









论文题目:Topic Modeling using Topics from Many Domains, Lifelong Learning and Big Data
论文地址:http://www.jmlr.org/proceedings/papers/v32/chenf14.pdf
论文大体内容:
本文提出Lifelong Learning的概念,通过对每个dataset自动地学习、整理出knowledge base,并使用这个knowledge base去指导各个dataset的再学习,以获得更好的主题效果。同时,通过将big data划分为多个small data,使用Lifelong Learning的方法,达到对big data的有效且高效的处理。
1、作者提出使用prior knowledge sets(pk-set)来表示先验知识,但是该先验知识尽管在某一个dataset中是正确的,到了另一个dataset有可能会出错(如一词多义等),本文也将解决这个问题。
2、知识积累的伪代码如图。(对每个dataset学习其中的知识Si,然后合并为整体知识S,之后再使用S指导各个dataset重新学习)

3、Lifelong Topic Model(LTM)的伪代码如图。(对每个dataset学习其中的知识A,再整合A与S得出K,然后用K指导dataset的学习)

4、新知识A与知识库S的知识整合的伪代码如图。(如果两者KL散度(KL散度越小,说明相似度越高)的值小于某个阈值,则说明这个新知识要加入到知识库中)

5、主题模型中抽取出的主题词不一定是全部正确的,所以作者使用Ponintwise Mutual Information(PMI)的方法,去测量主题词的任意两个词之间的关联度,如果两个词之间的关联度很低,则说明两者中很大概率存在不对的词,需要去掉。
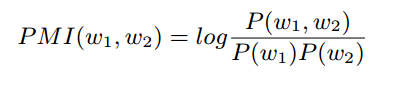
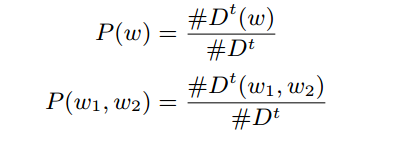
6、Baseline:作者对比了4个baseline,包括:
①LDA[1],最原始、基本的LDA算法,使用狄利克雷分布计算主题概率的非监督式主题模型;
②DF-LDA[2],基于knowledge base的主题模型,使用了must-link与cannot-link的方法;
③GK-LDA[3],基于knowledge base的主题模型,使用了每个topic下的单词概率去掉错误的知识的方法;
④AKL[4],基于knowledge base的主题模型,使用了聚类的方法去学习知识;
7、Dataset:作者使用了Amazon网站上的评论数据集,包括50个领域各1000个评论。
8、参数设置:LDA的参数α=1,β=0.1,主题数量设定为T=15。
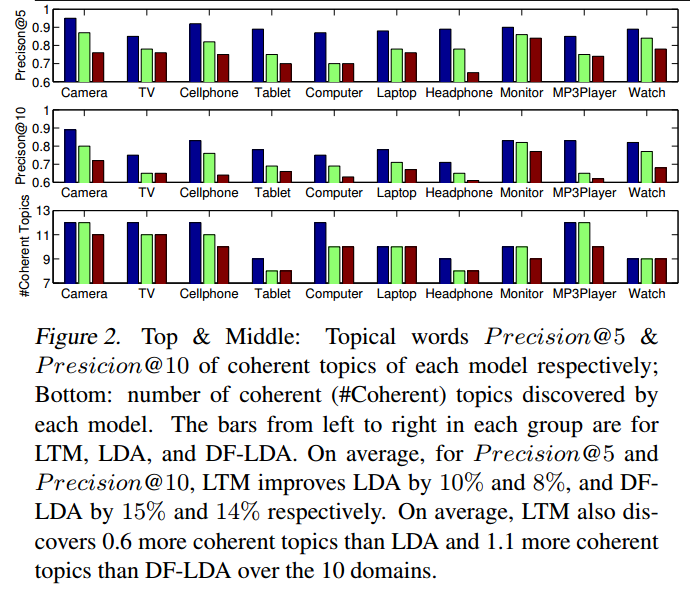
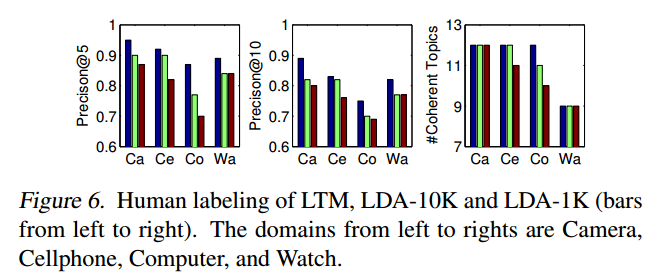
9、实验结论:Topic Coherence比baseline有一点点提升,Precision@n也比baseline有提升。同时作者对大的dataset进行分割,然后再使用LTM模型学习,发现模型的效果与速度均有所提升。

参考资料:
[1]、http://www.jmlr.org/papers/v3/blei03a.html
[2]、http://dl.acm.org/citation.cfm?id=1553378
[3]、http://dl.acm.org/citation.cfm?id=2505519
[4]、http://anthology.aclweb.org/P/P14/P14-1033.pdf
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









