






损失函数
损失函数(Loss Function)是机器学习和深度学习中用于量化模型预测值与真实值之间差异的函数,是模型优化的目标。通过最小化损失函数,模型逐步调整参数以提高预测准确性。不同任务和场景需要选择不同的损失函数。现在深度学习模型中最主要的梯度下降法就是基于损失函数的梯度来计算的,所以损失函数十分重要,常见的损失函数包括:
- 均方误差(MSE, Mean Squared Error)
- 平均绝对误差(MAE, Mean Absolute Error)
- Huber Loss
- 交叉熵损失(Cross-Entropy Loss)
- Hinge Loss(合页损失)
- Focal Loss
- 对比损失(Contrastive Loss)
- Triplet Loss
- KL散度(Kullback-Leibler Divergence)
接下来就让我们来进一步了解一下这些损失函数。
均方误差(Mean Squared Error, MSE)详解
均方误差是一种衡量预测值与真实值之间差距的指标。它计算的是所有预测误差(即预测值减去真实值)的平方之后的平均值。它先计算每一个样本的误差(预测值减真实值),然后平方(这样可以避免正负抵消,并且更重视大的误差),最后取平均值。数值越小,说明模型预测结果与真实值越接近。它对较大的误差特别敏感,因为误差平方会放大大的偏差。MSE 通常用于回归任务中,是评估模型好坏最常用的指标之一。
1. 数学定义
公式
MSE = 1 n ∑ i = 1 n ( y i − y ^ i ) 2 \text{MSE} = \frac{1}{n} \sum_{i=1}^n (y_i - \hat{y}_i)^2 MSE=n1i=1∑n(yi−y^i)2
符号说明
- y i y_i yi:第 i i i 个样本的真实值
- y ^ i \hat{y}_i y^i:第 i i i 个样本的预测值
- n n n:样本数量
特点
- 输出范围: [ 0 , + ∞ ) [0, +\infty) [0,+∞),值越小表示模型越好
- 可微性:处处可导,适合梯度下降优化
- 对称性:对正负误差同等惩罚
2. 核心特性
- 放大较大误差:平方操作使大误差对损失贡献更大
- 高斯分布假设:最小化MSE等价于假设误差服从 N ( 0 , σ 2 ) N(0,\sigma^2) N(0,σ2)时的最大似然估计
3. 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 光滑可导,便于优化 | ❌ 对异常值敏感 |
| ✅ 物理意义明确 | ❌ 量纲为原单位的平方 |
| ✅ 推动模型修正大误差 | ❌ 可能过度拟合离群点 |
4. 变体与改进
4.1 RMSE(均方根误差)
公式:
RMSE
=
MSE
\text{RMSE} = \sqrt{\text{MSE}}
RMSE=MSE
特点:
- 解决MSE量纲问题(单位与原始数据一致)
- 对较大误差仍保持敏感性
- 更直观解释预测误差大小
适用场景:
- 需要保持原始量纲的回归任务
- 模型效果的可解释性要求较高时
4.2 加权MSE
公式:
Weighted MSE
=
1
n
∑
i
=
1
n
w
i
(
y
i
−
y
^
i
)
2
\text{Weighted MSE} = \frac{1}{n}\sum_{i=1}^n w_i(y_i-\hat{y}_i)^2
Weighted MSE=n1i=1∑nwi(yi−y^i)2
参数说明:
- w i w_i wi:第i个样本的权重( w i > 0 w_i > 0 wi>0)
- 通常需要满足 ∑ i = 1 n w i = n \sum_{i=1}^n w_i = n ∑i=1nwi=n(保持数值范围与MSE相当)
典型应用:
- 时间序列预测:近期数据赋予更高权重
- 不均衡数据:重要样本加大权重
- 带置信度的数据:根据测量精度分配权重
平均绝对误差(Mean Absolute Error, MAE)详解
平均绝对误差是衡量预测值与真实值之间差异的一种指标。它通过计算所有预测误差的绝对值(不考虑正负),然后取平均,来表示模型预测的平均偏差。它反映了预测值与真实值之间的平均距离。与均方误差(MSE)不同,MAE 不会对大的误差给予过度惩罚,而是将所有误差等权处理。数值越小,代表模型预测结果越接近真实值。
1. 数学定义
公式
MAE = 1 n ∑ i = 1 n ∣ y i − y ^ i ∣ \text{MAE} = \frac{1}{n} \sum_{i=1}^n |y_i - \hat{y}_i| MAE=n1i=1∑n∣yi−y^i∣
符号说明
- y i y_i yi:第 i i i 个样本的真实值
- y ^ i \hat{y}_i y^i:第 i i i 个样本的预测值
- n n n:样本数量
2. 核心特性
- 线性惩罚:对误差进行线性惩罚(而非平方)
- 中位数优化:最小化MAE等价于预测中位数(对比MSE预测均值)
- 单位一致性:量纲与原始数据相同
3. 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 对异常值鲁棒 | ❌ 在零点不可导 |
| ✅ 解释直观 | ❌ 收敛速度较慢 |
| ✅ 单位一致 | ❌ 对小误差不够敏感 |
4. 变体与改进
4.1 加权MAE (Weighted MAE)
公式:
WMAE
=
1
n
∑
i
=
1
n
w
i
∣
y
i
−
y
^
i
∣
\text{WMAE} = \frac{1}{n}\sum_{i=1}^n w_i|y_i-\hat{y}_i|
WMAE=n1i=1∑nwi∣yi−y^i∣
特点:
- 允许对不同样本赋予不同重要性
- 权重 w i w_i wi需满足 ∑ w i = n \sum w_i = n ∑wi=n以保持数值范围
- 常用于时间序列预测(近期数据权重更高)
4.2 分位数损失 (Quantile Loss)
数学定义
基本公式:
L
τ
(
y
,
y
^
)
=
{
τ
⋅
∣
y
−
y
^
∣
if
y
≥
y
^
(
1
−
τ
)
⋅
∣
y
−
y
^
∣
if
y
<
y
^
L_\tau(y, \hat{y}) = \begin{cases} \tau \cdot |y - \hat{y}| & \text{if } y \geq \hat{y} \\ (1-\tau) \cdot |y - \hat{y}| & \text{if } y < \hat{y} \end{cases}
Lτ(y,y^)={τ⋅∣y−y^∣(1−τ)⋅∣y−y^∣if y≥y^if y<y^
向量化表示:
L
τ
=
1
n
∑
i
=
1
n
[
τ
⋅
max
(
y
i
−
y
^
i
,
0
)
+
(
1
−
τ
)
⋅
max
(
y
^
i
−
y
i
,
0
)
]
L_\tau = \frac{1}{n}\sum_{i=1}^n \left[ \tau \cdot \max(y_i-\hat{y}_i, 0) + (1-\tau) \cdot \max(\hat{y}_i-y_i, 0) \right]
Lτ=n1i=1∑n[τ⋅max(yi−y^i,0)+(1−τ)⋅max(y^i−yi,0)]
核心特性
| 特性 | 说明 |
|---|---|
| 非对称惩罚 | 根据 τ \tau τ值对高/低估施加不同权重 |
| 分位数预测 | τ = 0.5 \tau=0.5 τ=0.5时退化为MAE |
| 可导性 | 在 y = y ^ y=\hat{y} y=y^处不可导,但可使用次梯度 |
参数说明
-
τ
∈
(
0
,
1
)
\tau \in (0,1)
τ∈(0,1):目标分位数
- τ = 0.9 \tau=0.9 τ=0.9:预测90%分位数(低估值惩罚更大)
-
τ
=
0.1
\tau=0.1
τ=0.1:预测10%分位数(高估值惩罚更大)
Huber Loss 详解
Huber Loss 是一种结合了均方误差(MSE)和平均绝对误差(MAE)优点的损失函数。
• 当误差较小时,它表现得像 MSE,平滑且对小误差敏感;
• 当误差较大时,它表现得像 MAE,避免了对离群点过度惩罚。
1. 数学定义
公式
L δ ( y , y ^ ) = { 1 2 ( y − y ^ ) 2 当 ∣ y − y ^ ∣ ≤ δ δ ∣ y − y ^ ∣ − 1 2 δ 2 当 ∣ y − y ^ ∣ > δ L_\delta(y, \hat{y}) = \begin{cases} \frac{1}{2}(y - \hat{y})^2 & \text{当 } |y - \hat{y}| \leq \delta \\ \delta |y - \hat{y}| - \frac{1}{2}\delta^2 & \text{当 } |y - \hat{y}| > \delta \end{cases} Lδ(y,y^)={21(y−y^)2δ∣y−y^∣−21δ2当 ∣y−y^∣≤δ当 ∣y−y^∣>δ
参数说明
- δ \delta δ:超参数,控制线性与二次区域的阈值(通常取1.35)
- y y y:真实值
- y ^ \hat{y} y^:预测值
2. 核心特性
| 特性 | 说明 |
|---|---|
| 混合惩罚机制 | 小误差时类似MSE(二次),大误差时类似MAE(线性) |
| 可微性 | 在 δ \delta δ处一阶可导,二阶导数不连续 |
| 鲁棒性 | 对异常值的敏感度介于MSE和MAE之间 |
| 超参数敏感性 | δ \delta δ值需要根据数据分布调整 |
3. 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 平衡MSE和MAE的优点 | ❌ 需要调参选择 δ \delta δ |
| ✅ 对中等异常值鲁棒 | ❌ 计算复杂度高于MSE |
| ✅ 处处可导利于优化 | ❌ 极端异常值下仍可能不稳定 |
| ✅ 保持收敛速度 | ❌ 需要数据分布先验知识 |
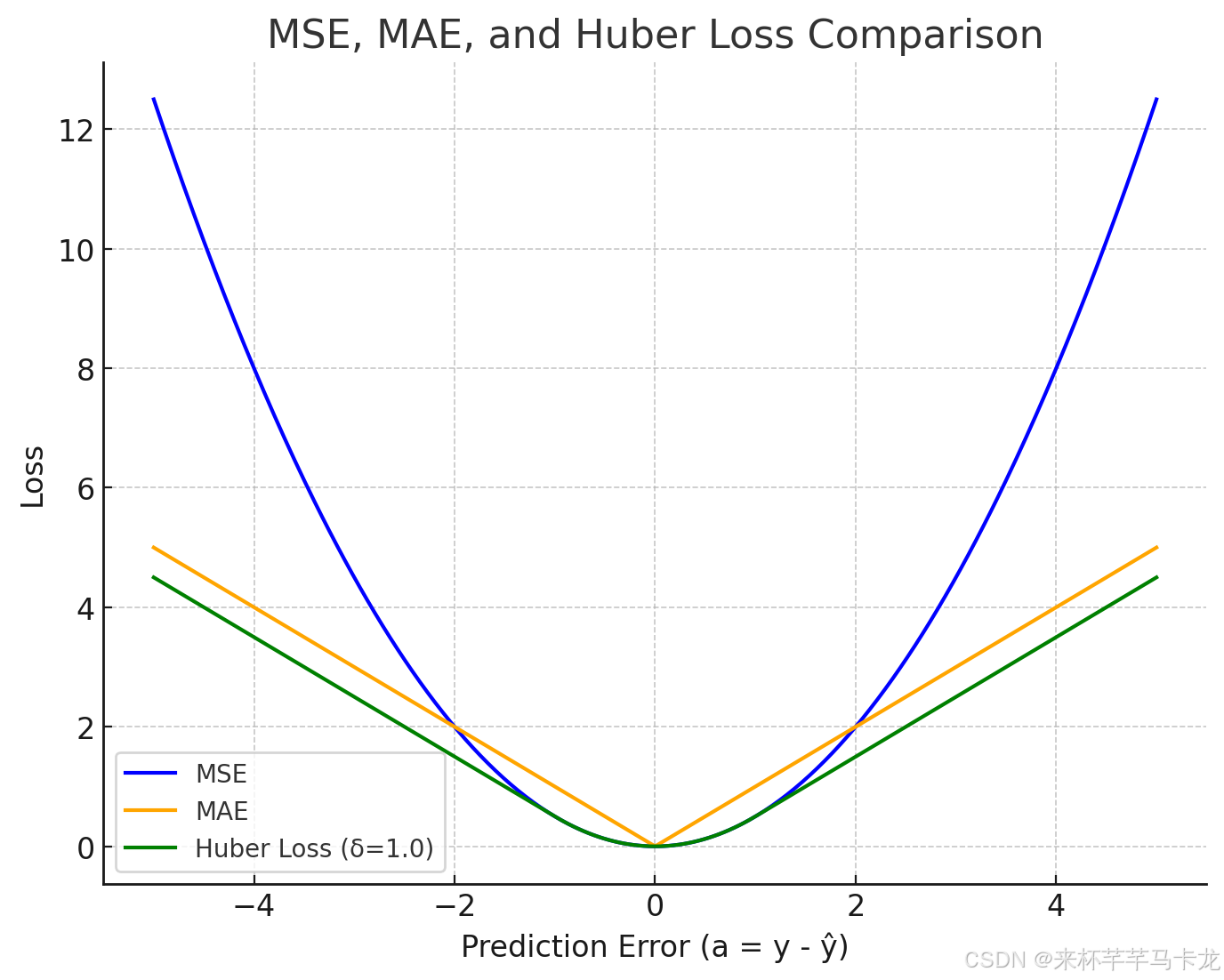
这就是 MSE、MAE 和 Huber Loss 三者的对比图:
• 蓝色曲线(MSE):误差越大,损失增长得非常快(平方增长),对离群点非常敏感。
• 橙色曲线(MAE):线性增长,对大误差不敏感,但梯度不连续。
• 绿色曲线(Huber Loss):在小误差区域和 MSE 一样平滑、灵敏;在误差超过 δ 时像 MAE 一样线性增长,避免对离群点过度惩罚。
4. 变体与改进
4.1 自适应Huber Loss
动态调整
δ
\delta
δ值:
δ
=
α
⋅
median
(
∣
y
−
y
^
∣
)
\delta = \alpha \cdot \text{median}(|y - \hat{y}|)
δ=α⋅median(∣y−y^∣)
其中
α
\alpha
α为比例系数(通常取1.48),median为中位数。
4.2 平滑Huber Loss
在
δ
\delta
δ处引入平滑过渡:
L
δ
s
m
o
o
t
h
=
δ
2
(
1
+
(
y
−
y
^
δ
)
2
−
1
)
L_\delta^{smooth} = \delta^2 \left( \sqrt{1 + \left(\frac{y-\hat{y}}{\delta}\right)^2} - 1 \right)
Lδsmooth=δ2
1+(δy−y^)2−1
4.3 多阈值Huber Loss
分段设置不同
δ
\delta
δ值:
L
=
∑
k
=
1
K
w
k
L
δ
k
(
y
,
y
^
)
L = \sum_{k=1}^K w_k L_{\delta_k}(y, \hat{y})
L=k=1∑KwkLδk(y,y^)
交叉熵损失(Cross-Entropy Loss)详解
交叉熵损失是一种用于衡量两个概率分布之间差异的指标,通常用于分类问题,特别是二分类或多分类任务中。它描述的是:模型预测的概率分布与真实分布(标签)之间有多大的距离。
当模型预测概率与真实标签非常接近时,交叉熵损失值很小;如果模型预测与真实概率差得很远,交叉熵损失会非常大;本质上它就是在衡量“模型到底有多自信、而这种自信是否正确”。
1. 数学定义
1.1 二分类交叉熵
L = − 1 n ∑ i = 1 n [ y i log ( y ^ i ) + ( 1 − y i ) log ( 1 − y ^ i ) ] L = -\frac{1}{n}\sum_{i=1}^n \left[y_i\log(\hat{y}_i) + (1-y_i)\log(1-\hat{y}_i)\right] L=−n1i=1∑n[yilog(y^i)+(1−yi)log(1−y^i)]
1.2 多分类交叉熵
L = − 1 n ∑ i = 1 n ∑ c = 1 C y i , c log ( y ^ i , c ) L = -\frac{1}{n}\sum_{i=1}^n \sum_{c=1}^C y_{i,c}\log(\hat{y}_{i,c}) L=−n1i=1∑nc=1∑Cyi,clog(y^i,c)
1.3 符号说明
| 符号 | 含义 |
|---|---|
| n n n | 样本数量 |
| C C C | 类别数量 |
| y i y_i yi | 真实标签(二分类时为0/1) |
| y ^ i \hat{y}_i y^i | 预测概率(经过softmax/sigmoid处理) |
| y i , c y_{i,c} yi,c | 第i个样本在第c类的one-hot编码 |
2. 核心特性
2.1 信息论基础
- 本质是KL散度的特例,衡量两个概率分布的差异
- 最小化交叉熵 ⇨ 最大化似然函数
2.2 梯度特性
∂ L ∂ z j = y ^ j − y j \frac{\partial L}{\partial z_j} = \hat{y}_j - y_j ∂zj∂L=y^j−yj
- 梯度与误差成正比,优化效率高
- 避免sigmoid导致的梯度消失问题
2.3 概率解释
- 要求预测值 y ^ \hat{y} y^构成合法概率分布( ∑ y ^ c = 1 \sum\hat{y}_c=1 ∑y^c=1)
- 与softmax/sigmoid激活函数天然配套
3. 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 梯度形式简单利于优化 | ❌ 对错误分类惩罚可能过强 |
| ✅ 概率解释性强 | ❌ 需要规范化的概率输入 |
| ✅ 适合多分类任务 | ❌ 类别不平衡时效果下降 |
| ✅ 与深度学习框架深度集成 | ❌ 对噪声标签敏感 |
4. 变体与改进
4.1 加权交叉熵
L = − 1 n ∑ i = 1 n w y i log ( y ^ i ) L = -\frac{1}{n}\sum_{i=1}^n w_{y_i}\log(\hat{y}_i) L=−n1i=1∑nwyilog(y^i)
- w y i w_{y_i} wyi:按类别频率的逆或自定义权重
- 解决类别不平衡问题
4.2 Focal Loss
L = − α t ( 1 − y ^ t ) γ log ( y ^ t ) L = -\alpha_t(1-\hat{y}_t)^\gamma \log(\hat{y}_t) L=−αt(1−y^t)γlog(y^t)
- γ \gamma γ:聚焦参数(通常γ=2)
- 降低易分类样本的权重,解决难易样本不平衡
4.3 Label Smoothing
y i , c L S = ( 1 − ϵ ) y i , c + ϵ / C y_{i,c}^{LS} = (1-\epsilon)y_{i,c} + \epsilon/C yi,cLS=(1−ϵ)yi,c+ϵ/C
- ϵ \epsilon ϵ:平滑系数(通常0.1)
- 防止模型对标签过度自信
4.4 二元交叉熵改进
| 变体 | 公式特点 | 适用场景 |
|---|---|---|
| Sigmoid交叉熵 | 配合sigmoid使用 | 多标签分类 |
| Softmax交叉熵 | 配合softmax使用 | 单标签多分类 |
| 泊松交叉熵 | 适用于计数数据 | 自然语言处理 |
5. 应用场景选择指南
| 场景 | 推荐变体 | 理由 |
|---|---|---|
| 类别极度不平衡 | Focal Loss + 加权 | 缓解主导类影响 |
| 多标签分类 | Sigmoid交叉熵 | 允许类别共存 |
| 低置信度预测 | Label Smoothing | 提高泛化能力 |
| 噪声标签数据 | 广义交叉熵 | 鲁棒性增强 |
Hinge Loss(合页损失)详解
Hinge Loss(合页损失)是一种常用于**支持向量机(SVM)**中的损失函数,它用于度量模型预测结果与真实标签之间的差距,鼓励模型在预测时不仅要分类正确,还要有一定的“间隔”(margin)安全距离。当模型正确且距离决策边界较远(margin ≥ 1)时,不产生损失;当模型预测值接近或越过决策边界,损失增加,鼓励模型把样本推得更远一些,保持安全间隔;名字“合页”来源于函数形状像一个打开的合页:一边平平的(0 损失),另一边折下去是线性增长。
1. 数学定义
1.1 标准形式
L
(
y
,
y
^
)
=
max
(
0
,
1
−
y
⋅
y
^
)
L(y, \hat{y}) = \max(0, 1 - y \cdot \hat{y})
L(y,y^)=max(0,1−y⋅y^)
其中:
- y ∈ { − 1 , + 1 } y \in \{-1, +1\} y∈{−1,+1}:二分类的真实标签
- y ^ \hat{y} y^:决策函数的原始输出(未经过sigmoid/softmax)
1.2 多分类扩展(Crammer-Singer形式)
L
=
max
(
0
,
1
+
max
j
≠
y
i
(
y
^
j
)
−
y
^
y
i
)
L = \max(0, 1 + \max_{j \neq y_i}(\hat{y}_j) - \hat{y}_{y_i})
L=max(0,1+j=yimax(y^j)−y^yi)
其中
y
i
y_i
yi为样本的真实类别索引
2. 核心特性
2.1 几何解释
- 构建分类间隔(margin)的损失函数
- 仅惩罚误分类和间隔内的样本
- 最优解倾向于最大化决策边界到最近样本的距离
2.2 数学特性
| 特性 | 说明 |
|---|---|
| 非平滑性 | 在 y ^ = 1 \hat{y}=1 y^=1处不可导 |
| 稀疏性 | 对远离决策边界的样本梯度为0 |
| 边界控制 | 通过margin参数调节分类严格度 |
2.3 与SVM的关系
- 线性SVM的原生损失函数
- 等价于SVM的拉格朗日对偶形式中的约束优化
3. 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 天然支持最大间隔分类 | ❌ 仅适用于二分类/多分类 |
| ✅ 对离群点鲁棒 | ❌ 需要原始输出(非概率) |
| ✅ 产生稀疏解 | ❌ 不可直接用于概率估计 |
| ✅ 适合高维特征 | ❌ 对噪声标签敏感 |
4. 变体与改进
4.1 平方Hinge Loss
L = max ( 0 , 1 − y y ^ ) 2 L = \max(0, 1 - y\hat{y})^2 L=max(0,1−yy^)2
- 加强误分类惩罚
- 在不可导点附近更平滑
4.2 自适应Margin Hinge Loss
L = max ( 0 , ϕ ( y ) − y y ^ ) L = \max(0, \phi(y) - y\hat{y}) L=max(0,ϕ(y)−yy^)
- ϕ ( y ) \phi(y) ϕ(y):类别相关的动态margin
- 解决类别不平衡问题
4.3 多标签Hinge Loss
L = ∑ j = 1 C max ( 0 , 1 − y j y ^ j ) L = \sum_{j=1}^C \max(0, 1 - y_j\hat{y}_j) L=j=1∑Cmax(0,1−yjy^j)
- 扩展至多标签分类
- 每个类别独立计算损失
Focal Loss 详解
Focal Loss 是一种用于处理类别不平衡问题的损失函数,最早应用在目标检测模型 RetinaNet 中。
它的目标是:
• 减少那些容易分类样本(模型已经很自信)的损失权重;
• 增强难分类样本(模型不自信)的影响力,让模型专注于“难例”。
• 当模型对样本预测得很准(即 pt 很接近 1),(1 - pt )γ 项会变得非常小,降低该样本的损失贡献;
• 当模型对样本预测得不准(pt 小),这个惩罚因子变大,让“难分样本”在损失中权重更大;
• 相当于一种“自适应调节”机制,让模型不被大量简单样本牵着走,而把注意力集中在困难样本上。
1. 数学定义
1.1 标准形式
F
L
(
p
t
)
=
−
α
t
(
1
−
p
t
)
γ
log
(
p
t
)
FL(p_t) = -\alpha_t (1 - p_t)^\gamma \log(p_t)
FL(pt)=−αt(1−pt)γlog(pt)
其中:
- p t = { p 当 y = 1 1 − p 当 y = 0 p_t = \begin{cases} p & \text{当 } y=1 \\ 1-p & \text{当 } y=0 \end{cases} pt={p1−p当 y=1当 y=0
- α t \alpha_t αt:类别平衡权重( α ∈ [ 0 , 1 ] \alpha \in [0,1] α∈[0,1])
- γ \gamma γ:聚焦参数( γ ≥ 0 \gamma \geq 0 γ≥0)
1.2 二分类完整表达式
F L = { − α ( 1 − p ) γ log ( p ) 正样本 − ( 1 − α ) p γ log ( 1 − p ) 负样本 FL = \begin{cases} -\alpha (1 - p)^\gamma \log(p) & \text{正样本} \\ -(1-\alpha) p^\gamma \log(1-p) & \text{负样本} \end{cases} FL={−α(1−p)γlog(p)−(1−α)pγlog(1−p)正样本负样本
2. 核心特性
2.1 动态缩放机制
| 参数 | 作用 |
|---|---|
| γ \gamma γ | 控制难易样本权重衰减速率 |
| α \alpha α | 调节类别不平衡基础权重 |
2.2 梯度特性
∂ F L ∂ p = α t γ ( 1 − p t ) γ − 1 ( γ p t log ( p t ) − p t + 1 ) \frac{\partial FL}{\partial p} = \alpha_t \gamma (1-p_t)^{\gamma-1} (\gamma p_t \log(p_t) - p_t + 1) ∂p∂FL=αtγ(1−pt)γ−1(γptlog(pt)−pt+1)
- 对易分类样本( p t → 1 p_t \to 1 pt→1)梯度指数级衰减
- 对难样本保持显著梯度
2.3 与交叉熵的关系
当 γ = 0 , α = 0.5 \gamma=0,\alpha=0.5 γ=0,α=0.5时退化为标准交叉熵
3. 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 显著提升难样本学习 | ❌ 引入两个超参数需调优 |
| ✅ 缓解类别不平衡 | ❌ 计算复杂度略高于CE |
| ✅ 兼容多数网络架构 | ❌ 极端易样本可能欠学习 |
| ✅ 避免梯度被易样本主导 | ❌ 需要概率输入(sigmoid后) |
4. 变体与改进
4.1 自适应Focal Loss
动态调整
γ
\gamma
γ值:
γ
=
γ
0
+
β
⋅
epoch
\gamma = \gamma_0 + \beta \cdot \text{epoch}
γ=γ0+β⋅epoch
4.2 Asymmetric Focal Loss
正负样本采用不同
γ
\gamma
γ:
F
L
=
{
−
(
1
−
p
)
γ
+
log
(
p
)
正样本
−
p
γ
−
log
(
1
−
p
)
负样本
FL = \begin{cases} -(1 - p)^{\gamma_+} \log(p) & \text{正样本} \\ -p^{\gamma_-} \log(1-p) & \text{负样本} \end{cases}
FL={−(1−p)γ+log(p)−pγ−log(1−p)正样本负样本
4.3 Focal-Tversky Loss
结合Dice系数改进:
F
L
T
v
e
r
s
k
y
=
(
1
−
T
I
)
γ
,
T
I
=
T
P
T
P
+
α
F
N
+
β
F
P
FL_{Tversky} = (1 - TI)^\gamma,\quad TI = \frac{TP}{TP + \alpha FN + \beta FP}
FLTversky=(1−TI)γ,TI=TP+αFN+βFPTP
对比损失(Contrastive Loss)详解
对比损失(Contrastive Loss)是一种用于度量学习(metric learning)的经典损失函数,广泛应用于孪生网络(Siamese Network)、图像检索、人脸识别、多模态匹配等任务中。对比损失的目标是:
• 让相似样本对在特征空间中距离更近。
• 让不相似样本对在特征空间中距离更远。
1. 数学定义
1.1 标准形式
L ( x i , x j ) = { 1 2 ∥ f ( x i ) − f ( x j ) ∥ 2 2 正样本对 1 2 max ( 0 , m − ∥ f ( x i ) − f ( x j ) ∥ 2 ) 2 负样本对 L(x_i, x_j) = \begin{cases} \frac{1}{2} \|f(x_i) - f(x_j)\|_2^2 & \text{正样本对} \\ \frac{1}{2} \max(0, m - \|f(x_i) - f(x_j)\|_2)^2 & \text{负样本对} \end{cases} L(xi,xj)={21∥f(xi)−f(xj)∥2221max(0,m−∥f(xi)−f(xj)∥2)2正样本对负样本对
1.2 参数说明
| 符号 | 含义 |
|---|---|
| x i , x j x_i, x_j xi,xj | 输入样本对 |
| f ( ⋅ ) f(\cdot) f(⋅) | 特征编码函数 |
| m m m | 边际超参数( m > 0 m > 0 m>0) |
| ∣ ⋅ ∣ 2 |\cdot|_2 ∣⋅∣2 | L2欧氏距离 |
2. 核心特性
2.1 几何解释
- 正样本对:拉近嵌入空间距离
- 负样本对:推开至至少 m m m的距离
- 决策边界:在特征空间构建半径为 m / 2 m/2 m/2的隔离带
2.2 梯度特性
| 样本类型 | 梯度方向 |
|---|---|
| 正样本对 | 指向互相靠近方向 |
| 负样本对(距离 < m <m <m) | 指向互相远离方向 |
| 负样本对(距离 ≥ m \geq m ≥m) | 零梯度(停止更新) |
2.3 与度量学习关系
- 等价于学习马氏距离矩阵的线性变换
- 与t-SNE的成对相似度目标有理论关联
3. 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 适用于无监督/自监督学习 | ❌ 对样本对构造敏感 |
| ✅ 可学习判别性特征 | ❌ 需要精心设计负采样策略 |
| ✅ 兼容深度网络架构 | ❌ 计算复杂度随样本对数量平方增长 |
| ✅ 解耦类别定义依赖 | ❌ 边际参数 m m m需调优 |
4. 变体与改进
4.1 Triplet Loss
L = max ( 0 , ∥ f ( x a ) − f ( x p ) ∥ 2 2 − ∥ f ( x a ) − f ( x n ) ∥ 2 2 + m ) L = \max(0, \|f(x_a) - f(x_p)\|_2^2 - \|f(x_a) - f(x_n)\|_2^2 + m) L=max(0,∥f(xa)−f(xp)∥22−∥f(xa)−f(xn)∥22+m)
- 引入锚点(Anchor)概念
- 同时比较正负样本对
4.2 N-pair Loss
L = log ( 1 + ∑ k ≠ i exp ( f ( x i ) T f ( x k ) − f ( x i ) T f ( x j ) ) ) L = \log(1 + \sum_{k\neq i} \exp(f(x_i)^T f(x_k) - f(x_i)^T f(x_j))) L=log(1+k=i∑exp(f(xi)Tf(xk)−f(xi)Tf(xj)))
- 单正样本对比多负样本
- 提高负样本利用率
4.3 Supervised Contrastive Loss
L = 1 ∣ P ( i ) ∣ ∑ p ∈ P ( i ) − log exp ( z i ⋅ z p / τ ) ∑ a ∈ A ( i ) exp ( z i ⋅ z a / τ ) L = \frac{1}{|P(i)|} \sum_{p\in P(i)} -\log \frac{\exp(z_i \cdot z_p / \tau)}{\sum_{a\in A(i)} \exp(z_i \cdot z_a / \tau)} L=∣P(i)∣1p∈P(i)∑−log∑a∈A(i)exp(zi⋅za/τ)exp(zi⋅zp/τ)
- P ( i ) P(i) P(i):与 i i i同类的样本集合
-
τ
\tau
τ:温度系数
Triplet Loss 详解
Triplet Loss 旨在学习一种特征空间映射,使得:
• 同一类别的样本彼此接近;
• 不同类别的样本彼此远离。
它是通过“三元组”样本来训练的,每个三元组包含:
• Anchor(锚点样本):一个基准样本
• Positive(正样本):与 Anchor 同类别的样本
• Negative(负样本):与 Anchor 不同类别的样本
1. 数学定义
1.1 标准形式
L ( a , p , n ) = max ( 0 , d ( a , p ) − d ( a , n ) + m ) L(a, p, n) = \max(0, d(a,p) - d(a,n) + m) L(a,p,n)=max(0,d(a,p)−d(a,n)+m)
1.2 参数说明
| 符号 | 含义 |
|---|---|
| a a a (anchor) | 锚点样本 |
| p p p (positive) | 与 a a a同类正样本 |
| n n n (negative) | 与 a a a异类负样本 |
| d ( ⋅ , ⋅ ) d(\cdot,\cdot) d(⋅,⋅) | 距离度量(通常为L2距离) |
| m m m (margin) | 边界超参数( m > 0 m > 0 m>0) |
2. 核心特性
2.1 几何解释
- 构建特征空间中的相对距离约束:
- 正样本距离 d ( a , p ) d(a,p) d(a,p)应小于负样本距离 d ( a , n ) d(a,n) d(a,n)
- 边界 m m m控制类间最小间隔
2.2 梯度特性
| 样本状态 | 梯度方向 |
|---|---|
| 满足 d ( a , p ) + m < d ( a , n ) d(a,p)+m < d(a,n) d(a,p)+m<d(a,n) | 零梯度(停止更新) |
| 不满足约束 | 锚点向正样本靠近,远离负样本 |
2.3 与对比损失的关系
- 对比损失的扩展形式(从二元对到三元组)
- 引入相对比较替代绝对距离约束
3. 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 学习相对相似性 | ❌ 计算复杂度高( O ( N 3 ) O(N^3) O(N3)) |
| ✅ 适合细粒度分类 | ❌ 对样本三元组构造敏感 |
| ✅ 可发现隐含语义关系 | ❌ 需要设计困难样本挖掘策略 |
| ✅ 兼容深度度量学习 | ❌ 边界参数 m m m需调优 |
4. 变体与改进
4.1 加权Triplet Loss
L = max ( 0 , w p d ( a , p ) − w n d ( a , n ) + m ) L = \max(0, w_p d(a,p) - w_n d(a,n) + m) L=max(0,wpd(a,p)−wnd(a,n)+m)
- w p / w n w_p/w_n wp/wn:动态调整正负样本权重
4.2 Angular Triplet Loss
L = max ( 0 , cos θ a p − cos θ a n + m ) L = \max(0, \cos\theta_{ap} - \cos\theta_{an} + m) L=max(0,cosθap−cosθan+m)
- 改用角度距离替代欧氏距离
- 适用于超球面特征空间
4.3 N-pair-mc Loss
L = log ( 1 + ∑ j = 1 N − 1 exp ( f a T f n j − f a T f p ) ) L = \log(1 + \sum_{j=1}^{N-1} \exp(f_a^T f_{n_j} - f_a^T f_p)) L=log(1+j=1∑N−1exp(faTfnj−faTfp))
- 单个锚点对比多个负样本
- 提升负样本利用率
KL散度(Kullback-Leibler Divergence)详解
KL 散度是一种衡量两个概率分布之间差异的非对称度量。
它描述的是:
如果真实分布是 P,我们用分布 Q 来近似它,那么会“损失”多少信息?
可以理解成:
👉 KL 散度 = 从分布 Q 生成数据时,错误地假设它来自分布 P 而导致的信息损失。
1. 数学定义
1.1 离散形式
D K L ( P ∥ Q ) = ∑ i P ( i ) log P ( i ) Q ( i ) D_{KL}(P \| Q) = \sum_{i} P(i) \log \frac{P(i)}{Q(i)} DKL(P∥Q)=i∑P(i)logQ(i)P(i)
1.2 连续形式
D K L ( P ∥ Q ) = ∫ − ∞ ∞ p ( x ) log p ( x ) q ( x ) d x D_{KL}(P \| Q) = \int_{-\infty}^{\infty} p(x) \log \frac{p(x)}{q(x)} dx DKL(P∥Q)=∫−∞∞p(x)logq(x)p(x)dx
1.3 参数说明
| 符号 | 含义 |
|---|---|
| P P P, p ( x ) p(x) p(x) | 真实分布(目标分布) |
| Q Q Q, q ( x ) q(x) q(x) | 近似分布(模型分布) |
| i i i, x x x | 离散事件/连续变量 |
2. 核心特性
2.1 基本性质
| 性质 | 数学表达 | 解释 |
|---|---|---|
| 非负性 | D K L ≥ 0 D_{KL} \geq 0 DKL≥0 | 当且仅当 P = Q P=Q P=Q时取零 |
| 非对称性 | D K L ( P ∣ Q ) ≠ D K L ( Q ∣ P ) D_{KL}(P|Q) \neq D_{KL}(Q|P) DKL(P∣Q)=DKL(Q∣P) | 不满足距离公理 |
| 可加性 | D K L ( P 1 × P 2 ∣ Q 1 × Q 2 ) = D K L ( P 1 ∣ Q 1 ) + D K L ( P 2 ∣ Q 2 ) D_{KL}(P_1 \times P_2 | Q_1 \times Q_2) = D_{KL}(P_1|Q_1) + D_{KL}(P_2|Q_2) DKL(P1×P2∣Q1×Q2)=DKL(P1∣Q1)+DKL(P2∣Q2) | 独立分布的散度可分解 |
2.2 信息论解释
- 表示用 Q Q Q近似 P P P时增加的信息量(单位:nats或bits)
- 与交叉熵关系: D K L ( P ∥ Q ) = H ( P , Q ) − H ( P ) D_{KL}(P\|Q) = H(P,Q) - H(P) DKL(P∥Q)=H(P,Q)−H(P)
2.3 统计特性
- 在指数族分布中有闭式解
- 大样本下与似然比检验统计量渐进等价
3. 优缺点对比
| 优点 | 缺点 |
|---|---|
| ✅ 具有明确的信息论解释 | ❌ 不满足对称性 |
| ✅ 对分布差异敏感 | ❌ 对 Q = 0 Q=0 Q=0而 P > 0 P>0 P>0的点未定义 |
| ✅ 适用于概率分布比较 | ❌ 不满足三角不等式 |
| ✅ 与MLE理论关联强 | ❌ 实际计算可能数值不稳定 |
4. 变体与改进
4.1 对称化KL散度
D s y m ( P , Q ) = 1 2 [ D K L ( P ∥ Q ) + D K L ( Q ∥ P ) ] D_{sym}(P,Q) = \frac{1}{2}[D_{KL}(P\|Q) + D_{KL}(Q\|P)] Dsym(P,Q)=21[DKL(P∥Q)+DKL(Q∥P)]
4.2 JS散度(Jensen-Shannon)
D J S ( P ∥ Q ) = 1 2 D K L ( P ∥ P + Q 2 ) + 1 2 D K L ( Q ∥ P + Q 2 ) D_{JS}(P\|Q) = \frac{1}{2}D_{KL}\left(P \middle\| \frac{P+Q}{2}\right) + \frac{1}{2}D_{KL}\left(Q \middle\| \frac{P+Q}{2}\right) DJS(P∥Q)=21DKL(P 2P+Q)+21DKL(Q 2P+Q)
4.3 Renyi散度
D α ( P ∥ Q ) = 1 α − 1 log ∑ i P ( i ) α Q ( i ) 1 − α D_\alpha(P\|Q) = \frac{1}{\alpha-1} \log \sum_{i} P(i)^\alpha Q(i)^{1-\alpha} Dα(P∥Q)=α−11logi∑P(i)αQ(i)1−α
上述损失函数的区别总结
| 损失函数 | 适用任务 | 对异常值敏感度 | 梯度特性 | 典型应用场景 |
|---|---|---|---|---|
| MSE | 回归 | 高(平方放大) | 光滑 | 房价预测 |
| MAE | 回归 | 低(绝对值) | 在0点不可导 | 鲁棒回归 |
| Huber Loss | 回归 | 可调(通过δ) | 分段光滑 | 带噪声的回归数据 |
| 交叉熵 | 分类 | - | 对错误预测梯度大 | 神经网络分类 |
| Hinge Loss | 分类 | 低 | 稀疏(支持向量) | SVM |
| Focal Loss | 分类 | - | 聚焦难样本 | 类别不平衡的分类任务 |
| 对比损失 | 度量学习 | 依赖样本对设计 | 依赖距离度量 | 人脸识别 |
| Triplet Loss | 度量学习 | 依赖三元组设计 | 需调整margin | 特征嵌入学习 |
| KL散度 | 生成模型 | - | 非对称(分布差异) | VAE、生成对抗网络 |

















 1569
1569

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









