







语义分割技术综述
本文就Image Segmentation Using Deep Learning: A Survey
第三章的模型进行了分析和介绍,第一第二章的基础指示可以看原文进行学习,相关知识有很多这里就不班门弄斧了。
最好是一边读原文一边看本文效果更佳原文连接
能力有限,水平一般,抱着学习的态度分享此文,有不准确的地方还请各位大佬斧正!
3.1 全卷积网络
关于FCN的资料有很多这里就不展开了
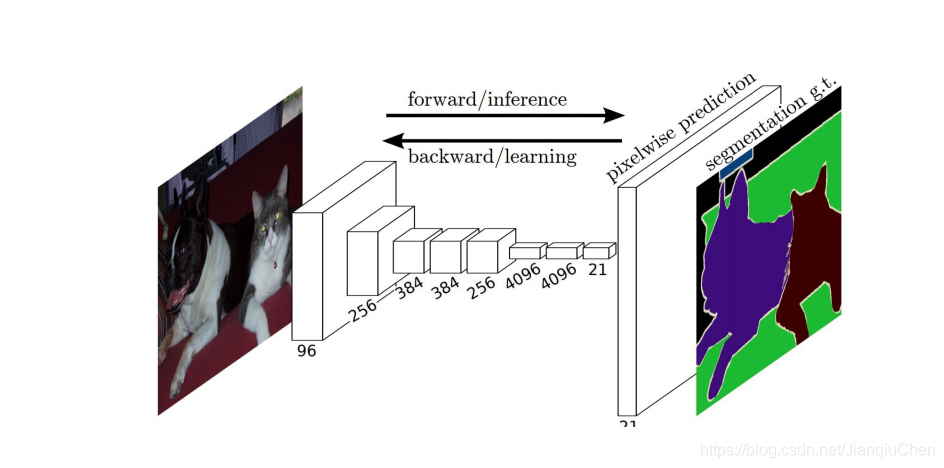
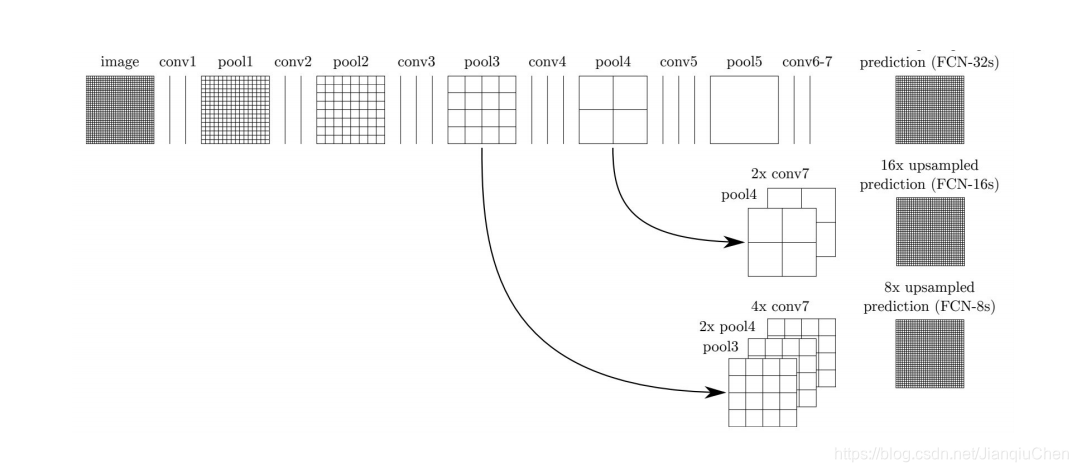
下图为升级版的FCN(跳跃连接)
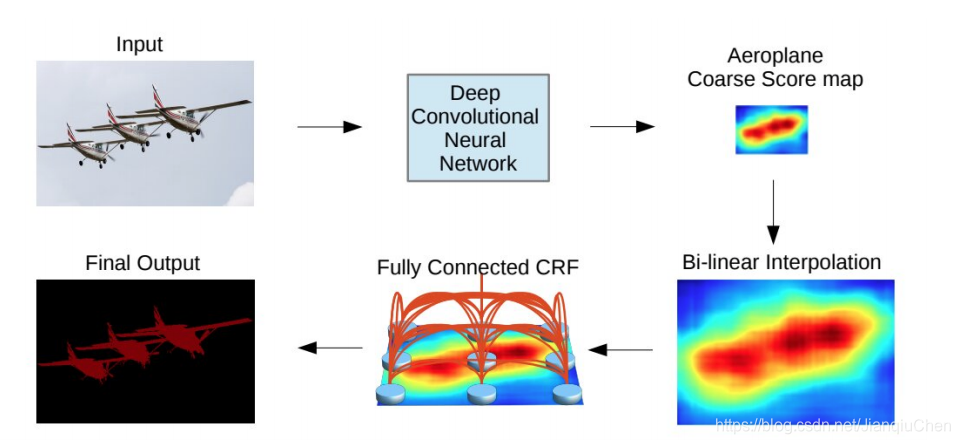
3.2 带图像的卷积模型
CNNs+全连接的CRF以解决深度卷积网络最后一层的定位不足以进行精确的对象分割的问题。 这种模型可以更好的定位分割边界。
3.3 解码器编码器模型
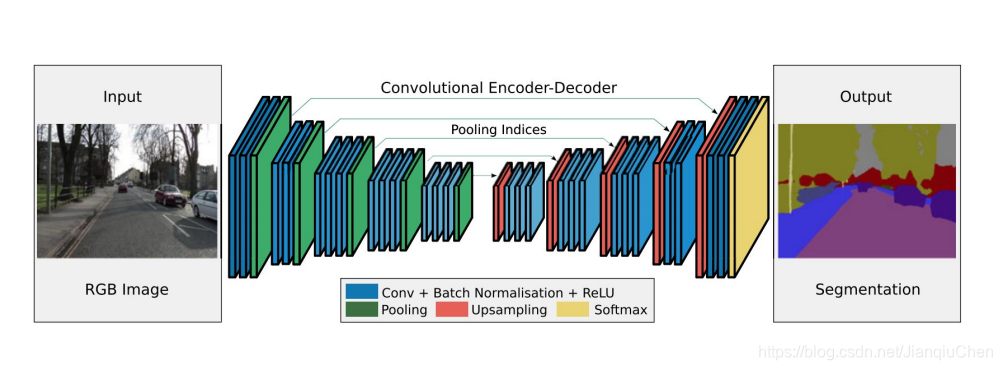
如下图所示,左侧是编码器结构(VGG-16),右侧是解码器结构
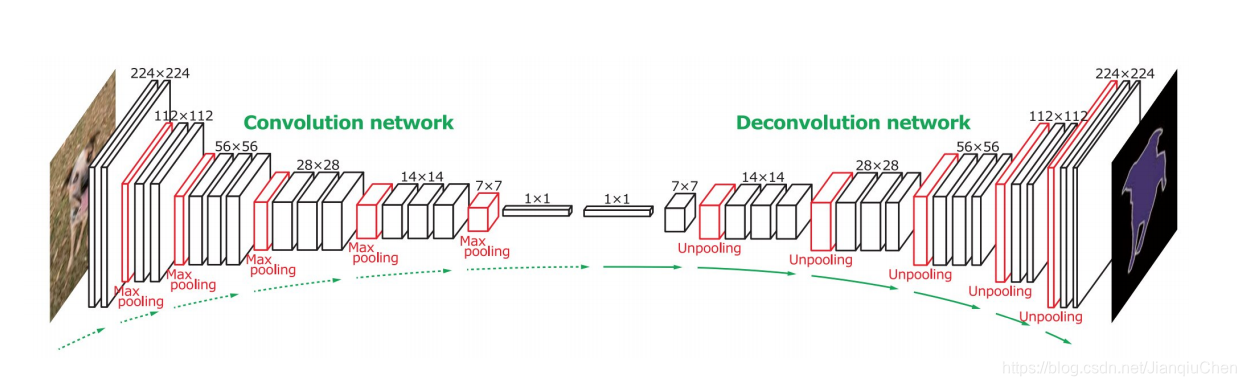
一种更优的网络Segnet。encoder是一个沿用VGG16的网络模型,主要对物体信息进行解析。decoder将解析后的信息对应成最终的图像形式,即每个像素都用对应其物体信息的颜色(或者是label)来表示。
Encoder对图像的低级局域像素值进行归类与分析,从而获得高阶语义信息
Decoder对缩小后的特征图像进行上采样, 并使用之前max-pooling的索引进行上采样。
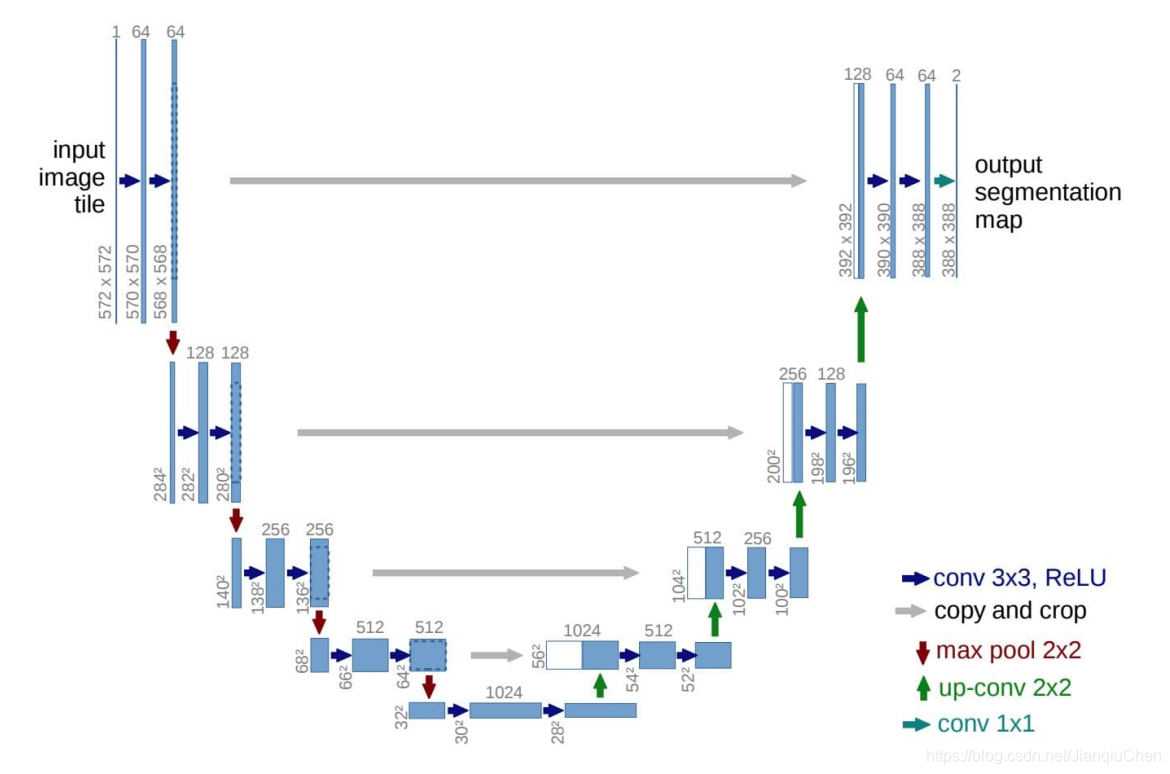
编码器解码器结构应用于医学的模型
U-net 和V-net 在这个领域表现良好,并在其他领域也有优秀贡献
U-net的提出是最初是在用于显微镜下的图片语义分割。
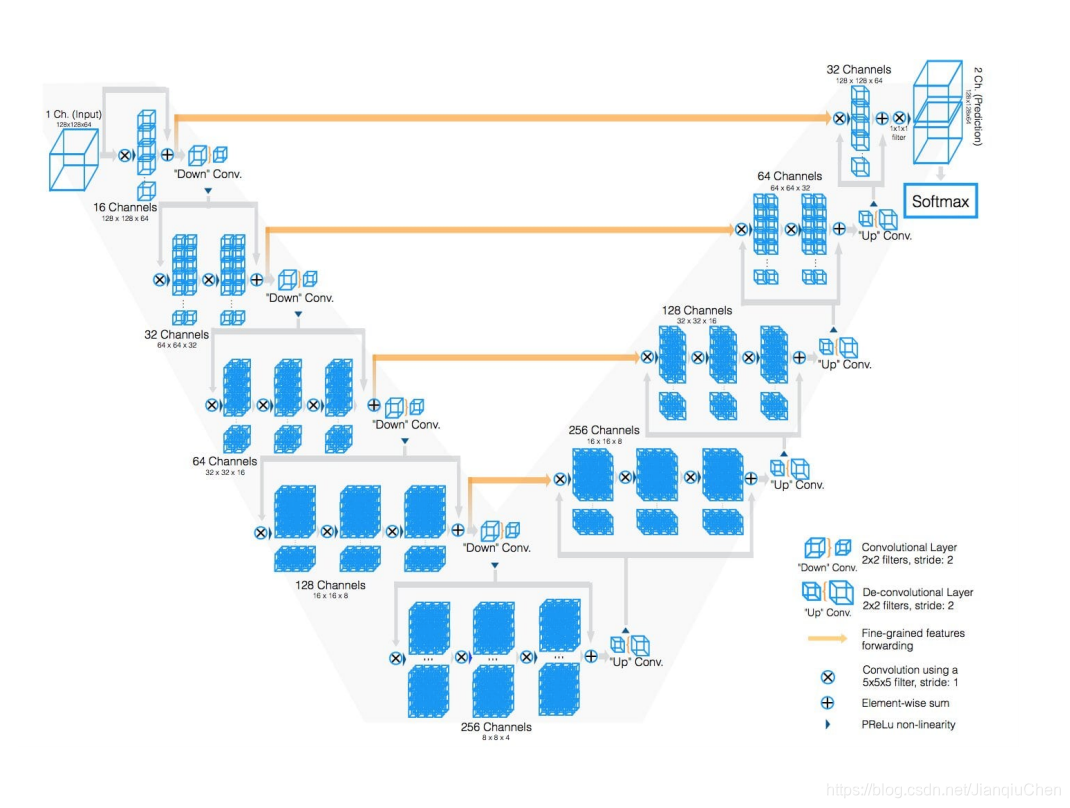
U-net 有两个主要部分,分别是收缩并捕获信息和扩张并精准定位。
左侧是特征提取部分 使用3x3的卷积和max pool进行编码。
右侧是上采样部分,每上采样一次,就和特征提取部分对应的通道数相同尺度融合,但是融合之前要将其crop。这里的融合也是拼接。
V-net也是基于FCN的模型,主要用于3D 医学图像的分割, 使用了一种客观的Dice coefficient。这种方法可以解决前景和后景图像体素不平衡的问题。
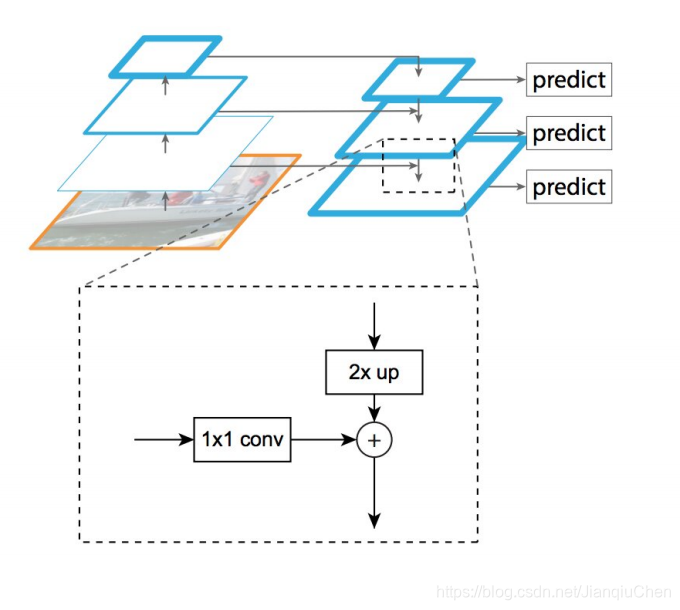
3.4 基于多尺度和金字塔网络的模型
Feature Pyramid Network (FPN) 网络
FPN 将bottom-up 和 top-down 过程进行横向连接。
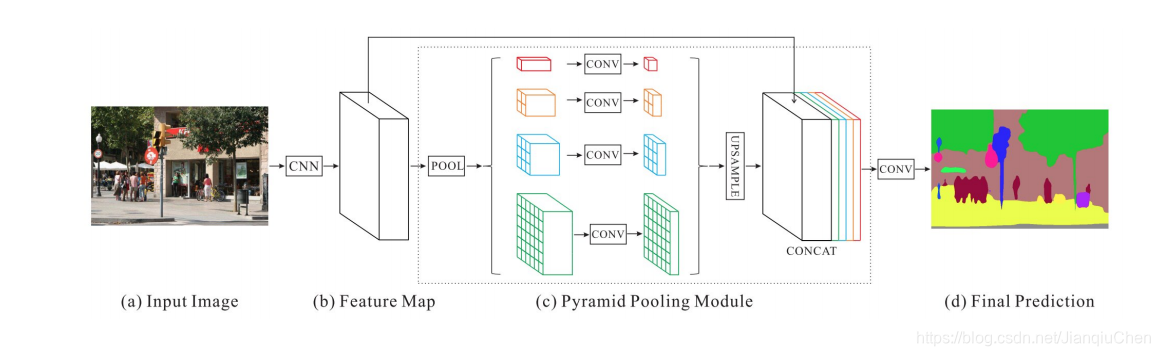
Pyramid Scene Parsing Network (PSPN) 也是基于多尺度的网络。PSPN更好的学习全局信息。PSPN不同的是使用了带有空洞卷积的参差网络ResNet作为特征提取。
首先输入图像经过一个特征提取网络提取特征,这部分作者采用的是添加了空洞卷积的ResNet网络,空洞卷积的作用前面也提到过了,主要是增大感受野,提取到的特征(具体而言stride=8)作为后面pyramid pooling模块的输入。在pyramid pooling模块中构建了深度为4的特征金字塔,不同深度的特征是基于输入特征通过不同尺度的池化操作得到的,池化的尺度是可以调整的,这篇文章中给出的池化后的特征尺寸分别是11、22、33和66。然后通过一个1*1卷积层将特征维度缩减为原来的1/4,最后将这些金字塔特征直接上采样到与输入特征相同尺寸,然后和输入特征做合并,也就是concat操作得到最终输出的特征图。特征合并的过程其实就是融合目标的细节特征(浅层特征)和全局特征(深层特征,也就是上下文信息)的过程,这里因为特征提取网络最后输出的特征层感受野足够大,所以有足够的全局信息(虽然网络的深度不算深),个人认为如果这里能够融合更多的浅层特征(比如stride=4的那一层),也许分割结果在细节方面会更好一些
还有一种Laplacian Pyramid Reconstruction
网络高层特征富含语义信息,低层特征更多是结构信息。在本文提出的特征融合策略中,高层特征的预测输出通过一定方法(类似于拉式金字塔的做法)得到边缘的区域,然后从低层特征的预测结果中拿出这部分和高层输出结合在一起。即:大范围的语义信息取自高层特征,边缘信息取自低层特征。
3.5 R-CNN 模型
Fast R-CNN, Faster R-CNN, Maksed-RCNN 这些模型已经非常成功在目标检测领域。关于RCNN和目标检测见RCNN。
几个优秀的实例分割模型
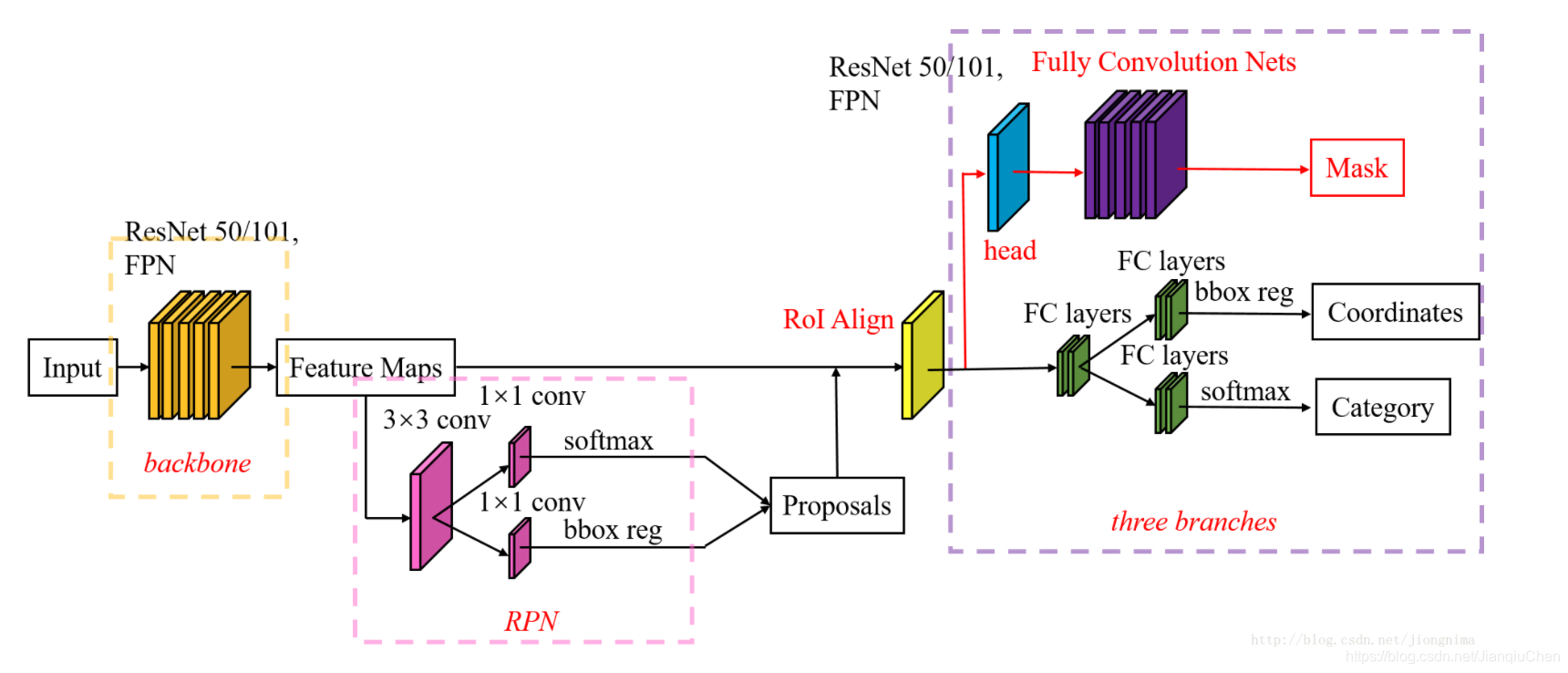
Mask R-CNN
mask Rcnn 是基于faster rcnn基础上改版而来的。
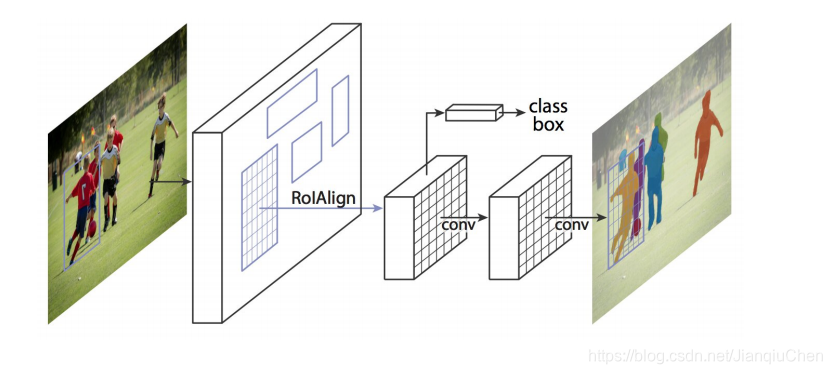
Mask-Rcnn的网络结构
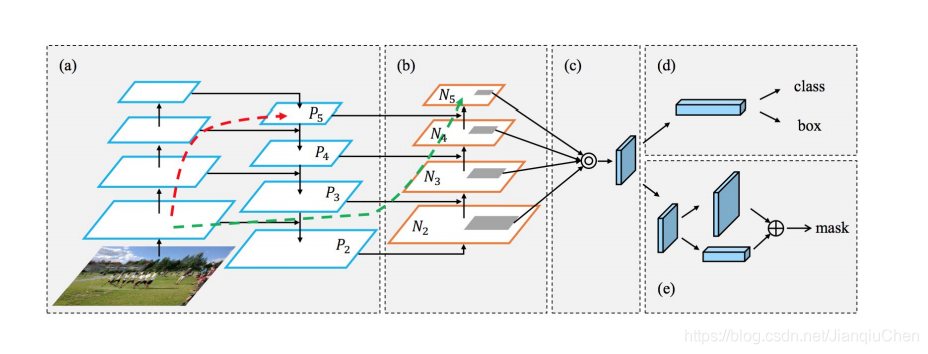
The Path Aggregation Network
3.6 空洞卷积模型和Deeplab 家族
空洞卷积提供了更大的感受野:例如3x3的卷机核在dilation rate为2的时候有和5x5的卷积核一样的感受野,但仅用了9个参数。如下图。

Deeplab V1:
使用空洞卷积和CRF(条件随机场)解决之前模型池化导致的信息丢失和标签之间的概率模型没有被应用的问题
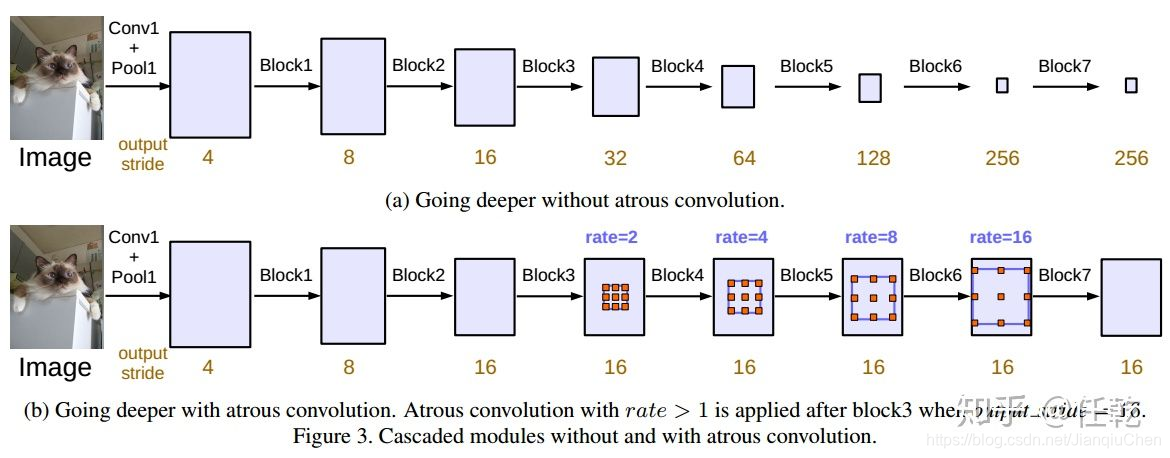
空洞卷积的主要作用是在增大感受野的同时,不增加参数数量,而且VGG中提出的多个小卷积核代替大卷积核的方法,只能使感受野线性增长,而多个空洞卷积串联,可以实现指数增长。
DeepLab V2:
DeepLab V2相对于DeepLab V1做了以下改进:
1)用多尺度获得更好的分割效果(ASPP)
2)基础层由VGG16改为ResNet
3)使用不同的学习率
其中ASPP的引入是最大也是最重要的改变。多尺度主要是为了解决目标在图像中表现为不同大小时仍能够有很好的分割结果,比如同样的物体,在近处拍摄时物体显得大,远处拍摄时显得小。具体做法是并行的采用多个采样率的空洞卷积提取特征,再将特征融合,类似于空间金字塔结构,形象的称为Atrous Spatial Pyramid Pooling (ASPP)。具体形式如下图所示
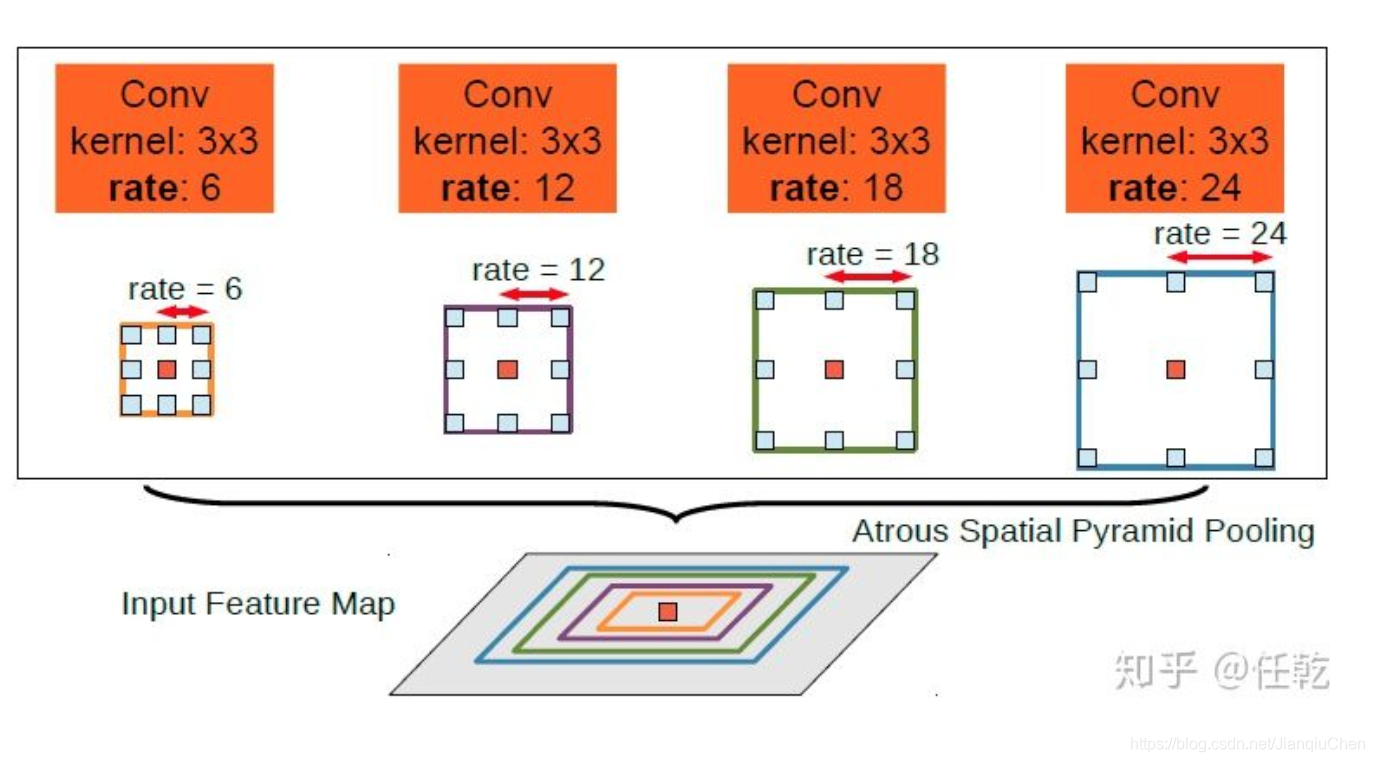
DeepLab V3:
1)提出了更通用的框架,适用于任何网络
2)复制了ResNet最后的block,并级联起来
3)在ASPP中使用BN层
4)去掉了CRF
block 4 是Resnet的最后一个模块
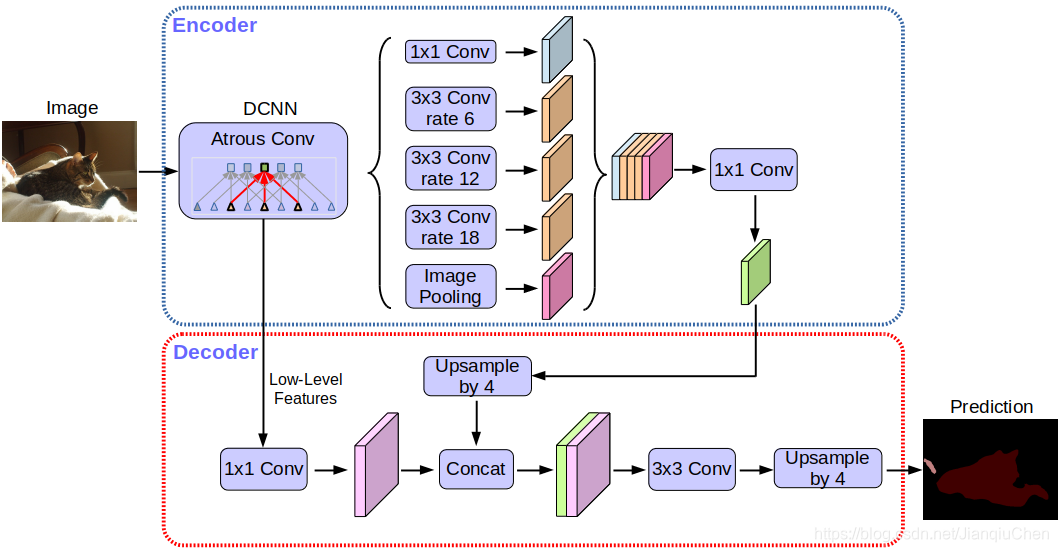
deeplab v3+
加入编码器解码器构造,可以通过改变Atrous rate 实现精度和时间的平衡
3.7 基于循环神经网络模型
用两个 RNNs 水平的扫描图像,一个从上倒下,一个从下往上。每一个 RNN 将一个 patch 拉直以后的向量作为输入,然后更新其 hidden state,沿着输入图像 X 的每一个 column 进行。
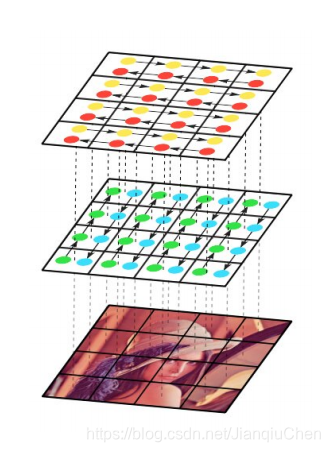
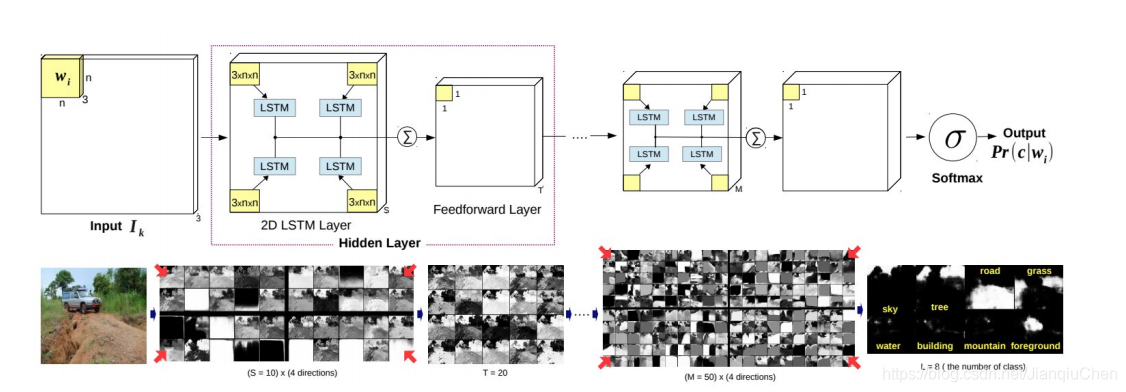
还有一种2D-LSTM的结构
输入图像被分成多个不重叠的窗口,每个窗口的RGB通道传入4个单独的LSTM模型。每个窗口有左上,左下,右上,右下4个方向。每个LSTM块的输出通过前向传播层,然后对每个方向进行求和并应用双曲正切。最后对最后的LSTM块进行求和并送入softmax。
graph-LSTM
使用LSTM网络的动机:传统的CNN大多是捕捉有限的局部信息,但是在语义预测的时候往往需要的是全局的信息。例如“举起的胳膊”这种,对比躯干才能判断胳膊是举起的还是放下的
- 输入的RGB图像首先经过预处理,使用SLIC来生成超像素的图像,在此基础上构建graph LSTM
- 原RGB图像经过5层cnn,获得feature map,该feature map分为两路继续进行
- 第一路 经过1X1的卷积层,获得confidence map(置信度map)
- 第二路 输入到LSTM
- 将更新序列作为上一步的输入,加快收敛速度(参差连接)
- 1X1的卷积获得置信度map,得到结果
更新序列排序: 通过将超像素的confidence进行排序,confidence最高的那个节点先更新。如果同时出现了置信度一样的两个节点,则先更新空间上偏左的那个
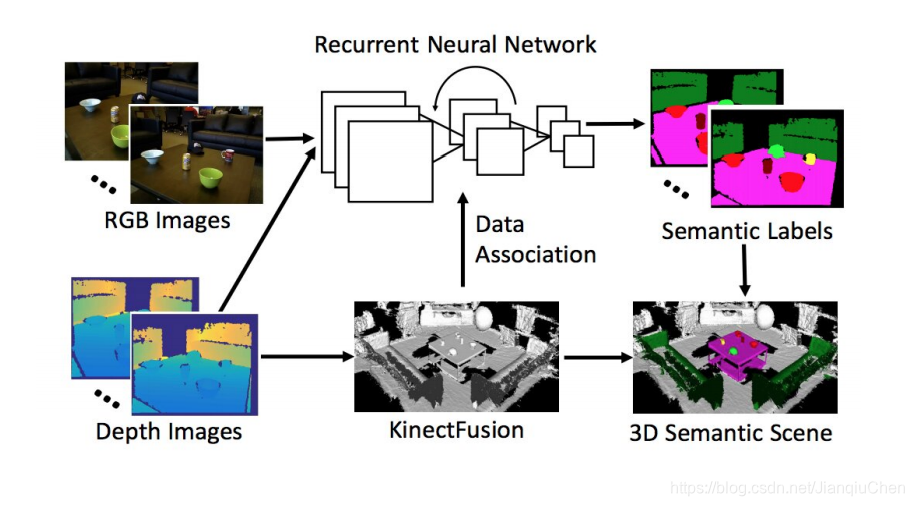
DA-RNN: 用于连接3D场景和语义标注
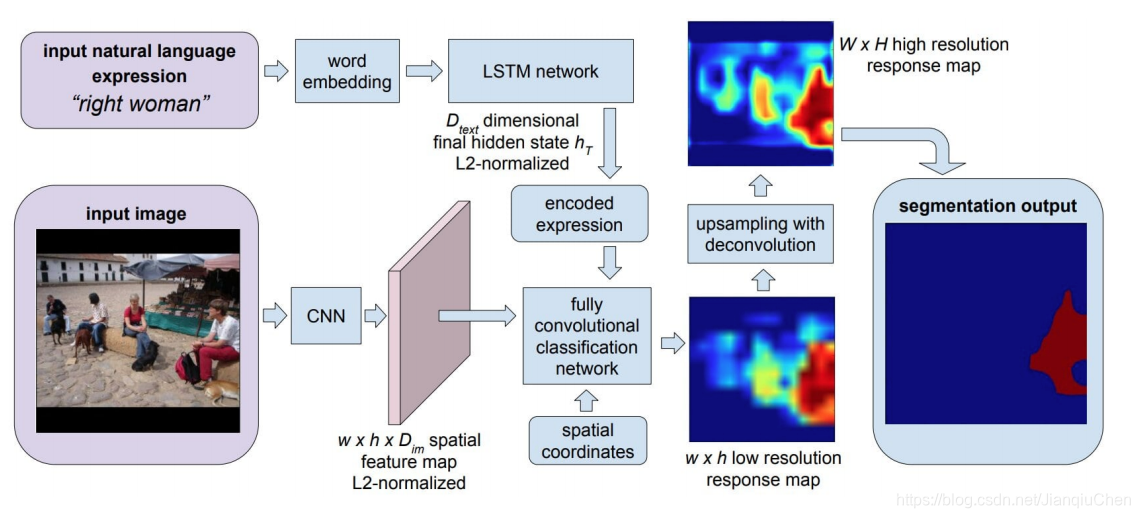
基于自然语言表达的语义分割算法:
使用CNN和LSTM分别对图像和图像描述进行编码
将描述进行向量表述并和图像的fcn模型进行融合
具体该模型工作原理可以看
R. Hu, M. Rohrbach, and T. Darrell, “Segmentation from natural language expressions,” in European Conference on Computer Vision. Springer, 2016, pp. 108–124.
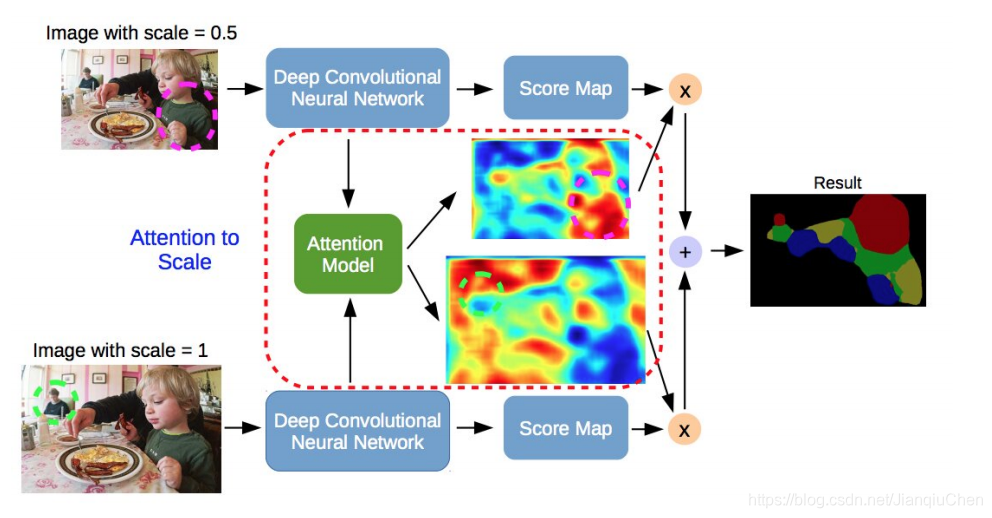
3.8 注意力机制模型
注意力机制模型对不同对比例图像赋予不同对权重(例如下图的模型赋予大权重在小比例的人 进行1.0缩放,对近处的小孩进行小缩放0.5)
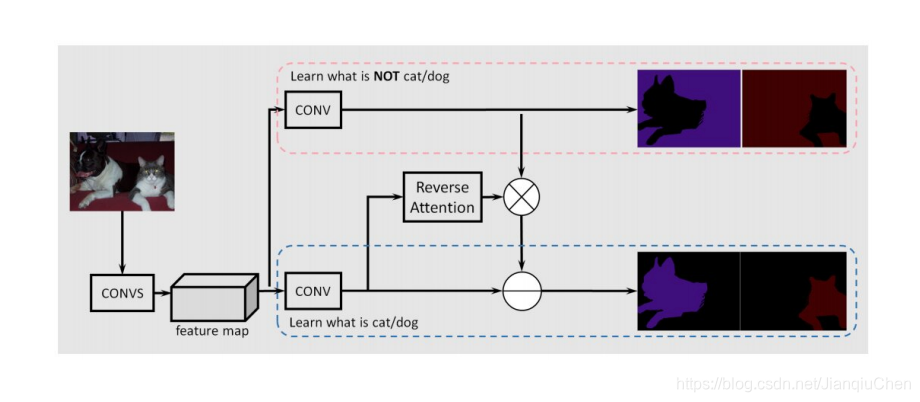
反向注意力机制:
此模型有三个分支:
第一个分支 学习的是pixel属于各个类别的概率分布;
第二个分支 学习的是pixel不属于各个类别的概率分布;
第三个分支 学习的是第一二个branch预测的map之间结合的权重;
Dual Attention network:
采用移除down-sampling的dilated ResNet(与DeepLab相同)的预训练网络基础网络为,最后得到的feature map大小为输入图像的1/8。之后是两个并行的attention module分别捕获spatial和channel的依赖性,最后整合两个attention module的输出得到更好的特征表达。
这篇文章有详细的讲解在此引用一下JimmyHua的DAnet笔记
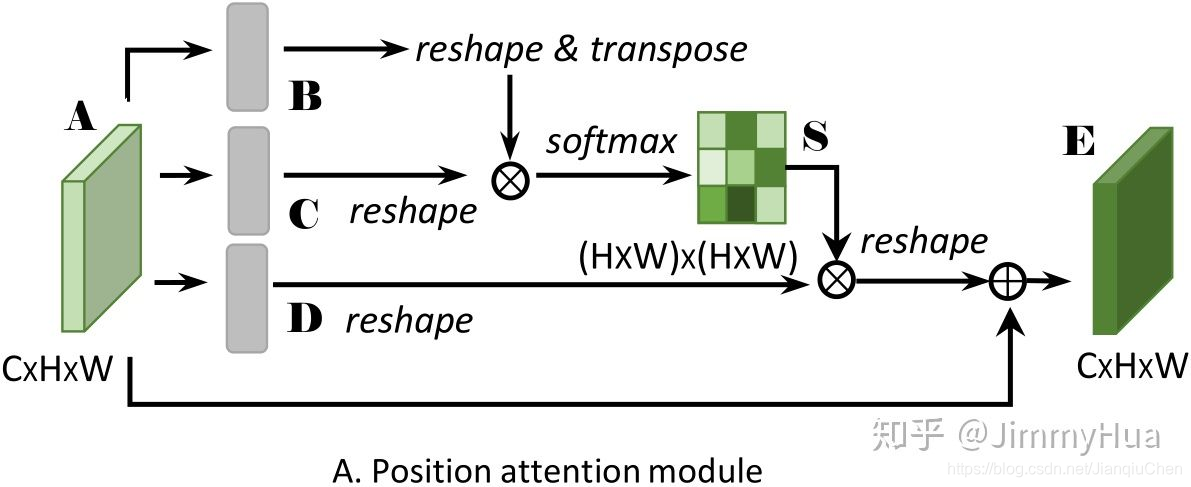
上半部分(Position Attention Module):
捕获特征图的任意两个位置之间的空间依赖,对于某个特定的特征,被所有位置上的特征加权和更新。权重为相应的两个位置之间的特征相似性。因此,任何两个现有相似特征的位置可以相互贡献提升,而不管它们之间的距离。
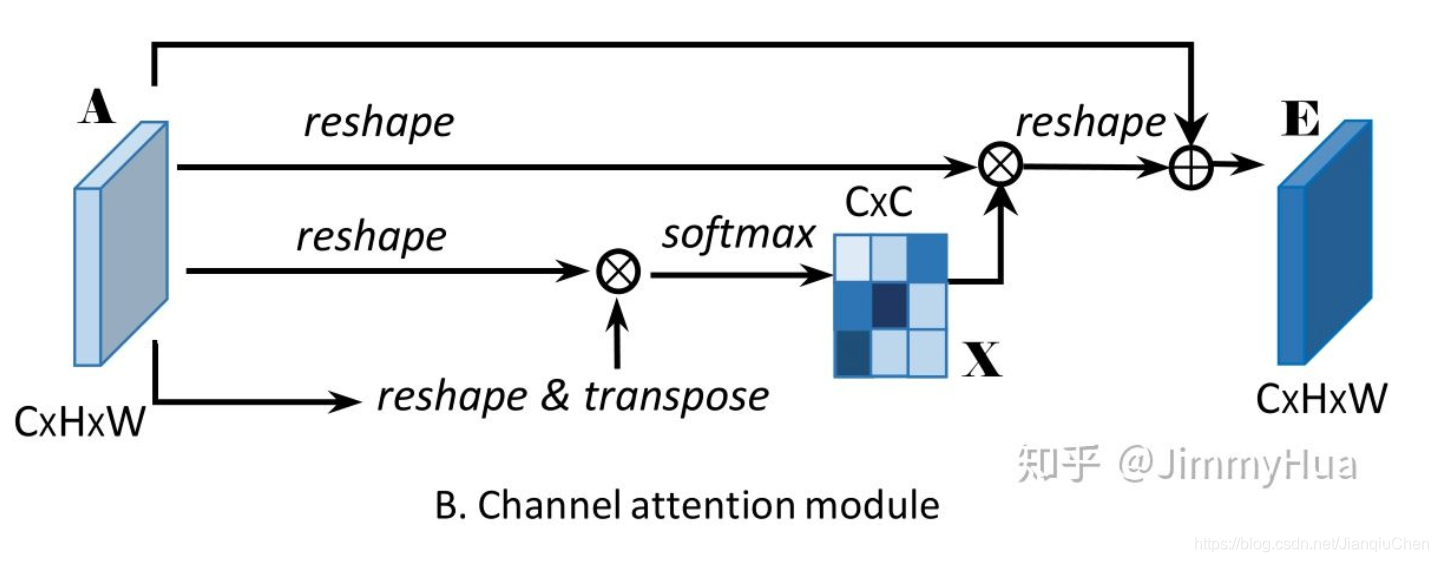
下半部分:
每个高层次特征的通道映射都可以看作是一个特定于类的响应,不同的语义响应相互关联。通过探索通道映射之间的相互依赖关系,可以强调相互依赖的特征映射,提高特定语义的特征表示。
两个attention module的输出先求和再做一次卷积得到最后的预测特征图
3.9生成模型和对抗训练
将模型生成的预测图或者真实的ground truth图像一同放入对抗网络
组合1:原始训练图片+ground truth, 这时候判别器判别为 1 标签;
组合2:原始训练图片+Segmentor分割结果, 这时候判别器判别为0标签。
这样可以优化原始的损失函数,加入了对抗网络的损失函数, 提高分割精度,提高鉴别能力。
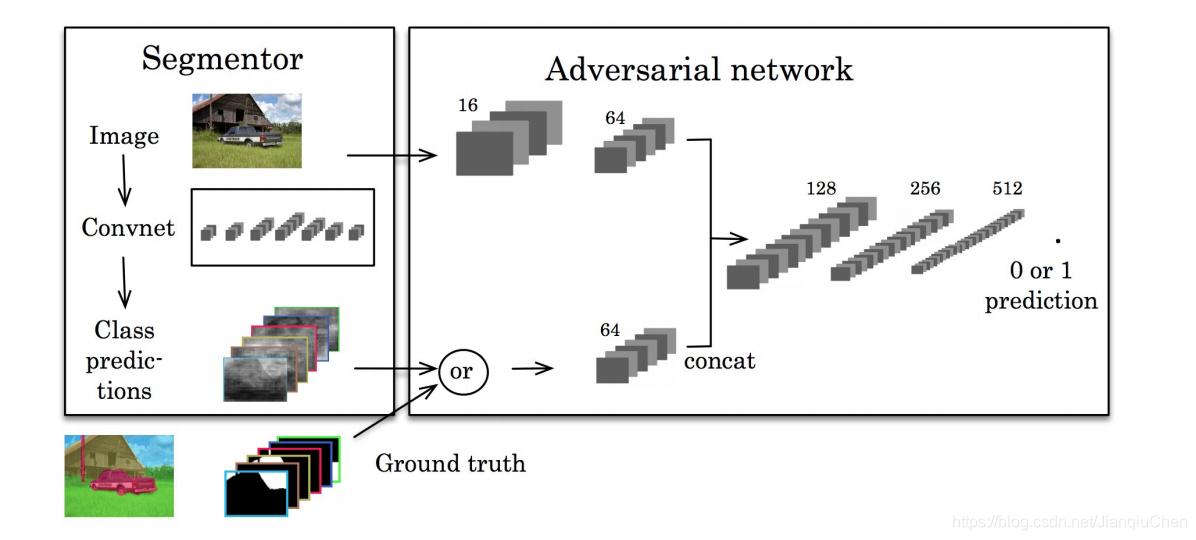
效果如图所示

弱监督的对抗网络语义分割:
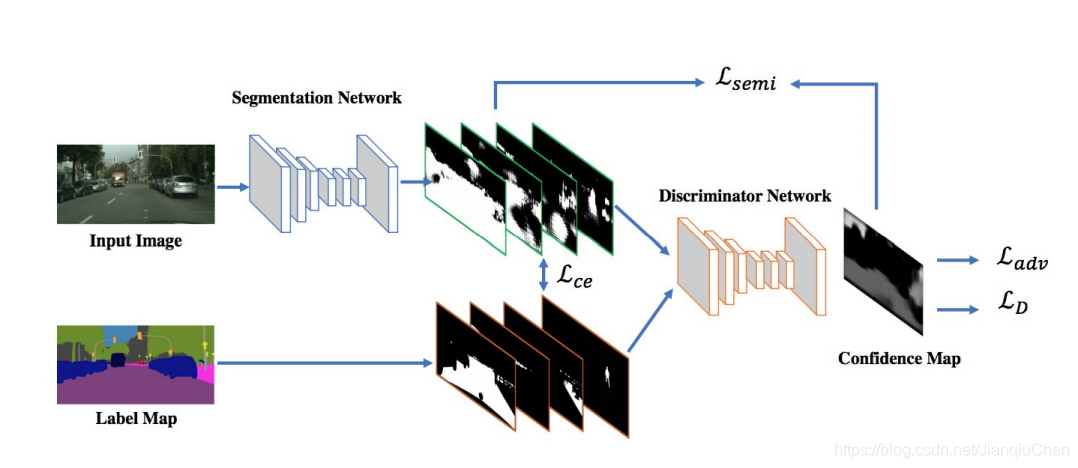
假设分割类别数为K,那么判别器则有K+1个类别的输出。多出来的分类类别为”该像素为假像素”。训练时,使用标记的分割图像训练前K个通道,使用(真实图片,生成图片)图片组按照adversarial loss的定义训练”该像素为假像素”的通道。真是图片既有分割数据库中的图片,也有大量未标注的图片。或者也可以理解为判断“真/假”的分类器,其“真”的这一类扩展成了K类具体的语义类别。
对于全卷积化的判别器,其改动就是将分类结果变为输入图片大小的dense prediction。从判断每一个样本的真伪变为每一个像素的真伪。这样独立的”该像素为假像素”通道才能和K类分割输出放在一起。
除此之外,文章中提出的模型分为了’semi-supervised’和’weakly-supervised’,用以区分扩展用的数据是完全没有标注还是使用了分类标签。对于使用分类标签的’weakly-supervised’模型,GAN的生成器使用conditional GAN,将图片的分类标签作为输入。
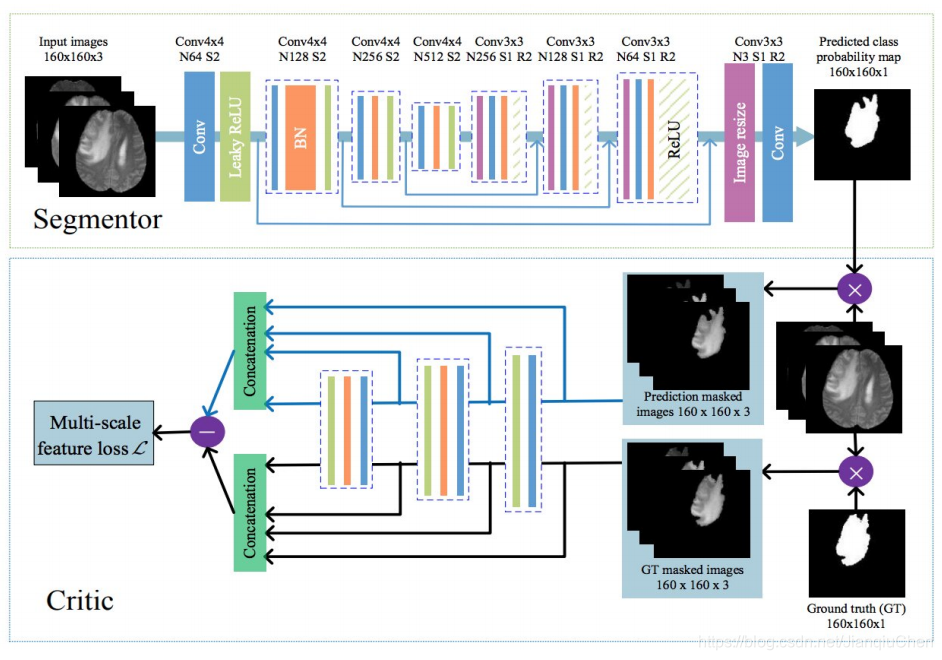
应用于医学的多尺度L1 Loss的语义分割模型:
整个网络分为segmentor和critic两部分:
1、segmentor部分为unet结构,encoder部分为4层stride=2的卷积,decoder部分为4层upsample,输出为网络预测的肿瘤二值图像;
2、critic部分的网络共用segmentor部分encoder的前三层,分别向critic部分输入经预测的肿瘤二值图掩膜的原始输入图像,以及经真值肿瘤二值图掩膜的原始输入图像,最后的loss计算两个不同输出之间的MAE值(L1 loss)。其中Multi-scale体现在对critic部分每一个卷积层输出的特征图像都计算MAE值,最后的总loss取平均。
3、训练方式类似于GAN的min-max对抗学习过程。首先,固定S(segmentor),对C(critic)进行一轮训练;再固定C(critic),对S(segmentor)进行一轮训练,如此反复。对 critic 的训练想使loss变大(min),对 segmentor 训练想使loss变小(max)。
3.10 图像分割的主动轮廓线学习模型
将轮廓线的长度加入损失函数
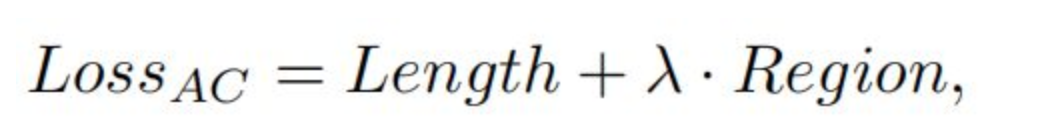
感兴趣的可以看一下这篇笔记,感觉讲的很不错这边就不多赘述了
图像分割的主动轮廓线学习模型
3.11 其他模型
EncNet:使用基础的特征提取将特征图送入上下文编码模型
RefineNet:该网络显式地利用下采样过程中的所有可用信息来启用使用远程残差连接的高分辨率预测
Seednet:使用强化学习的方式解决交互式分割的问题
Feedforward-Net:将小图像元素(超像素)映射到从一系列范围不断扩大的嵌套区域中提取的丰富特征表示。这些区域是通过从超像素一直“缩小”到场景级分辨率而获得的。
全景分割:全景分割将语义分割(为每个像素分配一个类标签)和实例分割(检测并分割每个对象实例)的典型任务统一起来。拟议的任务需要生成一个丰富而完整的连贯场景分割,这是迈向现实世界视觉系统的重要一步。
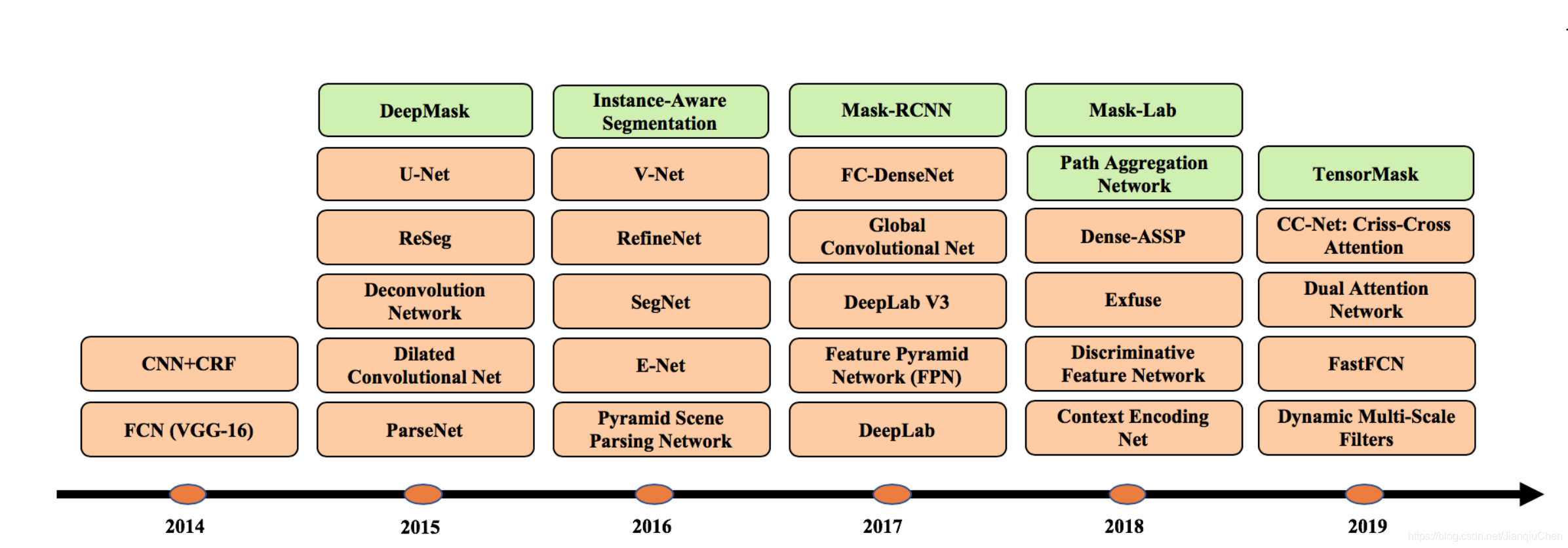
语义分割优秀模型一览
引用:
https://blog.csdn.net/u014380165/article/details/83869175
https://zhuanlan.zhihu.com/p/75333140
https://zhuanlan.zhihu.com/p/59055363
https://blog.csdn.net/u010158659/article/details/78649827
https://blog.csdn.net/qq_26020233/article/details/88790378

















 92
92

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









