






5 卷积神经网络基础
5.4 基本卷积神经网络
5.4.1 AlexNet
网络提出:

网络结构:
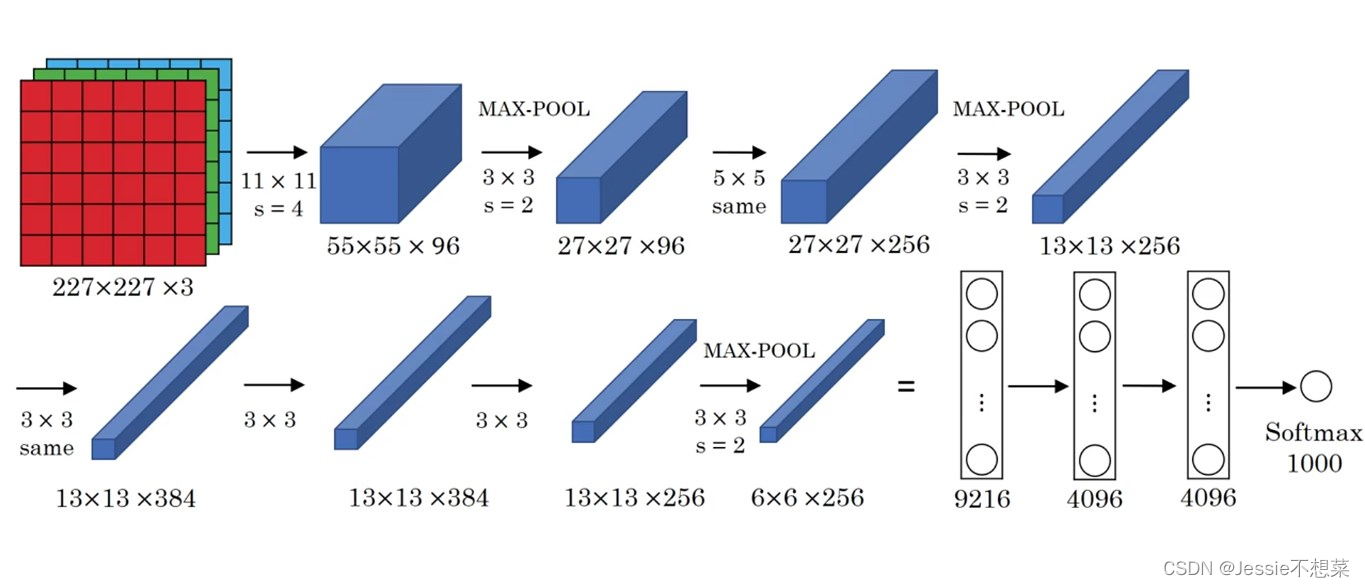
网络说明:
- 网络一共有8层可学习层——5层卷积层和3层全连接层
- 改进
- -池化层均采用最大池化
- -选用ReLU作为非线性环节激活函数
- -网络规模扩大,参数数量接近6000万
- -出现“多个卷积层+一个池化层”的结构
- 普遍规律
- -随网络深入,宽、高衰减,通道数增加

改进:输入样本
- 最简单、通用的图像数据变形的方式
- 从原始图像(256,256)中,随机的crop出一些图像(224,224)。【平移变换,crop】
- 水平翻转图像。【反射变换,flip】
- 给图像增加一些随机的光照。【光照、彩色变换,color jittering】

改进:激活函数
- 采用ReLU替代 Tan Sigmoid
- 用于卷积层与全连接层之后
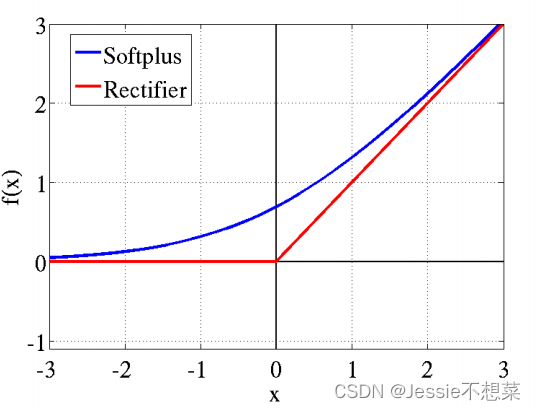
改进:
Dropout
- 在每个全连接层后面使用一个 Dropout 层,以概率 p 随机关闭激活函数
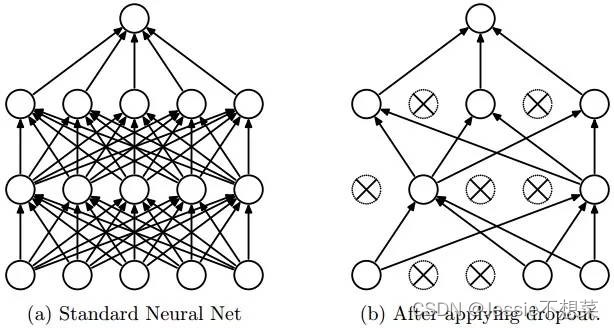
改进:双GPU策略
- AlexNet使用两块GTX580显卡进行训练,两块显卡只需要在特定的层进行通信
5.4.2 VGG-16
网络提出:

网络结构:
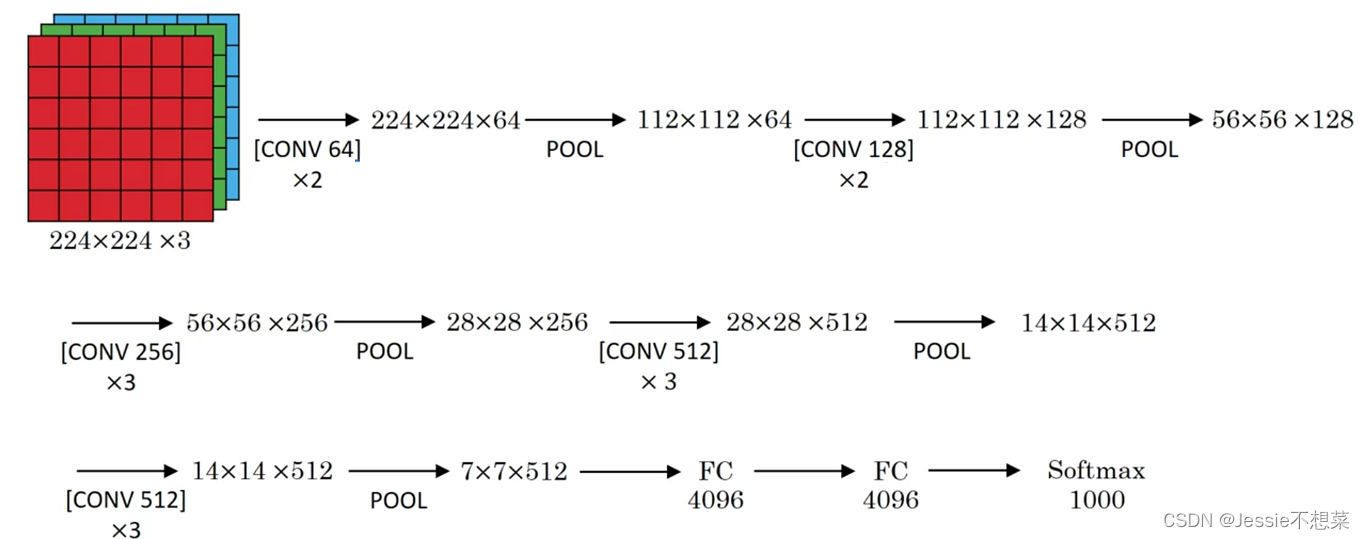

网络说明:
- 改进
- -网络规模进一步增大,参数数量约为1.38亿
- -由于各卷积层、池化层的超参数基本相同,整体结构呈现出规整的特点。
- 普遍规律
- -随网络深入,高和宽衰减,通道数增多。
5.4.3 残差网络
非残差网络的缺陷:

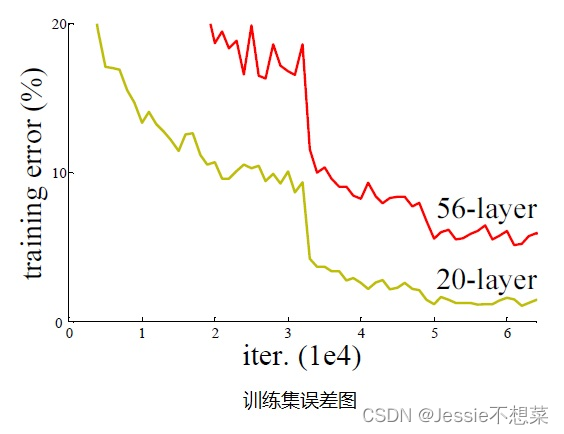
残差网络的优势:
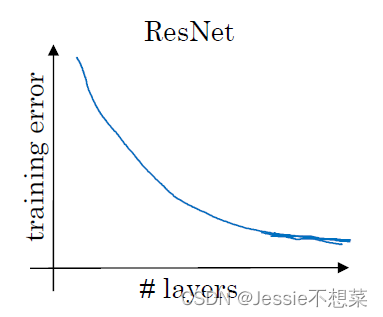
梯度消失问题:


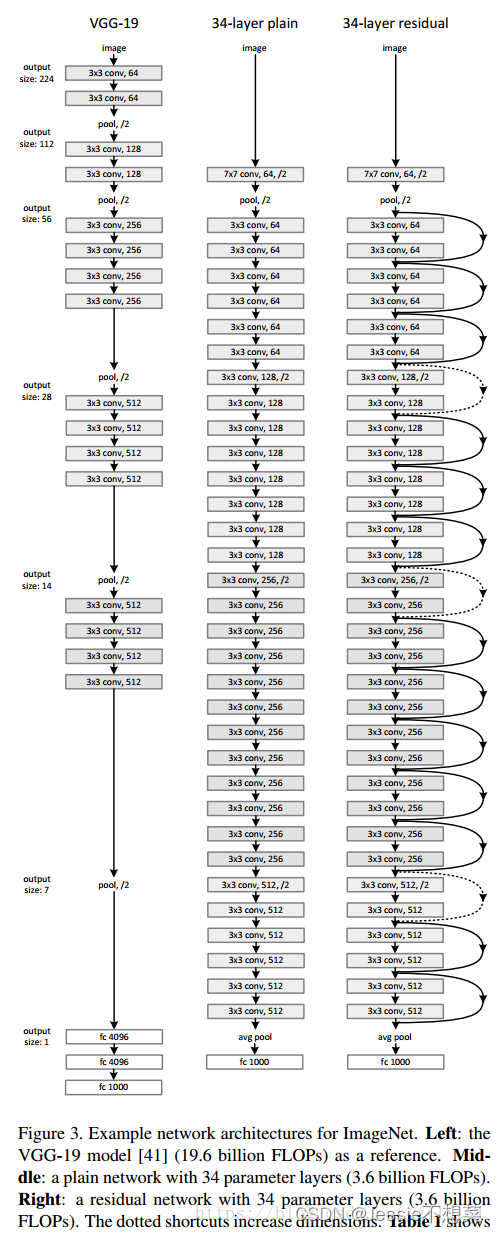
残差网络
- 普通网络的基准模型受VGG网络的启发
- 卷积层主要有3×3的过滤器,并遵循两个简单的设计规则:①对输出特征图的尺寸相同的各层,都有相同数量的过滤器; ②如果特征图的大小减半,那么过滤器的数量就增加一倍,以保证每一层的时间复杂度相同。
- ResNet模型比VGG网络更少的过滤器和更低的复杂性。ResNet具有34层的权重层,有36亿FLOPs,只是VGG-19(19.6亿FLOPs)的18%。
5.5 常用数据集
5.5.1 MNIST
- MNIST:
MNIST
数据集主要由一些手 写数字的图片和相应的标签组成,图片一共有
10
类,分别对应从
0~9
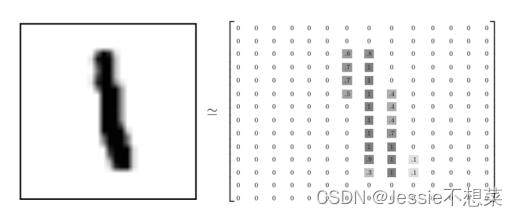
原始的 MNIST 数据库一共包含下面 4 个文件
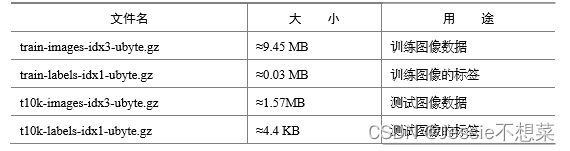
MNIST数据集是由0〜9手写数字图片和数字标签所组成的,由60000个训练样本和10000个测试样 本组成,每个样本都是一张28 * 28像素的灰度手写数字图片。

数据集加载:

- Fashion-MNIST:
- FashionMNIST 是一个替代 MNIST 手写数字集 的图像数据集。它是由 Zalando旗下的研究部门提供,涵盖了来自 10 种类别的共 7 万个不同商品的正面图片。
- FashionMNIST 的大小、格式和训练集/测试集划分与原始的MNIST 完全一致。60000/10000 的训练测试数据划分,28x28的灰度图片。你可以直接用它来测试你的机器学习和深度学习算法性能,且不需要改动任何的代码。
以下是数据集中的类,以及来自每个类的
10
个随机图像:

5.5.2 PASCAL VOC
- PASCAL的全称是Pattern Analysis, Statistical Modelling andComputational Learning
- VOC的全称是Visual Object Classes
- 目标分类(识别)、检测、分割最常用的数据集之一
- 第一届PASCAL VOC举办于2005年,2012年终止。常用的是PASCAL 2012
- 一共分成20类:
- person
- bird, cat, cow, dog, horse, sheep
- aeroplane, bicycle, boat, bus, car, motorbike, train
- bottle, chair, dining table, potted plant, sofa, tv/monitor
- 文件格式:

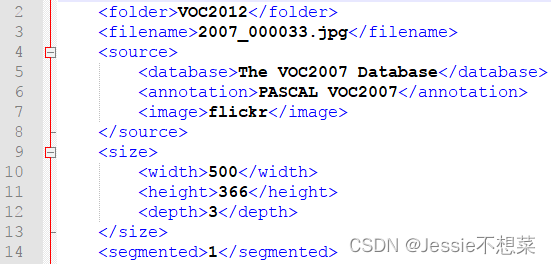
- 标注格式:
里面是图像对应的XML标注信息描述,每张图像有一个与之对应同名的描述XML
文件,
XML
前面部分声明图像数据来源,大小等元信息,举例如下:
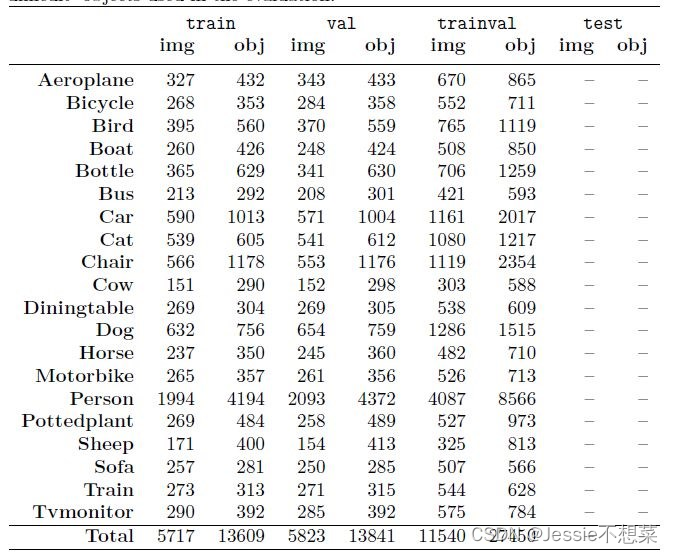
Pascal VOC2012 Main
中统计的训练、验证、验证与训练、测试图像:
5.5.3 MS COCO
- PASCAL的全称是Microsoft Common Objects in Context,起源 于微软于2014年出资标注的Microsoft COCO数据集
- 数据集以scene understanding为目标,主要从复杂的日常场景中截取
- 包含目标分类(识别)、检测、分割、语义标注等数据集
- ImageNet竞赛停办后,COCO竞赛就成为是当前目标识别、检 测等领域的一个最权威、最重要的标杆
- 官网:http://cocodataset.org
提供的标注类别有80 类,有超过33 万张图片,其中20 万张有 标注,整个数据集中个体的数目超过150 万个。
- 人:1类
- 交通工具:8类,自行车,汽车等
- 公路常见:5类,信号灯,停车标志等
- 动物:10类,猫狗等
- 携带物品:5类,背包,雨伞等
- 运动器材:10类,飞盘,滑雪板,网球拍等。
- 厨房餐具:7类,瓶子,勺子等
- 水果及食品:10类
- 家庭用品:7类,椅子、床,电视等
- 家庭常见物品:17类,笔记本,鼠标,遥控器等
5.5.4 ImageNet
- 始于2009年,李飞飞与Google的合作:“ImageNet: A Large-Scale Hierarchical Image Database”
- 总图像数据:14,197,122
- 总类别数:21841
- 带有标记框的图像数:1,034,908
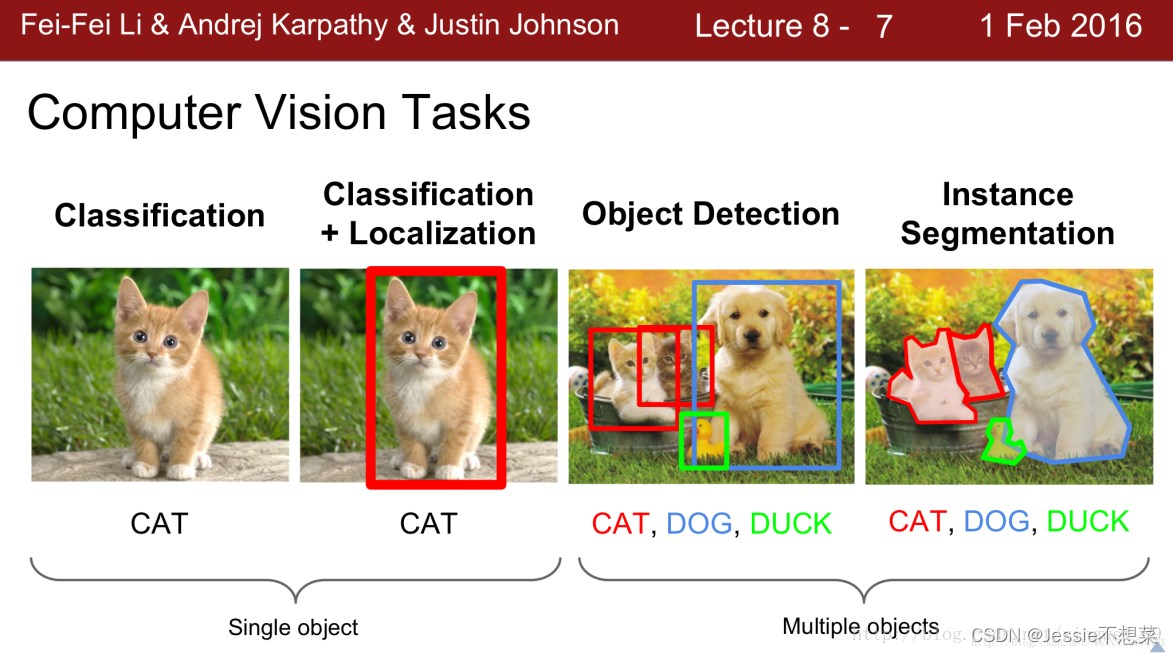
6 深度学习视觉应用
6.1 评价指标
6.1.1 相关概念
TP:被正确地划分为正例的个数,即实际为正例且被分类器划分为正例的实例数
FP:被错误地划分为正例的个数,即实际为负例但被分类器划分为正例的实例数
FN:被错误地划分为负例的个数,即实际为正例但被分类器划分为负例的实例数
TN:被正确地划分为负例的个数,即实际为负例且被分类器划分为负例的实例数
精确率P(Precision):TP/(TP+FP)
召回率R(Recall):TP/(TP+FN)。
P-R的关系曲线图,表示了召回率和准确率之间的关系:

精度(准确率)越高,召回率越低
置信度与准确率:
- 可以通过改变阈值(也可以看作上下移动蓝色的虚线),来选择让系统识别能出多少个图片,当然阈值的变化会导致Precision与Recall值发生变化。比如,把蓝色虚线放到第一张图片下面,也就是说让系统只识别出最上面的那张飞机图片,那么Precision的值就是100%,而Recall的值则是20%。如果把蓝色虚线放到第二张图片下面,也就是说让系统只识别出最上面的前两张图片,那么Precision的值还是100%,而Recall的值则增长到是40%。
AP
计算:
- mAP:均值平均准确率
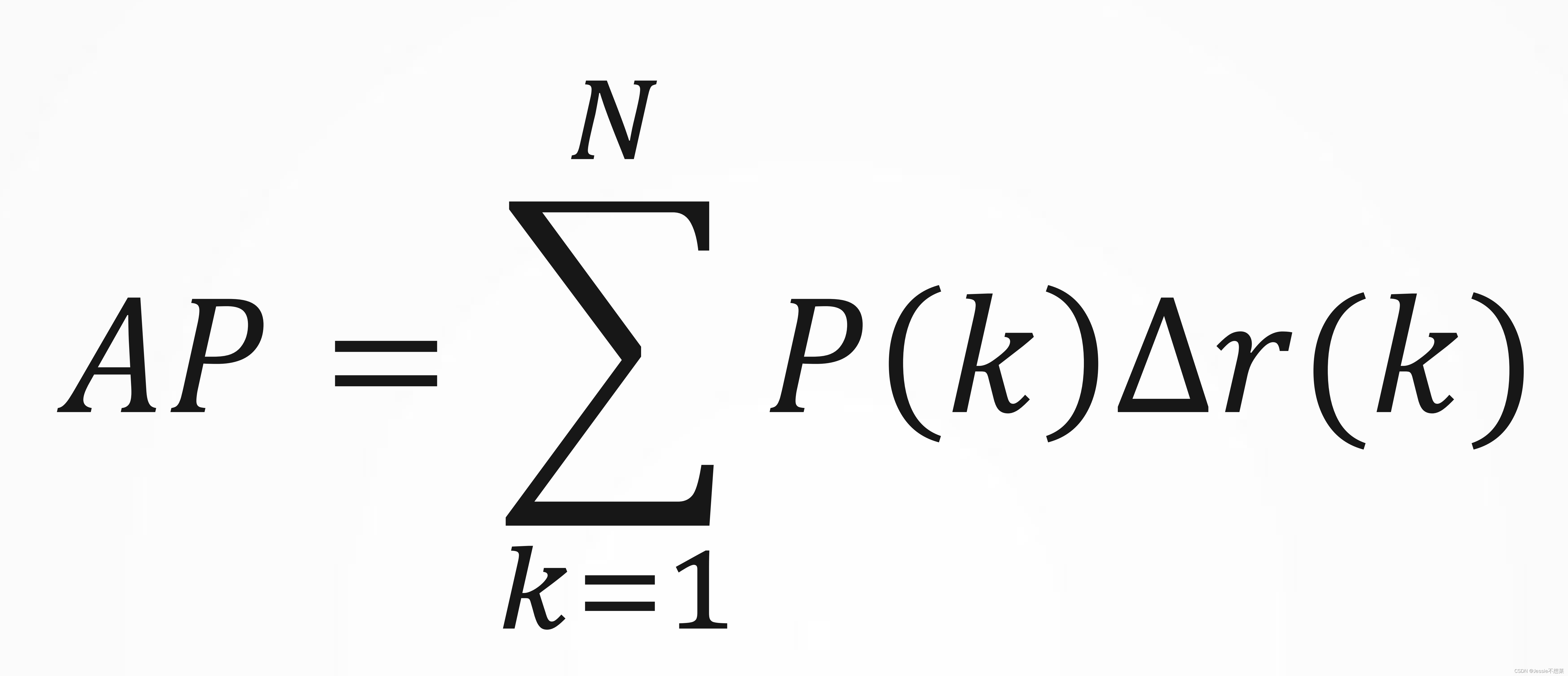
其中𝑁代表测试集中所有图片的个数 𝑃(𝑘)表示在能识别出 𝑘个图片的时候Precision 的值,而 Δ𝑟(𝑘)则表示识别图片个数从 𝑘−1变化到 𝑘时(通过调整阈值)Recall 值的变化情况 。
mAP计算:
- 每一个类别均可确定对应的AP
- 多类的检测中,取每个类AP的平均值,即为mAP
6.2 目标检测与YOLO
- 目标检测问题
目标检测是在给定的图片中精确找到物体所在位置,并标注出物体的类别。物体的尺寸变化范围很大,摆放物体的角度,姿态不定,而且可以出现在图片的任何地方,并且物体还可以是多个类别。
- 目标检测问题发展
- R-CNN
- SPP NET
- Fast R-CNN
- Faster R-CNN
- 最终实现YOLO
YOLO是一个集大成的方法,不了解之前的方法,很难掌握
YOLO
的思路。















 96
96

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









