







文章目录

1. Abstract
SAM正在成为许多高级任务的基础步骤,如图像分割、图像字幕和图像编辑。然而,其巨大的计算成本使其无法在行业场景中得到更广泛的应用。计算主要来自高分辨率输入的Transformer架构。

研究者为这项基本任务提出了一种性能相当的加速替代方法。通过将任务重新表述为片段生成和提示,我们发现具有实例分割分支的常规CNN检测器也可以很好地完成该任务。具体而言,我们将该任务转换为研究充分的实例分割任务,并仅使用SAM作者发布的SA-1B数据集的1/50直接训练现有的实例分割方法。使用我们的方法,我们在50倍的运行时速度下实现了与SAM方法相当的性能。我们给出了足够的实验结果来证明它的有效性。


2. 背景介绍
SAM被视为一个里程碑式的愿景基础模型。它可以在各种可能的用户交互提示的引导下分割图像中的任何对象。SAM利用了在广泛的SA-1B数据集上训练的Transformer模型,这使其能够熟练地处理各种场景和对象。SAM为一项激动人心的新任务打开了大门,该任务被称为Segment Anything。这项任务,由于其可推广性和潜力,具有成为未来广泛愿景任务基石的所有条件。
然而,尽管SAM和后续模型在处理细分市场任何任务方面取得了这些进步和有希望的结果,但其实际应用仍然具有挑战性。突出的问题是与SAM架构的主要部分Transformer(ViT)模型相关的大量计算资源需求。与卷积技术相比,ViT因其繁重的计算资源需求而脱颖而出,这给其实际部署带来了障碍,尤其是在实时应用中。因此,这种限制阻碍了SA任务的进展和潜力。
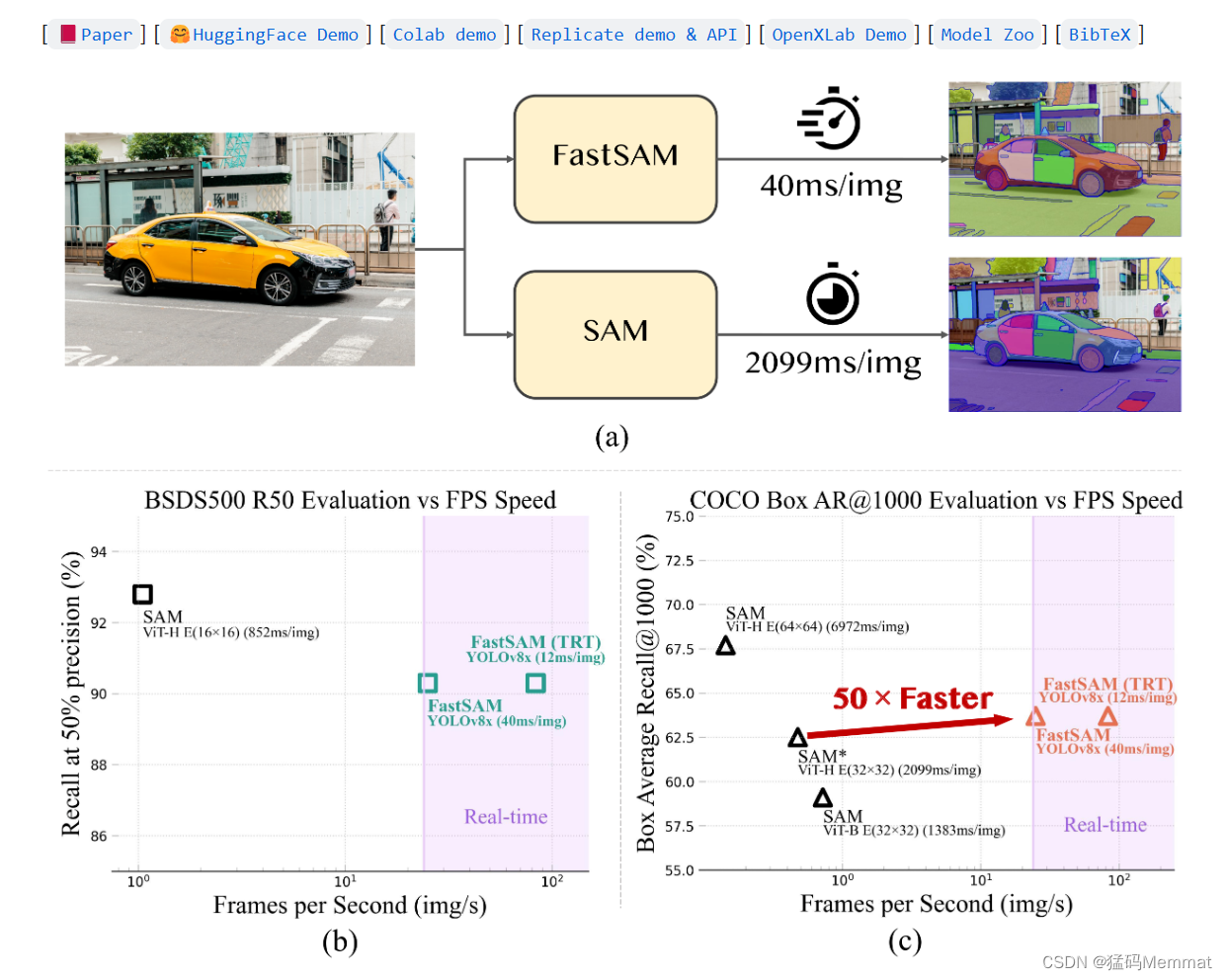



针对工业上对SAM实时分割的需求,本文设计了一个SA任务的实时解决方案FastSAM。我们将SA任务解耦为两个连续的阶段,即全实例分割(all-instance segmentation)和提示引导选择(prompt-guided selection)。第一阶段是基于卷积神经网络(CNN)检测器的实现。它生成图像中所有实例的分割掩码。然后在第二阶段,输出与提示符相对应的感兴趣区域。通过利用cnn的计算效率,我们证明了在不影响性能质量的情况下,任何模型的实时分段都是可以实现的。我们希望所提出的方法将促进分割任何东西的基本任务的工业应用。
我们提出的FastSAM基于YOLOv8-seg [16], YOLOv8-seg是一种配备实例分割分支的目标检测器,它利用了YOLACT[4]方法。我们还采用了SAM发布的广泛的SA-1B数据集。通过仅在SA-1B数据集的2%(1/50)上直接训练该CNN检测器,它实现了与SAM相当的性能,但大大减少了计算和资源需求,从而实现了实时应用。我们还将其应用于多个下游分割任务,以展示其泛化性能。在MS COCO上的目标提议任务[13]上,我们在AR1000下实现了63.7,比在32× 32点提示输入下的SAM高1.2分,但在单个NVIDIA RTX 3090上运行速度快50倍。
实时分段模型对工业应用很有价值。它可以应用于许多场景。所提出的方法不仅为大量的视觉任务提供了一种新的、实用的解决方案,而且速度非常快,比crre快几十倍或几百倍。它还为一般视觉任务的大型模型体系结构提供了新的视图。我们认为,对于特定的任务,特定的模型仍然可以获得更好的效率和准确性权衡。然后,在模型压缩的意义上,我们的方法证明了一条路径的可行性,该路径可以通过在结构之前引入人工先验来显着减少计算量。我们的贡献可以概括如下:
- 介绍了一种新颖的、基于cnn的实时SA任务解决方案,该解决方案在保持竞争性性能的同时显著降低了计算需求。
- 这项工作提出了将CNN检测器应用于SA任务的第一个研究,为轻量级CNN模型在复杂视觉任务中的潜力提供了见解。
- 在多个基准上对所提出的方法和SAM进行比较评估,可以深入了解该方法在SA领域中的优缺点。
2.0.1 TensorRT
TensorRT介绍: https://blog.csdn.net/weixin_42111770/article/details/114336102
pytorch模型(.pth)转tensorrt模型(.engine)几种方式:https://blog.csdn.net/qq_39056987/article/details/124588857
2.0.2 Zero-Shot
ZSLearning希望我们的模型能够对其从没见过的类别进行分类,让机器具有推理能力,实现真正的智能。其中零次(Zero-shot)是指对于要分类的类别对象,一次也不学习。
Zero-shot一种定义:利用训练集数据训练模型,使得模型能够对测试集的对象进行分类,但是训练集类别和测试集类别之间没有交集;期间需要借助类别的描述,来建立训练集和测试集之间的联系,从而使得模型有效。
Zero-shot(零次学习)简介: https://blog.csdn.net/gary101818/article/details/129108491
机器学习中通常需要大量的训练数据来训练模型,以便它能够准确地识别和分类新的输入。然而,在现实世界中,获取大规模标记数据集可能是昂贵和耗时的。因此,零样本学习、一次样本学习和少样本学习等技术应运而生,它们旨在解决这个问题。
零样本学习(Zero-Shot Learning)是一种能够在没有任何样本的情况下学习新类别的方法。通常情况下,模型只能识别它在训练集中见过的类别。但通过零样本学习,模型能够利用一些辅助信息来进行推理,并推广到从未见过的类别上。这些辅助信息可以是关于类别的语义描述、属性或其他先验知识。
一次样本学习(One-Shot Learning)是一种只需要一个样本就能学习新类别的方法。这种方法试图通过学习样本之间的相似性来进行分类。例如,当我们只有一张狮子的照片时,一次样本学习可以帮助我们将新的狮子图像正确分类。
少样本学习(Few-Shot Learning)是介于零样本学习和一次样本学习之间的方法。它允许模型在有限数量的示例下学习新的类别。相比于零样本学习,少样本学习提供了更多的训练数据,但仍然相对较少。这使得模型能够从少量示例中学习新的类别,并在面对新的输入时进行准确分类。
Zero-Shot, One-Shot, and Few-Shot Learning概念介绍: https://blog.csdn.net/weixin_42010722/article/details/131182669
3. 框架详情 (Methodology)
3.1 Overview
下图给出了所提出的FastSAM方法的概述。该方法由两个阶段组成,即所有实例分割(all-instance segmentation, ais)和提示引导选择(prompt-guided selection, pgs)。前一阶段是基础,第二阶段本质上是面向任务的后处理。与端到端变换器不同,整体方法引入了许多与视觉分割任务相匹配的人类先验,如卷积的局部连接和感受野相关的对象分配策略。这使得它能够针对视觉分割任务进行定制,并且可以在较小数量的参数上更快地收敛。
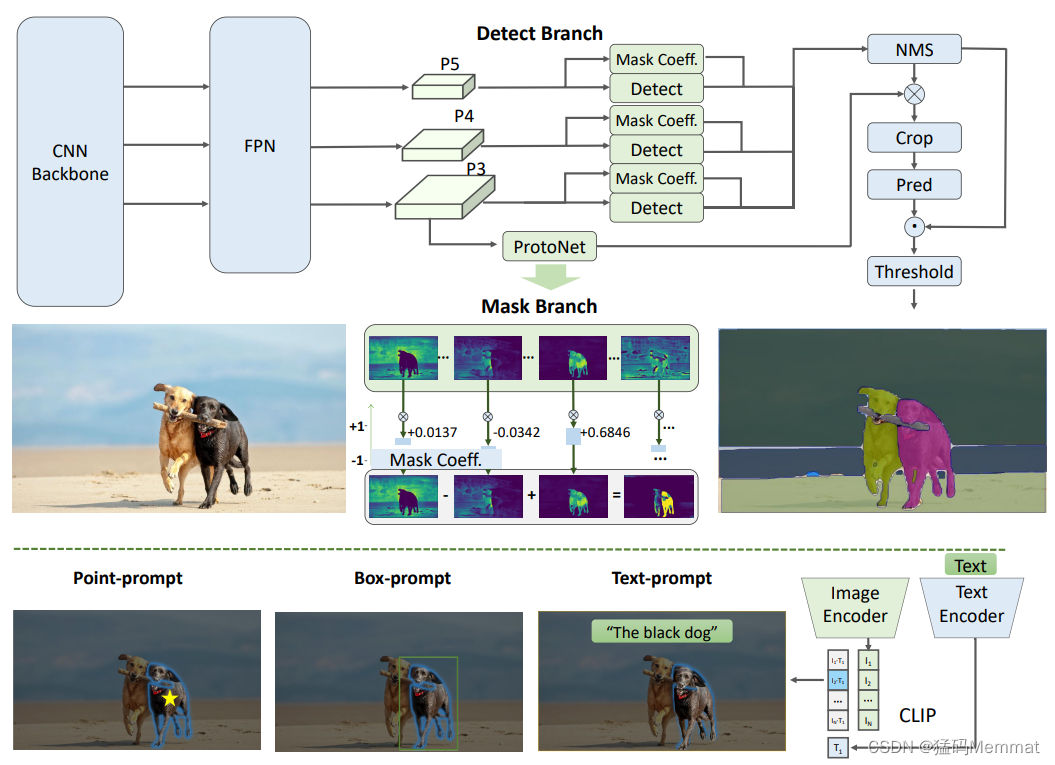
检测分支输出类别和边界框,而分割分支输出k个原型(在FastSAM中默认为32)以及k个掩码系数。分割和检测任务是并行计算的。分割分支输入高分辨率特征图,保留空间细节,还包含语义信息。该映射通过卷积层进行处理,放大,然后通过另外两个卷积层输出掩码。掩码系数,类似于探测头的分类分支,范围在-1和1之间。实例分割结果是通过将掩模系数与原型相乘,然后将其相加而获得的。
from fastsam import FastSAM, FastSAMPrompt
model = FastSAM('./weights/FastSAM.pt')
IMAGE_PATH = './images/dogs.jpg'
DEVICE = 'cpu'
everything_results = model(IMAGE_PATH, device=DEVICE, retina_masks=True, imgsz=1024, conf=0.4, iou=0.9,)
prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE)
# everything prompt
ann = prompt_process.everything_prompt()
# bbox default shape [0,0,0,0] -> [x1,y1,x2,y2]
ann = prompt_process.box_prompt(bbox=[[200, 200, 300, 300]])
# text prompt
ann = prompt_process.text_prompt(text='a photo of a dog')
# point prompt
# points default [[0,0]] [[x1,y1],[x2,y2]]
# point_label default [0] [1,0] 0:background, 1:foreground
ann = prompt_process.point_prompt(points=[[620, 360]], pointlabel=[1])
prompt_process.plot(annotations=ann,output_path='./output/dog.jpg',)
3.2 All-instance Segmentation

3.3 Prompt-guided Selection
在使用YOLOv8成功分割图像中的所有对象或区域之后,分割任何对象任务的第二阶段是使用各种提示来识别感兴趣的特定对象。它主要涉及点提示、框提示和文本提示的使用。
Point prompt 包括将选定的点与从第一阶段获得的各种遮罩进行匹配。目标是确定点所在的遮罩。与SAM类似,我们在方法中使用前地面/背景点作为提示。在前景点位于多个遮罩中的情况下,可以利用背景点来过滤出与手头任务无关的遮罩。通过使用一组前景/背景点,我们能够在感兴趣的区域内选择多个遮罩。这些遮罩将合并为一个遮罩,以完全标记感兴趣的对象。此外,我们还利用形态学运算来提高掩模合并的性能。
Box prompt 长方体提示涉及在选定长方体和与第一阶段中的各种遮罩相对应的边界框之间执行并集交集(IoU)匹配。其目的是用所选框识别具有最高IoU分数的掩码,从而选择感兴趣的对象。
Text prompt 在文本提示的情况下,使用CLIP模型提取文本的相应文本嵌入。然后确定相应的图像嵌入,并使用相似性度量将其与每个掩模的内在特征相匹配。然后选择与文本提示的图像嵌入具有最高相似性得分的掩码。
通过仔细实施这些提示引导选择技术,FastSAM可以从分割图像中可靠地选择感兴趣的特定对象。上述方法提供了一种实时完成任何分割任务的有效方法,从而大大提高了YOLOv8模型在复杂图像分割任务中的实用性。一种更有效的即时引导选择技术留给了未来的探索。
3.3.1 CLIP
clip.py
import hashlib
import os
import urllib
import warnings
from typing import Any, Union, List
from pkg_resources import packaging
import torch
from PIL import Image
from torchvision.transforms import Compose, Resize, CenterCrop, ToTensor, Normalize
from tqdm import tqdm
from .model import build_model
from .simple_tokenizer import SimpleTokenizer as _Tokenizer
try:
from torchvision.transforms import InterpolationMode
BICUBIC = InterpolationMode.BICUBIC
except ImportError:
BICUBIC = Image.BICUBIC
if packaging.version.parse(torch.__version__) < packaging.version.parse("1.7.1"):
warnings.warn("PyTorch version 1.7.1 or higher is recommended")
__all__ = ["available_models", "load", "tokenize"]
_tokenizer = _Tokenizer()
_MODELS = {
"RN50": "https://openaipublic.azureedge.net/clip/models/afeb0e10f9e5a86da6080e35cf09123aca3b358a0c3e3b6c78a7b63bc04b6762/RN50.pt",
"RN101": "https://openaipublic.azureedge.net/clip/models/8fa8567bab74a42d41c5915025a8e4538c3bdbe8804a470a72f30b0d94fab599/RN101.pt",
"RN50x4": "https://openaipublic.azureedge.net/clip/models/7e526bd135e493cef0776de27d5f42653e6b4c8bf9e0f653bb11773263205fdd/RN50x4.pt",
"RN50x16": "https://openaipublic.azureedge.net/clip/models/52378b407f34354e150460fe41077663dd5b39c54cd0bfd2b27167a4a06ec9aa/RN50x16.pt",
"RN50x64": "https://openaipublic.azureedge.net/clip/models/be1cfb55d75a9666199fb2206c106743da0f6468c9d327f3e0d0a543a9919d9c/RN50x64.pt",
"ViT-B/32": "https://openaipublic.azureedge.net/clip/models/40d365715913c9da98579312b702a82c18be219cc2a73407c4526f58eba950af/ViT-B-32.pt",
"ViT-B/16": "https://openaipublic.azureedge.net/clip/models/5806e77cd80f8b59890b7e101eabd078d9fb84e6937f9e85e4ecb61988df416f/ViT-B-16.pt",
"ViT-L/14": "https://openaipublic.azureedge.net/clip/models/b8cca3fd41ae0c99ba7e8951adf17d267cdb84cd88be6f7c2e0eca1737a03836/ViT-L-14.pt",
"ViT-L/14@336px": "https://openaipublic.azureedge.net/clip/models/3035c92b350959924f9f00213499208652fc7ea050643e8b385c2dac08641f02/ViT-L-14-336px.pt",
}
def _download(url: str, root: str):
os.makedirs(root, exist_ok=True)
filename = os.path.basename(url)
expected_sha256 = url.split("/")[-2]
download_target = os.path.join(root, filename)
if os.path.exists(download_target) and not os.path.isfile(download_target):
raise RuntimeError(f"{download_target} exists and is not a regular file")
if os.path.isfile(download_target):
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() == expected_sha256:
return download_target
else:
warnings.warn(f"{download_target} exists, but the SHA256 checksum does not match; re-downloading the file")
with urllib.request.urlopen(url) as source, open(download_target, "wb") as output:
with tqdm(total=int(source.info().get("Content-Length")), ncols=80, unit='iB', unit_scale=True, unit_divisor=1024) as loop:
while True:
buffer = source.read(8192)
if not buffer:
break
output.write(buffer)
loop.update(len(buffer))
if hashlib.sha256(open(download_target, "rb").read()).hexdigest() != expected_sha256:
raise RuntimeError("Model has been downloaded but the SHA256 checksum does not not match")
return download_target
def _convert_image_to_rgb(image):
return image.convert("RGB")
def _transform(n_px):
return Compose([
Resize(n_px, interpolation=BICUBIC),
CenterCrop(n_px),
_convert_image_to_rgb,
ToTensor(),
Normalize((0.48145466, 0.4578275, 0.40821073), (0.26862954, 0.26130258, 0.27577711)),
])
def available_models() -> List[str]:
"""Returns the names of available CLIP models"""
return list(_MODELS.keys())
def load(name: str, device: Union[str, torch.device] = "cuda" if torch.cuda.is_available() else "cpu", jit: bool = False, download_root: str = None):
"""Load a CLIP model
Parameters
----------
name : str
A model name listed by `clip.available_models()`, or the path to a model checkpoint containing the state_dict
device : Union[str, torch.device]
The device to put the loaded model
jit : bool
Whether to load the optimized JIT model or more hackable non-JIT model (default).
download_root: str
path to download the model files; by default, it uses "~/.cache/clip"
Returns
-------
model : torch.nn.Module
The CLIP model
preprocess : Callable[[PIL.Image], torch.Tensor]
A torchvision transform that converts a PIL image into a tensor that the returned model can take as its input
"""
if name in _MODELS:
model_path = _download(_MODELS[name], download_root or os.path.expanduser("~/.cache/clip"))
elif os.path.isfile(name):
model_path = name
else:
raise RuntimeError(f"Model {name} not found; available models = {available_models()}")
with open(model_path, 'rb') as opened_file:
try:
# loading JIT archive
model = torch.jit.load(opened_file, map_location=device if jit else "cpu").eval()
state_dict = None
except RuntimeError:
# loading saved state dict
if jit:
warnings.warn(f"File {model_path} is not a JIT archive. Loading as a state dict instead")
jit = False
state_dict = torch.load(opened_file, map_location="cpu")
if not jit:
model = build_model(state_dict or model.state_dict()).to(device)
if str(device) == "cpu":
model.float()
return model, _transform(model.visual.input_resolution)
# patch the device names
device_holder = torch.jit.trace(lambda: torch.ones([]).to(torch.device(device)), example_inputs=[])
device_node = [n for n in device_holder.graph.findAllNodes("prim::Constant") if "Device" in repr(n)][-1]
def _node_get(node: torch._C.Node, key: str):
"""Gets attributes of a node which is polymorphic over return type.
From https://github.com/pytorch/pytorch/pull/82628
"""
sel = node.kindOf(key)
return getattr(node, sel)(key)
def patch_device(module):
try:
graphs = [module.graph] if hasattr(module, "graph") else []
except RuntimeError:
graphs = []
if hasattr(module, "forward1"):
graphs.append(module.forward1.graph)
for graph in graphs:
for node in graph.findAllNodes("prim::Constant"):
if "value" in node.attributeNames() and str(_node_get(node, "value")).startswith("cuda"):
node.copyAttributes(device_node)
model.apply(patch_device)
patch_device(model.encode_image)
patch_device(model.encode_text)
# patch dtype to float32 on CPU
if str(device) == "cpu":
float_holder = torch.jit.trace(lambda: torch.ones([]).float(), example_inputs=[])
float_input = list(float_holder.graph.findNode("aten::to").inputs())[1]
float_node = float_input.node()
def patch_float(module):
try:
graphs = [module.graph] if hasattr(module, "graph") else []
except RuntimeError:
graphs = []
if hasattr(module, "forward1"):
graphs.append(module.forward1.graph)
for graph in graphs:
for node in graph.findAllNodes("aten::to"):
inputs = list(node.inputs())
for i in [1, 2]: # dtype can be the second or third argument to aten::to()
if _node_get(inputs[i].node(), "value") == 5:
inputs[i].node().copyAttributes(float_node)
model.apply(patch_float)
patch_float(model.encode_image)
patch_float(model.encode_text)
model.float()
return model, _transform(model.input_resolution.item())
def tokenize(texts: Union[str, List[str]], context_length: int = 77, truncate: bool = False) -> Union[torch.IntTensor, torch.LongTensor]:
"""
Returns the tokenized representation of given input string(s)
Parameters
----------
texts : Union[str, List[str]]
An input string or a list of input strings to tokenize
context_length : int
The context length to use; all CLIP models use 77 as the context length
truncate: bool
Whether to truncate the text in case its encoding is longer than the context length
Returns
-------
A two-dimensional tensor containing the resulting tokens, shape = [number of input strings, context_length].
We return LongTensor when torch version is <1.8.0, since older index_select requires indices to be long.
"""
if isinstance(texts, str):
texts = [texts]
sot_token = _tokenizer.encoder["<|startoftext|>"]
eot_token = _tokenizer.encoder["<|endoftext|>"]
all_tokens = [[sot_token] + _tokenizer.encode(text) + [eot_token] for text in texts]
if packaging.version.parse(torch.__version__) < packaging.version.parse("1.8.0"):
result = torch.zeros(len(all_tokens), context_length, dtype=torch.long)
else:
result = torch.zeros(len(all_tokens), context_length, dtype=torch.int)
for i, tokens in enumerate(all_tokens):
if len(tokens) > context_length:
if truncate:
tokens = tokens[:context_length]
tokens[-1] = eot_token
else:
raise RuntimeError(f"Input {texts[i]} is too long for context length {context_length}")
result[i, :len(tokens)] = torch.tensor(tokens)
return result
多模态模型:CLIP
论文标题:Learning Transferable Visual Models From Natural Language Supervision
论文网址:https://arxiv.org/abs/2103.00020
源码网址:https://github.com/OpenAI/CLIP
4. Experiments
在本节中,我们首先分析FastSAM的运行时效率。然后我们用四个zero-shot任务做实验,以及实际场景中的应用程序、效率和部署。在实验的第一部分中,我们的目标是测试FastSAM和SAM在功能上的相似性。在SAM之后,我们还实验了四个不同级别的任务:(1)低级:边缘检测,(2)中级:对象建议生成,(3)高级:实例分割,最后(4)高级:使用自由格式文本输入分割对象。我们的实验还进一步验证了FastSAM在实际应用和速度方面的能力。

4.1 Run-time Efficiency Evaluation

Segmentation Results of FastSAM
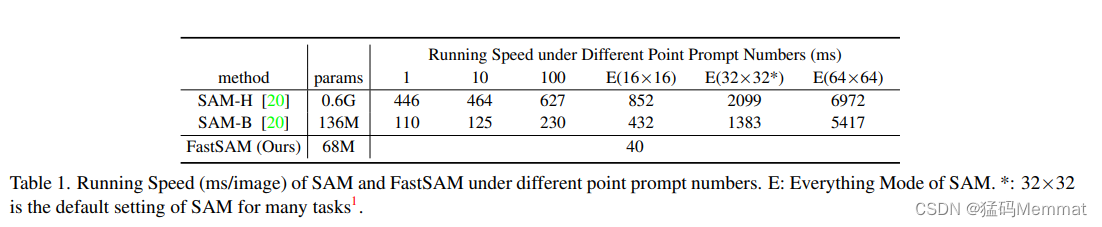
在表1中,我们报告了SAM和FastSAM在单个NVIDIA GeForce RTX 3090 GPU上的运行速度。可以看出,FastSAM在所有提示数上都超过SAM。此外,FastSAM的运行速度不会随着提示符的变化而变化,这使它成为Everything模式的更好选择。
4.2 Zero-Shot Edge Detection


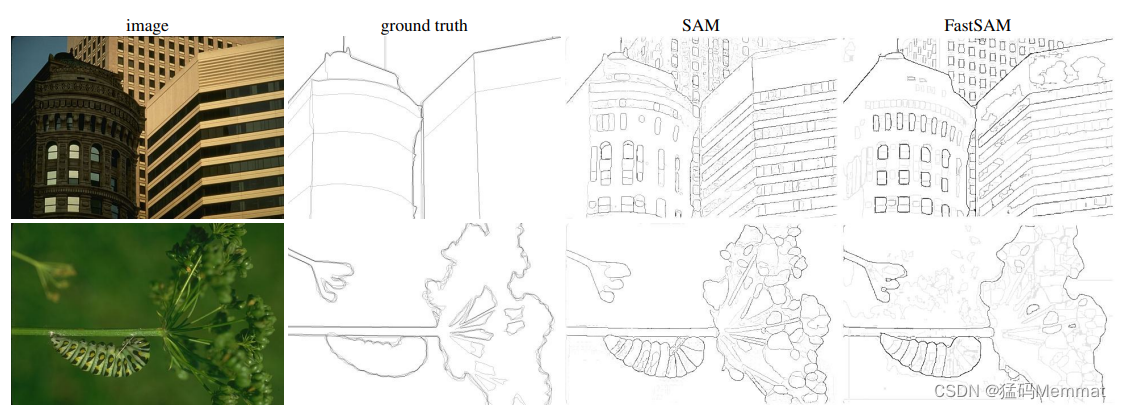
SAM和Fast-SAM比较
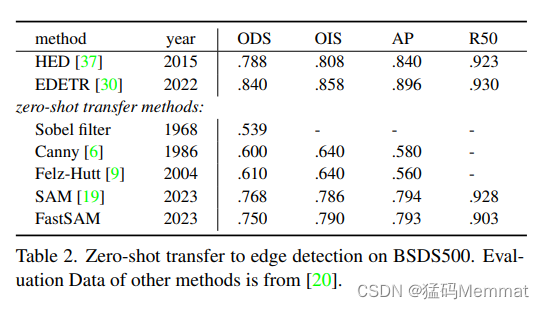
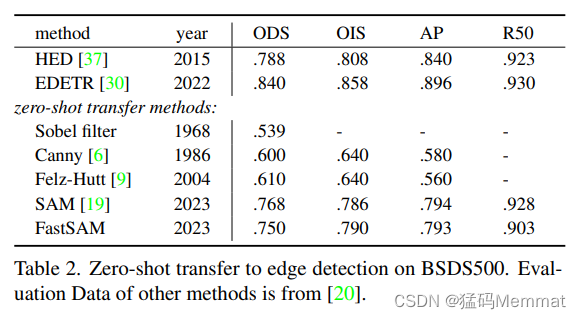
4.2.1 BSDS500
FastSAM is assessed on the basic low-level task of edge detection using BSDS500.
Pablo Arbelaez, Michael Maire, Charless Fowlkes, and Jitendra Malik. Contour detection and hierarchical image segmentation.
IEEE transactions on pattern analysis and machine intelligence, 33(5):898–916, 2010.

4.2.2 Sobel filtering
Irwin Sobel, Gary Feldman, et al. A 3x3 isotropic gradient operator for image processing. a talk at the Stanford Artificial Project in, pages 271–272, 1968.
4.2.3 NMS
edge NMS step
John Canny. A computational approach to edge detection.
IEEE Transactions on pattern analysis and machine intelligence, (6):679-698, 1986
4.3 Zero-Shot Object Proposal Generation
4.4 Zero-Shot Instance Segmentation

与SAM方法类似,我们利用ViTDet[23]生成的边界框(bounding box, bbox)作为提示符来完成实例分割任务。如第3.3节所述,我们选择具有最高交集/联合(IoU)的掩码,bbox作为预测掩码。结果。
表6给出了评估结果。在此任务中,我们未能实现高AP。我们推断这主要是因为分割掩码精度或基于盒的掩码选择策略。第6节给出了几个例子。

4.5 Zero-Shot Object Localization with Text Prompts

在上图中显示了定性结果。FastSAM可以根据文本提示很好地分割对象。然而,文本到掩模分割的运行速度并不令人满意,因为每个掩模区域都需要被馈送到CLIP特征提取器中。如何将CLIP嵌入提取器组合到FastSAM的骨干网络中,仍然是关于模型压缩的一个有趣的问题。
5. Real-world Applications





5.1 Points Mode
Doesn’t work well in this picture with one point

6. Discussion

7. model.py: FastSAM
# Ultralytics YOLO 🚀, AGPL-3.0 license
"""
FastSAM model interface.
Usage - Predict:
from ultralytics import FastSAM
model = FastSAM('last.pt')
results = model.predict('ultralytics/assets/bus.jpg')
"""
from ultralytics.yolo.cfg import get_cfg
from ultralytics.yolo.engine.exporter import Exporter
from ultralytics.yolo.engine.model import YOLO
from ultralytics.yolo.utils import DEFAULT_CFG, LOGGER, ROOT, is_git_dir
from ultralytics.yolo.utils.checks import check_imgsz
from ultralytics.yolo.utils.torch_utils import model_info, smart_inference_mode
from .predict import FastSAMPredictor
class FastSAM(YOLO):
@smart_inference_mode()
def predict(self, source=None, stream=False, **kwargs):
"""
Perform prediction using the YOLO model.
Args:
source (str | int | PIL | np.ndarray): The source of the image to make predictions on.
Accepts all source types accepted by the YOLO model.
stream (bool): Whether to stream the predictions or not. Defaults to False.
**kwargs : Additional keyword arguments passed to the predictor.
Check the 'configuration' section in the documentation for all available options.
Returns:
(List[ultralytics.yolo.engine.results.Results]): The prediction results.
"""
if source is None:
source = ROOT / 'assets' if is_git_dir() else 'https://ultralytics.com/images/bus.jpg'
LOGGER.warning(f"WARNING ⚠️ 'source' is missing. Using 'source={source}'.")
overrides = self.overrides.copy()
overrides['conf'] = 0.25
overrides.update(kwargs) # prefer kwargs
overrides['mode'] = kwargs.get('mode', 'predict')
assert overrides['mode'] in ['track', 'predict']
overrides['save'] = kwargs.get('save', False) # do not save by default if called in Python
self.predictor = FastSAMPredictor(overrides=overrides)
self.predictor.setup_model(model=self.model, verbose=False)
try:
return self.predictor(source, stream=stream)
except Exception as e:
return None
def train(self, **kwargs):
"""Function trains models but raises an error as FastSAM models do not support training."""
raise NotImplementedError("Currently, the training codes are on the way.")
def val(self, **kwargs):
"""Run validation given dataset."""
overrides = dict(task='segment', mode='val')
overrides.update(kwargs) # prefer kwargs
args = get_cfg(cfg=DEFAULT_CFG, overrides=overrides)
args.imgsz = check_imgsz(args.imgsz, max_dim=1)
validator = FastSAM(args=args)
validator(model=self.model)
self.metrics = validator.metrics
return validator.metrics
@smart_inference_mode()
def export(self, **kwargs):
"""
Export model.
Args:
**kwargs : Any other args accepted by the predictors. To see all args check 'configuration' section in docs
"""
overrides = dict(task='detect')
overrides.update(kwargs)
overrides['mode'] = 'export'
args = get_cfg(cfg=DEFAULT_CFG, overrides=overrides)
args.task = self.task
if args.imgsz == DEFAULT_CFG.imgsz:
args.imgsz = self.model.args['imgsz'] # use trained imgsz unless custom value is passed
if args.batch == DEFAULT_CFG.batch:
args.batch = 1 # default to 1 if not modified
return Exporter(overrides=args)(model=self.model)
def info(self, detailed=False, verbose=True):
"""
Logs model info.
Args:
detailed (bool): Show detailed information about model.
verbose (bool): Controls verbosity.
"""
return model_info(self.model, detailed=detailed, verbose=verbose, imgsz=640)
def __call__(self, source=None, stream=False, **kwargs):
"""Calls the 'predict' function with given arguments to perform object detection."""
return self.predict(source, stream, **kwargs)
def __getattr__(self, attr):
"""Raises error if object has no requested attribute."""
name = self.__class__.__name__
raise AttributeError(f"'{name}' object has no attribute '{attr}'. See valid attributes below.\n{self.__doc__}")
8. prompt.py: FastSAMPrompt
import os
import sys
import cv2
import matplotlib.pyplot as plt
import numpy as np
import torch
from .utils import image_to_np_ndarray
from PIL import Image
try:
import clip # for linear_assignment
except (ImportError, AssertionError, AttributeError):
from ultralytics.yolo.utils.checks import check_requirements
check_requirements('git+https://github.com/openai/CLIP.git') # required before installing lap from source
import clip
class FastSAMPrompt:
def __init__(self, image, results, device='cuda'):
if isinstance(image, str) or isinstance(image, Image.Image):
image = image_to_np_ndarray(image)
self.device = device
self.results = results
self.img = image
def _segment_image(self, image, bbox):
if isinstance(image, Image.Image):
image_array = np.array(image)
else:
image_array = image
segmented_image_array = np.zeros_like(image_array)
x1, y1, x2, y2 = bbox
segmented_image_array[y1:y2, x1:x2] = image_array[y1:y2, x1:x2]
segmented_image = Image.fromarray(segmented_image_array)
black_image = Image.new('RGB', image.size, (255, 255, 255))
# transparency_mask = np.zeros_like((), dtype=np.uint8)
transparency_mask = np.zeros((image_array.shape[0], image_array.shape[1]), dtype=np.uint8)
transparency_mask[y1:y2, x1:x2] = 255
transparency_mask_image = Image.fromarray(transparency_mask, mode='L')
black_image.paste(segmented_image, mask=transparency_mask_image)
return black_image
def _format_results(self, result, filter=0):
annotations = []
n = len(result.masks.data)
for i in range(n):
annotation = {}
mask = result.masks.data[i] == 1.0
if torch.sum(mask) < filter:
continue
annotation['id'] = i
annotation['segmentation'] = mask.cpu().numpy()
annotation['bbox'] = result.boxes.data[i]
annotation['score'] = result.boxes.conf[i]
annotation['area'] = annotation['segmentation'].sum()
annotations.append(annotation)
return annotations
def filter_masks(annotations): # filte the overlap mask
annotations.sort(key=lambda x: x['area'], reverse=True)
to_remove = set()
for i in range(0, len(annotations)):
a = annotations[i]
for j in range(i + 1, len(annotations)):
b = annotations[j]
if i != j and j not in to_remove:
# check if
if b['area'] < a['area']:
if (a['segmentation'] & b['segmentation']).sum() / b['segmentation'].sum() > 0.8:
to_remove.add(j)
return [a for i, a in enumerate(annotations) if i not in to_remove], to_remove
def _get_bbox_from_mask(self, mask):
mask = mask.astype(np.uint8)
contours, hierarchy = cv2.findContours(mask, cv2.RETR_EXTERNAL, cv2.CHAIN_APPROX_SIMPLE)
x1, y1, w, h = cv2.boundingRect(contours[0])
x2, y2 = x1 + w, y1 + h
if len(contours) > 1:
for b in contours:
x_t, y_t, w_t, h_t = cv2.boundingRect(b)
# Merge multiple bounding boxes into one.
x1 = min(x1, x_t)
y1 = min(y1, y_t)
x2 = max(x2, x_t + w_t)
y2 = max(y2, y_t + h_t)
h = y2 - y1
w = x2 - x1
return [x1, y1, x2, y2]
def plot_to_result(self,
annotations,
bboxes=None,
points=None,
point_label=None,
mask_random_color=True,
better_quality=True,
retina=False,
withContours=True) -> np.ndarray:
if isinstance(annotations[0], dict):
annotations = [annotation['segmentation'] for annotation in annotations]
image = self.img
image = cv2.cvtColor(image, cv2.COLOR_BGR2RGB)
original_h = image.shape[0]
original_w = image.shape[1]
if sys.platform == "darwin":
plt.switch_backend("TkAgg")
plt.figure(figsize=(original_w / 100, original_h / 100))
# Add subplot with no margin.
plt.subplots_adjust(top=1, bottom=0, right=1, left=0, hspace=0, wspace=0)
plt.margins(0, 0)
plt.gca().xaxis.set_major_locator(plt.NullLocator())
plt.gca().yaxis.set_major_locator(plt.NullLocator())
plt.imshow(image)
if better_quality:
if isinstance(annotations[0], torch.Tensor):
annotations = np.array(annotations.cpu())
for i, mask in enumerate(annotations):
mask = cv2.morphologyEx(mask.astype(np.uint8), cv2.MORPH_CLOSE, np.ones((3, 3), np.uint8))
annotations[i] = cv2.morphologyEx(mask.astype(np.uint8), cv2.MORPH_OPEN, np.ones((8, 8), np.uint8))
if self.device == 'cpu':
annotations = np.array(annotations)
self.fast_show_mask(
annotations,
plt.gca(),
random_color=mask_random_color,
bboxes=bboxes,
points=points,
pointlabel=point_label,
retinamask=retina,
target_height=original_h,
target_width=original_w,
)
else:
if isinstance(annotations[0], np.ndarray):
annotations = torch.from_numpy(annotations)
self.fast_show_mask_gpu(
annotations,
plt.gca(),
random_color=mask_random_color,
bboxes=bboxes,
points=points,
pointlabel=point_label,
retinamask=retina,
target_height=original_h,
target_width=original_w,
)
if isinstance(annotations, torch.Tensor):
annotations = annotations.cpu().numpy()
if withContours:
contour_all = []
temp = np.zeros((original_h, original_w, 1))
for i, mask in enumerate(annotations):
if type(mask) == dict:
mask = mask['segmentation']
annotation = mask.astype(np.uint8)
if not retina:
annotation = cv2.resize(
annotation,
(original_w, original_h),
interpolation=cv2.INTER_NEAREST,
)
contours, hierarchy = cv2.findContours(annotation, cv2.RETR_TREE, cv2.CHAIN_APPROX_SIMPLE)
for contour in contours:
contour_all.append(contour)
cv2.drawContours(temp, contour_all, -1, (255, 255, 255), 2)
color = np.array([0 / 255, 0 / 255, 255 / 255, 0.8])
contour_mask = temp / 255 * color.reshape(1, 1, -1)
plt.imshow(contour_mask)
plt.axis('off')
fig = plt.gcf()
plt.draw()
try:
buf = fig.canvas.tostring_rgb()
except AttributeError:
fig.canvas.draw()
buf = fig.canvas.tostring_rgb()
cols, rows = fig.canvas.get_width_height()
img_array = np.frombuffer(buf, dtype=np.uint8).reshape(rows, cols, 3)
result = cv2.cvtColor(img_array, cv2.COLOR_RGB2BGR)
plt.close()
return result
# Remark for refactoring: IMO a function should do one thing only, storing the image and plotting should be seperated and do not necessarily need to be class functions but standalone utility functions that the user can chain in his scripts to have more fine-grained control.
def plot(self,
annotations,
output_path,
bboxes=None,
points=None,
point_label=None,
mask_random_color=True,
better_quality=True,
retina=False,
withContours=True):
if len(annotations) == 0:
return None
result = self.plot_to_result(
annotations,
bboxes,
points,
point_label,
mask_random_color,
better_quality,
retina,
withContours,
)
path = os.path.dirname(os.path.abspath(output_path))
if not os.path.exists(path):
os.makedirs(path)
result = result[:, :, ::-1]
cv2.imwrite(output_path, result)
# CPU post process
def fast_show_mask(
self,
annotation,
ax,
random_color=False,
bboxes=None,
points=None,
pointlabel=None,
retinamask=True,
target_height=960,
target_width=960,
):
msak_sum = annotation.shape[0]
height = annotation.shape[1]
weight = annotation.shape[2]
#Sort annotations based on area.
areas = np.sum(annotation, axis=(1, 2))
sorted_indices = np.argsort(areas)
annotation = annotation[sorted_indices]
index = (annotation != 0).argmax(axis=0)
if random_color:
color = np.random.random((msak_sum, 1, 1, 3))
else:
color = np.ones((msak_sum, 1, 1, 3)) * np.array([30 / 255, 144 / 255, 255 / 255])
transparency = np.ones((msak_sum, 1, 1, 1)) * 0.6
visual = np.concatenate([color, transparency], axis=-1)
mask_image = np.expand_dims(annotation, -1) * visual
show = np.zeros((height, weight, 4))
h_indices, w_indices = np.meshgrid(np.arange(height), np.arange(weight), indexing='ij')
indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
# Use vectorized indexing to update the values of 'show'.
show[h_indices, w_indices, :] = mask_image[indices]
if bboxes is not None:
for bbox in bboxes:
x1, y1, x2, y2 = bbox
ax.add_patch(plt.Rectangle((x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor='b', linewidth=1))
# draw point
if points is not None:
plt.scatter(
[point[0] for i, point in enumerate(points) if pointlabel[i] == 1],
[point[1] for i, point in enumerate(points) if pointlabel[i] == 1],
s=20,
c='y',
)
plt.scatter(
[point[0] for i, point in enumerate(points) if pointlabel[i] == 0],
[point[1] for i, point in enumerate(points) if pointlabel[i] == 0],
s=20,
c='m',
)
if not retinamask:
show = cv2.resize(show, (target_width, target_height), interpolation=cv2.INTER_NEAREST)
ax.imshow(show)
def fast_show_mask_gpu(
self,
annotation,
ax,
random_color=False,
bboxes=None,
points=None,
pointlabel=None,
retinamask=True,
target_height=960,
target_width=960,
):
msak_sum = annotation.shape[0]
height = annotation.shape[1]
weight = annotation.shape[2]
areas = torch.sum(annotation, dim=(1, 2))
sorted_indices = torch.argsort(areas, descending=False)
annotation = annotation[sorted_indices]
# Find the index of the first non-zero value at each position.
index = (annotation != 0).to(torch.long).argmax(dim=0)
if random_color:
color = torch.rand((msak_sum, 1, 1, 3)).to(annotation.device)
else:
color = torch.ones((msak_sum, 1, 1, 3)).to(annotation.device) * torch.tensor([
30 / 255, 144 / 255, 255 / 255]).to(annotation.device)
transparency = torch.ones((msak_sum, 1, 1, 1)).to(annotation.device) * 0.6
visual = torch.cat([color, transparency], dim=-1)
mask_image = torch.unsqueeze(annotation, -1) * visual
# Select data according to the index. The index indicates which batch's data to choose at each position, converting the mask_image into a single batch form.
show = torch.zeros((height, weight, 4)).to(annotation.device)
try:
h_indices, w_indices = torch.meshgrid(torch.arange(height), torch.arange(weight), indexing='ij')
except:
h_indices, w_indices = torch.meshgrid(torch.arange(height), torch.arange(weight))
indices = (index[h_indices, w_indices], h_indices, w_indices, slice(None))
# Use vectorized indexing to update the values of 'show'.
show[h_indices, w_indices, :] = mask_image[indices]
show_cpu = show.cpu().numpy()
if bboxes is not None:
for bbox in bboxes:
x1, y1, x2, y2 = bbox
ax.add_patch(plt.Rectangle((x1, y1), x2 - x1, y2 - y1, fill=False, edgecolor='b', linewidth=1))
# draw point
if points is not None:
plt.scatter(
[point[0] for i, point in enumerate(points) if pointlabel[i] == 1],
[point[1] for i, point in enumerate(points) if pointlabel[i] == 1],
s=20,
c='y',
)
plt.scatter(
[point[0] for i, point in enumerate(points) if pointlabel[i] == 0],
[point[1] for i, point in enumerate(points) if pointlabel[i] == 0],
s=20,
c='m',
)
if not retinamask:
show_cpu = cv2.resize(show_cpu, (target_width, target_height), interpolation=cv2.INTER_NEAREST)
ax.imshow(show_cpu)
# clip
@torch.no_grad()
def retrieve(self, model, preprocess, elements, search_text: str, device) -> int:
preprocessed_images = [preprocess(image).to(device) for image in elements]
tokenized_text = clip.tokenize([search_text]).to(device)
stacked_images = torch.stack(preprocessed_images)
image_features = model.encode_image(stacked_images)
text_features = model.encode_text(tokenized_text)
image_features /= image_features.norm(dim=-1, keepdim=True)
text_features /= text_features.norm(dim=-1, keepdim=True)
probs = 100.0 * image_features @ text_features.T
return probs[:, 0].softmax(dim=0)
def _crop_image(self, format_results):
image = Image.fromarray(cv2.cvtColor(self.img, cv2.COLOR_BGR2RGB))
ori_w, ori_h = image.size
annotations = format_results
mask_h, mask_w = annotations[0]['segmentation'].shape
if ori_w != mask_w or ori_h != mask_h:
image = image.resize((mask_w, mask_h))
cropped_boxes = []
cropped_images = []
not_crop = []
filter_id = []
# annotations, _ = filter_masks(annotations)
# filter_id = list(_)
for _, mask in enumerate(annotations):
if np.sum(mask['segmentation']) <= 100:
filter_id.append(_)
continue
bbox = self._get_bbox_from_mask(mask['segmentation']) # mask 的 bbox
cropped_boxes.append(self._segment_image(image, bbox))
# cropped_boxes.append(segment_image(image,mask["segmentation"]))
cropped_images.append(bbox) # Save the bounding box of the cropped image.
return cropped_boxes, cropped_images, not_crop, filter_id, annotations
def box_prompt(self, bbox=None, bboxes=None):
if self.results == None:
return []
assert bbox or bboxes
if bboxes is None:
bboxes = [bbox]
max_iou_index = []
for bbox in bboxes:
assert (bbox[2] != 0 and bbox[3] != 0)
masks = self.results[0].masks.data
target_height = self.img.shape[0]
target_width = self.img.shape[1]
h = masks.shape[1]
w = masks.shape[2]
if h != target_height or w != target_width:
bbox = [
int(bbox[0] * w / target_width),
int(bbox[1] * h / target_height),
int(bbox[2] * w / target_width),
int(bbox[3] * h / target_height), ]
bbox[0] = round(bbox[0]) if round(bbox[0]) > 0 else 0
bbox[1] = round(bbox[1]) if round(bbox[1]) > 0 else 0
bbox[2] = round(bbox[2]) if round(bbox[2]) < w else w
bbox[3] = round(bbox[3]) if round(bbox[3]) < h else h
# IoUs = torch.zeros(len(masks), dtype=torch.float32)
bbox_area = (bbox[3] - bbox[1]) * (bbox[2] - bbox[0])
masks_area = torch.sum(masks[:, bbox[1]:bbox[3], bbox[0]:bbox[2]], dim=(1, 2))
orig_masks_area = torch.sum(masks, dim=(1, 2))
union = bbox_area + orig_masks_area - masks_area
IoUs = masks_area / union
max_iou_index.append(int(torch.argmax(IoUs)))
max_iou_index = list(set(max_iou_index))
return np.array(masks[max_iou_index].cpu().numpy())
def point_prompt(self, points, pointlabel): # numpy
if self.results == None:
return []
masks = self._format_results(self.results[0], 0)
target_height = self.img.shape[0]
target_width = self.img.shape[1]
h = masks[0]['segmentation'].shape[0]
w = masks[0]['segmentation'].shape[1]
if h != target_height or w != target_width:
points = [[int(point[0] * w / target_width), int(point[1] * h / target_height)] for point in points]
onemask = np.zeros((h, w))
masks = sorted(masks, key=lambda x: x['area'], reverse=True)
for i, annotation in enumerate(masks):
if type(annotation) == dict:
mask = annotation['segmentation']
else:
mask = annotation
for i, point in enumerate(points):
if mask[point[1], point[0]] == 1 and pointlabel[i] == 1:
onemask[mask] = 1
if mask[point[1], point[0]] == 1 and pointlabel[i] == 0:
onemask[mask] = 0
onemask = onemask >= 1
return np.array([onemask])
def text_prompt(self, text):
if self.results == None:
return []
format_results = self._format_results(self.results[0], 0)
cropped_boxes, cropped_images, not_crop, filter_id, annotations = self._crop_image(format_results)
clip_model, preprocess = clip.load('ViT-B/32', device=self.device)
scores = self.retrieve(clip_model, preprocess, cropped_boxes, text, device=self.device)
max_idx = scores.argsort()
max_idx = max_idx[-1]
max_idx += sum(np.array(filter_id) <= int(max_idx))
return np.array([annotations[max_idx]['segmentation']])
def everything_prompt(self):
if self.results == None:
return []
return self.results[0].masks.data

Reference
https://arxiv.org/pdf/2306.12156v1.pdf
https://github.com/CASIA-IVA-Lab/FastSAM
https://mp.weixin.qq.com/s/HvpQse6yzklPELEh8u9r7w

















 310
310











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











