






Blended RAG:IBM新研究,大幅超越传统RAG的新方案
RAG
检索增强生成(RAG)广泛应用于结合大型语言模型(LLM)和私有文档库,以打造高效的生成式问答系统。但随着文档库规模的扩大,提高 RAG 的准确率变得愈发困难,检索器通过从众多文档中筛选出最相关的信息来为 LLM 提供必要上下文,对 RAG 的准确性起着至关重要的作用。本文提出了一种新型的“混合 RAG”策略,结合了密集向量索引、稀疏编码器索引等语义搜索技术及混合查询策略。通过这种方法,我们在 NQ 等信息检索数据集上取得了更佳的检索成效,并刷新了基准记录。此外,我们将“混合检索器”应用于 RAG 系统,使得在 SQUAD 等生成式问答数据集上的表现大幅超越了传统的细调方法。
RAG的局限性
RAG利用了大语言模型超强的推理能力、理解能力,结合外部知识库,一举成为当前最热的大语言模型应用框架之一。RAG的成功是因为他将大语言模型的创造力和搜索引擎融为一体。RAG框架的核心一般包括两个组件:检索器(R)和生成器(G),其中,生成器的效果取决于大语言模型本身的参数规模和效果。
虽然大语言模型可以流畅的输出内容,但是知识库却并不总是有效。这个时候,检索器就开始发挥作用了,检索器可以迅速的从海量文档中筛选出有效的信息,补充和完善模型的输出。检索器为生成器提供精准的上下文信息。
目前,主流的检索器检索方法大多是依赖于关键词和相似性检索,这种方法会降低系统的整体准确程度。尽管可以已通过调整大语言模型的Prompt和参数来提升RAG的准确度,但是如果检索器提供的信息与查询不相关,那么最终答案势必会受到影响,变得不准确。
所以提升RAG准确度的方法,除了针对生成器的优化外,更大的空间则留给了检索器部分。作者的这篇文章,通过结合语义搜索和混合型搜索查询,来提高检索器和整个RAG系统的准确度。
什么是 Blended RAG?
在这篇论文中,作者尝试了三种独特的搜索策略:
- • 基于关键词相似度的搜索
- • 基于密集向量的搜索
- • 基于语义的稀疏编码器搜索
- • 以及将以上三者的融合,创造出混合型查询方式
语义搜索突破了传统关键词匹配的局限,深入理解用户查询的深层含义和真正目的。本项研究对三种主要索引的多种搜索技术进行了系统性评估:
- • BM25用于关键词搜索
- • KNN用于向量搜索
- • Elastic Learned Sparse Encoder(ELSER)则用于稀疏编码器的语义搜索
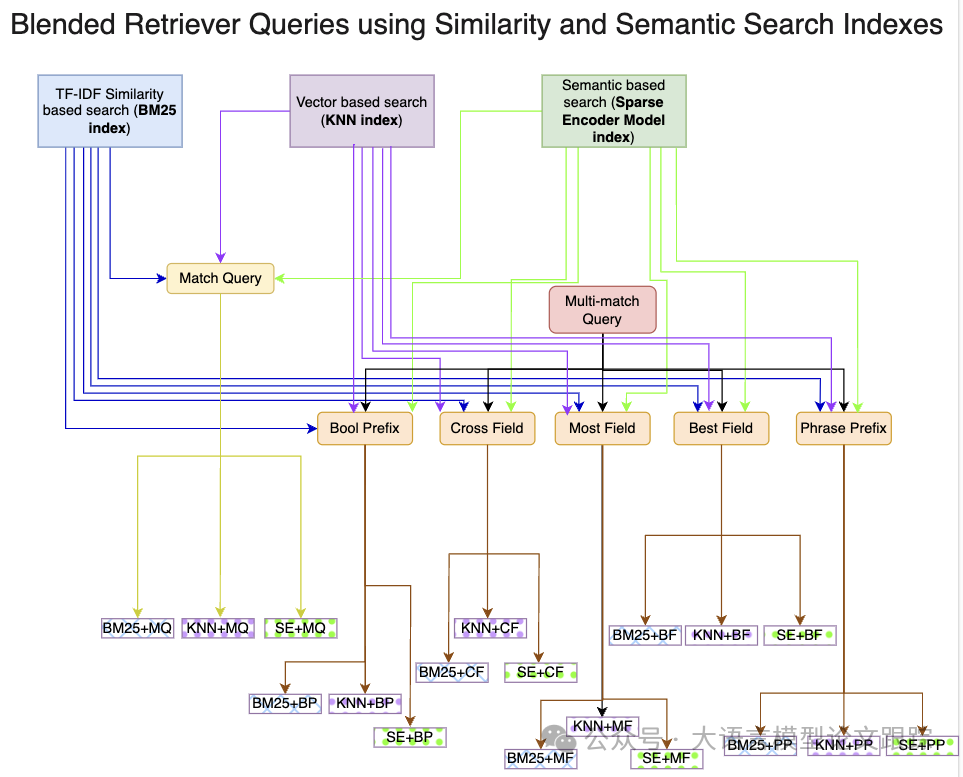
- \1. BM25索引:BM25索引精于运用全文搜索,并结合模糊匹配技术,为执行更高级的查询操作打下坚实基础。
- \2. 密集向量索引:构建的密集向量索引得益于句子转换器,能够精确衡量文档内容与查询内容向量表示的相似性。
- \3. 稀疏编码器索引:稀疏编码器检索模型索引融合了语义理解和相似性检索,捕捉词汇间细微的关系,更真实地反映用户意图与文档的相关性。
评估方法
作者按照一系列循序渐进的步骤推进评估,先从BM25索引的基本匹配查询开始。然后,转向混合查询,融合了多个字段的多样搜索技术,并运用稀疏编码器基础索引的多次匹配查询。这种方法在文档集合中查询文本的确切位置不明时显得尤为关键,确保了检索结果的全面性。
多匹配查询可归纳为:
跨界字段:在多个字段间寻找交集。多领域:透过各个领域的不同视角捕捉文本表现。精选字段:聚焦单一字段内词汇的聚合。短语优先:与精选字段相似,但更侧重短语匹配。
初步匹配查询完成后,引入了密集向量(KNN)和稀疏编码器索引,并为它们各自设计了专门的混合查询。这种策略性的方法汇聚了各个索引的长处,共同致力于提升我们RAG系统中的检索精确度。通过计算前k项检索准确度指标,来提炼每种查询方式的核心价值。
在众多潜在的组合中,精心挑选了六种最好的混合查询组合——它们在检索效能上表现最为出色,以便进一步深入研究。这些查询在一系列基准数据集上经过了严格的测试,以验证RAG系统中检索部分的准确性。
测试用的数据集包括:自然问题(NQ)、斯坦福问答数据集(SqUAD)和HotPotQA等。
检索器(Retriever)测试结果
NQ数据集的结果
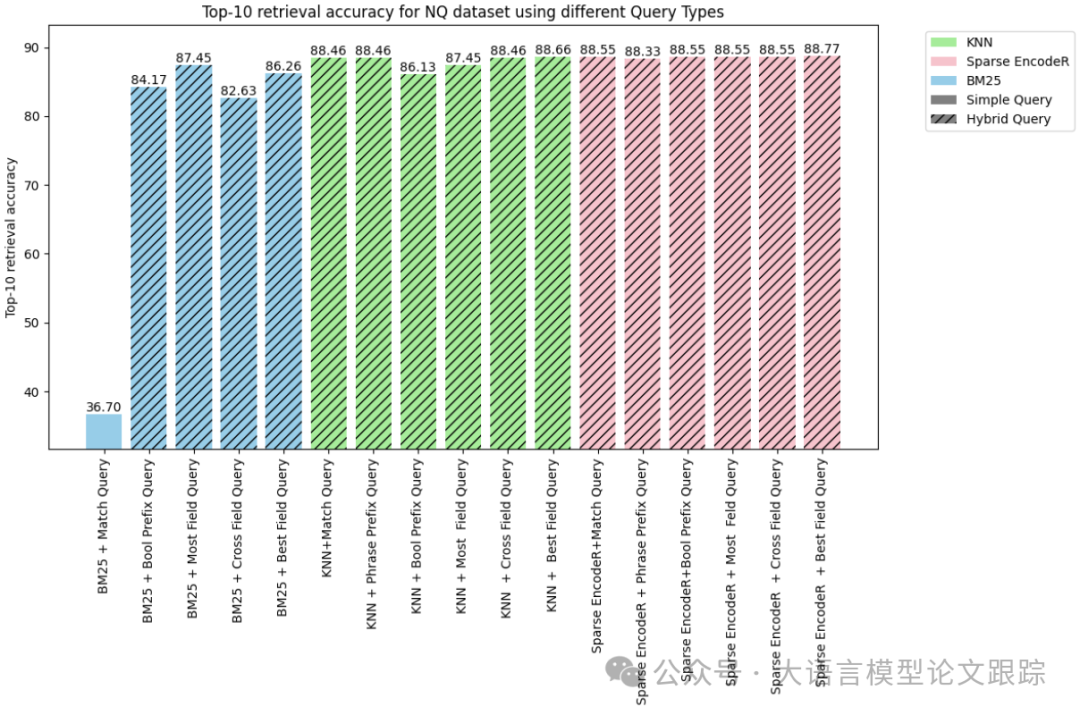
针对NQ数据集:结合稀疏编码器和最佳字段的混合查询策略实现了最高的检索准确率,达到了惊人的88.77%。该成果不仅超越了其他各种方法,还为该数据集内的检索任务创造了新的参考标准。
HotPotQA数据集中的前10项检索精准度
拥有逾500万文档和7500个查询项目的HotPotQA数据集,因计算需求庞大,全面评估也很难。
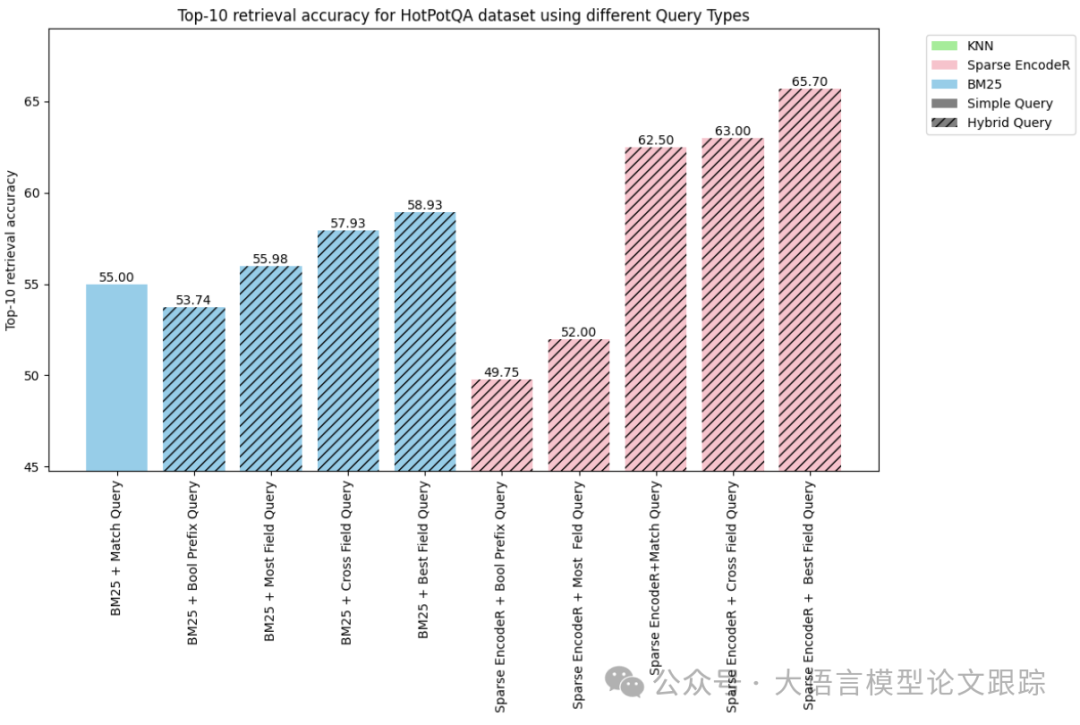
如上图所示,采用跨领域和精选领域等策略的混合查询表现尤为突出。其中,融合了稀疏编码器与精选领域搜索的混合查询在HotPotQA数据集中的效率最高,达到了65.70%。
测试结果总结
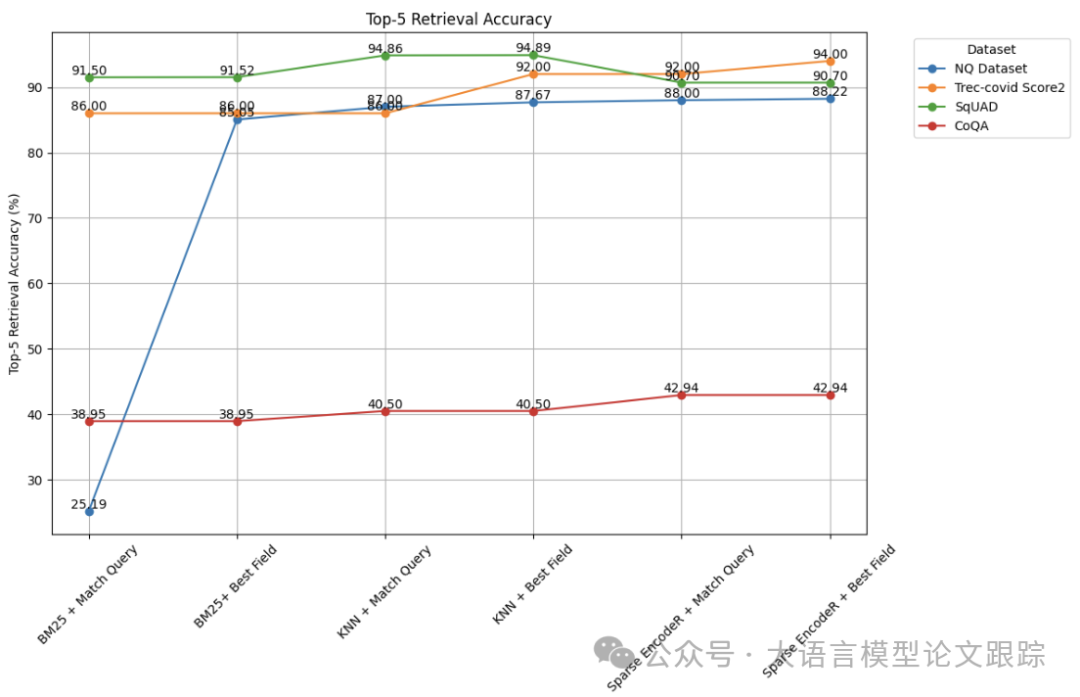
- • 除了CoQA数据集之外,我们的混合查询在所有数据集中都显示出提升的检索准确度,这得益于其有效利用元数据以获取最切题的搜索结果。
- • 采用基于密集向量的(KNN)语义搜索技术,相较于传统的关键词搜索方法,取得了显著的进步。
- • 基于语义搜索的混合查询在检索精度上超越了传统的关键词搜索和向量搜索。
- • 当结合“最佳字段”策略使用稀疏编码器的语义搜索时,往往能够带来比其他方法更佳的检索效果。
RAG评估测试结果
通过检索器评估实验,确定了最佳检索器,也就是最佳的索引加查询组合。接下来将最佳检索器应用于RAG流程的评估。为消除LLM的规模或类型对结果的影响,所有实验均采用FLAN-T5-XXL模型进行。
针对SqUAD数据集的V-ARAG评估
SqUAD是评估RAG系统或利用LLMs进行生成性问答的标准数据集。我们的研究对先前工作中的三种RAG流程变体进行了对比分析,采用精确匹配(EM)和F1分数作为评估指标,衡量答案生成的准确度,同时考量检索准确度的前5和前10名。
对照组RAG Pipeline
- • RAG-original:此变体是在自然问题数据集上经过微调的模型,尚未进行特定领域的适配。
- • RAG-end2end:作为RAG-original的进阶版,该模型针对SQuAD领域进行了进一步的微调,以实现领域适配。
Blended RAG:我们的Blended RAG变体独树一帜,未在SQuAD数据集或相关语料库上进行训练。它结合了优化的字段选择和语义索引的混合查询策略,旨在为LLMs提供精准信息,生成最为精确的回答。
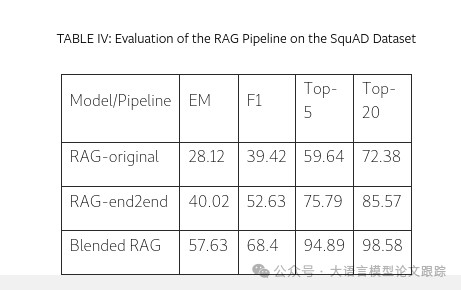
如上表所展示,我们的Blended RAG在生成性问答领域表现卓越,即便未对特定数据集进行微调,F1分数也提升了50%。这种特性对于大型企业数据集尤为有益,微调在这些场景中可能难以实施或根本无法实现,这突显了本研究的核心应用潜力。
局限性
稀疏向量索引与密集向量索引的权衡
HotPotQA语料库包含500万份文档,计算挑战巨大,生成的密集向量索引大约有50GB,严重影响了处理效率。密集向量索引以其快速的索引能力著称,但查询性能相对较慢。与此相反,稀疏向量索引虽然索引速度较慢,却能提供更快的查询体验。此外,两者在存储需求上的差异非常明显;例如,HotPotQA语料库的稀疏向量索引仅占用了10.5GB空间,而相应的密集向量索引则需50GB。
在这种情况下,我们建议采用稀疏编码器索引。对于数据量如此庞大的企业,我们还发现采用多租户联合搜索查询更为高效。
缺乏元数据的混合检索器
当数据集包含元数据或其他相关信息时,能够增强混合检索器的效果。然而,对于那些缺乏元数据的数据集,如CoQA,其效果并不显著。
一些结论
- • 通过混合搜索优化R:结合语义搜索,特别是与“最佳字段”查询相结合的稀疏编码器索引,已成为所有方法中的最优结构。
- • 通过混合检索器增强RAG:检索准确度的显著提升在RAG流程的整体评估中尤为明显,大幅超过了微调集上先前的基准。
https://arxiv.org/abs/2404.07220
通往 AGI 的神秘代码
if like_this_article():
do_action('点赞')
do_action('再看')
if like_all_arxiv_articles():
go_to_link('https://github.com/HuggingAGI/HuggingArxiv') star_github_repo(''https://github.com/HuggingAGI/HuggingArxiv')















 149
149

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









