







NewBeeNLP公众号原创出品
公众号专栏作者 @Maple小七
北京邮电大学·模式识别与智能系统
TL;DR
虽然以SentenceBERT为代表的语义向量检索展现出了超越传统的以BM25为代表的稀疏向量检索的性能,但是还没有人研究过索引量和向量维数对稠密向量检索性能的影响。
本文作者通过理论和实验来证明了随着索引量的增大,稠密向量检索的表现比起稀疏向量检索下降得更快,在极端情况下,稀疏向量检索反而优于稠密向量检索。

论文:The Curse of Dense Low-Dimensional Information Retrieval for Large Index Sizes
链接:https://arxiv.org/abs/2012.14210
开篇
传统的信息检索技术通常使用TF-IDF、BM25这类稀疏表示来检索文档,然而这些方法都建立在用户查询与相关文档存在词汇重叠的基础之上。然而现实世界并不会这么理想,稀疏向量查询通常会存在棘手的词汇空缺或语义鸿沟问题(lexical/semantic gap)。
「语义鸿沟」可以理解为是自然语言词汇的稀疏性和语法的多样性,这些现象可以通过同义词典、句式变换等方式来改善。
「词汇空缺」是源自翻译语言学的现象,我们可以将其简单地理解为用户查询与文档的不对称性,比如FAQ语料库通常存储的都是比较标准,正式的问句,然而真实场景下用户的提问通常非常口语化,标准问句和真实查询的字面匹配分数常常很低,这就不仅仅是单纯的词汇或句法差异了,而是更高层次的风格上的差异,甚至可以理解为两种不同的语言,这实际上也是当前的搜索引擎在正式检索文档前必须对用户查询进行复杂的修正、解析、理解,而不是直接计算TF-IDF的原因。
将用户查询浓缩为关键词的过程是非常复杂的,有没有直接将用户查询与文档进行匹配的方式呢?这正是稠密向量查询想要达到的效果,也就是将查询和文档映射到同一个低维向量空间,通过计算余弦相似度来检索相关文档,关于稠密向量表示的探索可以追溯到经典的潜在语义分析(LSA),2013年的DSSM首次将深度学习方法引入了稠密向量检索,目前,以SentenceBERT为代表的语义检索模型在很多数据集上超越了基于稀疏向量的检索方法。
然而,这些模型的实验数据集的索引量大多都比较小,其中最大的MS Macro数据集也只有八百万个文档,然而在实际的应用场景中,索引量常常能够达到上亿的量级。当索引量非常大的时候,稠密向量表示还优于稀疏向量表示吗?接下来,我们分别从理论和实践的角度来分析这个问题。
Theory
给定一个查询向量 和文档向量 ,分别计算查询和文档的余弦相似度:
直观上来看,查询结果的假阳性率(false positives)会随着索引量 的增大而增大,不妨假设文档向量相互独立,如果要保证没有检索到假阳性文档,则需要满足
其中 是与 相关的文档向量,如果该条件不满足,则出现假阳性的概率为
可以发现随着索引量 的增大,出现假阳性的概率的确也是增大的。
但假阳性率和向量维数的关系就没这么直观了,对于随机的 ,我们希望求出具体的假阳性率:
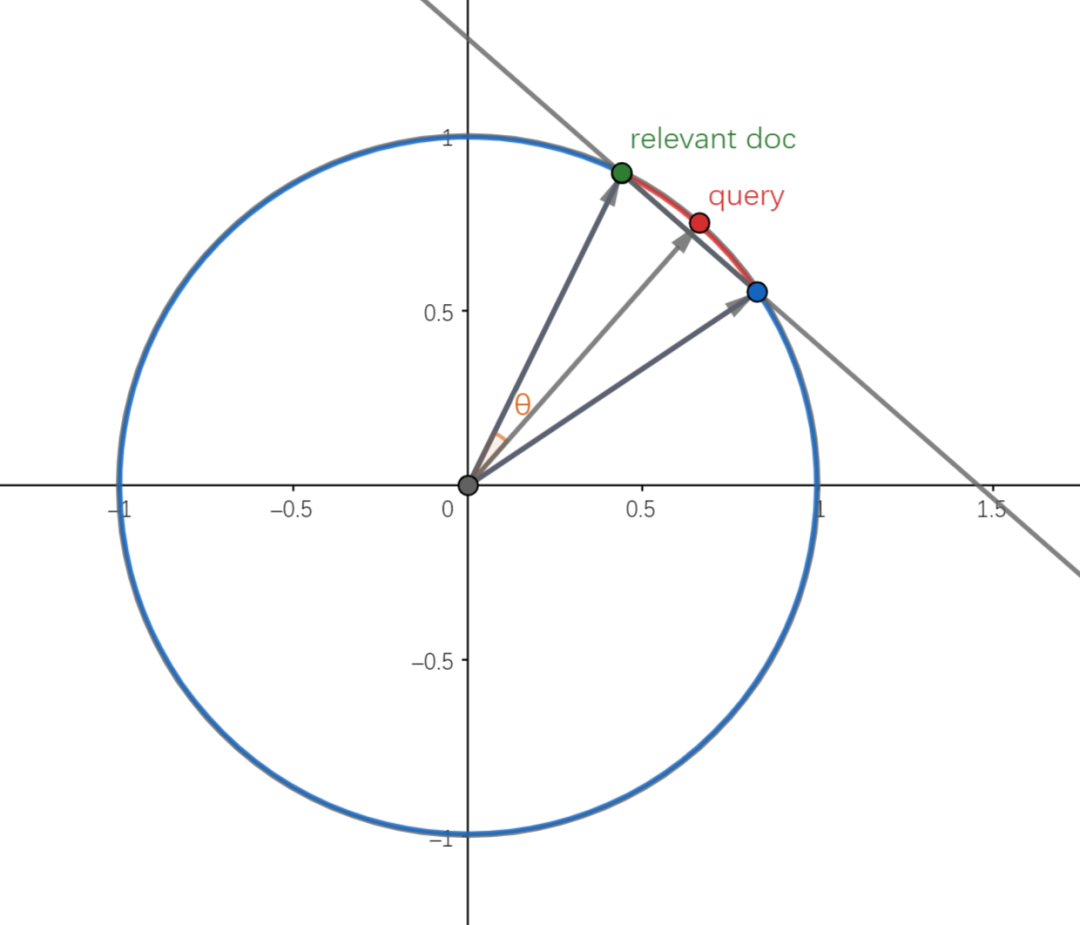
首先,不妨将 维文档向量标准化为单位向量,当 满足 的时候,则 为假阳性,因此我们考虑用 维超平面从单位球面上切出会出现假阳性的区域,一个随机生成的向量被判定为假阳性的概率为
其中 是切出来的区域的表面积, 则是单位球面的面积。以二维空间为例,如下图所示,当 落入红色区域 时,则 为假阳性文档。
高维空间就很难直观地理解了, 维空间中 的计算公式为
其中 为 和 形成的极角, 为正则不完全贝塔函数:
针对相同的夹角 , 是随着维数 的递增而单调递减的,也就是说,向量维数越大,出现假阳性文档的概率就越小。
因此,虽然稠密向量索引的优势之一在于向量维数远小于稀疏向量索引,非常节省内存,但过小的维数会导致假阳性率的提升,同时当索引量越来越大时,低维稠密表示比起高维稠密表示会有更高的假阳性率。
Empirical Investigation
上面的理论证明均假设了向量是独立均匀分布的,这实际上只为我们提供了一个假阳性率的下界。实际上,正如BERT-flow[1]里面提到的一样,模型学习到的稠密向量分布通常是各向异性的,这些向量在整个向量空间中只占据了一个狭窄的锥形空间,这样的性质将大幅度提升检索结果的假阳性率,因此作者希望通过实验来观察这种现象到底有多严重。
Dataset
作者的实验数据集为MS MACRO,该数据集包括了一百万个来自Bing的真实用户查询和八百万个候选文档,绝大部分查询只对应着一个相关文档,检索评价指标为MRR@10。为了更好地对比稠密向量检索和稀疏向量检索的相对性能差异,作者还定义了一个rank-aware error rate指标:
并在该指标的基础上进一步定义了相对误差率: ,举个例子,50%的相对错误率就表示稠密向量表示的bad case只有BM25向量表示的一半。
Model
作者采用基于BM25的ElasticSearch实现了稀疏向量检索,针对稠密向量检索,作者训练了基于DistilRoBERTa-base的孪生网络,损失函数采用的是对比学习常用的InfoNCE loss:
其中负样本的采样方式为批内负采样,并为每个 加入了一个BM25检索出的困难负样本(hard-negative),为了对比输出向量维数对模型性能的影响,作者在模型的平均池化层后面额外接了一个线性变换层。
Experiments
Increasing Index Size
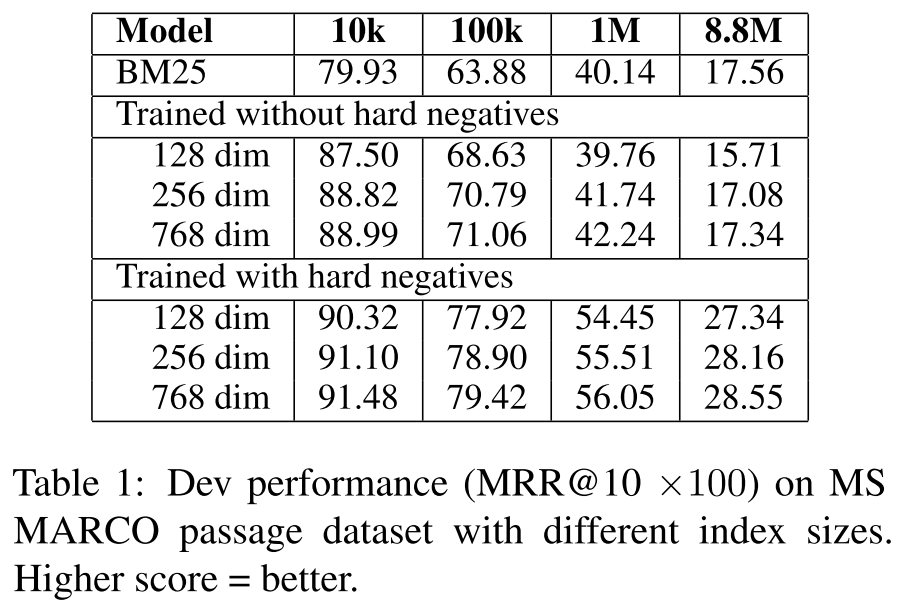
如下表实验结果所示,当我们将索引量从一万增加到八百万的时候,所有检索模型的性能均出现了明显的下降,稠密向量表示和稀疏向量表示的性能差距也逐渐缩小。
当向量维数过小时(128 dim),模型性能会出现小幅下降,虽然增大向量维数可以一定程度上缓解索引量增大的影响,但在巨大的索引量面前,增大维数带来的性能提升是微乎其微的。
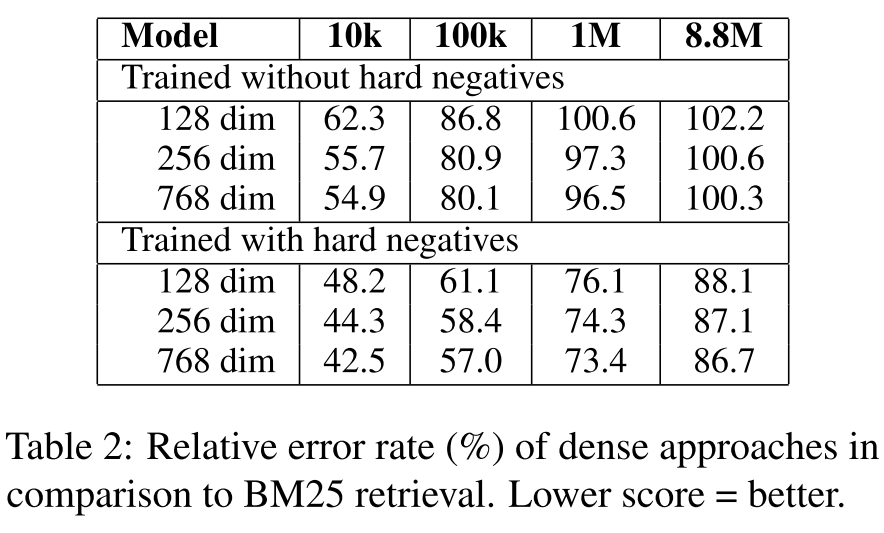
下表展示了稠密向量与BM25向量比较的相对错误率,随着索引量的增大,稠密向量检索和BM25向量检索的差距逐渐减小。
Index with Random Noise
如果我们将大量随机字符串加入文档库,模型性能会受到影响吗?由于MS MACRO数据集的标注是不充分的,也就是说每个查询只标注了一个相关文档,但实际上可能有多个文档都是相关的。
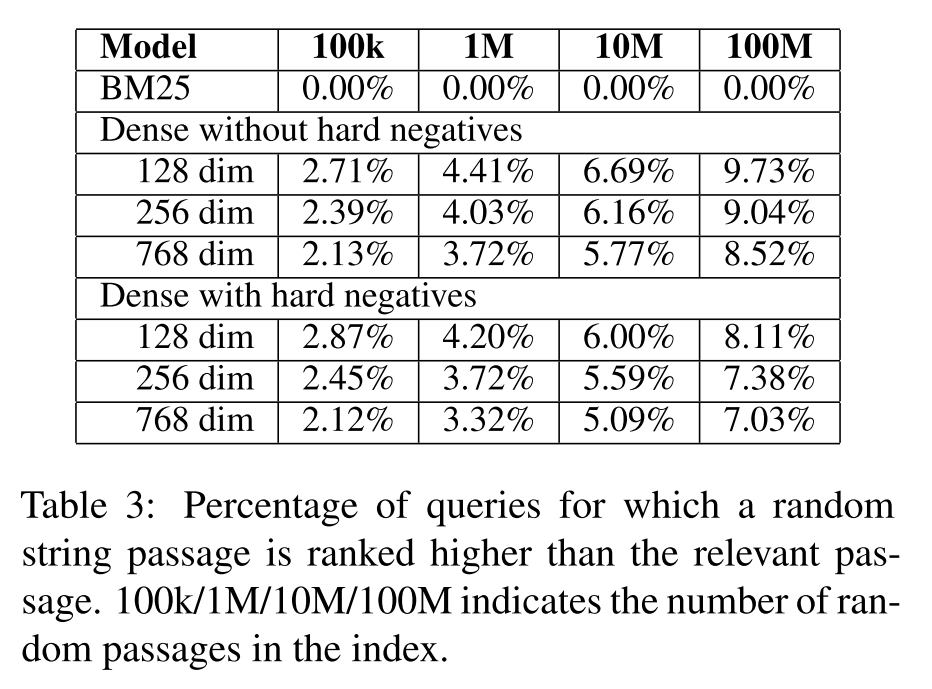
为了防止相关但未被标注的文档对实验结果的影响,作者假定检索的时候只存在一个相关索引向量和一堆随机生成的向量,这些随机向量是通过将长度为20~150的随机字符串输入模型后得到的,在实验中,作者统计有多少随机字符串与查询的相似度高于相关文档与查询的相似度。
实验结果如下表所示,随着加入的随机字符串数量的增多,稠密向量表示的性能出现了明显的下降。具体来说,当我们加入了一亿个随机字符串的时候,每十个查询中就有一个查询会返回随机字符串,这样高的错误率在实际应用中是难以容忍的。
值得注意的是,BM25却完全没有受到随机字符串的影响,这是因为生成和查询词汇匹配的字符串的概率是非常低的。另外作者还认为实验结果表明错误率比理论估计增长的速度更快,这说明稠密向量的分布非常集中,只占据了整个向量空间的一小部分,不过该结论仅仅是一个直观感受。
为了直观地感受稠密向量的分布情况,我们可以将稠密表示的查询向量,文档向量和随机字符串向量通过UMAP可视化出来,如下图所示,可以发现随机字符串向量(红色)和查询、文档向量有较大部分的重合。
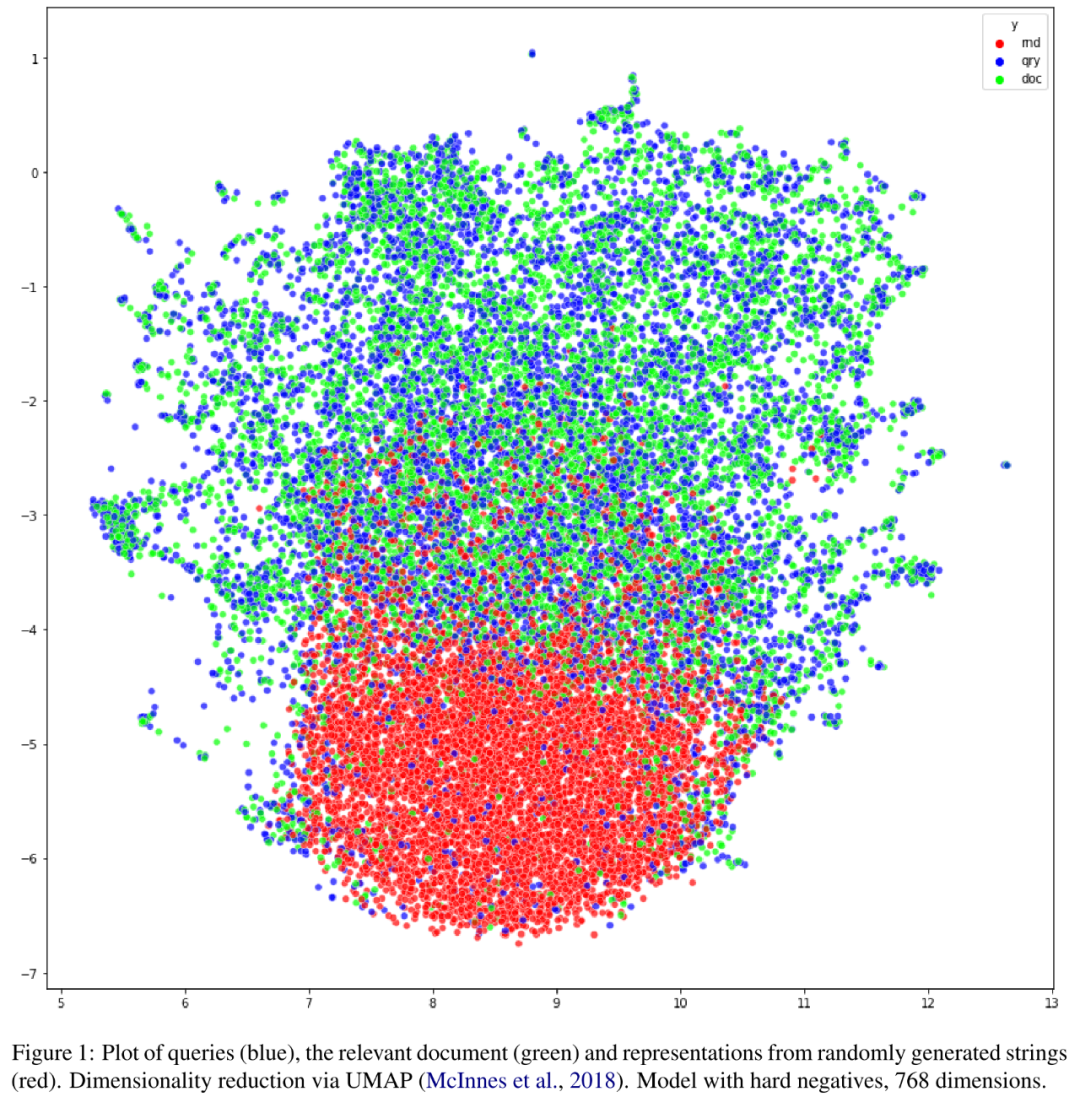
Discussion
这篇论文从理论和实验的角度证明了稠密向量检索的假阳性率会随着索引量的增大和向量维数的减小而增大。虽然稠密向量检索具有很好的发展前景,但需要知道目前的稠密检索通常更适用于量级较小且干净的索引,当前的模型通常都是在小索引量的数据集上进行的实验,得出的结论可能不适合大数据集。
因此并不是在任何场景下稠密检索都要优于稀疏检索,SentenceBERT也并不能完全替代BM25。当索引量过大时,如何有效结合稀疏向量索引高精度和稠密向量索引高召回的优势,移除噪声的干扰,其实是一个值得关注的方向。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定要备注信息才能通过)

本文参考资料
[1]
BERT-flow: https://zhuanlan.zhihu.com/p/331807184
- END -






















 615
615

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









