






说到Elasticsearch和Logstash,首先我们先了解下什么是ELK、EFK集群,再从整体去理解elasticsearch和Logstash
什么是ELK集群?
ELK集群是日志中心集群,主要是针对系统产生的日志进行收集、分析、存储
像平时常用的命令grep、awk、tailf等都能对日志进行分析,如统计PV,但是这些命令有个缺点就是它们只适用于日志数量较少的场景
所以日志较多的情况下我们就要用相应的日志集群——ELK
ELK集群的组件
ELK、EFK分别是三个字母三个核心组件
1.Elasticsearch:主要用于日志存储
是一个基于Lucene的搜索服务器。提供搜集、分析、存储数据三大功能。它提供了一个分布式多用户能力的全文搜索引擎,基于RESTful web接口。Elasticsearch是用Java开发的,并作为Apache许可条款下的开放源码发布,是当前流行的企业级搜索引擎。设计用于云计算中,能够达到实时搜索,稳定,可靠,快速,安装使用方便
2.Logstash:主要用于日志搜集(Filebeat)
主要是用来日志的搜集、分析、过滤日志的工具。用于管理日志和事件的工具,你可以用它去收集日志、转换日志、解析日志并将他们作为数据提供给其它模块调用,例如搜索、存储等
3.Filebeat
隶属于Beats,轻量级数据收集引擎。基于原先 Logstash-fowarder 的源码改造出来。换句话说:Filebeat就是新版的 Logstash-fowarder,也会是 ELK Stack 在 Agent 的第一选择,目前Beats包含四种工具
(1)Packetbeat(搜集网络流量数据)
(2)Metricbeat(搜集系统、进程和文件系统级别的 CPU 和内存使用情况等数据。通过从操作系统和服务收集指标,帮助您监控服务器及其托管的服务。
(3)Filebeat(搜集日志文件数据)
(4)Winlogbeat(搜集 Windows 事件日志数据)
4.Kibana:主要用于日志展示
是一个优秀的前端日志展示框架,它可以非常详细的将日志转化为各种图表,为用户提供强大的数据可视化支持,它能够搜索、展示存储在 Elasticsearch 中索引数据。使用它可以很方便的用图表、表格、地图展示和分析数据。
ELK的架构
基础架构
logstash作为日志搜集器,从数据源采集数据,并对数据进行过滤,格式化处理,然后交由Elasticsearch存储,kibana从Elasticsearch调取日志,对日志进行可视化处理
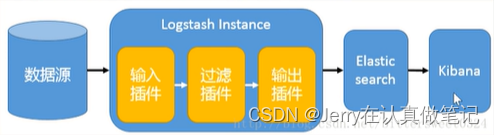
多节点部署Logstash架构
这种架构模式适合需要采集日志的客户端不多,且各服务端cpu,内存等资源充足的情况下。因为每个节点都安装Logstash,非常消耗节点资源。其中,logstash作为日志搜集器,将每一台节点的数据发送到Elasticsearch上进行存储,再由kibana进行可视化分析
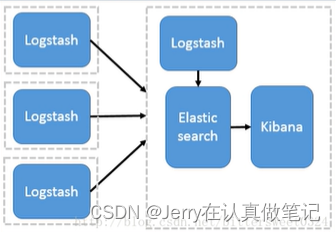
以上内容摘自ELK组件介绍_哔哩哔哩_bilibili
只做笔记用途,欢迎大家补充。















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









