










论文题目:Mining Aspect-Specific Opinion using a Holistic Lifelong Topic Model
论文地址:http://dl.acm.org/citation.cfm?id=2883086
论文大体内容:
本文提出JAST(Joint Aspectbased Sentiment Topic)模型,进行对文本观点进行细粒度的挖掘,同时,使用了Lifelong的思想,将JAST改进为LAST(Lifelong Aspectbased Sentiment Topic),并超过其它state-of-the-art水平的baseline。
1、aspect级别的观点挖掘包含4个模块:(如句子: The screen is very clear and great.)
①aspect抽取:screen是一个aspect;
②观点识别:clear,great是观点;
③观点正负分类:clear,great是积极的观点;
④general和aspect级别的观点分离:clear是专门描述screen的aspect观点,而great是general观点;
2、作者提出JAST模型进行aspect级别(细粒度)的观点挖掘,如下图。
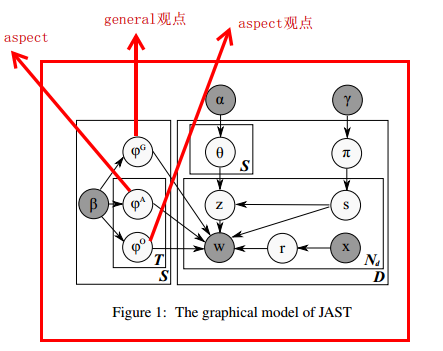
3、但通过分析,发现JAST的主要问题是常分不清general和aspect的观点词。如对于笔记本电脑,smooth是screen的aspect观点,但并不是所有笔记本电脑都是触摸屏的,所以对于topic model来说,它依赖的是词的共现,这种因为词的共现度低而造成aspect观点抽取不出的问题,topic model本身并不能解决。
4、这个时候就可以加入lifelong的思想,使用lifelong解决(在一个dataset中共现度低,但在多个dataset中,能够积累起来)。
5、LAST模型的算法如下图(实际就是JAST+Lifelong)。里面包括:
①使用SKL(Symmetrised KL Divergence)判断aspect的相似度,将很不相似的aspect不参与互学习;
②knowledge的存储;
③knowledge的挖掘,包括3类knowledge,分别是aspect-opinion,aspect-aspect,opinion-opinion;
④knowledge的使用,先过滤掉包含JAST模型生成的general观点词的knowledge;

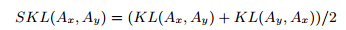
6、本文将6个模型进行实验对比:
①LDA[1];
②ASUM[2]:Aspect and Sentiment Unification Model,整合aspect和sentiment,以通过不同的aspect来生成sentiment;
③ASUM-L:对ASUM的改进,增加观点的词典来提升ASUM的效果;
④JAST;
⑤JAST-S:JAST的半监督模型,使用了最大熵分类器;
⑥LAST;
7、dataset:Amazon 50个商品的各1000个评论。
8、参数设定:α=0.1,β=0.01,γ=1,主题数15,1000次迭代。
9、评测方法:
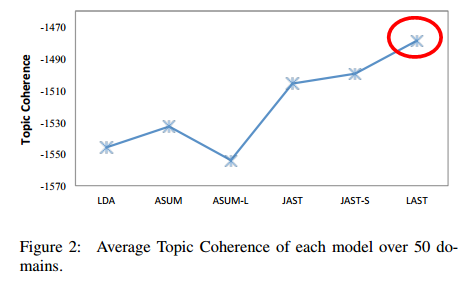
①topic coherenct;
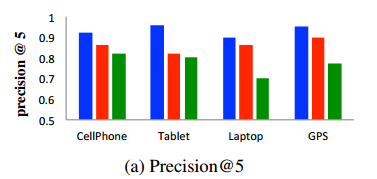
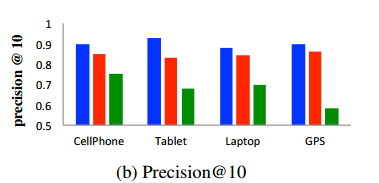
②precision@5,precision@10;
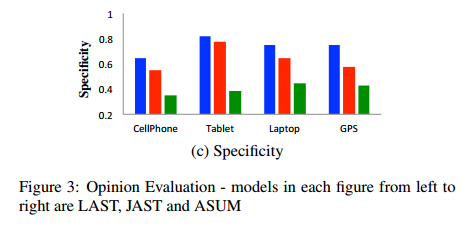
③specificity,评测top10主题词中aspect观点的比例;
P.S. ②③都是需要人工评测生成的主题词。
实验后评测发现比baseline好,而且LAST是比JAST好的。
10、思考:
一个dataset效果不够,需要多个dataset的知识积累的,就使用Lifelong思想吧。
参考资料:
[1]、http://www.jmlr.org/papers/v3/blei03a.html
[2]、http://dl.acm.org/citation.cfm?id=1935932
以上均为个人见解,因本人水平有限,如发现有所错漏,敬请指出,谢谢!















 1500
1500

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









