










论文题目:ELLA: An Efficient Lifelong Learning Algorithm
论文地址:http://www.jmlr.org/proceedings/papers/v28/ruvolo13.pdf
论文发表于:International Conference on Machine Learning(ICML) 2013(A类会议)
论文大体内容:
本文提出一种高效的Lifelong Learning算法,主要包括Knowledge Base(sparsely shared basis),使用Knowledge Base进行transfer learning,更新Knowledge Base等操作。最终的效果跟 batch multi-task learning(GO-MTL[1])基本一样,但是速度上快了3个数量级(1000多倍)。本文主要的motivation在于速度的提升。
1、transfer,multitask和lifelong的区别[3]:

2、Lifelong learning的framework:

3、本文使用参数方法(如线性回归,逻辑回归等)进行训练模型,对于每个task t,参数为θ(t),输入的样本X是d维的,优化方程如下:

其中L∈R^(d, k),S(t)∈R^(k, 1),θ(t)∈R^(d, 1),θ(t)=L*S(t);
优化方程就是要使预测的loss function最小化,同时为了减少每个task对于隐藏层的使用,所以加入S的稀疏性控制;
4、解优化方程常用的做法是使用类EM迭代的方式,分别迭代S与L(GO-MTL使用的方法),但是并不高效,主要有2方面:
①解法需要使用全部样本,计算量增大;
②每次L改变后,到更新S(t)的时候,需要把T个S都更新,带来特别大的计算量;
5、本文对这2方面的改进是:
①将模型改为增量式的,对优化方程作二阶泰勒展开;
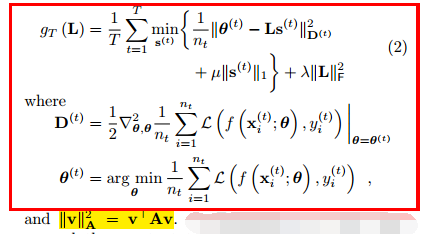
②对于一个task t的数据,只更新S(t),其它task t’的S(t’)不更新;
6、算法ELLA伪代码

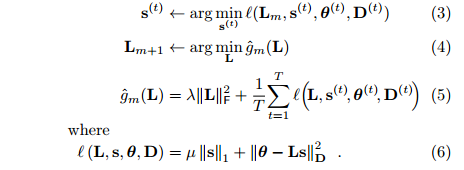
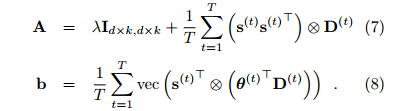
①A∈R^(k*d, k*d),b∈R^(k*d, 1),L∈R^(d, k),S(t)∈R^(k, 1),θ(t)∈R^(d, 1),其中d是X的feature数量,k是隐藏层维数,它们的关系是θ(t)=L*S(t),L=mat(A^(-1)*b);
②来一个数据,判断是否为新task,然后相应的更新X,Y(创建新的或者合并到以前的数据中),若为旧task,将A,b减去已经累加过的旧task的值,保证A,b均是对每个task累加的值;
③利用常用的简单分类或者回归方法(如线性回归、逻辑回归等),训练出θ(t),D(t);
④将L的某一列或某几列置0(感觉没什么用);
⑤使用Lm(上一次的L)更新S(t);
⑥对(5)的方程求导为0,然后更新A,b,再通过L=mat(A^(-1)*b)更新L;
7、对于线性回归来说,θ(t)与D(t)分别是:
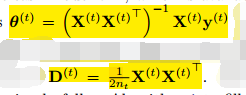
8、对于逻辑回归来说,θ(t)与D(t)分别是:

实验
9、Baseline:
①GO-MTL[1]:a batch MTL algorithm;
②OMTL[2]:a perceptron-based approach to online multi-task learning;
③STL:independent single-task learning;
10、Dataset:
①synthetic regression tasks:自定义的tasks,Tmax = 100 random tasks with d = 13 features and nt = 100 instances per task;
②land mine detection: 通过雷达图片找地雷;
③facial expression recognition:identification of three different facial movements from photographs of a subject;
④predicting student exam scores:from 15,362 students in 139 schools in London;

11、评测标准
①分类实验:AUC曲线;
②回归实验:rMSE;
12、实验步骤
①将每个task划分50%的作为training set,50%的作为testset;
②参数k∈[1, min(10,T/4)],λ取{e−5; e−2; e1; e4}等值;
③一次进来task t下的一个样本,然后根据已有的所有该task下的样本,然后训练θ(t),得到task下的参数;
④对于testset的样本,先看是哪个task的数据,再使用该task下的参数θ(t)进行预测;
13、实验结果:
①与batch MTL结果差不多100%一样(效果几乎没变化);
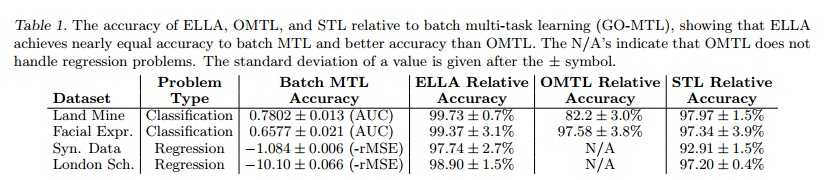
②时间提高了3到5个数量级(1000-100000);

③随着task数目增加,准确率是不断的变大,并慢慢收敛的;

参考资料:
[1]、https://arxiv.org/ftp/arxiv/papers/1206/1206.6417.pdf
[2]、http://www.jmlr.org/proceedings/papers/v15/saha11b/saha11b.pdf
[3]、https://www.cs.uic.edu/~liub/Lifelong-Machine-Learning-Tutorial-KDD-2016.pdf
[4]、http://www.seas.upenn.edu/~eeaton/papers/slides-Ruvolo2013ELLA.pdf
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!















 1万+
1万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









