






本文共3748字,可根据需要在目录跳转阅读
二、LoRA训练环境 & Stable Diffusion WebUI 部署
Git,Visual Studio 2015,2017,2019 and 2022 redistributable
前言
简单介绍一下LoRA模型:LoRA是Low-Rank Adaptation of Large Language Models(大模型的低秩序自适应) 的缩写,也就是在大模型的基础上对部分神经网络进行调整训练。通俗来说,LoRA是“微调”大模型的。对比训练一个大模型的成本,“微调”大大降低了训练的成本同时更有效率地满足需求,造车也就不必从头再造轮子。LoRA的优势在于对特定风格及特定对象的训练,例如,对图片的统一风格化生成和特定IP形象的训练。
本文要点:
在我的学习过程中搜寻到的大部分参考文章都是以人像或IP形象为例进行的LoRA模型训练,苦于缺少LoRA模型在实体产品设计上的应用经验分享。本篇就以咖啡机为例分享LoRA模型在实体产品上训练的过程及应用效果分享(入门级实验性的训练,更多的实验反馈能够帮助学习优化模型效果)。
- LoRA训练环境的线上及线下部署经验
- 素材收集及训练过程
- 模型不同生成参数的效果对比和优化方法
一、设备要求
- 能跑得动的GPU(至少是消费级显卡)mac缺乏CUDA支持,推荐线上部署用云服务器跑
- 稳定的魔法
二、LoRA训练环境 & Stable Diffusion WebUI 部署
—本地部署
-
kohya_ss 训练脚本及GUI
https://github.com/bmaltais/kohya_ss
进入链接的github页面,下滑到readme的installation部分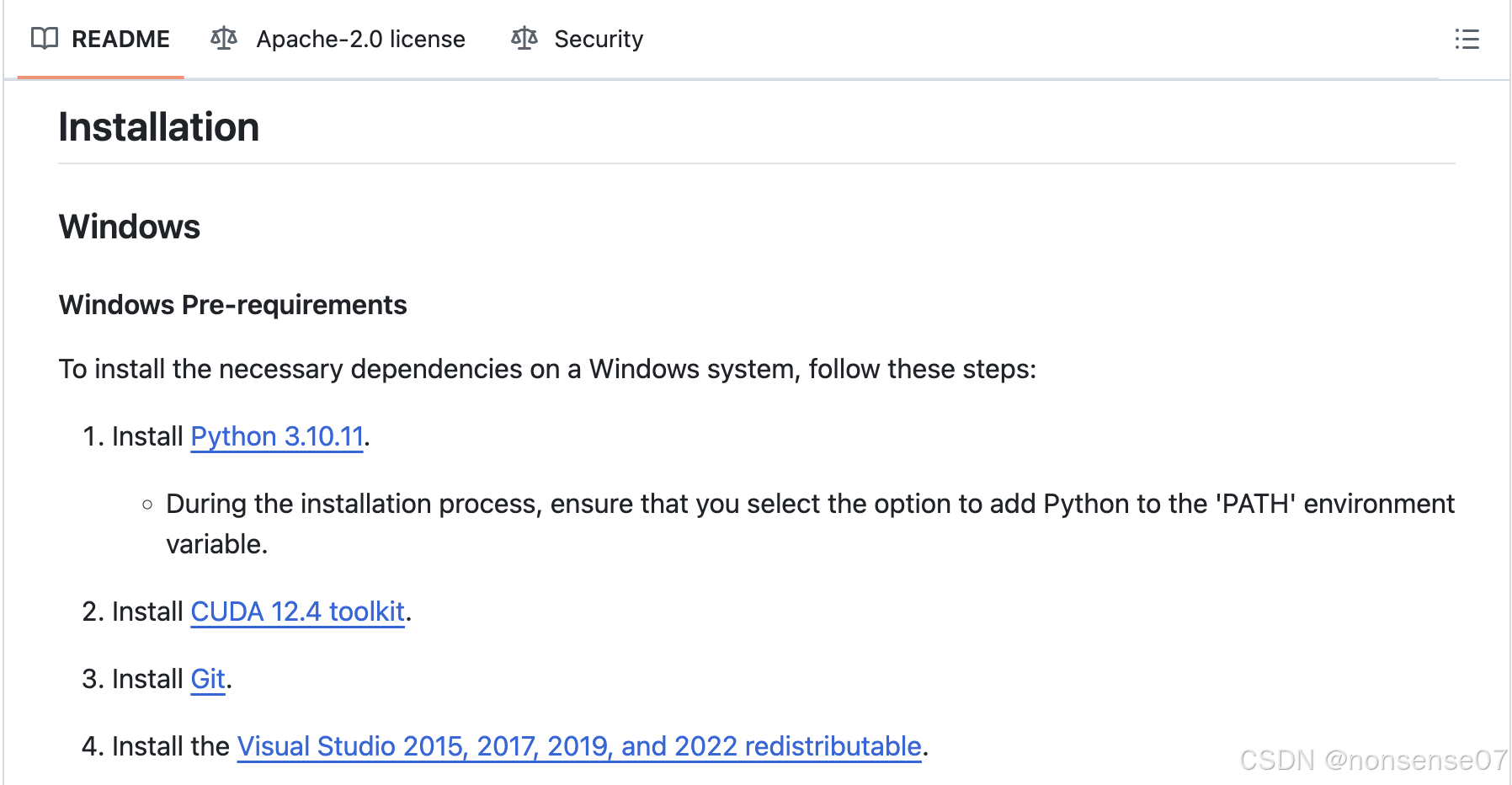
安装以上依赖的软件
python
—(推荐)下载anaconda,方便管理环境(这很重要)
https://www.anaconda.com/download/success官网下载安装后创建环境,在电脑菜单栏搜索打开anaconda prompt,并输入以下代码(其中name是可以自定义的,版本号我们就选依赖要求的3.10.11)
conda create -n name python=3.10.11
创建成功后,通过输入以下代码就能成功进入环境了
conda activate name(自定义的环境名)— 也可以直接安装,记得在安装时添加python到路径环境变量即可
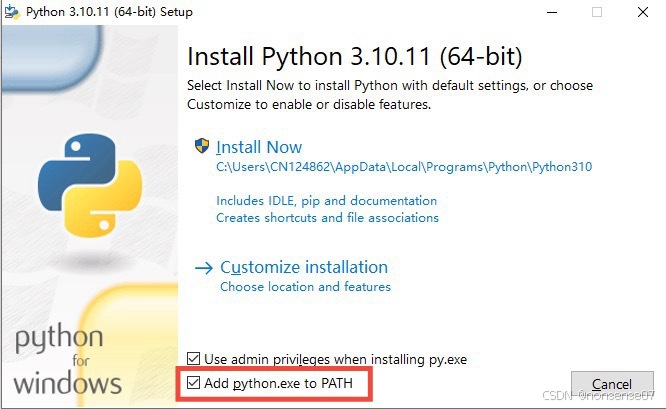
CUDA 12.4 toolkit
直接下载,官网会自动识别你的电脑配置
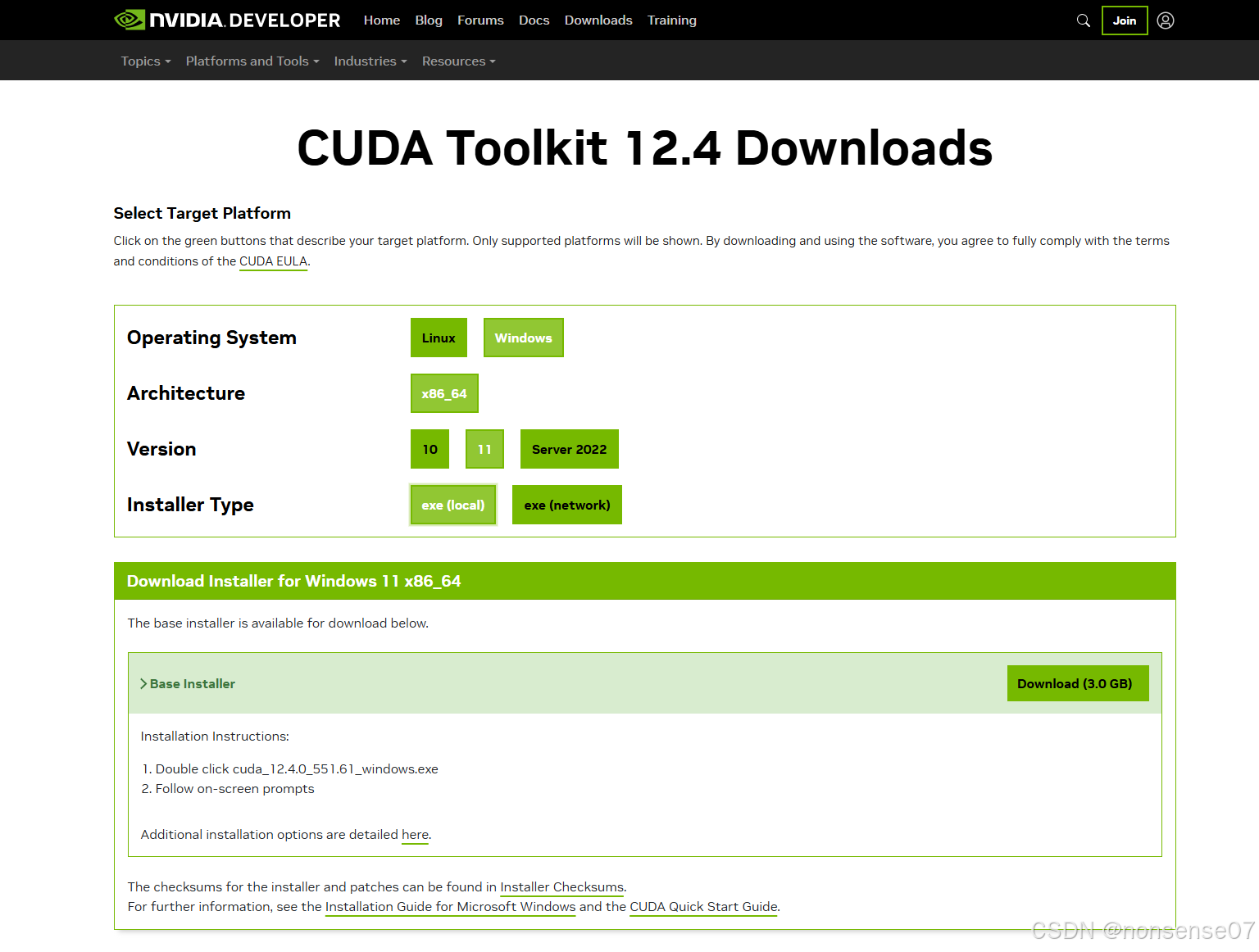
Git,Visual Studio 2015,2017,2019 and 2022 redistributable
直接下载安装
https://git-scm.com/downloads/winhttps://aka.ms/vs/17/release/vc_redist.x64.exe所有依赖安装完成后,若使用anaconda的,先在终端通过输入conda activate name进入环境,再执行以下命令,直接安装python的可直接在终端执行以下命令
git clone https://github.com/bmaltais/kohya_ss.git
cd kohya_ss.\setup.bat到这里kohya_ss的训练脚本和GUI部署就完成了
-
Stable Diffusion WebUI
再打开个终端界面,若使用anaconda的记得进入环境,执行以下命令
git clone https://github.com/AUTOMATIC1111/stable-diffusion-webui.git.\webui-user.bat到这里sd webui的部署也完成了
—线上部署(Google Colab)
优势:无需自己配置环境,不受硬件限制(相当于在云端借着别人的电脑在训练)
缺点:免费使用量有限额,一旦与云服务器断开,即失去记忆,重新再跑一遍
-
Stable Diffusion webUI
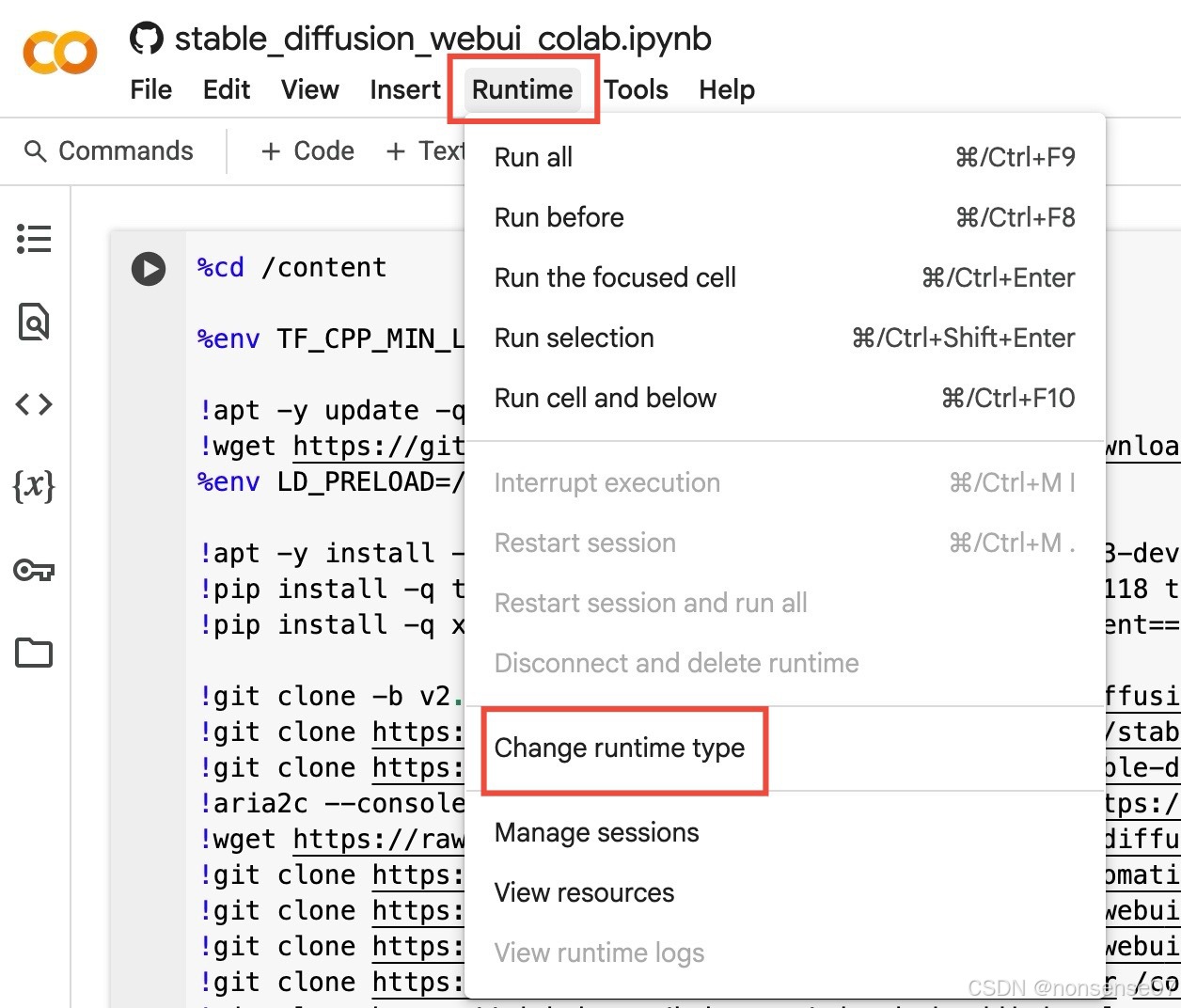
https://github.com/camenduru/stable-diffusion-webui-colab进入这个网址,下滑看到Colab,选择第一行的stable版本
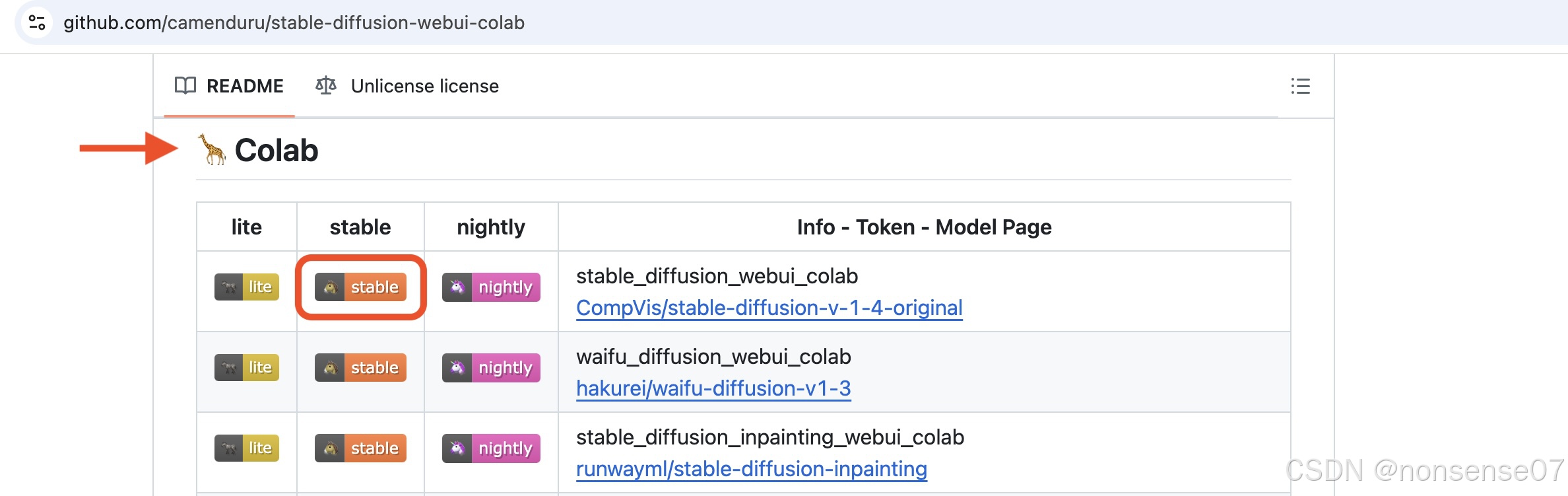
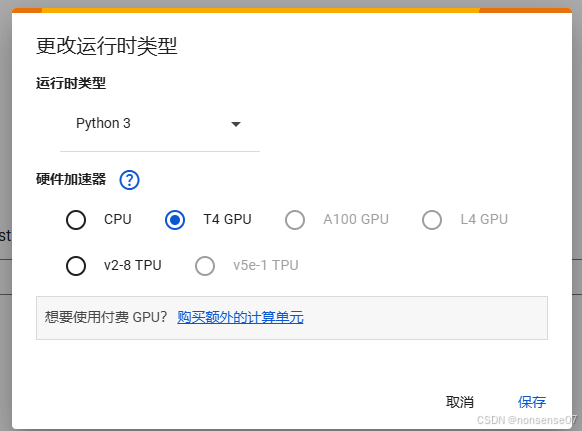
更改运行类型为gpu
-
kohya_ss trainer
https://github.com/Linaqruf/kohya-trainer 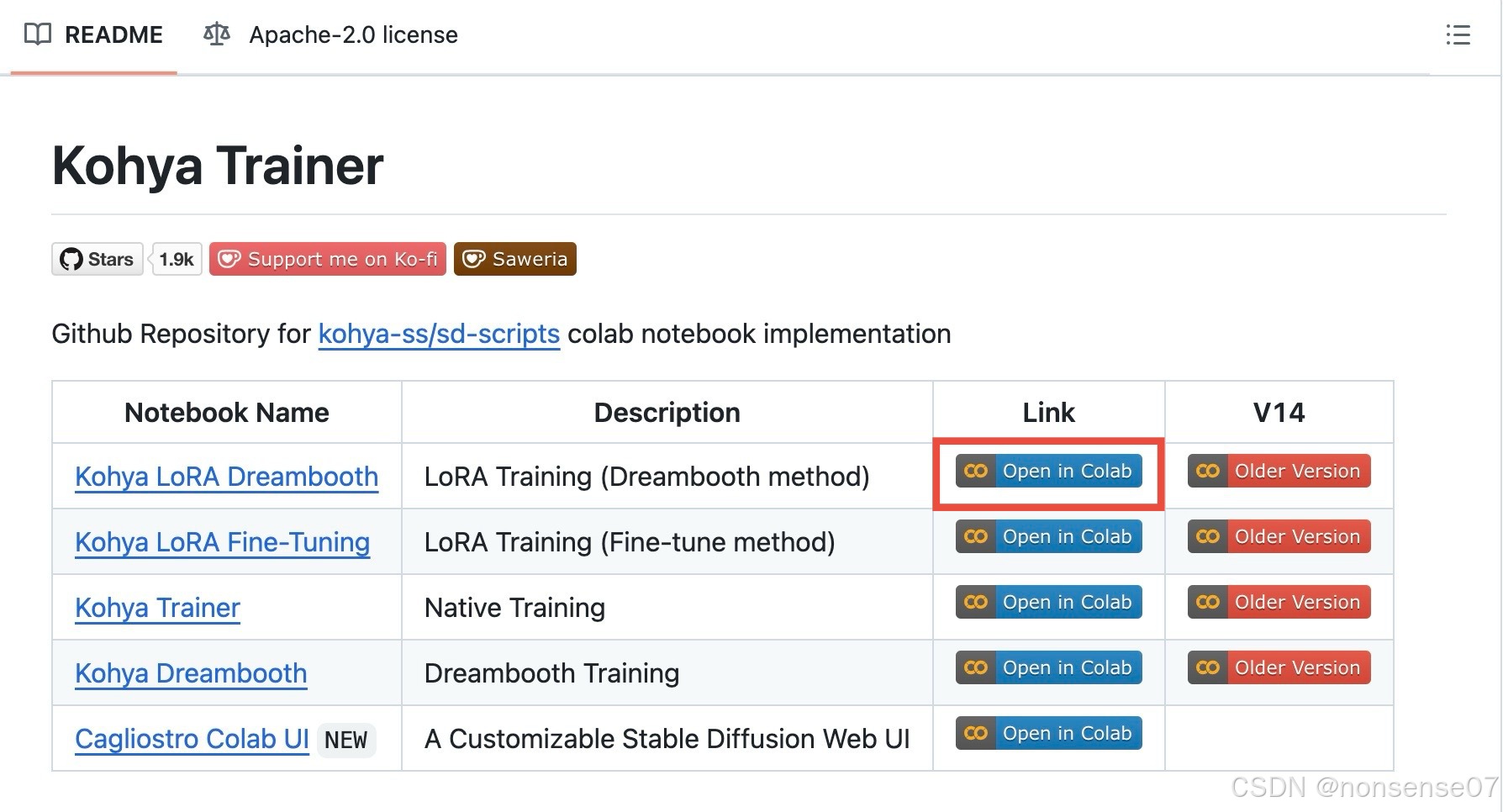
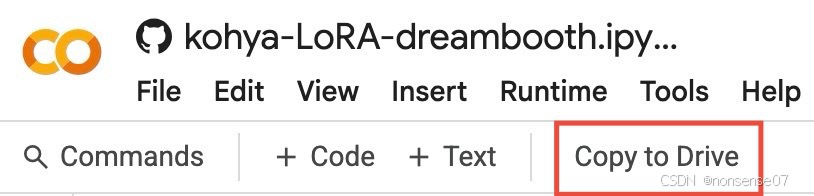
Google Colab与Google Drive联用的,复制到自己的Google Drive,训练集上传到Drive及训练生成的模型文件也会保存在Drive
三、实物产品LoRA训练过程及应用到SD生图
—LoRA训练过程
素材准备
在<kohya_ss>文件夹下新建<train>文件夹(用于放置所有训练相关的文件),再在<train>下新建<coffee machine>文件夹(用于放置本次训练的文件)

在<coffee machine>文件下新建以下三个文件夹

在<image>文件夹中新建<100_cof>文件夹用于存放素材(该文件夹命名的数字会影响训练步数,可根据需要更改)
素材要主体清晰,尽量多角度,也可以添加在场景中的
素材打标
若用anaconda的要conda activate进入相应环境,在终端执行以下命令,打开sd webui界面
cd stable-diffusion-webui.\webui-user.bat将<100_cof>的文件夹地址复制粘贴到以下页面的【Input directory】和【Output directory】,并在【Caption]中选中【Deepbooru】或【BLIP】(也可以同时选中)
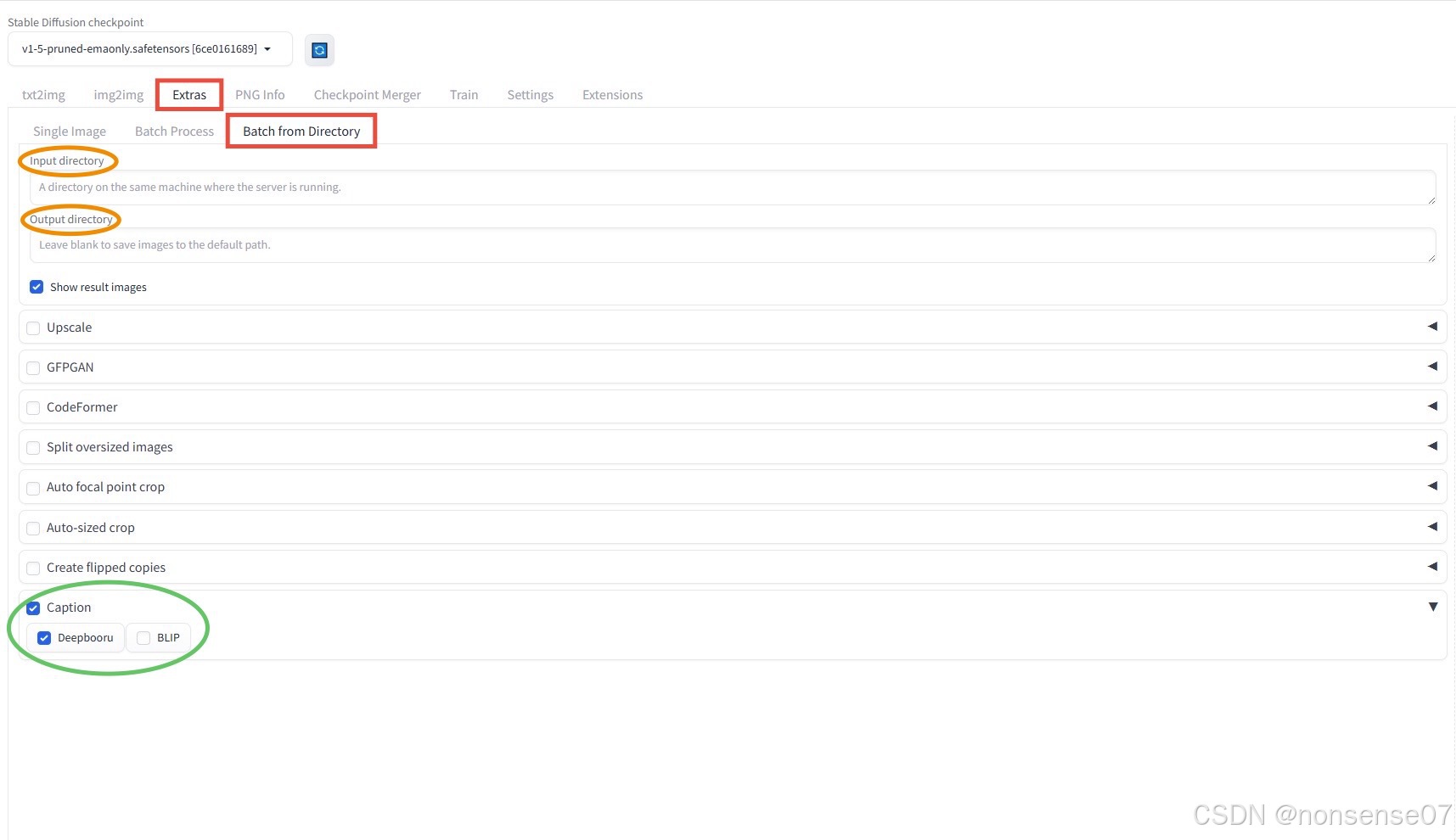
生成后即可在<100_cof>文件夹中看到每张图片对应的标签(.txt文件),并根据需要手动优化
训练设置
在对应环境下,开个新的终端页面,执行以下命令,打开kohya_ss的训练界面
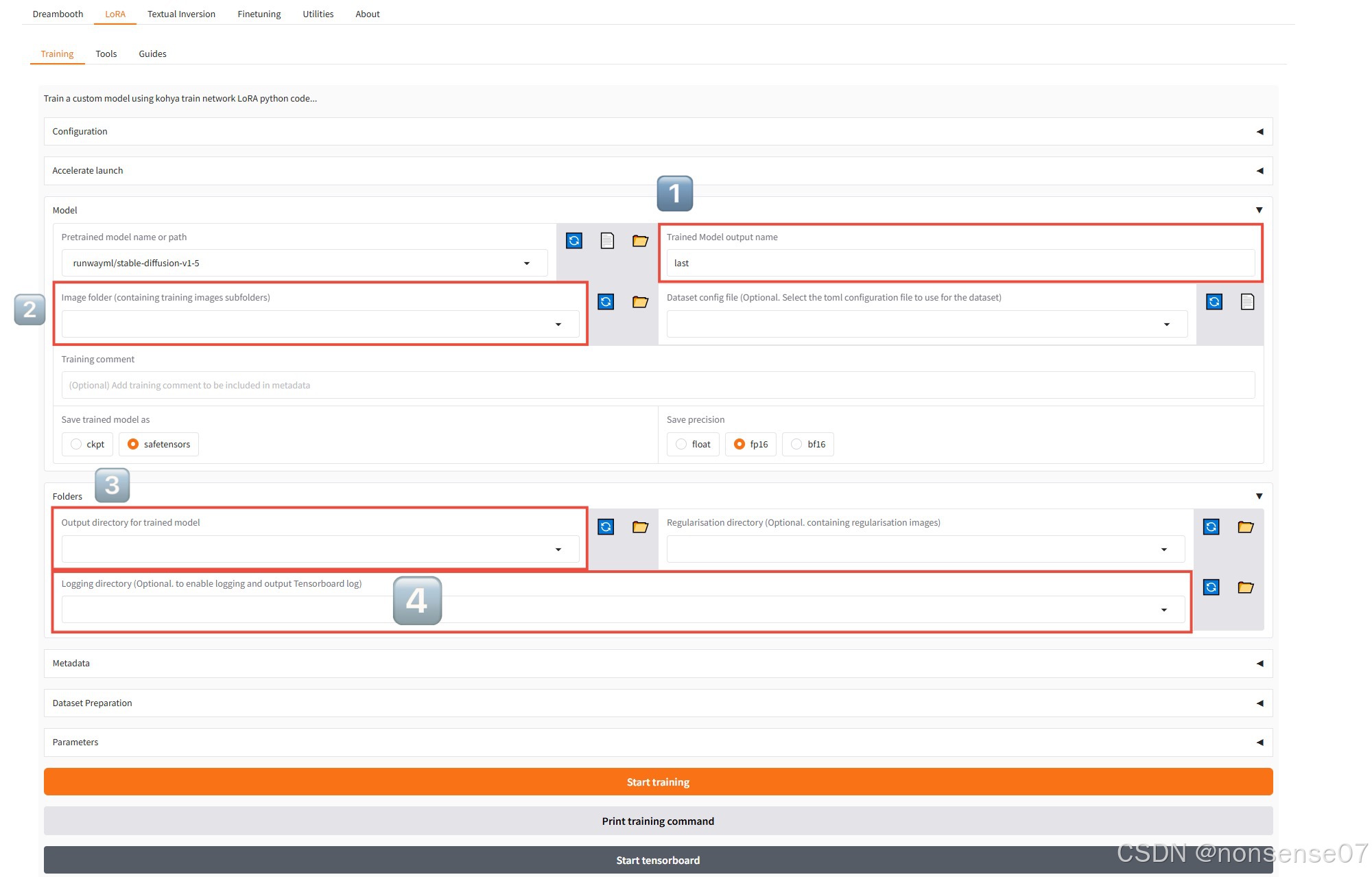
cd kohya_ss.\gui.bat图片中标注的四处是训练必填的,分别是1️⃣lora模型名称 2️⃣image文件夹地址 例如:kohya_ss/train/image 3️⃣模型结果保存地址 例如:kohya_ss/train/model
4️⃣训练日志存放地址 例如:kohya_ss/train/log,点击“start training” 开始训练
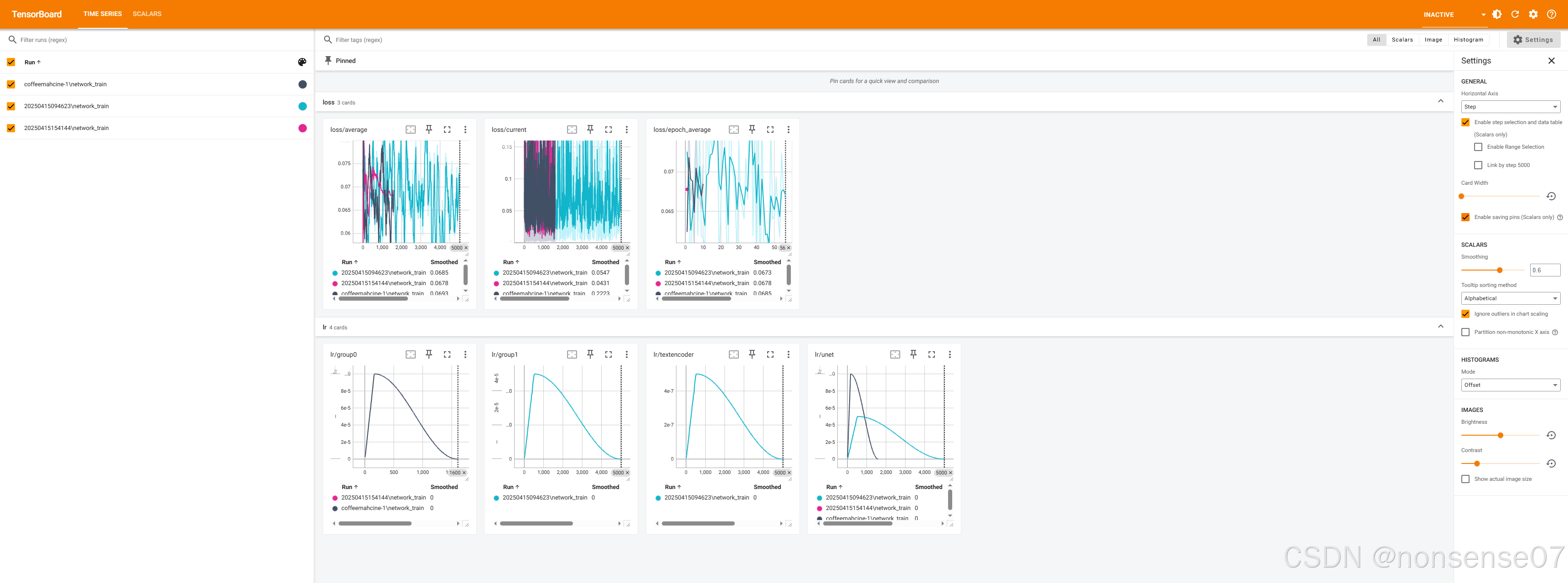
训练开始后,点击“start tensorboard”可以看到实时训练日志,如果训练结束后还想看某次训练的日志情况,只用填4️⃣的文件夹,再“start tensorboard”就可以看到了
—LoRA应用到Stable diffusion生图
模型导入
产品生图目前sd在civitai最火的就是名为ProductDesign的大模型,该网址可直接下载
https://civitai.com/models/23893/product-design-minimalism-eddiemauro下载后将该模型移入【stable-diffusion-webui】文件夹下【models】文件夹下的【stable-diffusion】文件夹中 (该文件夹存放checkpoint大模型)
(ps:使用该大模型,prompt的第一个词必须得是"3D product render"或"product render"以激活使用)
并将训练好的safetensors后缀的模型文件复制或移动到【stable-diffusion-webui】文件夹下的【models】文件夹下的【LoRA】文件夹中
打开sd webui可以刷新看到,点击即可以选择ProductDesign大模型并在prompt中调用LoRA模型
生图测试
在sd生图我们常要对各种可能影响的参数进行测试,以达到较好的生图效果,X/Y/Z plot是不可以错过的生图脚本。
通过更改xyz的type,可以同时对不同采样器(sampler),采样步数(steps),LoRA模型权重进行列表对比
例如:X type为sampler values选择了不同的采样器,Y type为steps values选择
例如:X type为sampler/X values为不同的采样器,Y type为steps/Y values为5,10,15,20,25,30

Sampler目前来说效果比较好的是DPM++2M,schedule type:karras,Steps大概在20-30会较为理想
同时LoRA对光影风格的迁移学习能力会较强,以下是用了xiaomi su7仅4张图片训练的LoRA配合咖啡机训练的LoRA生图的测试


更多LoRA模型训练与SD生图在产品上的应用要点总结会在后续分享

















 1438
1438

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









