







二十年前,“混合”一词仅在植物学和化学领域使用。如今,“混合”这个概念在搜索领域一片繁荣,许多搜索系统都在推出基于 AI 技术的混合搜索方案。但是,“混合搜索”是真的具有应用价值,还只是流行的一阵风呢?
许多搜索系统都在推出混合搜索功能,混合搜索将传统搜索中的关键字、文本信息检索技术和基于 AI 的“向量”或“神经”搜索结合在一起。“混合搜索”是否只是一个流行词呢?毕竟基于文本的搜索是一项应用广泛的技术,以至于用户早已习惯了它的特点,甚至是局限性。将文本搜索与新的 AI 技术结合真的能为搜索系统锦上添花吗?
答案显而易见:这取决于实际情况。
现在的数据存储是多媒体和多模态的,文本、图像、视频和音频常常存储在同一数据库和同一计算机上。这意味着,如果你想在五金商店的网站上搜索螺丝刀的图片,你不能只查询“螺丝刀”这个词,就期望它能返回相应的结果。首先你得存储并索引文本或商品的标签。除非你明确地将数据库中所有螺丝刀的图片与“螺丝刀”这个标签或其他文本相关联,表明它是螺丝刀的图片,否则利用传统的搜索技术是无法返回搜索结果的。如果你没有明确的标签和文本,将最先进的 AI 技术添加到文本搜索中将不会有任何帮助。这样的话,那么将 AI 技术与传统搜索结合就没有意义了。
假设有一个拥有网购平台的大型五金商,售卖数十万种不同的商品。但是,他们没有员工制作详细的产品标签和描述或检查它们的准确性;没有商品图片,也没有时间拍摄好的图片。这样的话,对他们来说,最好的文本搜索系统也是一个的有缺陷的解决方案。最新的 AI 技术可以很好地解决这些局限性。深度学习和 神经搜索[1] 让创建强大的通用神经网络模型成为可能,并将搜索模型以一种通用的方式应用于不同类型的数据中——文本、图像、音频和视频。因此,即使没有文本标签,搜索“螺丝刀”也可以找到螺丝刀的图片!
但是这些最新的搜索技术,返回的结果通常缺乏可解释性。客户可能希望输入查询“十字螺丝刀”,实际返回“开槽和十字螺丝刀,4 寸长”的产品。传统的搜索技术可以做到,但 AI 技术却很难达到这样的效果。
搜索模型
我们将基于三个特定的搜索模型搭建混合搜索引擎:BM25, SBERT 和 CLIP。
BM25 是最经典的基于文本的信息检索算法。BM25 最早发展于 1990 年代,现在已经被广泛使用。有关 BM25 的更多信息,请参阅 Robertson & Zaragoza(2009)[2],2000a[3] 和 2000b[4] ,或查看 维基百科上关于 BM25 的演示[5]。我们利用 Python 的 [rank_bm25] 包,实现了 BM25 排名算法。
SBERT[6] 是一个广泛用于文本信息检索的神经网络框架,我们使用的是 msmarco-distilbert-base-v3[7] 模型,因为它是为 MS-MARCO 段落排名任务训练的,与我们所做的排名任务差不多。
CLIP[8] 是一个连接的图像和描述文本的神经网络,它是在图像-文本对上训练的。CLIP 有许多应用,在本文我们中将使用它实现文本查询和图像匹配,并返回排名结果。我们使用的是 OpenAI 的 clip-vit-base-patch32[9] 模型,这也是使用最广泛的 CLIP 模型。
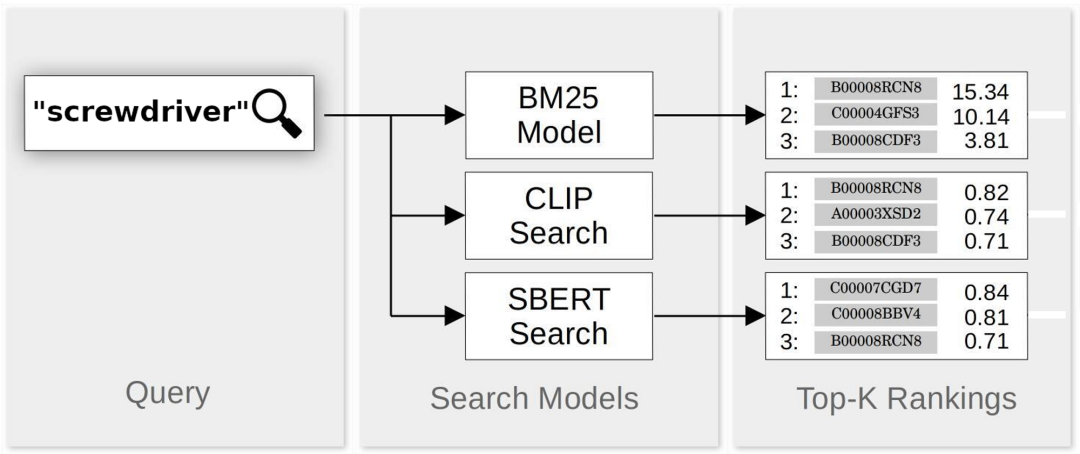
三种模型都是对文本查询的匹配结果进行评分和排名,然后返回一些排名靠前的结果(结果数由用户决定)。这三种模型都很容易集成。SBERT 和 CLIP 返回的分数都在 -1.0(查询最差匹配)到 1.0(查询最佳匹配)之间。BM25 分数最低为 0.0,但没有上限。为了方便比较,我们进行了以下处理:
去除 CLIP 或 SBERT 返回的小于 0.0 的结果,因为这些都是错误的匹配结果。
利用公式将 BM25 分数归一化到 0.0 到 1.0 之间:将 BM25 分数除以本身加上 10。
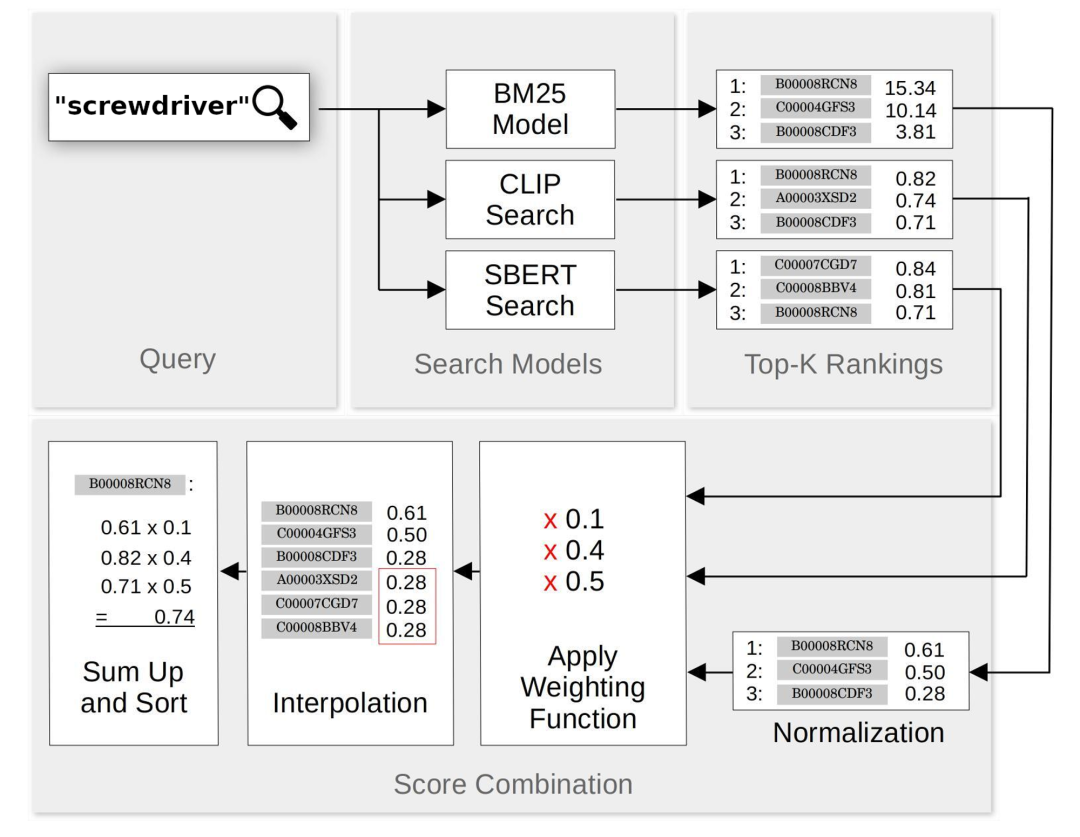
当匹配结果出现在一个或两个,但不是所有三个搜索方法的顶部结果中时,我们会为错过它的搜索方法分配一个内插分数。如果请求前 N 个匹配项,我们会为缺失的匹配项分配一个较小的非零值,该值是经验值。
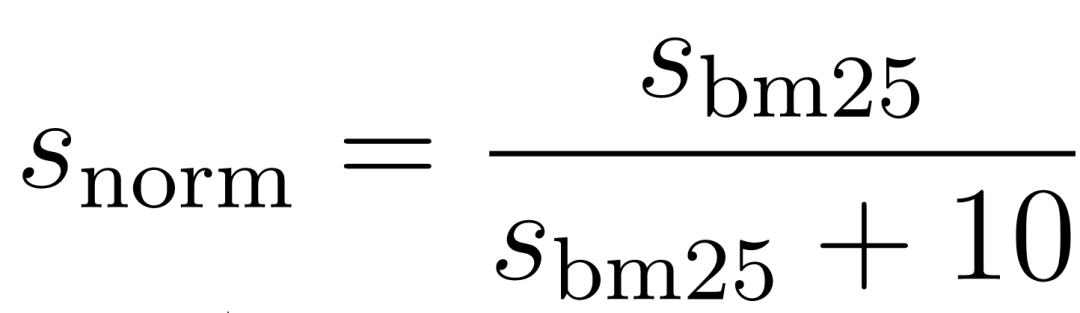
例如,假设我们搜索“螺丝刀”,并从 BM25、SBERT 和 CLIP 中获得了 20 个最佳匹配项。BM25 和 SBERT 搜索都在前 20 个匹配中识别出了产品“磁头螺丝刀 6 件套,3 个十字头和 3 个平头”,但 CLIP 的前 20 个匹配中没有该产品,因为图片是它的包装盒。这时,我们会找到 CLIP 前 20 个匹配结果中的最低分数,并将 这个分数分配给 “磁头螺丝刀 6 件套,3 个十字头和 3 个平头”这个产品。
混合搜索
我们构建了一个混合搜索方案,该方案结合了 BM25、SBERT 和 CLIP 的搜索结果。对于每个查询,我们都使用 3 种系统完成搜索,从每个系统中检索出 20 个最佳匹配,并按照上一节中的描述调整它们的分数。每个匹配项的分数都是 3 个搜索系统(SBERT、CLIP 和归一化的 BM25)的分数的加权和。下面是混合搜索方案工作的示意图:
在实际应用中,我们发现以下的权重组合效果很好:
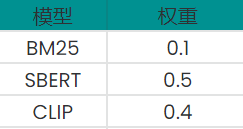 对于这个结果,我们可以直观地理解为,混合搜索系统在文本检索(SBERT 和 BM25)上的权重略大于 0.5 ,在文本到图像检索(CLIP)上的权重略小于 0.5 ,BM25 的 0.1 权重确保了对传统术语匹配的偏好,或者在神经模型无法产生好的匹配结果时作为补充。
对于这个结果,我们可以直观地理解为,混合搜索系统在文本检索(SBERT 和 BM25)上的权重略大于 0.5 ,在文本到图像检索(CLIP)上的权重略小于 0.5 ,BM25 的 0.1 权重确保了对传统术语匹配的偏好,或者在神经模型无法产生好的匹配结果时作为补充。
搜索方案比较
测试数据
理想情况下,我们应该拥有在线商家的产品数据库和查询日志。但是,出于商业和法律原因,公司(特别是虚构的公司)通常不会向研究人员提供产品数据库和查询日志。因此,我们只能使用替代方案。
我们使用了最接近的替代方案:XMarket dataset 数据集[10]。这些数据来自 18 个国家的亚马逊市场,包括亚马逊网站上的产品图像,以及产品名称、产品描述、类别和各种元数据。本文中,我们使用了 XMarket 数据集的一个子集:仅使用来自于美国亚马逊网站的电子产品类别中的条目,涉及 837 个类别,15934 种产品。此外,在每个产品的可用信息字段中,我们仅使用了以下内容:
ASIN — 亚马逊分配的唯一产品 ID。
标题 — 亚马逊使用的产品名称。
描述 — 产品的文本描述,大概来自制造商或供应商。
类别 — 亚马逊分层产品本体中的一个标签。
图片 — 亚马逊在产品页上使用的图片。
下面是一个示例图:
 XMarket 数据集中的条目示例
XMarket 数据集中的条目示例
你可以通过登录 Jina AI (在命令行中输入 jina auth login,访问现有帐户或创建帐户)并使用 DocArray[11] 模块下载数据:
from docarray import DocumentArray
xmarket_dataset = DocumentArray.pull('xmarket_dataset')
xmarket_dataset.summary()╭────────────────── Documents Summary ───────────────────╮
│ │
│ Type DocumentArrayInMemory │
│ Length 16934 │
│ Homogenous Documents True │
│ Has nested Documents in ('chunks',) │
│ Common Attributes ('id', 'tags', 'chunks') │
│ Multimodal dataclass True │
│ │
╰────────────────────────────────────────────────────────╯
╭──────────────────────── Attributes Summary ────────────────────────╮
│ │
│ Attribute Data type#Unique values Has empty value │
│ ──────────────────────────────────────────────────────────────── │
│ chunks ('ChunkArray',) 16934 False │
│ id ('str',) 16934 False │
│ tags ('dict',) 16934 False │
│ │
╰─────────────────────────────────────────────────────任务描述
由于我们没有亚马逊的查询日志,因此我们无法对代表性样本的查询进行系统测试,所以只能选择类似但不同的任务。亚马逊在 XMarket 数据集中为每个产品分配了一个类别属性,并为这些类别分配了文本标签。例如,上一节中的 “Sandisk MicroSD 卡” 被归为 “Micro SD 卡” 类。我们用于比较的搜索任务是使用这些类别标签作为文本查询,然后检查查询结果是否为属于该类别的产品项。为了定量比较,我们使用 MRR (Mean Reciprocal Rank) 作为指标,按以下方式衡量:
使用类别标签查询搜索系统,检索返回的前 20 个排名最高的结果,然后找到实际上属于该类别的结果,最后为该查询分配 1.0/排名的分数。例如,如果输入查询“Micro SD 卡”,返回的第一个结果是属于“Micro SD 卡”的产品,那么这个查询的分数为 1.0。如果前四个结果不属于该类别,但第五个结果属于该类别,则分数为 0.2。如果前二十个结果都不属于该类别,则分数为 0.0。
对于每个搜索系统,我们通过对所有查询的分数求平均来计算 _MRR_。由于这取决于每个查询返回的结果数量,所以我们将分数标记为 MRR@20(返回 20 个结果)。
准备搜索数据库和索引
我们从 15934 种商品中选择了 1000 种用于测试,测试涵盖 296 个类别。其余数据将在下一节中使用。然后,通过获取测试集中每个产品的标题和描述来准备 BM25 索引,接着,利用 rank_bm25 包中的 BM25Okapi 算法,创建文本检索数据库。具体细节请参阅 GitHub 上的 README[12]。
对于 SBERT 模型,我们基于 Jina AI DocArray,使用测试集的标题和描述作为输入文本来创建向量检索数据库。
import finetuner
from docarray import Document, DocumentArray
sbert_model = finetuner.build_model('sentence-transformers/msmarco-distilbert-base-v3')
finetuner.encode(sbert_model, product_categories)
finetuner.encode(sbert_model, product_texts)对于 CLIP,我们采用了相同的步骤,但使用来自同一测试集的产品图像。
import finetuner
from docarray import Document, DocumentArray
clip_text_model = finetuner.build_model('openai/clip-vit-base-patch32', select_model='clip-text')
clip_vision_model = finetuner.build_model('openai/clip-vit-base-patch32', select_model='clip-vision')
finetuner.encode(clip_text_model, product_categories)
finetuner.encode(clip_vision_model, product_images)Baseline 结果
我们通过计算系统返回的前 20 个查询结果的 MMR@20 来评估三个搜索系统的性能:

这个结果并不令人惊讶。CLIP 是直接将文本查询与图像进行比较,而不是将查询与文本描述比较,所以性能比 BM25 差。虽然 CLIP 是直接比较文本查询与图像,但是它的 MRR@20 只是比 BM25 略低一点,这恰恰说明了 CLIP 的强大之处。尽管如此,我们可以预料到单纯的图像驱动的搜索系统很难满足现实用例的需求。
SBERT 基于神经方法进行文本搜索,平均性能比 BM25 更好。在这个数据集中,我们可以看出相比于图像信息,文本信息为搜索系统提供了更好的性能。
混合结果
这里使用的混合搜索引擎的具体实现,包括代码,请查看 Colab Notebook[13]。你可以使用自己的数据和用例尝试运行,看看这是否是适合的解决方案。我们使用相同的测试数据,对混合搜索方案进行了相同的测试。我们将三个搜索系统两两组合,然后将三个搜索系统组合在一起,完成了测试。最终,结果显示混合搜索系统的性能完胜单一搜索系统:
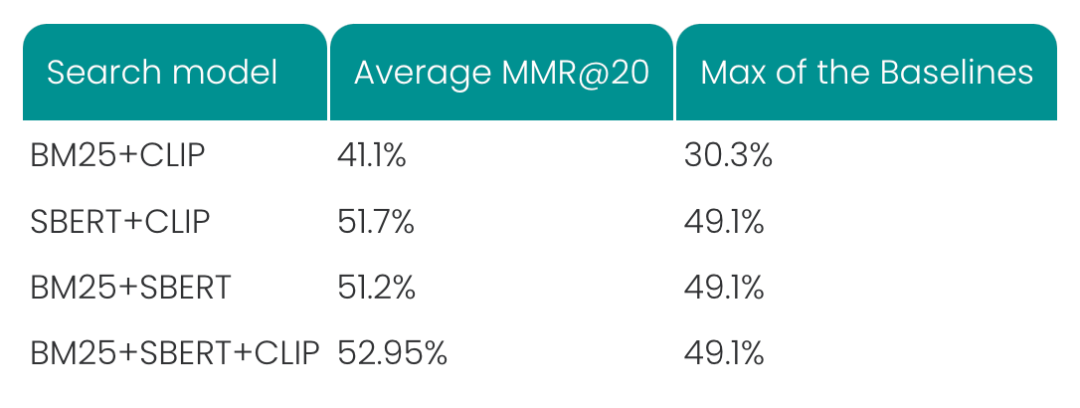
💡 混合搜索模型都比单独的搜索系统性能更好。
这些结果显示出了混合搜索方法的潜力,最大的提升来自于两个单独得分最差的模型: 混合 BM25 和 CLIP,得分从约 30% 提高到 41%,这说明文本和图像搜索是互补的。然而,与单独的 SBERT 搜索系统相比, SBERT + CLIP+ BM25 方法的提升并不明显,MMR 从 49% 的提高到了 53%,提升了 8%。
微调
微调是利用新任务的训练数据对预训练模型进一步训练,从而提高预训练模型的性能,适应于特定任务。Jina AI Finetuner[14] 是一款能够简化神经网络微调流程的工具,它通过处理云上的操作复杂性和物理基础架构,使得微调神经网络更容易,更高效。我们从 XMarket 数据集中选择了 1000 项作为测试数据,并利用剩下约 15000 项数作为训练数据来微调 SBERT 和 CLIP。
💡 训练集中只包含测试集中的部分类别,没有产品。
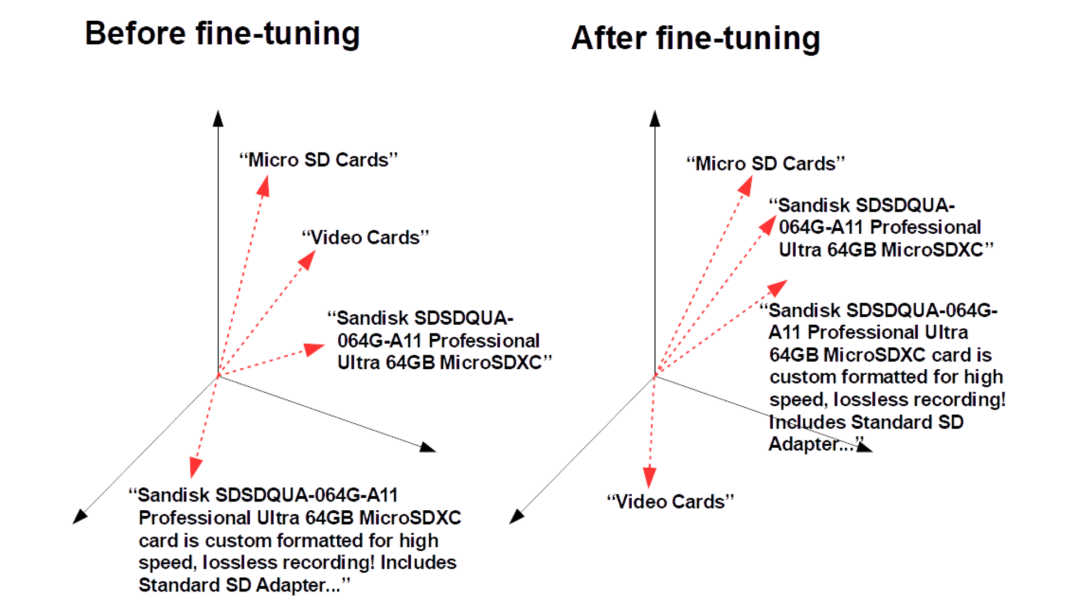
微调的图解表示:Jina AI Finetuner 通过训练神经网络使得属于一类的文本的输出向量更接近,不属于一类的输出向量距离更远。
对于 SBERT,首先从训练集中提取出产品标题、产品描述和类别名称。微调的目的是,通过训练 SBERT,使其能够识别同一类别的产品名称和描述,并且匹配它们的类别标签。为此,我们需要基于该信息,利用训练数据构建用于微调 SBERT 的 DocumentArray 对象,如 Jina AI Finetuner 文档[15] 中所述。
import finetuner
# login to finetuner api
finetuner.login()
# create and submit SBERT finetuning job
sbert_run = finetuner.fit(
model='sentence-transformers/msmarco-distilbert-base-v3',
train_data=sbert_train_data,
epochs=3,
batch_size=64,
learning_rate=1e-6,
cpu=False,
)
# Wait for the run to finish!
finetuned_sbert_model = finetuner.get_model(sbert_run.artifact_id)然后,提取成对的产品图像和类别名称,用相同的步骤构造用于微调的 CLIP DocumentArray 对象,其目的是通过训练模型使得类别名称向量和图像向量的距离更近。
# create and submit CLIP finetuning job
clip_run = finetuner.fit(
model='openai/clip-vit-base-patch32',
loss='CLIPLoss',
train_data=clip_train_da,
epochs=3,
batch_size=128,
learning_rate=1e-6,
cpu=False
)
# Wait for the run to finish!
finetuned_clip_text_model = finetuner.get_model(clip_run.artifact_id, select_model='clip-text')
finetuned_clip_vision_model = finetuner.get_model(clip_run.artifact_id, select_model='clip-vision')BM25 不是基于神经网络的,所以不能微调。与微调后的 SBERT 和 CLIP 模型相比,BM25 的劣势更加明显,因为它根本没有利用类别信息。微调 SBERT 和 CLIP 后,我们重新对测试集进行评估,结果如下所示:
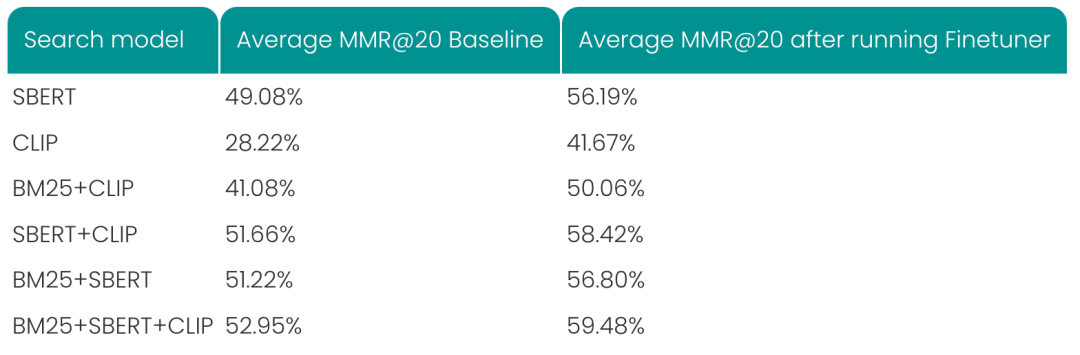
在所有的搜索系统中,我们都看到了微调后 MMR@20 的明显提升,其中微调后的 CLIP 表现突飞猛进。对于使用所有三种技术的混合搜索,相对改进超过 12%。
💡 基于神经网络的 AI 搜索技术的好处在于能够利用自己的数据集微调与训练模型,从而适应于特定任务。
为什么混合搜索如此高效呢?
很明显,混合搜索的效果很好,但是仅仅看定量指标还不能充分体现每个组件带来的改进。例如,对于查询“CD-RW 光盘”,BM25 对标注为“Verbatim CD-RW 700MB 2X-12X 可重写媒体光盘 - 25 包 主轴”的产品给出了很高的分数,这是正确的。

然而,SBERT 却被一段很长的描述文本误导了,这个描述中包含了许多与搜索词相关的术语:

Memorex 4x DVD+RW 25 包主轴。这 25 包用于较新的 DVD+R/+RW 驱动器 的 4x DVD+RW 光盘(部件号 32025541)由可重写的单面光盘组成,可存储 4.7 GB 的数据和大约 240 分钟的视频(取决于您的制作软件,120分钟最佳 )。一张光盘上可刻录超过六倍的数据。您可以从 VHS 或 8 毫米盒式磁带转移家庭录影、备份计算机硬盘和大文件,或者将它们装满 MP3 音乐文件和 数码相机的 JPEG 图像文件。可重写的“plus”光盘可以轻松地录制、弹出和播放它们,这要归功于“后台格式化”。此功能可缩短总刻录时间,优于“dash”格式。对于 PC 用户,DVD+RW 还提供了优于 DVD-RW 的功能,包括光盘内容编辑、内置缺陷管理和多会话写入。盒内物品包含 25 张 DVD+RW 光盘、1 个两件式存储盒和一张包含产品详细信息的纸质插页。
由于 CLIP 模型依赖于视觉相似性,所以它很难区分“CD-RW 光盘”和其他类型的光盘。如果去掉标签文本,对人类来说,它们也是一模一样的。CLIP 模型给出了最高排名,这个和用户查找的产品显然不相符:

当查询输入与描述不匹配,但与产品图片的可视化分析匹配时,CLIP 表现出色。例如,查询“耳塞式耳机”与文本标签“Maxell 190329 便携式轻型脑后延长舒适柔软触感橡胶记忆颈带立体声线颈带头塞 - 银色”不匹配。但它却和下图匹配:


SBERT 在产品拥有良好的文本信息的情况下表现出色,即使匹配不是精确的。例如,查询“光纤电缆”SBERT 返回的匹配结果见下图:

相比之下,CLIP 对于这个查询却起不到任何作用,因为它无法从视觉上与其他电缆区分,识别出光纤电缆,CLIP 返回的最佳匹配产品如下:

C2G 31348 Cat6 电缆 - Snagless 非屏蔽以太网网络跳线电缆,橙色
将 Hybrid Vigor 融入你的搜索系统
即使是在干净的视觉数据和详细的描述的情况下,基于文本检索技术与 AI 驱动的神经检索相结合的混合搜索,也比单独的搜索技术效果更好。现实中的大多数用例都不理想,描述不准确、不充分或完全缺失,商品图片质量差或不存在的情况经常出现。当用户输入精确的文本查询时,他们希望搜索系统返回满意的结果。所以这三种技术缺一不可,它们对于满足用户需求,返回良好的匹配结果必不可少。
基于 Jina AI 的框架,将搜索结果与针对具体用例的微调相结合,用户可以搭建开箱即用的高质量的搜索应用。Jina AI 在前行的路上步履不停,我们致力于通过直观的 Python 框架和 NoCode 解决方案,为用户提供最先进的云原生神经 AI 平台。如有任何疑问,欢迎加入我们的 Slack 社区[16] 来联系我们。
作者简介
Michael Günther,Jina AI ML Scientist
Scott Martens,Senior Evangelist
译者简介
吴书凝,Jina AI 社区贡献者
原文链接
https://jina.ai/news/hype-and-hybrids-multimodal-search-means-more-than-keywords-and-vectors-2
参考资料
[1]
神经搜索: https://jina.ai/
[2]Robertson & Zaragoza(2009): https://www.nowpublishers.com/article/Details/INR-019
[3]2000a: https://doi.org/10.1016/S0306-4573(00)00015-7
[4]2000b: https://doi.org/10.1016/S0306-4573(00)00016-9
[5]Wikipedia 上关于 BM25 的演示: https://en.wikipedia.org/wiki/Okapi_BM25
[6]SBERT: https://www.sbert.net/
[7]msmarco-distilbert-base-v3: https://huggingface.co/sentence-transformers/msmarco-distilbert-base-v3
[8]CLIP: https://openai.com/blog/clip/
[9]clip-vit-base-patch32: https://huggingface.co/openai/clip-vit-base-patch32
[10]XMarket dataset 数据集: https://xmrec.github.io/
[11]DocArray Python: https://github.com/docarray/docarray
[12]README : https://github.com/dorianbrown/rank_bm25/blob/master/README.md
[13]Colab Notebook: https://colab.research.google.com/drive/1XcpiJT3QOaR8Sk0Sl-d3qGZzbsOzWtQE?usp=sharing
[14]Finetuner GitHub: https://github.com/jina-ai/finetuner
[15]Finetuner 文档: https://finetuner.jina.ai/walkthrough/create-training-data/
[16]Slack 社区: https://jina.ai/slack/
更多技术文章

点击“阅读原文”,即刻阅读原文














 1563
1563











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









