







本篇主要介绍使用tfserving和docker同时部署多个模型,使用不同版本的模型,基本的流程与部署单个模型的过程类似,(关于运行tfserving容器使用单个模型进行预测的相关步骤可以参见 使用docker和tf serving搭建模型预测服务。)不同之处在于需要用到一个多模型的配置文件。首先得到多个可以用于tfserving预测的模型文件,相关步骤可以参考使用savedModel保存模型。本例中用使用savedModel保存模型中的相关代码生成三个模型,分别建立三个文件夹,将得到的模型分别放入,最后的文件结构如下图。其中100001文件夹表示模型的版本,可以在model1下放置不同版本的模型,默认情况下会加载具有较大版本号数字的模型。
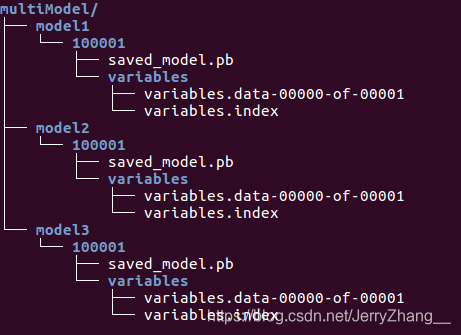
1. 多模型部署
在multiModel文件夹下新建一个配置文件model.config,文件内容为:
model_config_list:{
config:{
name:"model1",
base_path:"/models/multiModel/model1",
model_platform:"tens 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 1302
1302

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









