








FastSAM是一个用于图像分割的快速模型,它是对SAM(Segment Anything Model)模型的改进和优化。FastSAM模型的目标是提高计算效率,使得图像分割任务能够更快地完成。
FastSAM模型的优势主要体现在以下几个方面:
快速性能:FastSAM相比SAM原版提速了50倍。通过引入人工先验结构和模型压缩技术,FastSAM能够在保持高质量分割结果的同时,大幅降低计算复杂度,从而实现更快的图像分割速度。
通用性:FastSAM是一个通用的视觉模型,能够应用于各种图像分割任务。它具备处理和关联多种模态信息的能力,可以适应不同的数据异构性
模型压缩:FastSAM通过基于大模型产生高质量数据的方式,结合人工先验结构的引入,实现了模型的压缩。这种模型压缩的方法在保持分割质量的同时,降低了计算复杂度,提高了模型的效率
FastSAM模型的应用领域包括图像分割、语义分割等。它在计算机视觉领域具有重要的意义,为图像分割任务提供了更快速、高效的解决方案。

论文:https://arxiv.org/pdf/2306.12156.pdf
源码:https://github.com/CASIA-IVA-Lab/FastSAM
API演示效果:https://huggingface.co/spaces/An-619/FastSAM
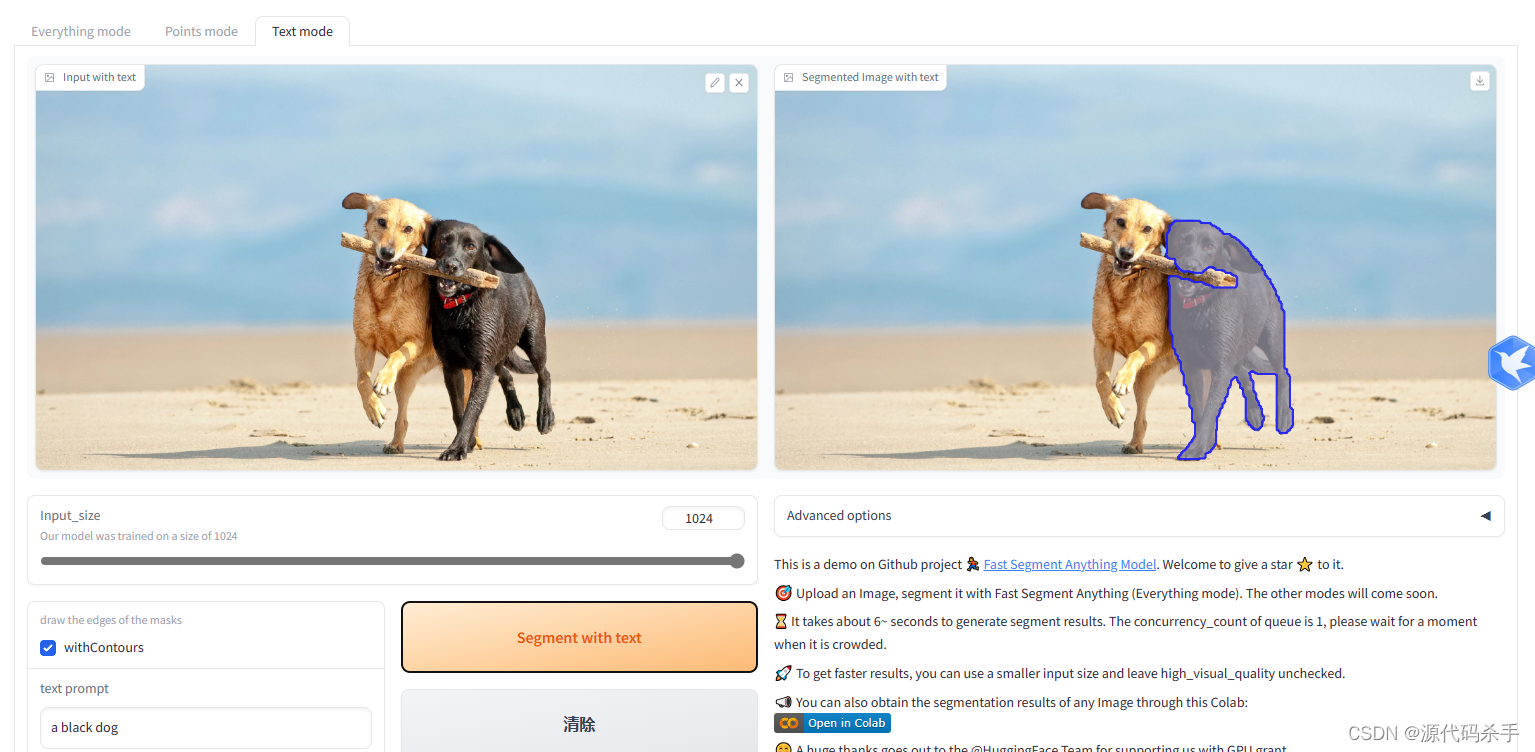
安装
在本地克隆存储库:
git clone https://github.com/CASIA-IVA-Lab/FastSAM.git
创建 conda 环境。代码需要 ,以及 和 。请按照此处的说明安装 PyTorch 和 TorchVision 依赖项。强烈建议同时安装具有CUDA支持的PyTorch和TorchVision。python>=3.7pytorch>=1.7torchvision>=0.8
conda create -n FastSAM python=3.9
conda activate FastSAM
安装软件包:
cd FastSAM
pip install -r requirements.txt
开始
首先下载模型检查点。
然后,您可以运行脚本来尝试一切模式和三种提示模式。
# Everything mode
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg
# Text prompt
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --text_prompt "the yellow dog"
# Box prompt (xywh)
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --box_prompt "[[570,200,230,400]]"
# Points prompt
python Inference.py --model_path ./weights/FastSAM.pt --img_path ./images/dogs.jpg --point_prompt "[[520,360],[620,300]]" --point_label "[1,0]"
您可以使用以下代码生成所有掩码,根据提示选择遮罩,并可视化结果。
from fastsam import FastSAM, FastSAMPrompt
model = FastSAM('./weights/FastSAM.pt')
IMAGE_PATH = './images/dogs.jpg'
DEVICE = 'cpu'
everything_results = model(IMAGE_PATH, device=DEVICE, retina_masks=True, imgsz=1024, conf=0.4, iou=0.9,)
prompt_process = FastSAMPrompt(IMAGE_PATH, everything_results, device=DEVICE)
# everything prompt
ann = prompt_process.everything_prompt()
# bbox default shape [0,0,0,0] -> [x1,y1,x2,y2]
ann = prompt_process.box_prompt(bbox=[[200, 200, 300, 300]])
# text prompt
ann = prompt_process.text_prompt(text='a photo of a dog')
# point prompt
# points default [[0,0]] [[x1,y1],[x2,y2]]
# point_label default [0] [1,0] 0:background, 1:foreground
ann = prompt_process.point_prompt(points=[[620, 360]], pointlabel=[1])
prompt_process.plot(annotations=ann,output_path='./output/dog.jpg',)
参考
https://www.eet-china.com/mp/a231946.html
https://blog.csdn.net/amusi1994/article/details/131448054
https://www.toymoban.com/blog/610701.html
https://bbs.huaweicloud.com/blogs/264134
https://www.bilibili.com/video/BV1ns4y117ES/?vd_source=af0c0a99734922e212baf256fa291926
https://www.bilibili.com/video/BV1Vo4y1n7WX/?vd_source=af0c0a99734922e212baf256fa291926

















 5507
5507











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











