






第1讲 神经网络初体验
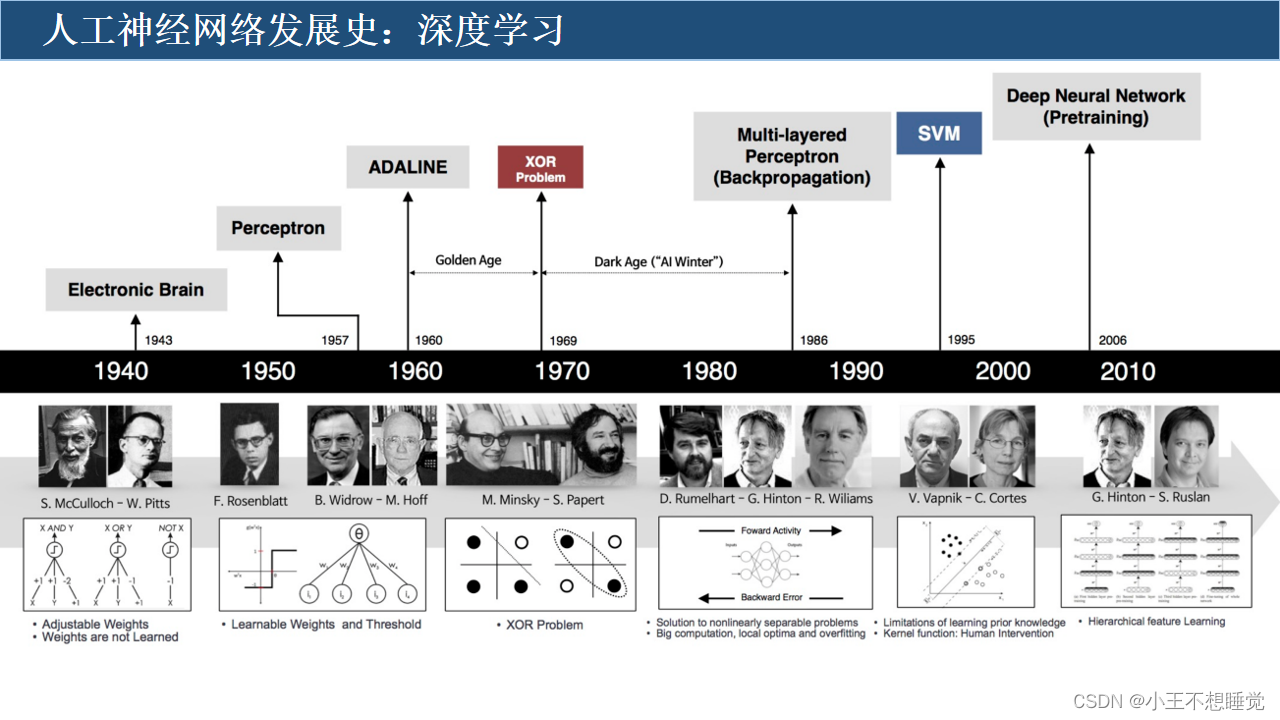
人工神经网络发展史
人工智能、机器学习、深度学习之间的关系: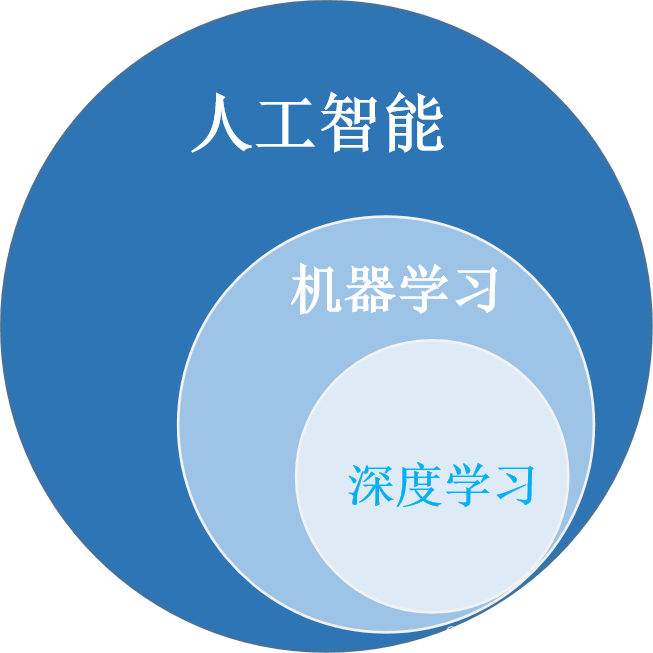
- 人工智能(Artificial Intelligence):计算机科学的一个分支。模拟、延伸和扩展人的智能的理论、方法、技术及应用系统。
- 机器学习(Machine Learning):一种实现人工智能的方法。研究计算机怎样模拟或实现人类的学习行为。
- 深度学习(Deep Learning):一种实现机器学习的技术。学习样本数据的内在规律和表示层次。
人工神经网络发展史:
- 萌芽期:19世纪,学习的实质是不断的形成刺激-反应的过程。
- 孕育期:1943年,提出了人工神经网络的概念及人工神经元的数学模型(M-P模型);神经元学习法则,赫布型学习,被认为是一种典型的无监督学习规则;感知机模型(Perceptron),二元分类器,被指为单层的人工神经网络。
- 寒冬:1969年,感知机的两大缺陷:其一,无法处理异或问题;其二,当时计算机的计算能力不足以处理大型神经网络。
- 误差反向传播算法:
- 1974:首次提出用误差反向传导(BackPropagation Algorithm,简称BP)来训练人工神经网络,有效解决了异或回路问题。
- 1983:应用神经网络,在旅行商这个NP(Nondeterministic Polynomially)问题的求解上获得当时最好成绩。
- 1986:改进的反向传播算法引入多层感知器。
- LeNet-5模型:1998年,LeNet-5采用了基于梯度的反向传播算法对网络进行有监督的训练。LeNet5 网络虽然很小,但是包含了“深度学习”的基本模块:卷积层,池化层,全连接层。
- 春天:GPU、FPGA等器件被用于高性能计算,大数据的出现,神经网络成为人工智能领域最热门的研究方向。
- 深度学习:2006年,深度置信网络( Deep Belief Networks, DBN)使用一种贪心无监督训练方法来解决问题并取得良好结果。
常见的深度学习框架包括:TensorFlow、PyTorch、Caffe、MxNet、Keras、PaddlePaddle
神经网络结构基础
生物神经网络
- 人工神经网络的计算模型灵感正是来自生物神经网络:
每个神经元与其他神经元相连,兴奋时,向相邻的神经元发送化学物质,改变电位;电位超过了一个阈值,被激活(兴奋)向其他神经元发送化学物质。
- 人工神经网络通常呈现为按照一定的层次结构连接起来的“神经元”:
分布式并行,依赖于大量的输入和一般的未知近似函数,最大化的拟合现实中的实际数据,提高机器学习预测的精度。
激活函数的性质
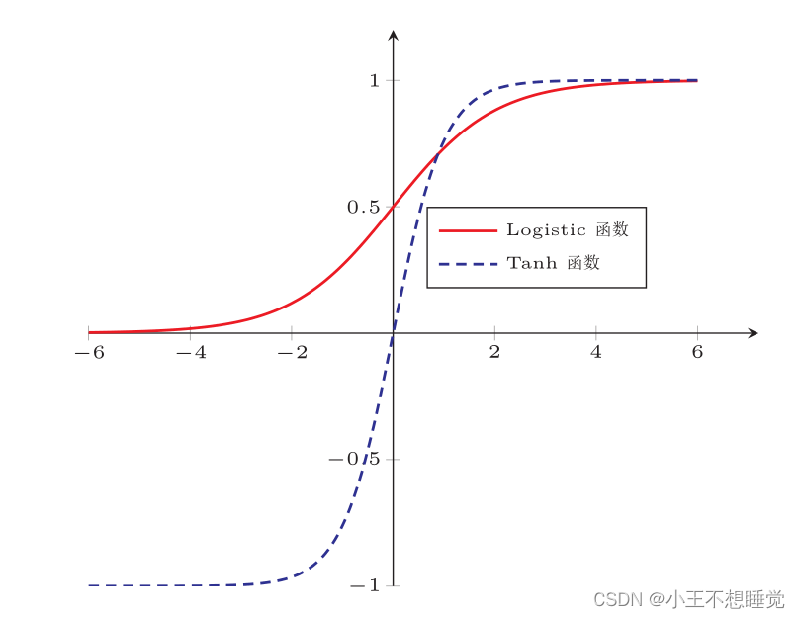
一般地,人工神经网络中的激活函数都选用非线性函数。原因如下:
- 假设网络中全部是线性部件,则线性的组合依旧是线性,与一个单独的线性分类器无异,这就达不到用非线性来逼近任意函数的目的。
- 使用非线性激活函数,以便使网络更加强大,增强其能力,使其可以学习复杂的对象和数据,并能表示输入/输出之间非线性的复杂的任意函数映射。即,使用非线性激活函数,能够从输入/输出之间生成非线性映射。
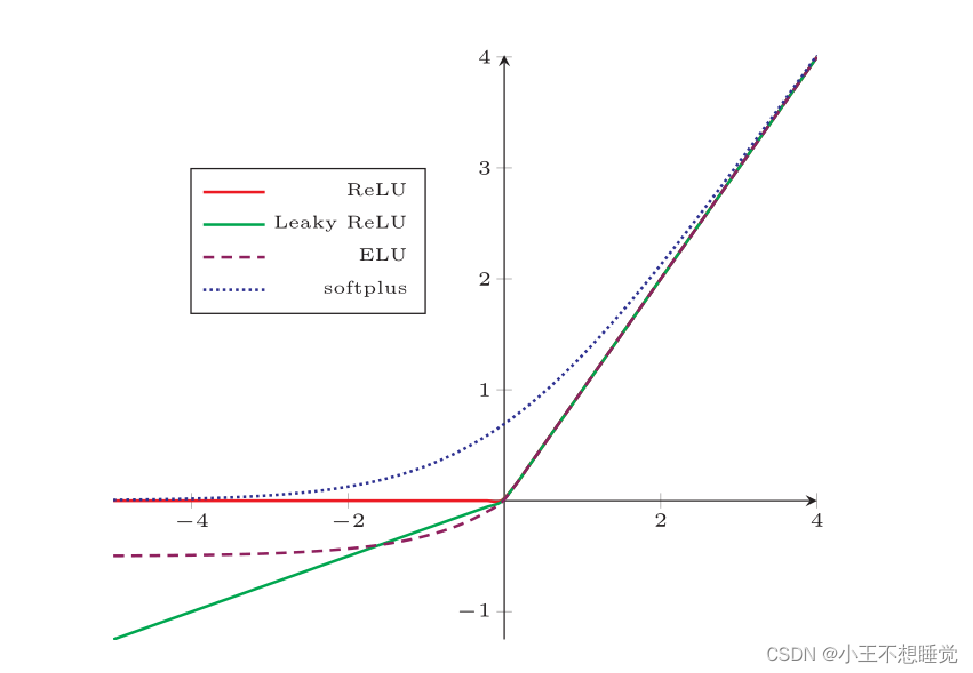
常见激活函数
![]()
![]()
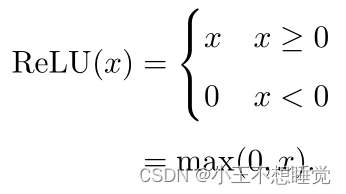
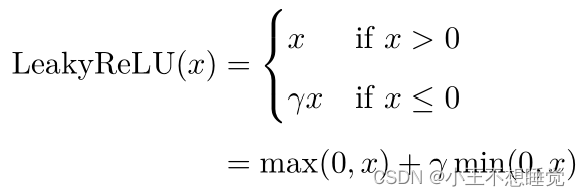
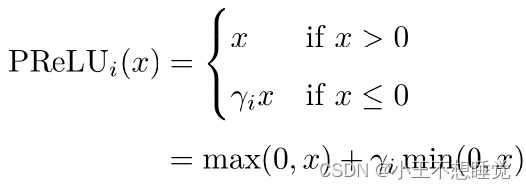
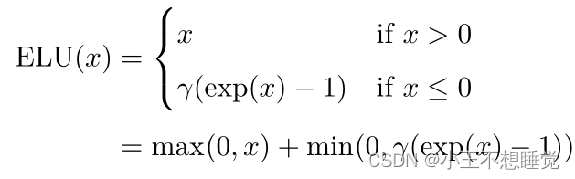
![]()
人工神经网络
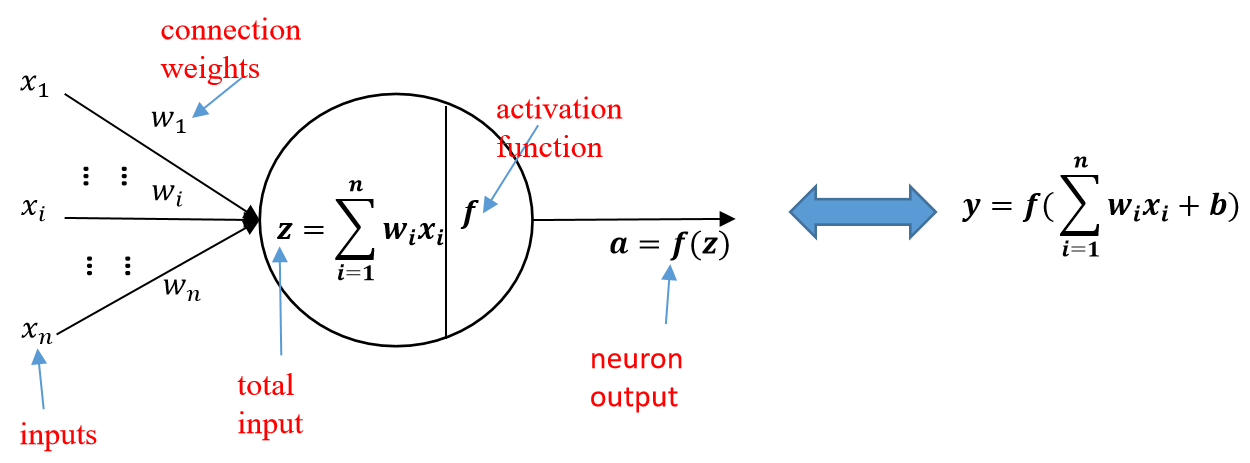
人工神经网络主要由大量的神经元以及它们之间的有向连接构成。
神经元的激活规则:主要是指神经元输入到输出之间的映射关系,一般为非线性函数。
- 网络的拓扑结构:不同神经元之间的连接关系。
- 学习算法:通过训练数据来学习神经网络的参数。
人工神经网络由神经元模型构成,这种由许多神经元组成的信息处理网络具有并行分布结构。
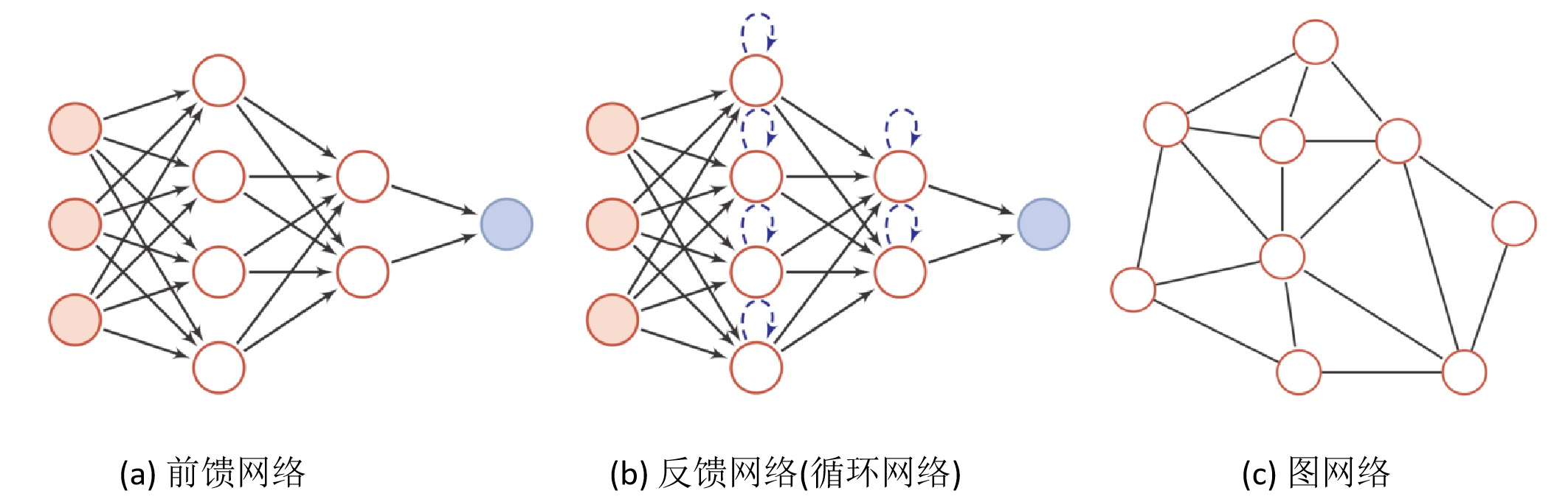
第2讲 前馈神经网络
网络结构
前馈神经网络(全连接神经网络、多层感知器)
各神经元分别属于不同的层,层内无连接。
- 相邻两层之间的神经元全部两两连接。
- 整个网络中无反馈,信号从输入层向输出层单向传播,可用一个有向无环图表示。
深度学习的三个步骤
定义网络——>损失函数——>优化
优化问题
难点:
- 参数过多,影响训练
- 非凸优化问题:即存在局部最优而非全局最优解,影响迭代
- 下层参数比较难调
- 参数解释起来比较困难
需求:
- 计算资源要大
- 数据要多
- 算法效率要好:即收敛快
第3讲 BP算法
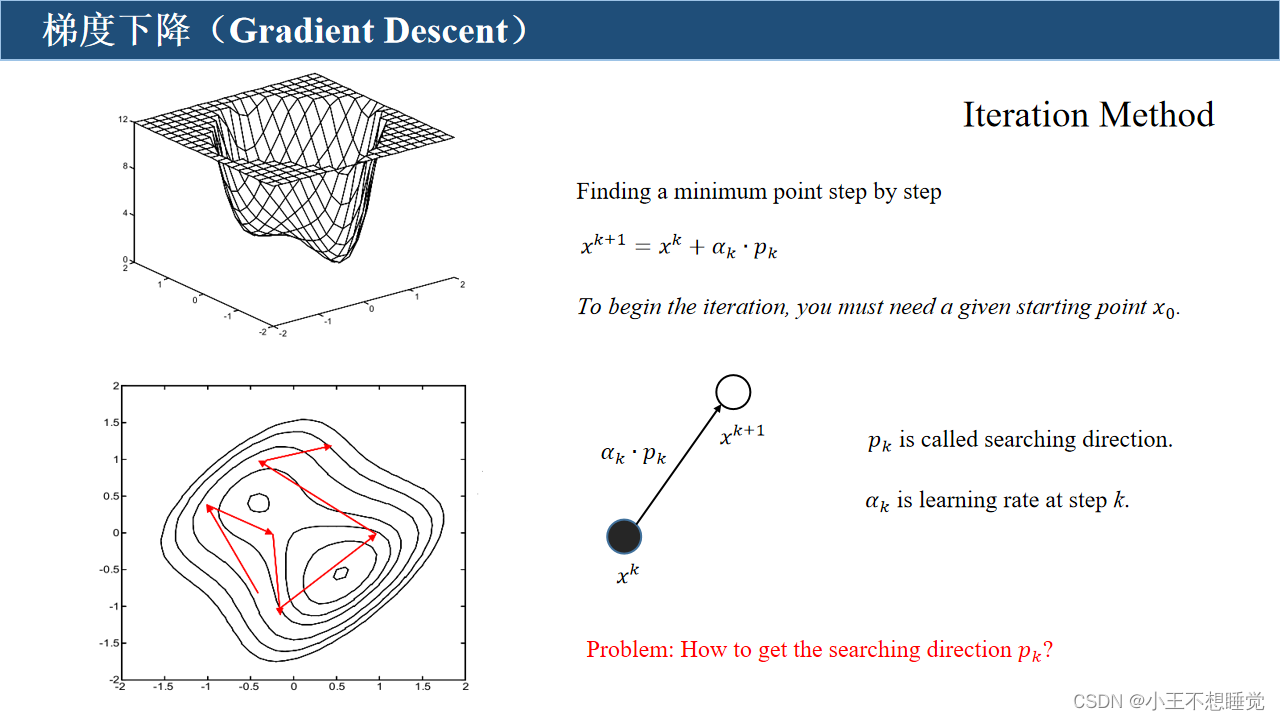
神经元(网络)的训练
训练的过程就是不断更新权重w和偏置b的过程,直到找到稳定的w和b使得模型的整体误差最小。

梯度下降(Gradient Descent)
第4讲 卷积神经网络
引入
卷积神经网络(Convolutional Neural Networks,CNN)是一种前馈神经网络。
- 卷积神经网络是受生物学上感受野(Receptive Field)的机制而提出的。
- 在视觉神经系统中,一个神经元的感受野是指视网膜上的特定区域,只有这个区域内的刺激才能够激活该神经元。
卷积神经网络有三个结构上的特性:
- 局部连接
- 权重共享
- 空间或时间上的次采样
卷积
卷积的运算过程
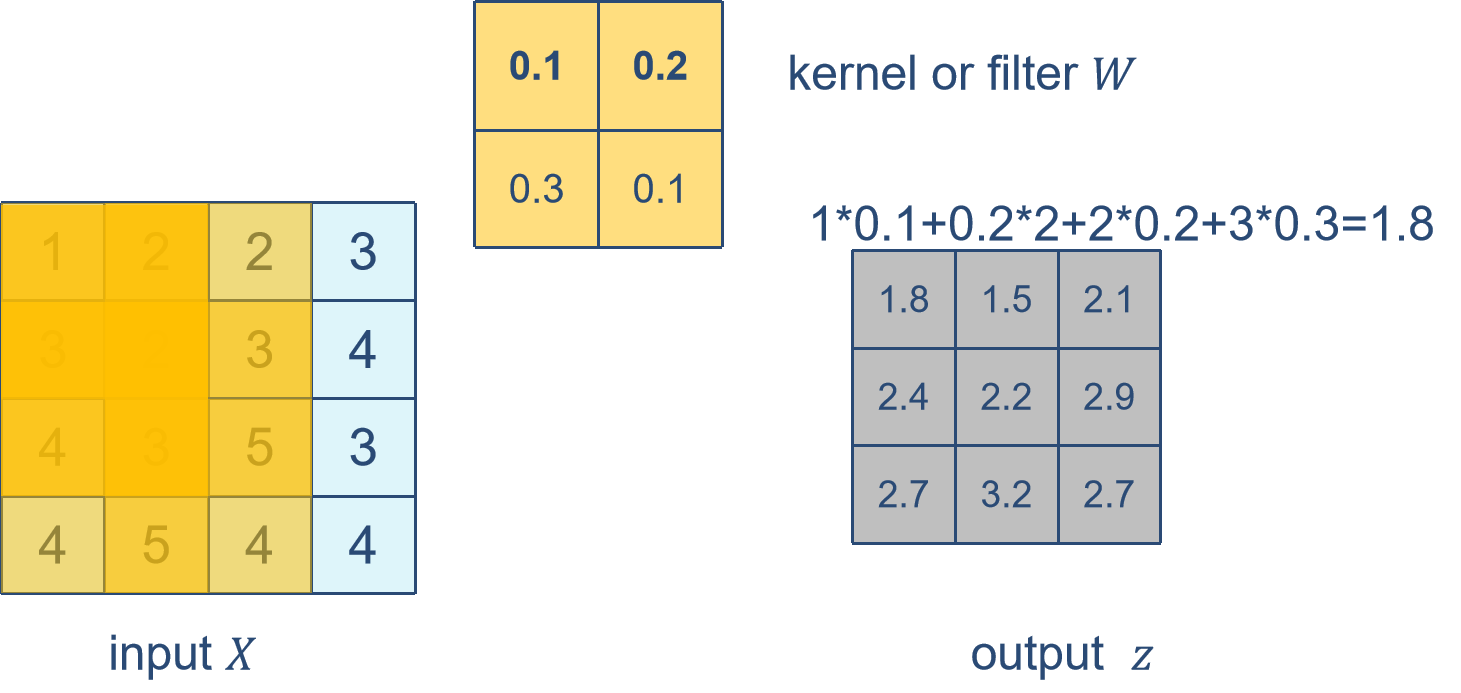
- 填充(padding):在输入矩阵的四周补零,称为padding,其大小为P。一般来说,如果在高的两侧一共填充ph行,在宽的两侧一共填充pw列,那么输出形状将会是:
- 步幅(stride):卷积窗口从输入数组的最左上方开始,按从左往右、从上往下的顺序,依次在输入数组上滑动。每次滑动的行数和列数称为步幅(stride)。一般来说,当高上步幅为sh,宽上步幅为sw时,输出形状为:
卷积神经网络的基本组成
池化层(Pooling Layer)
池化层也叫子采样层(Subsampling Layer),其作用是进行特征选择,降低特征数量,并从而减少参数数量。(例:卷积层每一个特征映射的神经元个数没有显著减少,后面接的分类器的输入维数依然很高,容易出现过拟合。在卷积层之后加上一个池化层,从而降低特征维数,避免过拟合。)
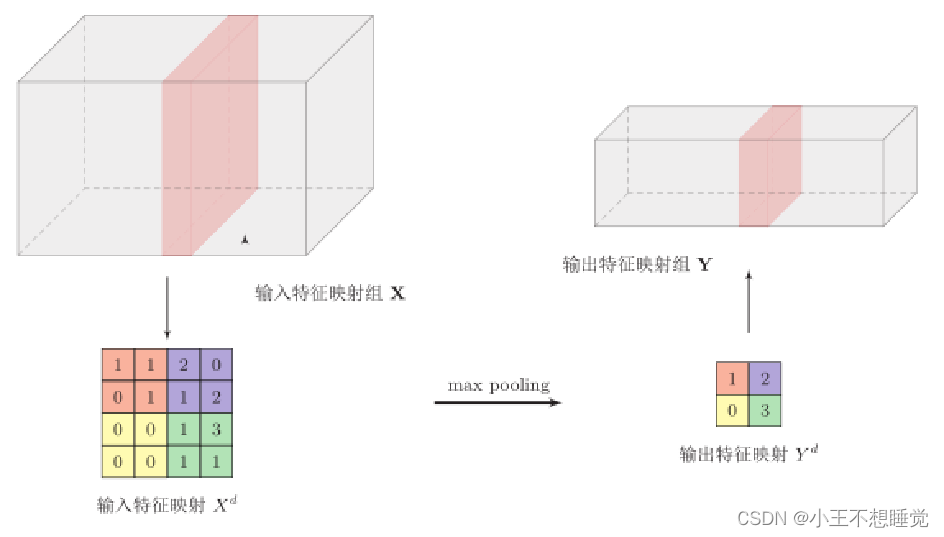
卷积网络结构
卷积网络是由卷积层、池化层、全连接层交叉堆叠而成。
- 趋向于小卷积、大深度
- 趋向于全卷积
典型结构:一个卷积块为连续M 个卷积层和b个池化层(M通常设置为2 ∼ 5,b为0或1)。一个卷积网络中可以堆叠N 个连续的卷积块,然后在接着K 个全连接层(N 的取值区间比较大,比如1 ∼ 100或者更大;K一般为0 ∼ 2)。
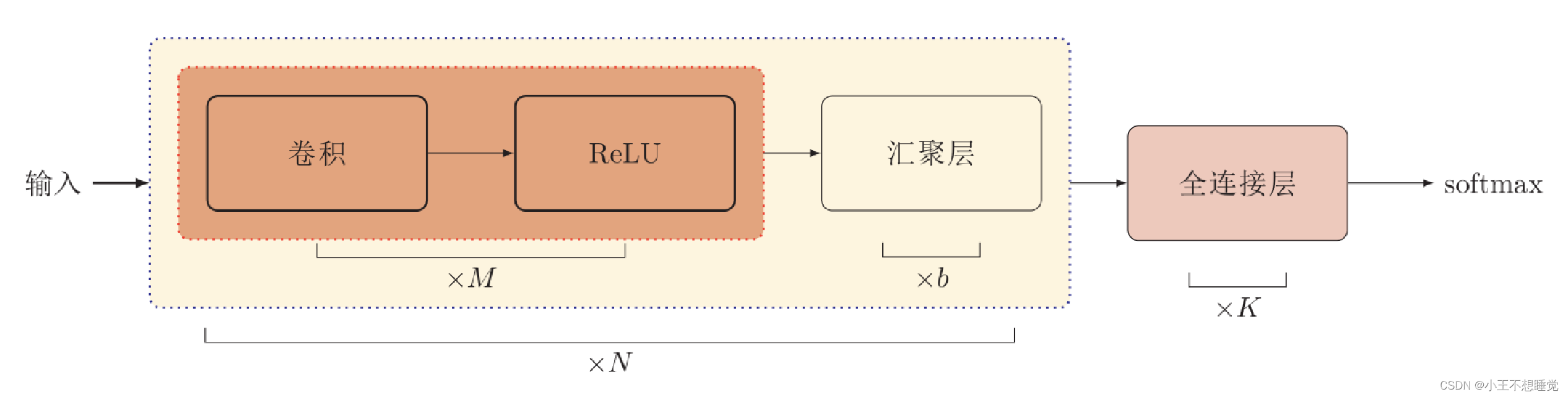
典型的卷积网络
CNN路线图
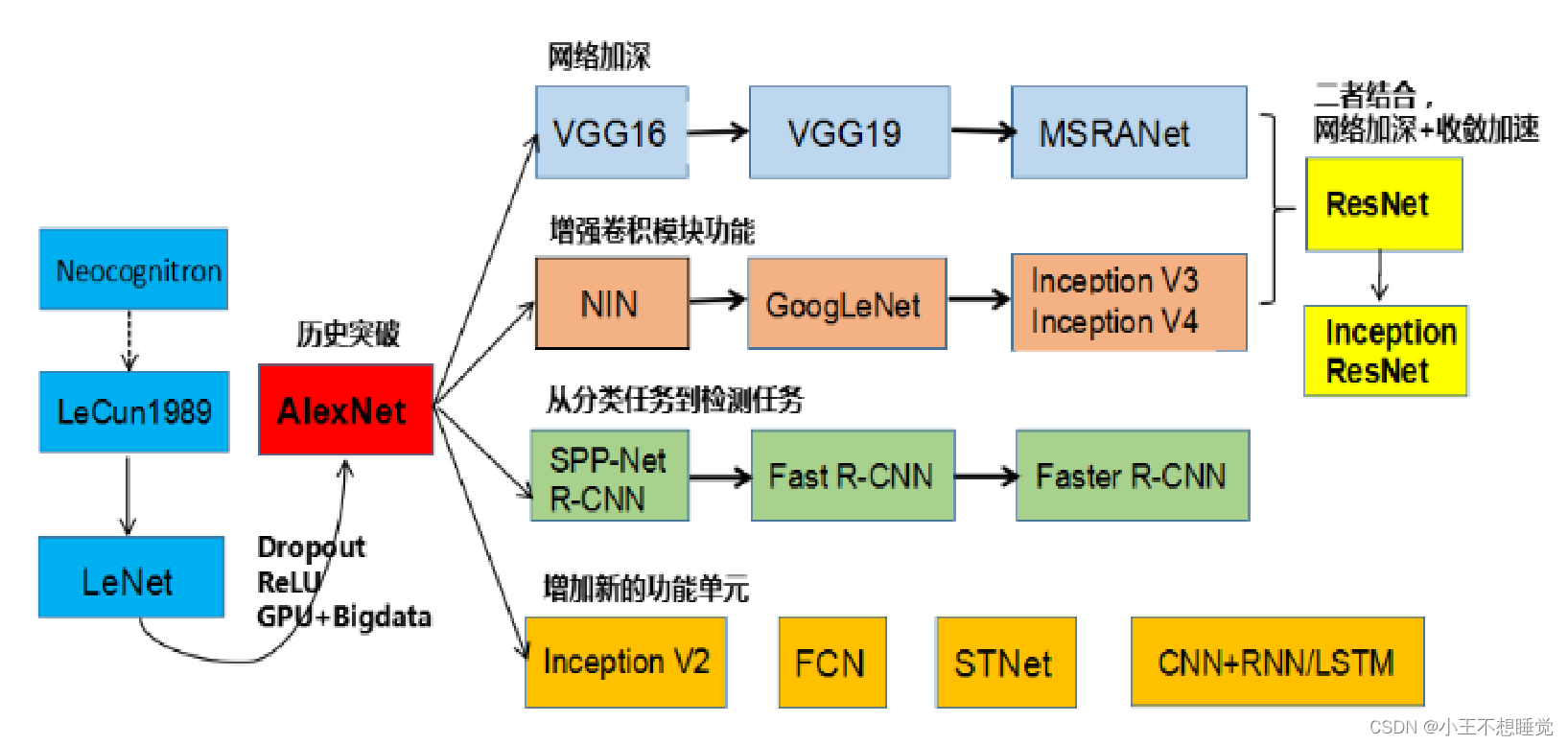
CNN的历史
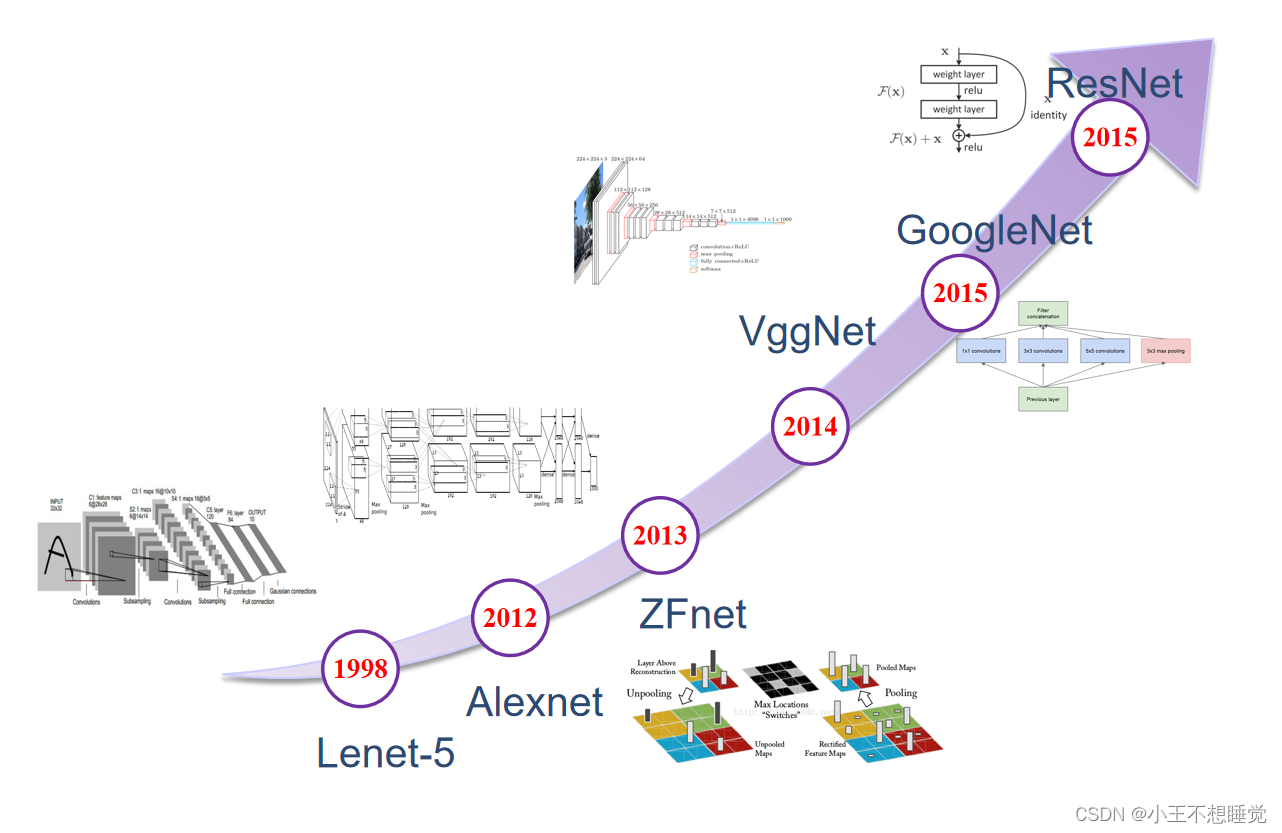
AlexNet
2012 ILSVRC winner
- (top 5 error of 16% compared to runner-up with 26% error)
- 第一个现代深度卷积网络模型,首次使用了很多现代深度卷积网络的一些技术方法,(比如使用GPU进行并行训练,采用了ReLU作为非线性激活函数,使用Dropout防止过拟合,使用数据增强)
- 共有8层,其中前5层卷积层,后边3层全连接层
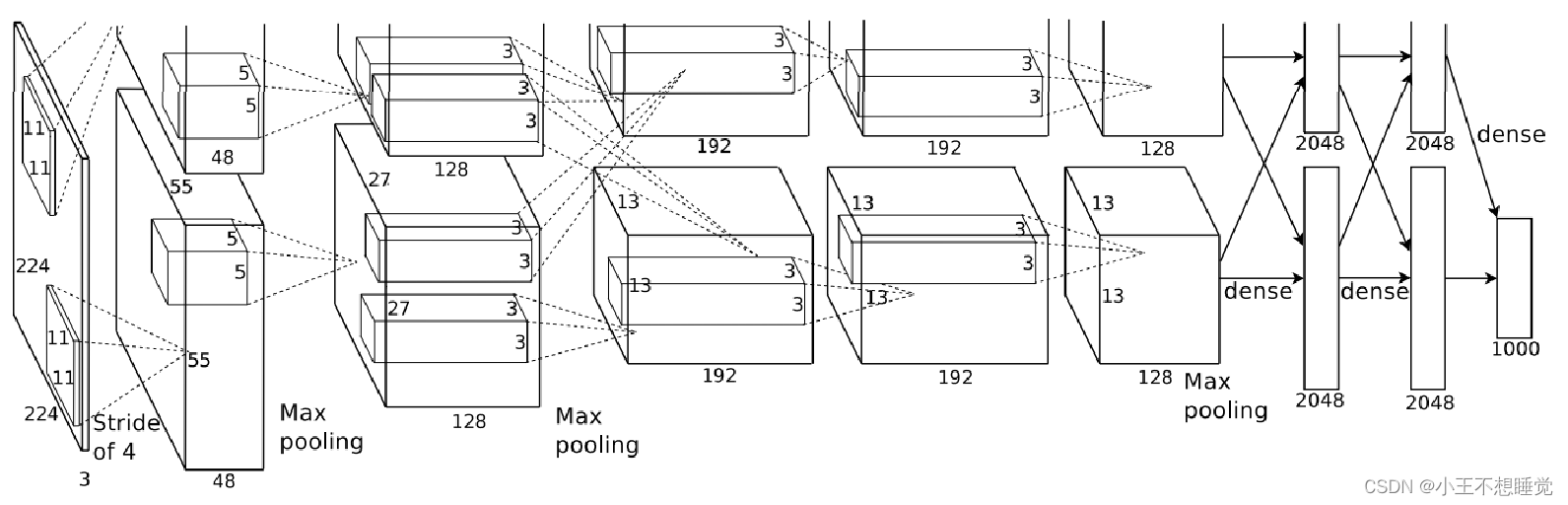
VGG
VGG耗费更多计算资源,并且使用了更多的参数(这里不是3×3卷积的锅),导致更多的内存占用。其中绝大多数的参数都是来自于第一个全连接层,VGG可是有3个全连接层。
- VGGNet的结构非常简洁,整个网络都使用了同样大小的卷积核尺寸(3×3)和最大池化尺寸(2×2)
- 几个小滤波器(3×3)卷积层的组合比一个大滤波器(5×5或7×7)卷积层好
- 验证了通过不断加深网络结构可以提升性能
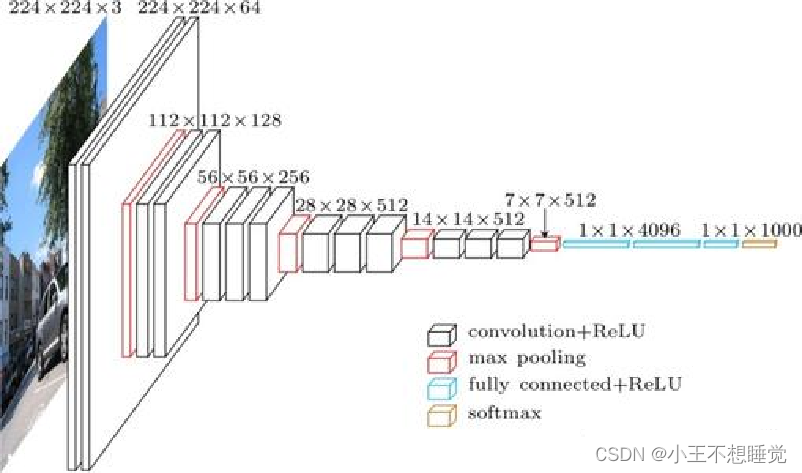
Inception网络
2014 ILSVRC winner (22层)
- 参数:GoogLeNet:4M VS AlexNet:60M
- 错误率:6.7%
- Inception网络是由有多个inception模块和少量的池化层堆叠而成。
残差网络
- 残差网络(Residual Network,ResNet)是通过给非线性的卷积层增加直连边的方式来提高信息的传播效率。
- 假设在一个深度网络中,期望一个非线性单元(可以为一层或多层的卷积层)f(x,θ)去逼近一个目标函数为h(x)。
- 将目标函数拆分成两部分:恒等函数和残差函数

第5讲 循环神经网络
意义
循环神经网络(Recurrent Neural Network, RNN)是一类以序列(sequence)数据为输入,在序列的演进方向进行递归(recursion)且所有节点(循环单元)按链式连接的递归神经网络(recursive neural network)
前馈网络的一些不足
- 连接存在层与层之间,每层的节点之间是无连接的。(无循环)
- 输入和输出的维数都是固定的,不能任意改变。无法处理变长的序列数据。
- 假设每次输入都是独立的,也就是说每次网络的输出只依赖于当前的输入。(例如,在NLP中,词汇节点位置无关,无法对语言中的词序进行建模。)
循环神经网络
- 循环神经网络通过使用带自反馈的神经元,能够处理任意长度的序列。
- 循环神经网络比前馈神经网络更加符合生物神经网络的结构。
- 循环神经网络已经被广泛应用在语音识别、语言模型以及自然语言生成等任务上。
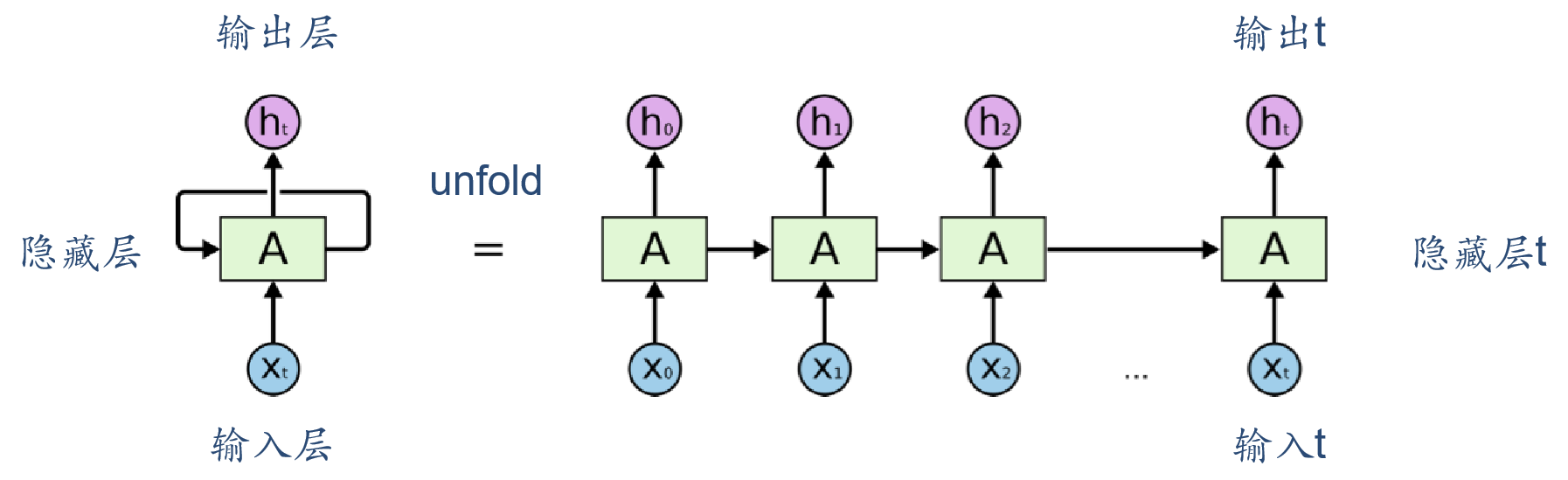
应用类别
- 输入-输出映射(机器学习)
- 存储
- 类别到序列(1到N,eg.作诗)
- 序列到类别(多对1,eg.电影评论)
- 同步的序列到序列(同步的多到多,N到N,eg.语音识别)
- 异步的序列到序列(N到M,序列长度不对等N!=M,eg.机器翻译)
循环神经网络的参数学习
长期依赖 (Long-Term Dependencies) 问题
- 很久以前的输入,对当前时刻的网络影响较小,反向传播的梯度也很难影响很久以前的输入。输出的根据离输出时刻太远,可能会造成梯度消失/梯度爆炸,只能学习到短期的依赖关系。
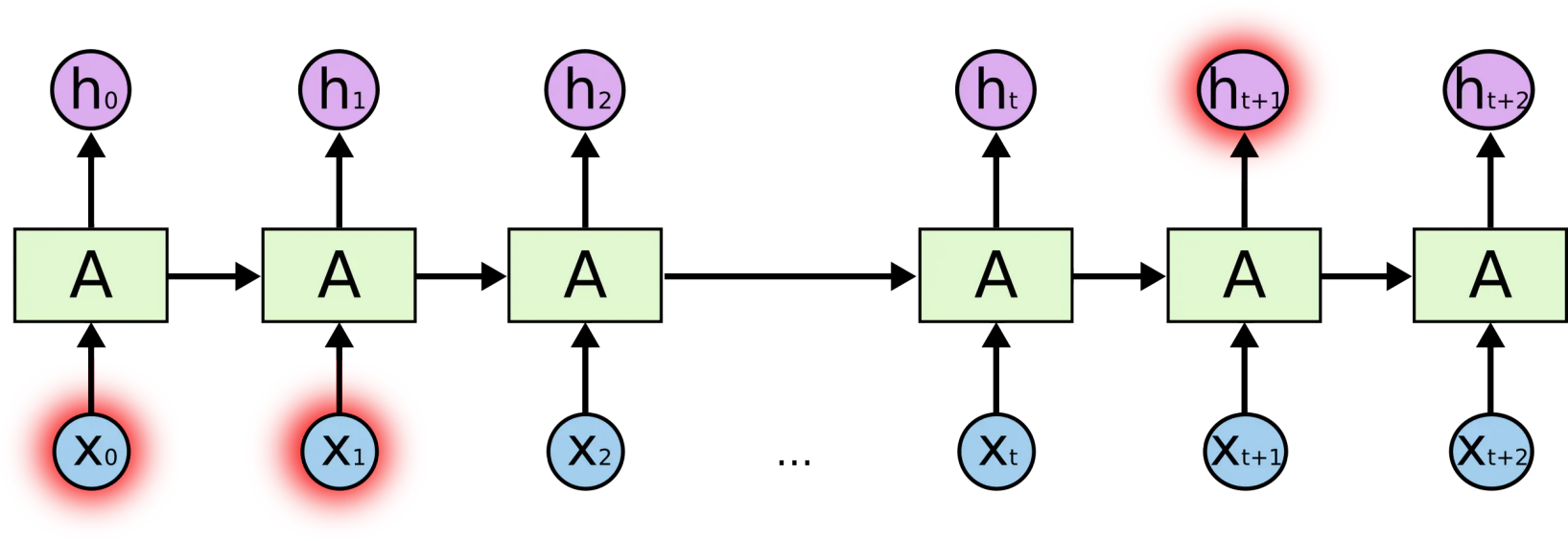
循环神经网络在时间维度上非常深! ——> 梯度消失或梯度爆炸
改进:
- 梯度爆炸问题
- 权重衰减:通过给参数增加L1或L2范数的正则化项来限制参数的取值范围。
- 梯度截断:当梯度的模大于一定阈值时,就将它截断成为一个较小的数。
- 梯度消失问题
- 改进模型
改进模型
- 循环边改为线性依赖关系:
- 增加非线性:
记忆容量饱和——>gate门控机制:把信息想象成水流,而gate就是控制水流可以通过。
深层循环神经网络
双向循环神经网络
双向循环神经网络(bidirectional recurrent neural network,Bi-RNN)由两层循环神经网络组成,它们的输入相同,只是信息传递的方向不同。
- 在有些任务中,一个时刻的输出不但和过去时刻的信息有关,也和后续时刻的信息有关。比如给定一个句子,其中一个词的词性由它的上下文决定,即 包含左右两边的信息。因此,在这些任务中,我们可以增加一个按照时间的逆序来传递信息的网络层,来增强网络的能力。
- 假设第 1 层按时间顺序,第 2 层按时间逆序,在时刻 t 时的隐状态定义为
和
,则
其中 ⊕为向量拼接操作。

eg.我今天不舒服,我打算____一天。
只根据‘不舒服‘,可能推出我打算‘去医院‘,‘睡觉‘,‘请假‘等等,但如果加上后面的‘一天‘,能选择的范围就变小了,‘去医院‘这种就不能选了,而‘请假‘‘休息‘之类的被选择概率就会更大。
- 在Forward层从0时刻到i时刻正向计算一遍,得到并保存每个时刻向前隐含层的输出;
- 在Backward层从i时刻到0时刻反向计算一遍,得到并保存每个时刻向后隐含层的输出;
- 最后在每个时刻结合Forward层和Backward层的相应时刻输出的结果得到最终的输出。
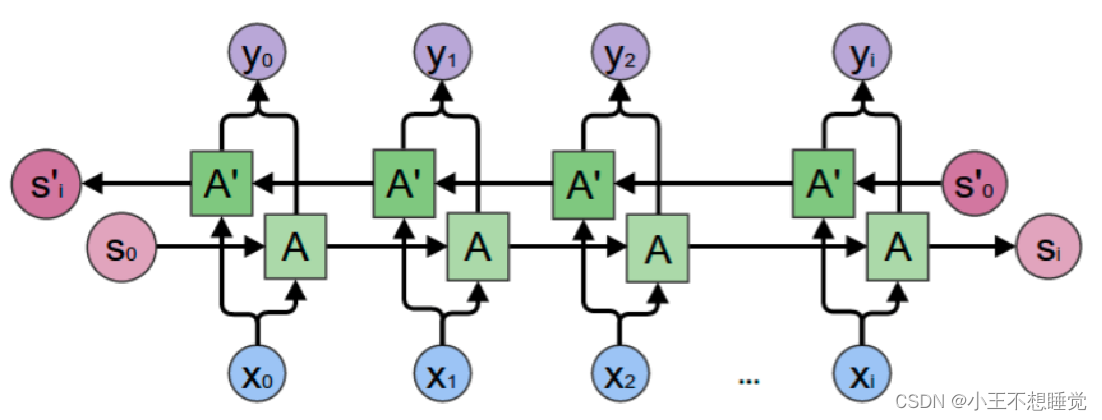
深度学习进阶
深度生成模型
深度生成模型:利用深层神经网络可以近似任意函数的能力来建模一个复杂的分布p_r(x) 。假设一个随机向量z服从一个简单的分布p(z), z∈Z(如标准正态分布),我们使用一个深层神经网络g:Z→χ,并使得g(z)服从p_r(x) 。

自编码器Auto-Encoder (AE)
- 自编码器是神经网络的一种,经过训练后能尝试将输入复制到输出。
- 搭建自编码器需要三步:
- 编码器 Encoder
- 解码器 Decoder
- 设定损失函数 Loss function
- 通过最小化损失函数来优化参数。
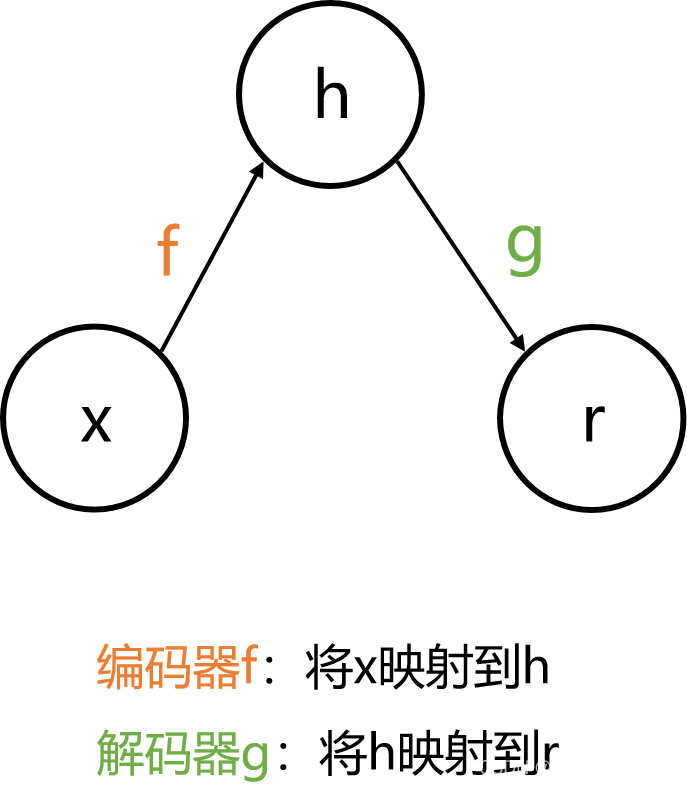
变分自编码器Variational Autoencoder (VAE)
- 变分自编码器,是一种深度生成模型,其思想是利用神经网络来分别建模两个复杂的条件概率密度函数。
- 推断网络
- 生成网络
- 生成模型的难题就是判断生成分布与真实分布的相似度,因为我们只知道两者的采样结果,不知道它们的分布表达式。
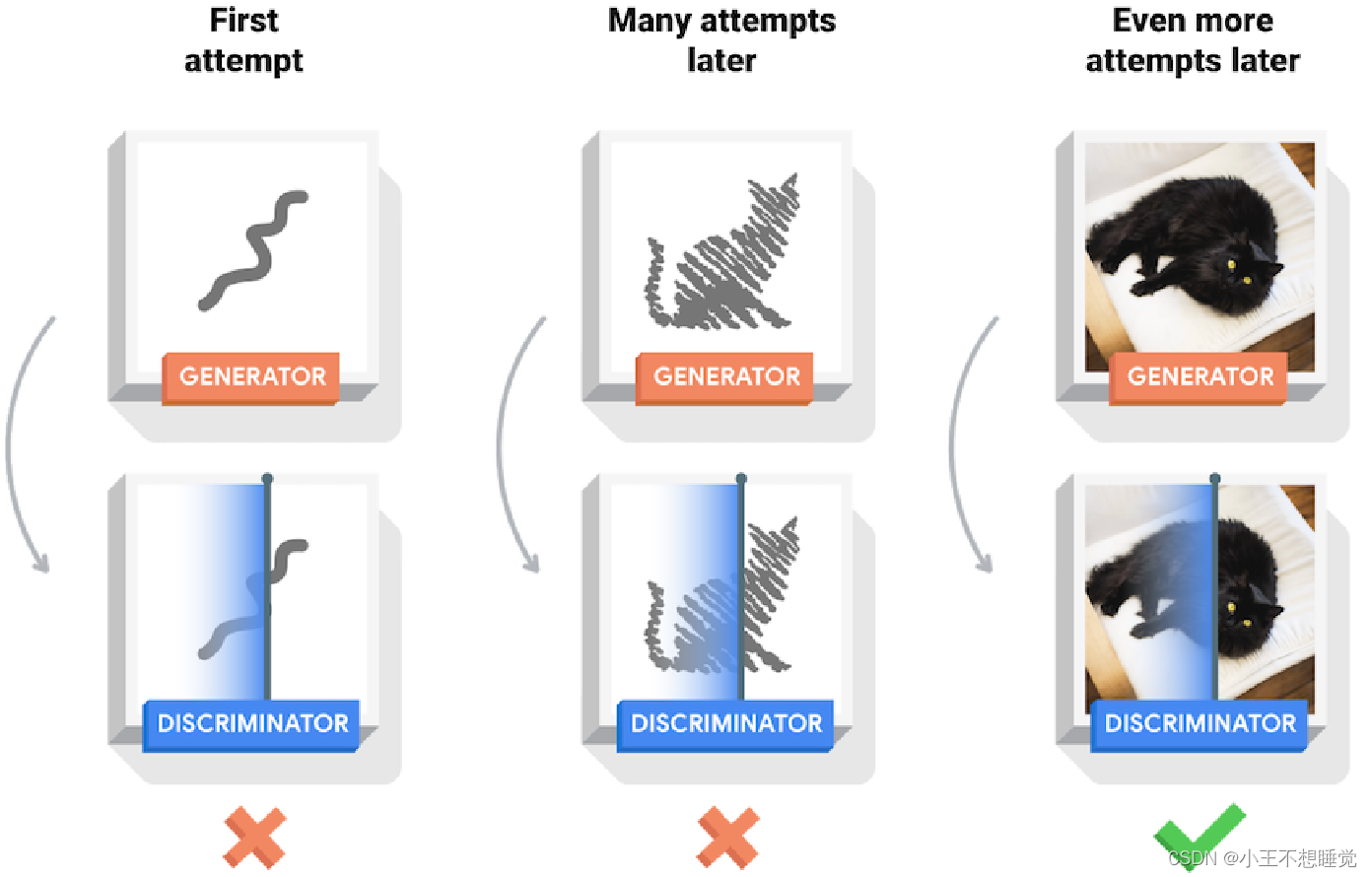
生成对抗网络Generative Adversarial Network (GAN)
生成对抗网络,由Ian J. Goodfello 等人于2014年在Generative Adversarial Nets 论文中提出。在GAN网络中,有两个模型——生成模型(generative model G)和判别模型(discriminative model D)。
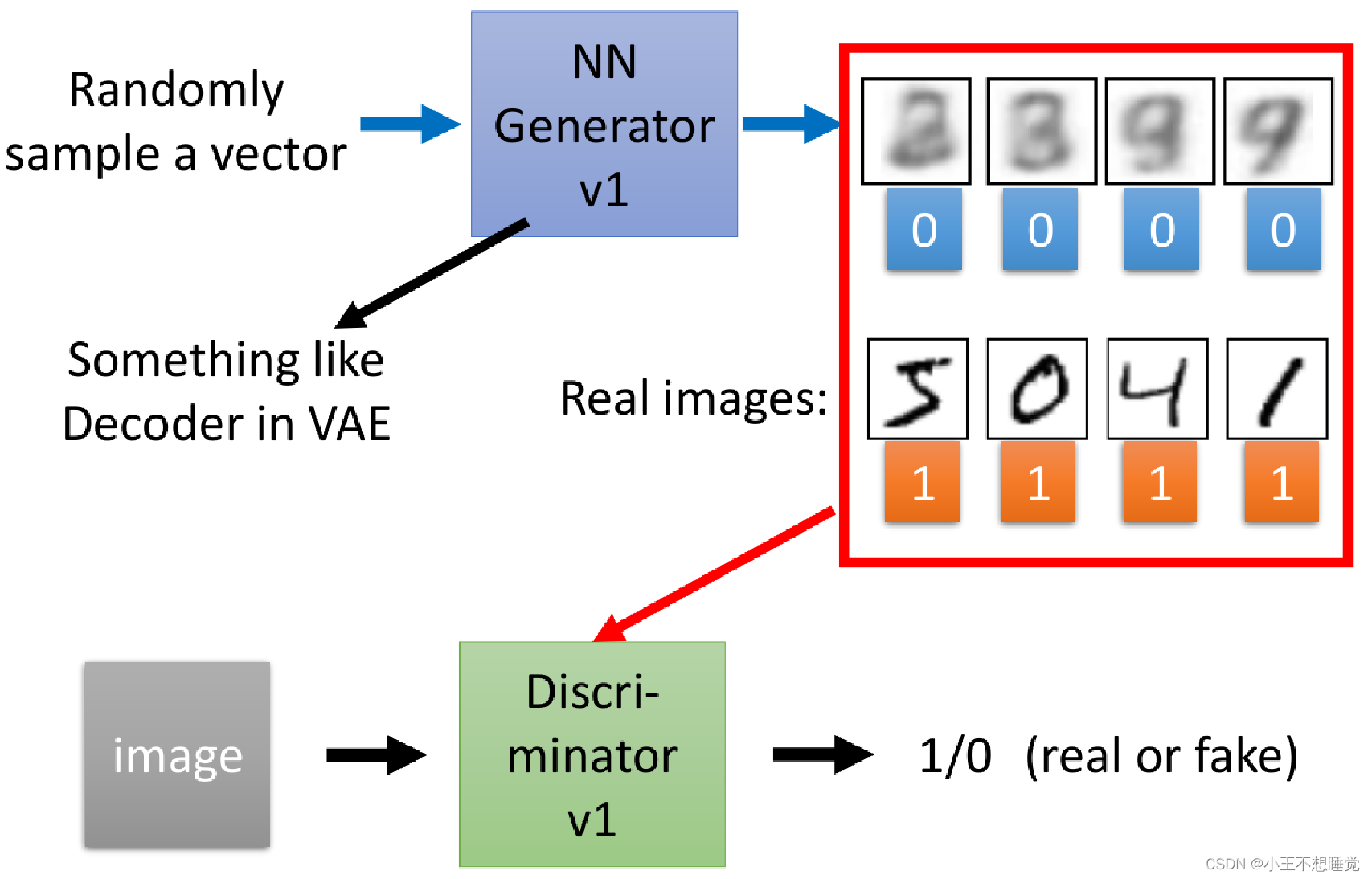
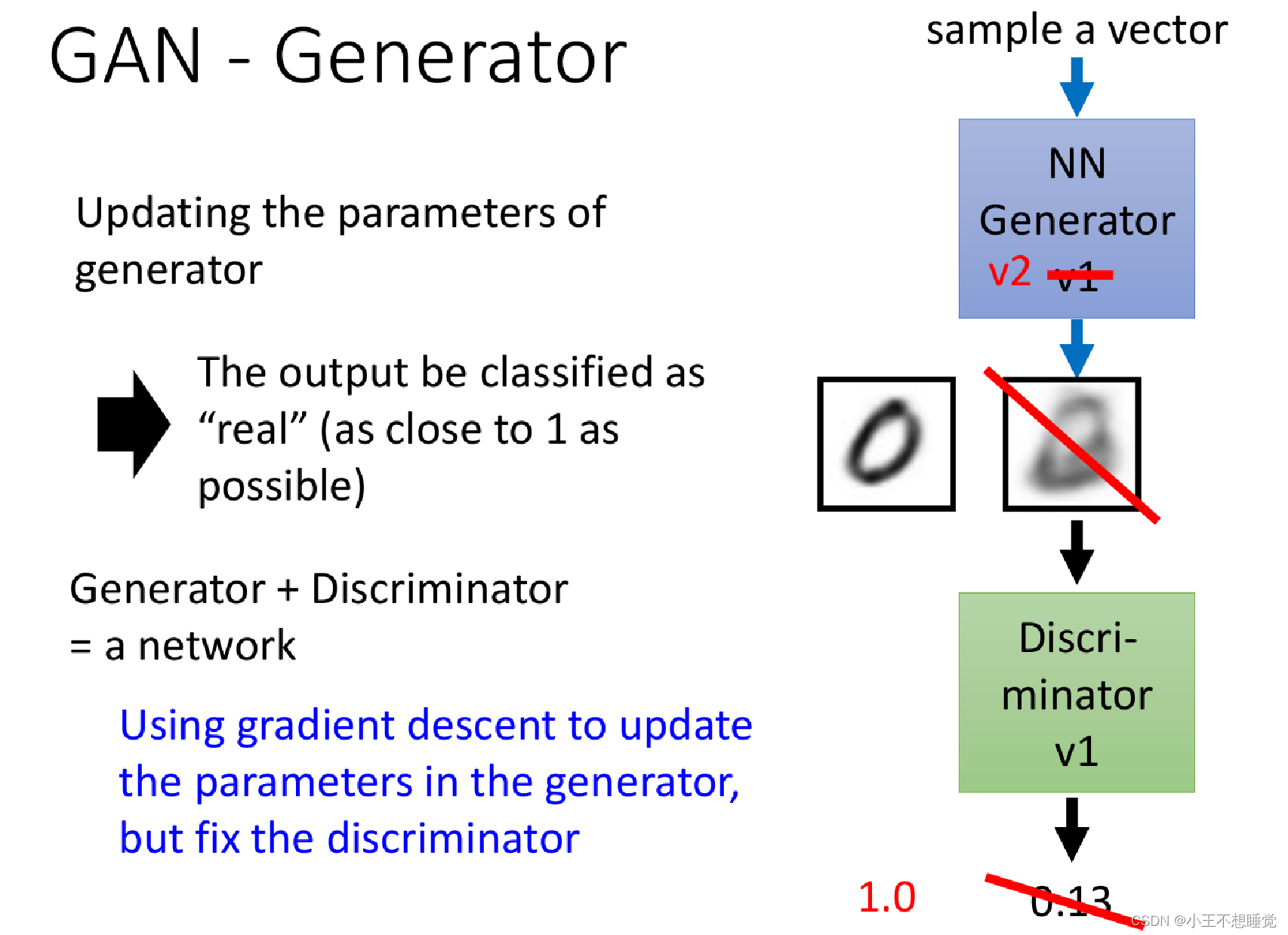
- 生成模型G:接受一个随机的噪声𝑧,通过噪声𝑧生成图片记做𝐺(𝑧)。G的目标就是生成假的图片去骗过判别网络D。
- 判别模型D:判别一张图片是“real”或“ fake”。输入𝑥代表一张图片,输出𝐷(𝑥)代表𝑥为真实图片的概率,如果为1,代表是真实的图片,而输出为0,则代表不是真实的图片。
鉴别器(Discriminator):
生成器(Generator):
深度强化模型
强化学习(Reinforcement Learning, LR)简介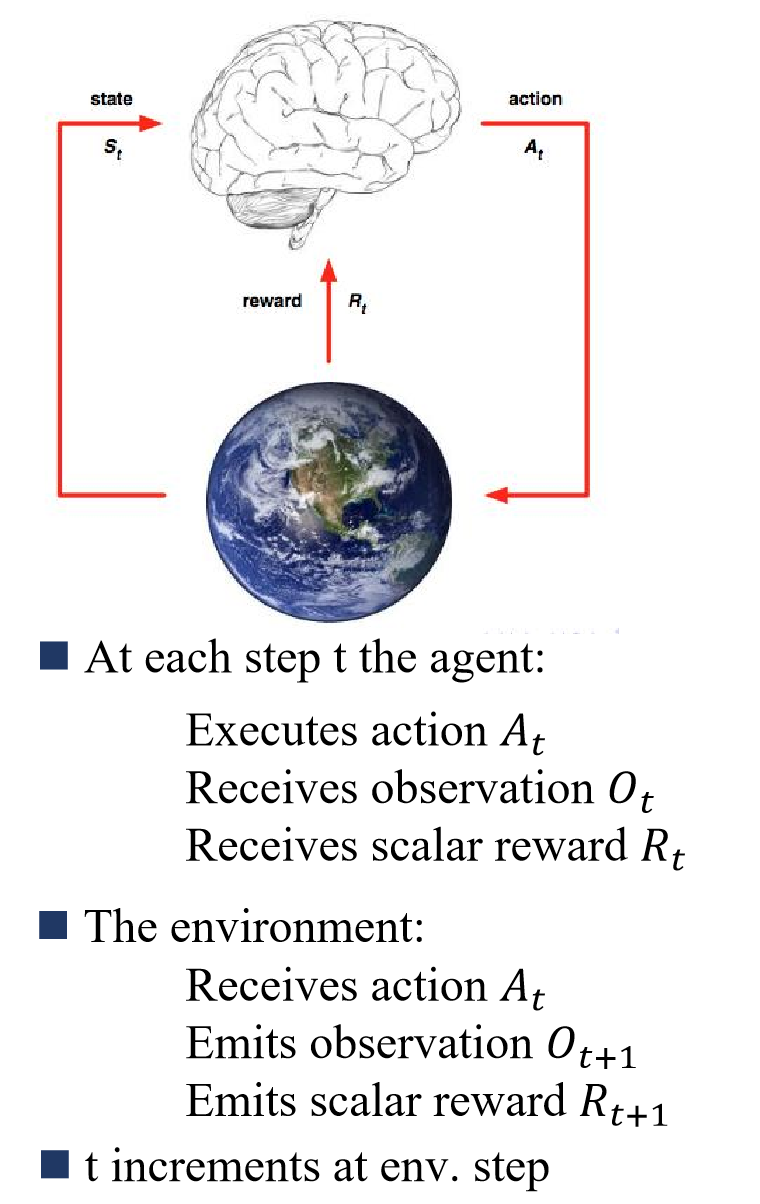
强化学习决策实现过程需要设定一个agent(图中大脑部分),agent能够接收当前环境的一个observation,agent还能接收当它执行某个action后的reward,而环境(environment)则是agent交互的对象,它是一个行为可控的对象,agent一开始不知道环境会对不同的action做出什么样的反应,而环境会通过observation告诉agent当前的环境状态,同时环境能够根据可能的最终结果反馈给agent一个reward,它表明了agent做出的决策有多好或者不好,整个强化学习优化的目标就是最大化积累reward。
强化学习的三个重要特点:
- 基本是以一种闭环的形式;
- 不会直接指示选择哪种行动(actions);
- 一系列的actions和奖励信号(reward signals)都会影响之后较长的时间。
迁移学习
概念
迁移学习(Transfer Learning)是一种机器学习方法,就是把为任务 A 开发的模型作为初始点,重新使用在为任务 B 开发模型的过程中。找到目标问题的相似性,迁移学习任务就是从相似性出发,将旧领域(domain)学习过的模型应用在新领域上。。例如,我们可能会发现学习识别苹果可能有助于识别梨,或者学习弹奏电子琴可能有助于学习钢琴。
基本定义
- 域(Domain):数据特征和特征分布组成,是学习的主体
- 源域 (Source domain):已有知识的域
- 目标域 (Target domain):要进行学习的域
- 任务 (Task):由目标函数和学习结果组成,是学习的结果
类别
- 按特征空间分类
- 同构迁移学习(Homogeneous TL): 源域和目标域的特征空间相同,转存失败重新上传取消 Dₛ = Dₜ
- 异构迁移学习(Heterogeneous TL):源域和目标域的特征空间不同,转存失败重新上传取消 Dₛ != Dₜ
- 按迁移情景分类
- 归纳式迁移学习(Inductive TL):源域和目标域的学习任务不同
- 直推式迁移学习(Transductive TL):源域和目标域不同,学习任务相同
- 无监督迁移学习(Unsupervised TL):源域和目标域均没有标签
- 按迁移方法分类
- 基于样本的迁移 (Instance based TL):通过权重重用源域和目标域的样例进行迁移 基于样本的迁移学习方法 (Instance based Transfer Learning) 根据一定的权重生成规则,对数据样本进行重用,来进行迁移学习。下图形象地表示了基于样本迁移方法的思想源域中存在不同种类的动物,如狗、鸟、猫等,目标域只有狗这一种类别。在迁移时,为了最大限度地和目标域相似,我们可以人为地提高源域中属于狗这个类别的样本权重。
- 基于特征的迁移 (Feature based TL):将源域和目标域的特征变换到相同空间 基于特征的迁移方法 (Feature based Transfer Learning) 是指将通过特征变换的方式互相迁移,来减少源域和目标域之间的差距;或者将源域和目标域的数据特征变换到统一特征空间中,然后利用传统的机器学习方法进行分类识别。根据特征的同构和异构性,又可以分为同构和异构迁移学习。下图很形象地表示了两种基于特 征的迁移学习方法。
- 基于模型的迁移 (Parameter based TL):利用源域和目标域的参数共享模型 基于模型的迁移方法 (Parameter/Model based Transfer Learning) 是指从源域和目标域中找到他们之间共享的参数信息,以实现迁移的方法。这种迁移方式要求的假设条件是: 源域中的数据与目标域中的数据可以共享一些模型的参数。下图形象地表示了基于模型的迁移学习方法的基本思想。
- 基于关系的迁移 (Relation based TL):利用源域中的逻辑网络关系进行迁移 基于关系的迁移学习方法 (Relation Based Transfer Learning) 与上述三种方法具有截然不同的思路。这种方法比较关注源域和目标域的样本之间的关系。下图形象地表示了不 同领域之间相似的关系。
关键点
将某个领域或任务上学习到的知识或模式应用到不同但相关的领域或问题中。
- 用什么迁移(What to transfer)
- 如何进行迁移(How to transfer)——>归纳式迁移学习、直推式迁移学习、无监督迁移学习
- 何时进行迁移(When to transfer)
桥梁是什么?——>假设领域间具有公共知识结构
方法
- 功能捕捉(Feature Extraction)
- 参数迁移(Parameter Transfer)
- 知识迁移(Knowledge Transfer)
下图为深度迁移学习方法与非深度迁移学习方法的结果对比,展示了近几年的一些代表性方法在相同数据集上的表现。从图中的结果可以看出,与传统的非深度迁移学习方法(TCA、GFK等)相比,深度迁移学习方法(BA、DDC、DAN)在精度上具有显著的优势。

Q: 迁移学习与传统的多任务学习有什么区别?
A: 迁移学习和多任务学习都涉及到多个任务之间的学习,但它们的目标和方法有所不同。迁移学习的目标是在源任务上训练一个模型,然后将其应用于目标任务,以提高目标任务的性能。而多任务学习的目标是同时训练多个任务的模型,以提高整体性能。多任务学习通常需要共享的参数,而迁移学习则通常需要单独训练的模型。
Q: 迁移学习与传统的深度学习有什么区别?
A: 迁移学习是一种特殊的深度学习方法,它涉及到在已经训练好的模型上进行微调以解决新的任务。传统的深度学习方法通常需要从头开始训练模型,而迁移学习可以利用已有的知识来加速训练过程。迁移学习的主要优势在于它可以在有限的数据集上实现较高的性能,从而减少训练数据的需求。
Q: 迁移学习是否只适用于图像和语音等特定领域?
A: 迁移学习不仅适用于图像和语音等特定领域,还可以应用于其他领域,如文本分类、推荐系统、生物信息学等。迁移学习的主要优势在于它可以在有限的数据集上实现较高的性能,从而减少训练数据的需求。因此,迁移学习在各个领域都有广泛的应用前景。
深度学习应用
深度学习在计算机视觉中的应用(Computer Vision,CV)
目标检测(Object Detection)
目标检测中的核心问题:
- 分类问题:即图片(或某个区域)中的图像属于哪个类别。
- 定位问题:目标可能出现在图像的任何位置。
- 大小问题:目标有各种不同的大小。
- 形状问题:目标可能有各种不同的形状。
基于深度学习的目标检测算法主要分为两类:Two stage 和 One stage。
语义分割
语义分割模型——全卷积神经网络 FCN
FCN 所追求的是,输入是一张图片是,输出也是一张图片,学习像素到像素的映射,端到端的映射。
全卷积神经网络主要使用了三种技术:
- 卷积化(Convolutional):卷积化即是将普通的分类网络,比如VGG16,ResNet50/101等网络丢弃全连接层,换上对应的卷积层即可。
- 上采样(Upsample):
普通的池化会缩小图片的尺寸,为了得到和原图等大的分割图,我们需要上采样/反卷积。反卷积和卷积类似,都是相乘相加的运算。只不过后者是多对一,前者是一对多。而反卷积的前向和后向传播,只用颠倒卷积的前后向传播即可。
- 跳跃结构(Skip Layer):这个结构的作用就在于优化结果,因为如果将全卷积之后的结果直接上采样得到的结果是很粗糙的,所以作者将不同池化层的结果进行上采样之后来优化输出。
自然语言处理 (Natural Language Processing, NLP)
深度学习在自然语言处理领域的应用
自动文摘 文本分类
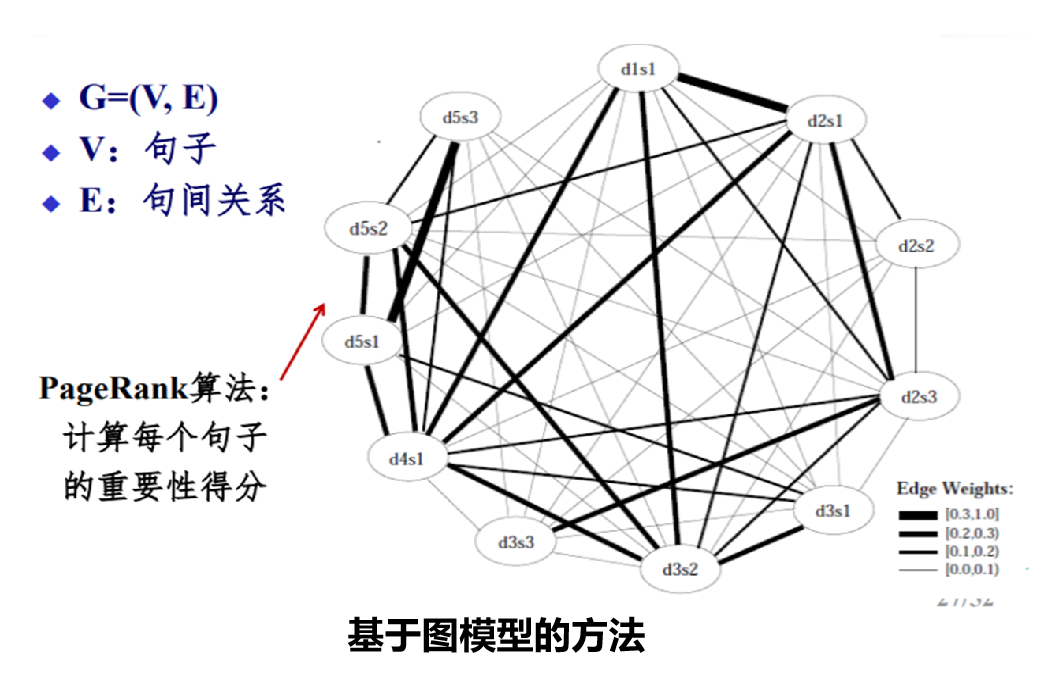

自动问答 机器翻译
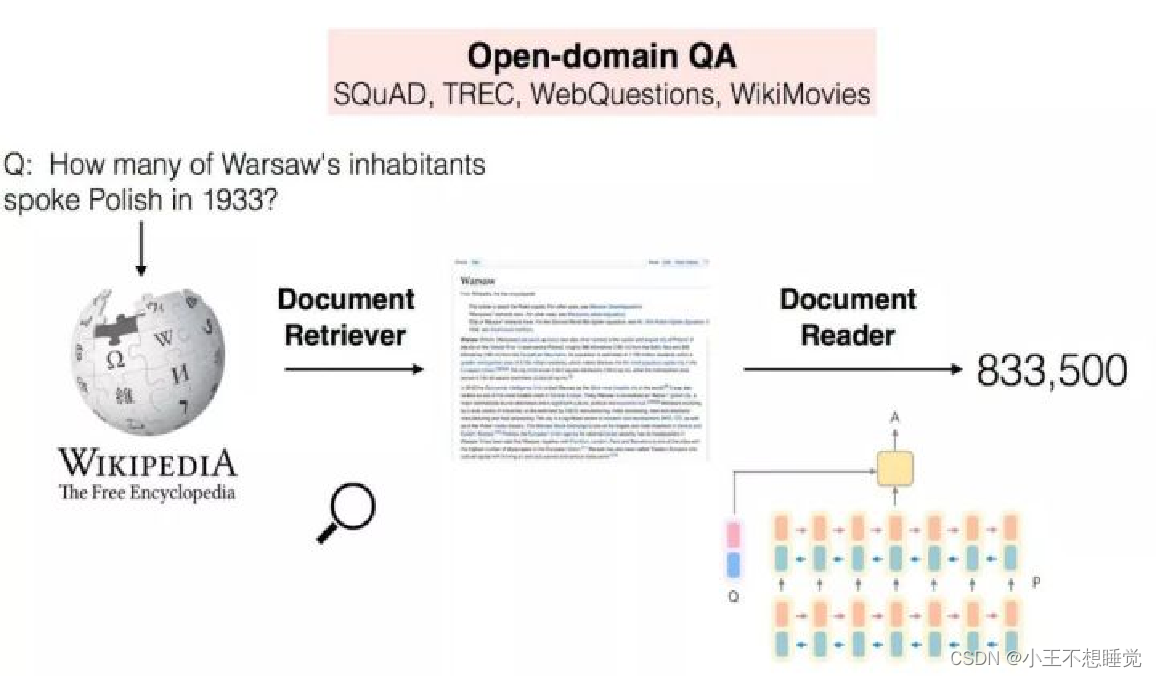
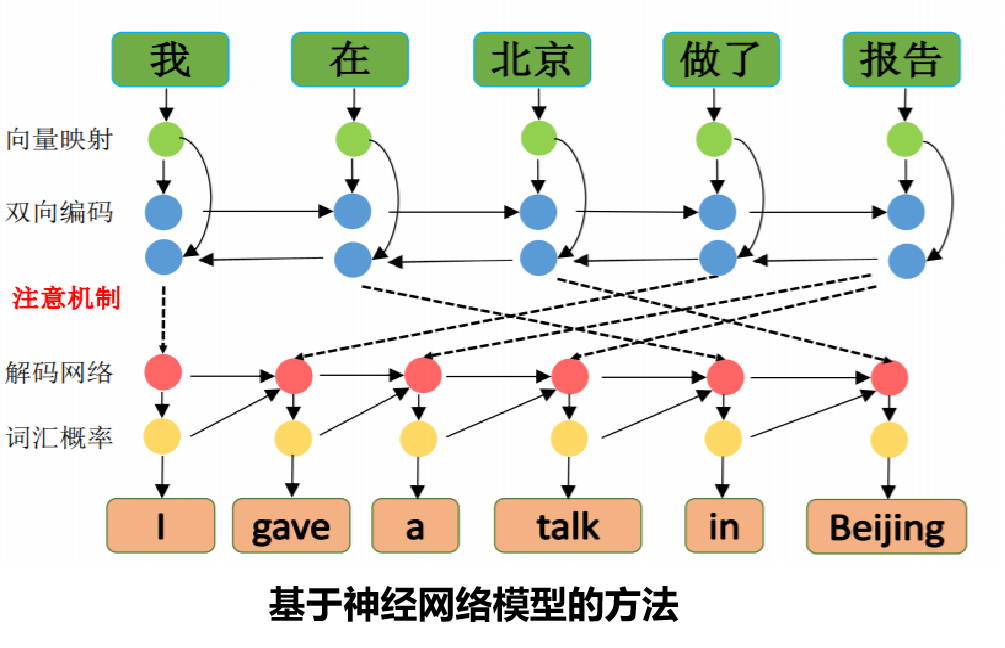
机器翻译(MT)
MT是一种自动将源语言文本翻译成目标语言的技术。它使用特定的算法和模型,尝试在不同语言之间实现最佳的语义映射。
示例: 当你输入"Hello, world!"到Google翻译,并将其从英语翻译成法语,你会得到"Bonjour le monde!"。这就是机器翻译的一个简单示例。
机器翻译的核心概念包括:
- 源语言(Source Language):原始的自然语言文本,需要进行翻译。
- 目标语言(Target Language):需要翻译成的自然语言文本。
- 翻译单位(Translation Unit):源语言文本中的基本翻译单位,通常是词、短语或句子。
- 翻译策略(Translation Strategy):机器翻译系统使用的翻译规则或策略,用于将源语言转换为目标语言。
- 译文(Translation):机器翻译系统对源语言文本的翻译结果。
机器翻译的核心是翻译模型,它可以基于规则、基于统计或基于神经网络。这些模型都试图找到最佳的翻译,但它们的工作原理和侧重点有所不同。
自动问答(QA)
自动问答(Question Answering, QA)是指利用计算机自动回答用户所提出的问题以满足用户知识需求的任务。不同于现有搜索引擎,问答系统是信息服务的一种高级形式,系统返回用户的不再是基于关键词匹配排序的文档列表,而是精准的自然语言答案。
- 涉及词法分析、句法分析、语义分析、信息检索、逻辑推理、知识工程、语言生成等多项关键技术。
- 技术的发展趋势是从限定领域向开放领域、从单轮问答向多轮对话、从单个数据源向多个数据源、从浅层语义分析向深度逻辑推理不断推进。
图神经网络
思想与基本架构
欧式空间与非欧式空间数据
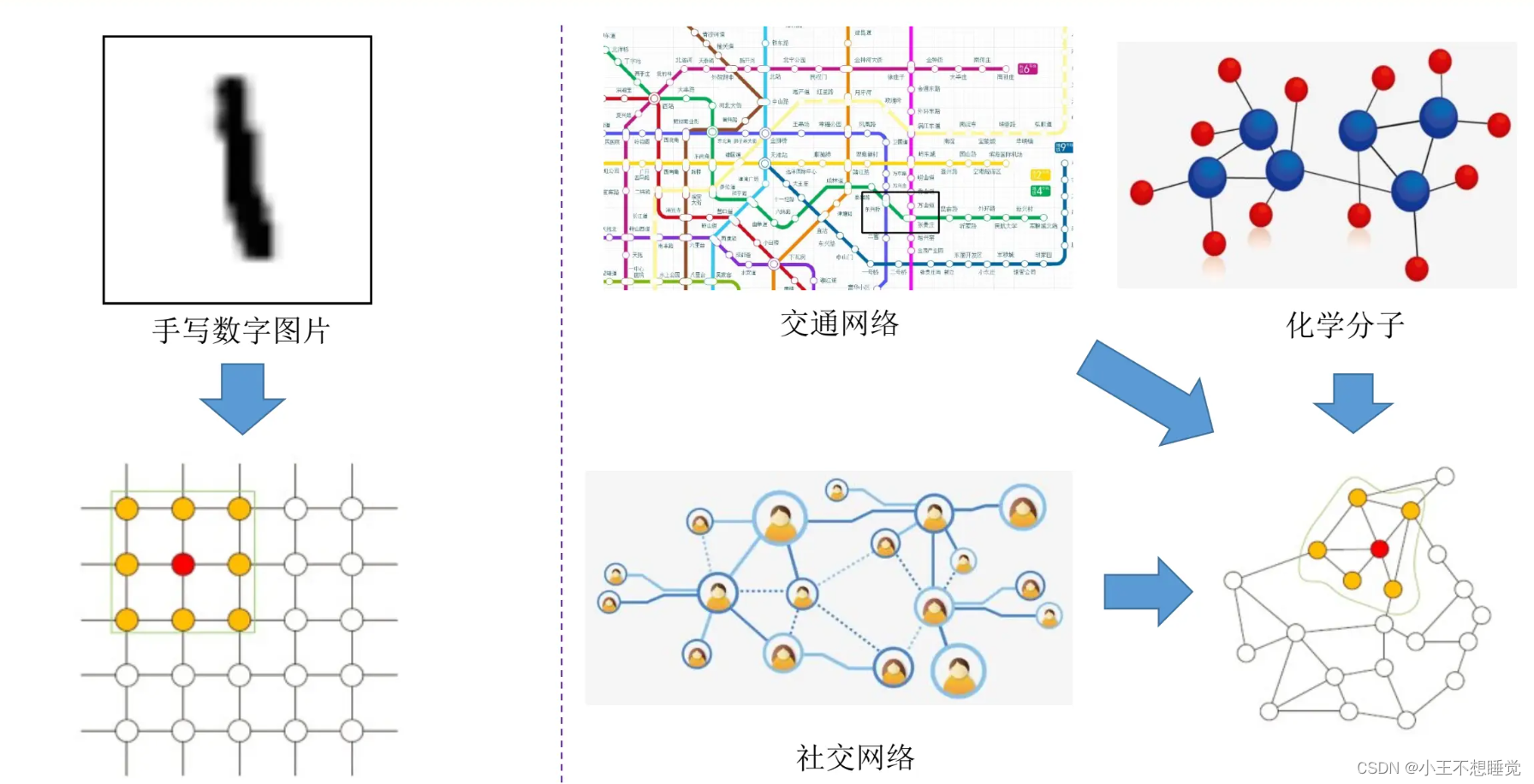
为什么研究
图神经网络(Graph Neural Networks)是一种可将图数据和神经网络相结合,在图数据上面借助神经网络提取特征的能力来进行计算处理的模型。
- 传统的神经网络无法处理非欧式结构的数据。
- 图神经网络(GNN)成为了研究的热点。
例如:卷积神经网络在非欧式结构的数据上无法保持平移不变性。通俗理解就是,在拓扑图中每个顶点的相邻顶点数目都有可能不同,因此无法使用一个同样尺寸的卷积核来进行卷积运算。然而,实际场景中又希望在这样的数据结构(拓扑图)上有效地提取特征以适配任务目标。
图的定义
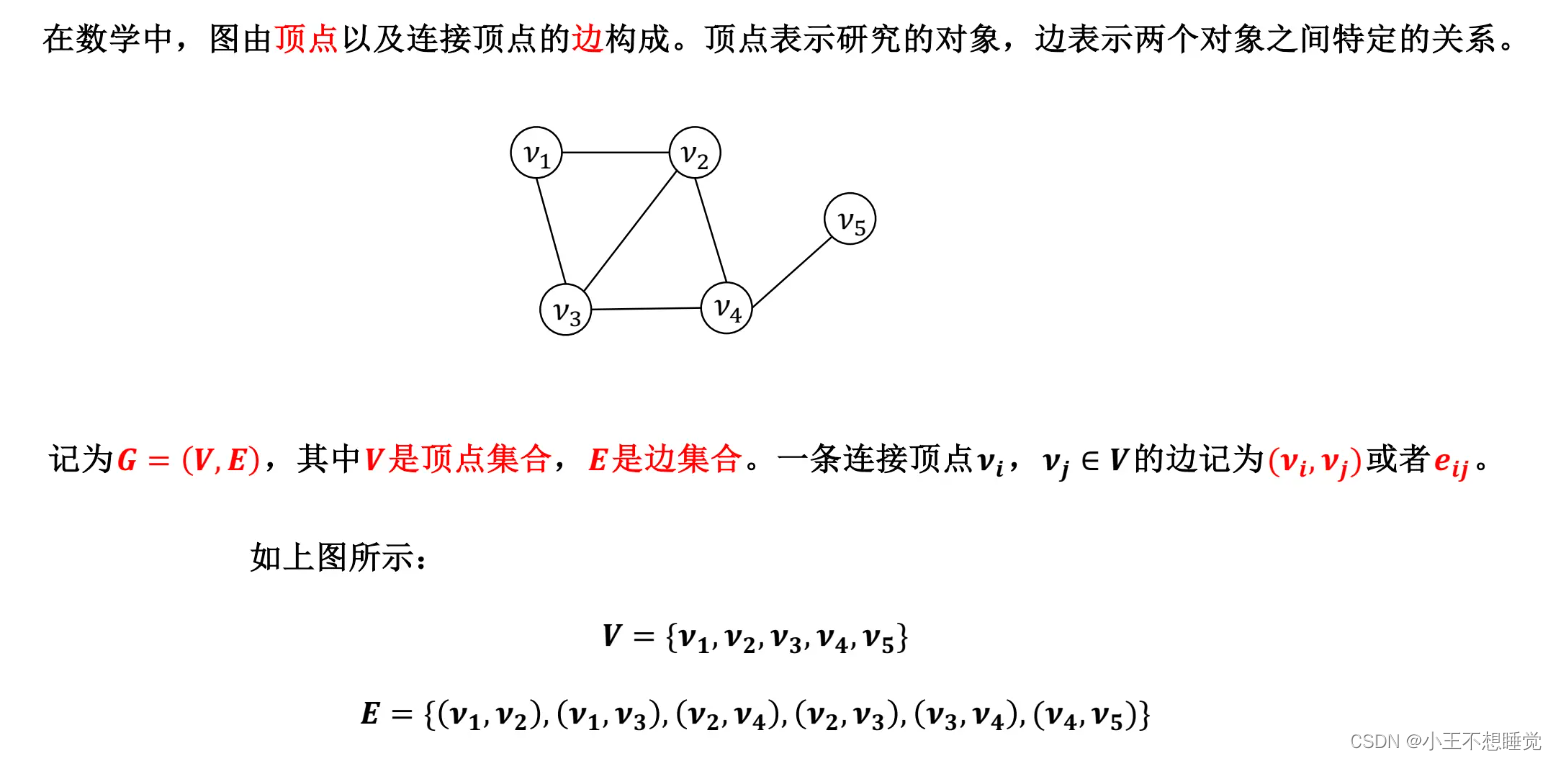
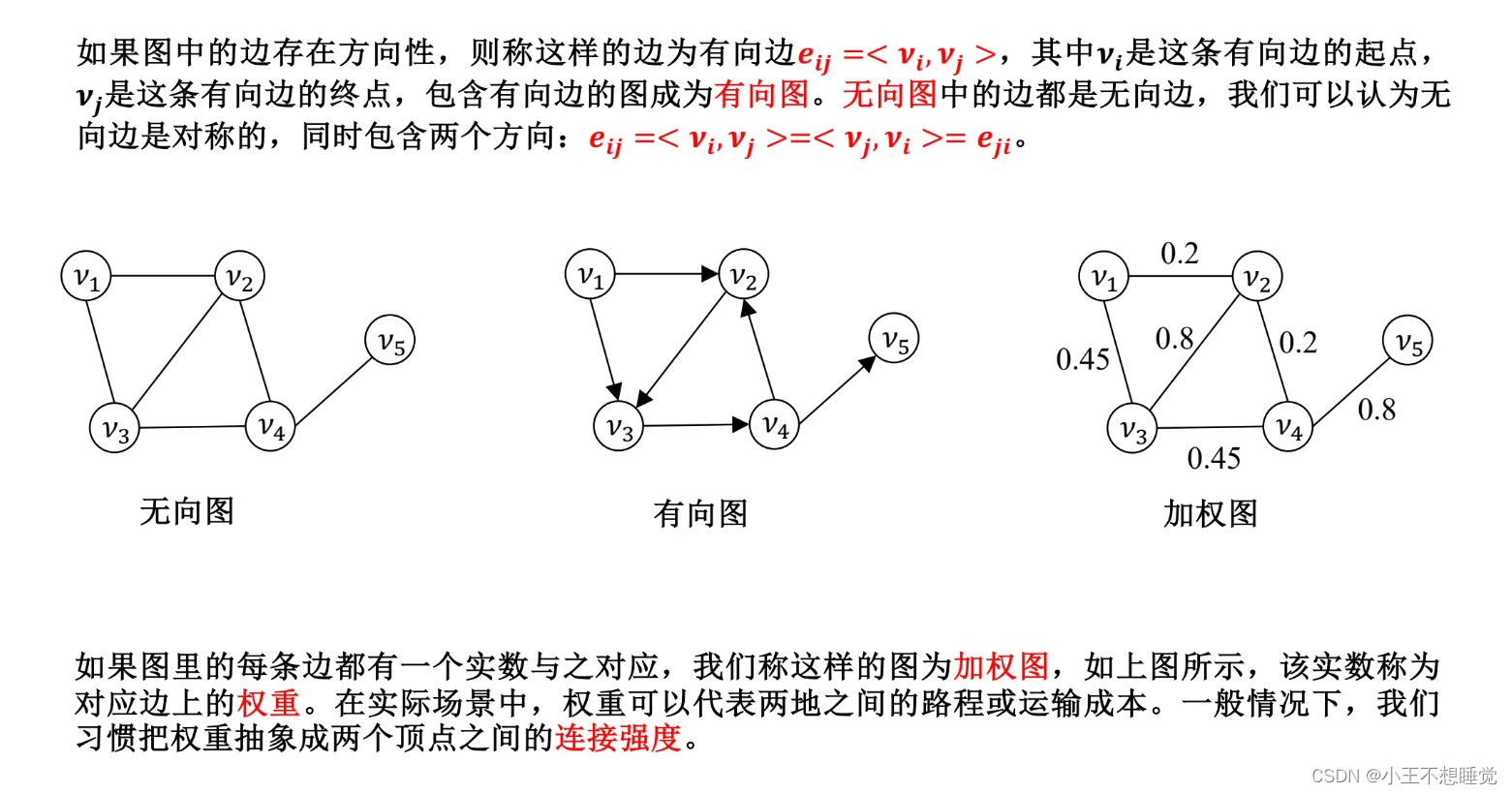
图的基本类型
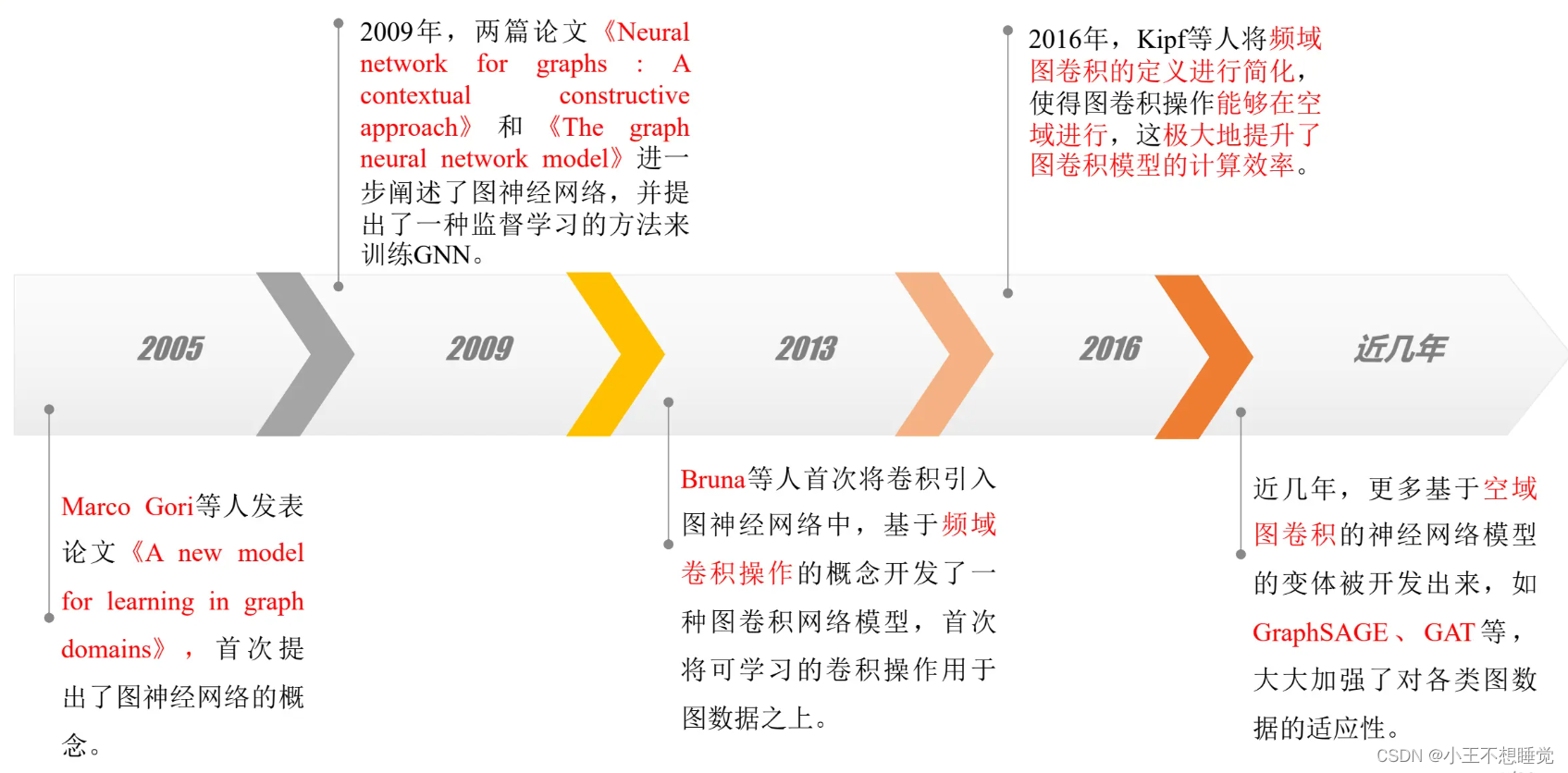
图神经网络的发展历程
三个层面任务
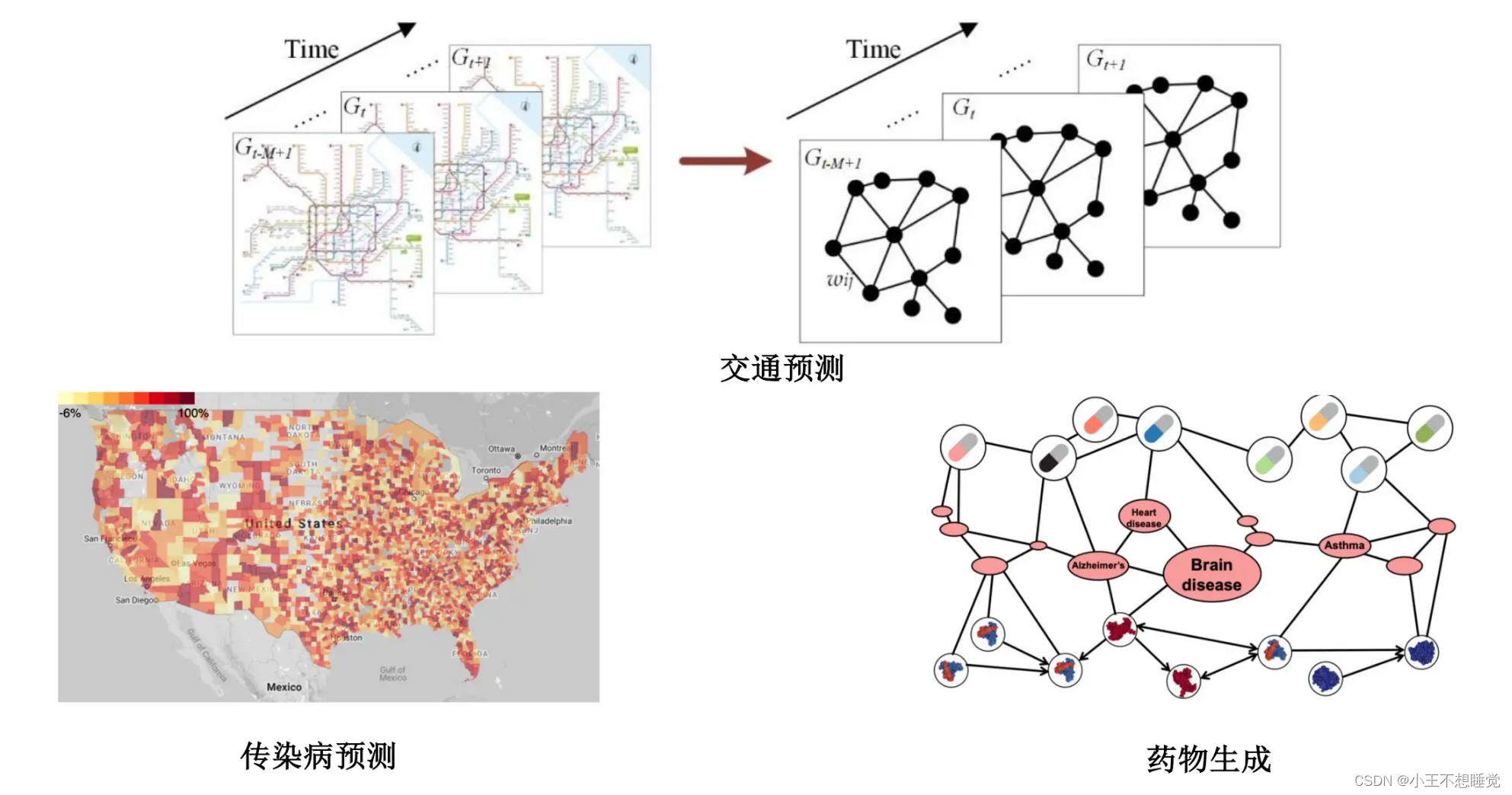
- 节点层面(Node Level):节点层面的任务主要包括分类任务和回归任务。节点层面的任务有很多,学术上使用较多对论文引用网络中的论文节点进行分类,工业界在线社交网络中用户标签的分类、恶意账户检测等。
- 边层面(Link Level):边层面的任务主要包括边的分类和预测任务。边的分类是指对边的某种性质进行预测;边预测是指给定的两个节点之间是否会构成边。目前,边层面的任务主要集中在推荐业务中。
- 图层面(Graph Level)的任务:图层面的任务不依赖于某个节点或者某条边的属性,而是从图的整体结构出发,实现分类、表示和生成等任务。目前,图层面的任务主要应用在自然科学研究领域,比如对药物分子的分类、酶的分类等。
结合其他传统神经网络的发展趋势
学习通练习题

资料仅供复习参考,侵删。
cr.Kerst















 719
719











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









