




 文章介绍了回归问题中常见的损失函数,如MSE、MAE、Huber、Log-cosh和Quantile损失函数,强调了它们在处理离群点和模型复杂度方面的差异。此外,文章还讨论了数据分布不均和数值偏差对损失函数的影响,提出加权损失函数和数据增强作为解决方案,并提及将回归问题转化为分类问题的策略。
文章介绍了回归问题中常见的损失函数,如MSE、MAE、Huber、Log-cosh和Quantile损失函数,强调了它们在处理离群点和模型复杂度方面的差异。此外,文章还讨论了数据分布不均和数值偏差对损失函数的影响,提出加权损失函数和数据增强作为解决方案,并提及将回归问题转化为分类问题的策略。
损失函数Loss Function的设计是机器学习模型的核心问题,一般情况下函数式子会分成两项:衡量预估值和目标间的差距、正则项式
。其中正则项式子一般用于衡量模型的复杂度,可以避免模型过拟合(奥卡姆剃刀原理)。
另一部分衡量预估值和目标间差距的函数,是本文所重点介绍的,比如MSE损失函数用于预估值与目标值的均方误差,在实际情景中,这部分的损失函数可能包含从多种方面反映预估同目标差距的组合,比如存在多个目标的情况。另一种情况是包含反映某些中间结构偏离的损失,但这种中间结果偏离一般不建议直接引入损失函数中,多数学者认为损失函数应只包含预测同目标直接相关的损失,中间结果的偏离损失(从先验知识中得到的)应该通过正则项引入。
本文将主要介绍回归类问题的常见损失函数,在实际工业场景中,很难直接认为某种损失函数更好,而是结合自身模型和目标的实际,去设计合适的损失函数(不一定是如下的几种)能精确衡量预测同目标的差距,更重要的是能帮忙模型去正确学习。
1. MSE损失函数
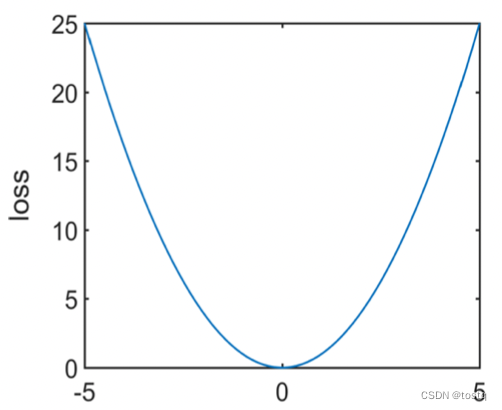
MSE损失函数又被称为平方损失square loss,或者L2损失,其定义为:
当在mini-batch中,计算batch的损失时,一般有两种方式(mean或sum),下式中n表示mini-batch的size。
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









