







# location:beijing
Attention[^1]
single head of attention
Attention blocks showed in Fig. 1 allow vectors to talk to each other and pass information back and forth to update their values.
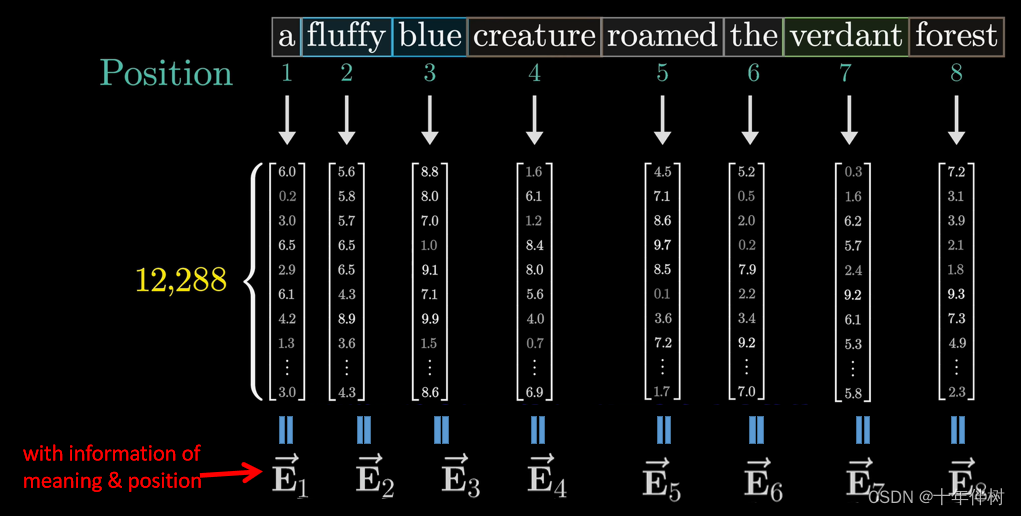
there is an example to understand the mechanism of Attention. Fig. 1. shows that vector E n ⃗ \vec{\mathbf{E}_n} En is a combination of token’s meaning and positional information (M&P). then E n ⃗ \vec{\mathbf{E}_n} En will be sent to Attention blocks.
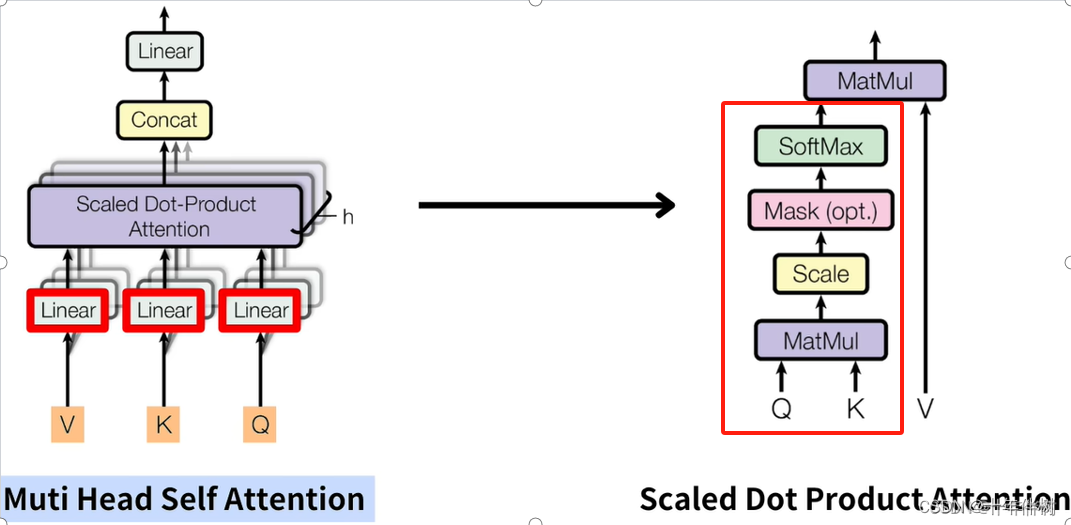
the input of Attention E n ⃗ \vec{\mathbf{E}_n} En will be figured by three linear layers: V, K, Q for feature shifting.
We can see Q as a method that adds attributes that can receive information of M&P from in-context words(vectors) to E n ⃗ \vec{\mathbf{E}_n} En. And the outcomes are Q n ⃗ \vec{\mathbf{Q}_n} Qn
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 593
593

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









