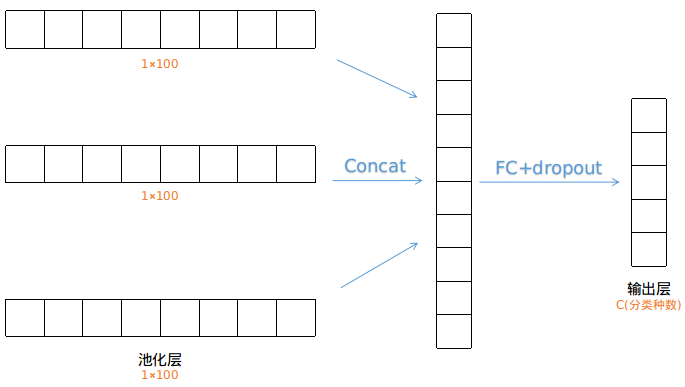
到此为止,整个TextCNN的结构就介绍完成了,整体结构非常的简洁,下图为整体结构:
(Ps:图中举例只有三个词,输入层行数太小,实际处理中会padding成一个较长的矩阵,以保证4×D和5×D卷积的正常处理。)
4. Word2Vec与TextCNN的结合
如果单独使用TextCNN,输入层是通过赋随机值的方法进行初始化的。
如果结合TextCNN和Word2Vec,则利用Word2Vec模型训练的词向量参数初始化输入层,此时反向传播仍能继续优化输入层的参数。
如果看过TextCNN的论文,就会发现上述两种方法分别对应论文中的CNN-rand和CNN-non-static这两种变体。
理论基础介绍完毕,如果有不懂的地方可以提出问题,我尽自己的努力完善语句表达。
下一篇博客讲代码实现。















 1142
1142











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









