






作者:Tobias Lee
合作单位:北京大学、腾讯云智能、香港大学
链接:https://zhuanlan.zhihu.com/p/633632317
给大家介绍一下我们最近关于大语言模型生成质量评估的一个工作:
Paper Title: Large Language Models are not Fair Evaluators
Arixv Link: https://https://arxiv.org/pdf/2305.17926v1.pdf.pdf
GitHub: https://https://github.com/i-Eval/FairEvalval
TL; DR:
大型语言模型(如GPT-4)评估不同模型表现时存在系统性偏见: 通过改变不同模型的答案在评价模版中的顺序,可以轻松篡改它们的质量排名,从而扭曲评估结果。
随着生成式 AI 的快速发展,怎么评测模型生成的内容成为了一个非常有意思的问题。传统的生成的指标像 n-gram based metrics(BLEU、ROUGE)以及基于语义距离的指标 BERT-Score 都不太适合开放域的,chatbot 式的 AI 生成内容的评估。
那咋办呢,不能通通靠人工测评吧,那得多费劲。好在大语言模型他不仅强,最近以 Vicuna 为代表的一系列工作 发现,大语言模型(LLMs)可以当标注人员来用,给一个特定的模板,LLMs 自己也能给两段生成的内容打分:

评估模板
在这个模板里,包含三个占位符:T(Q, R1, R2)。
对于每个测试问题 q(例如,当我摸鱼了一个礼拜啥都没干的时候,老板问我进度怎么办?),
以及模型 1 和模型 2 分别给出的两个回答
r1: 回复他你啥也没干
和
r2: 说你最近在忙着写一篇关于大语言模型测评缺陷的调研,整理思路,进行初步实验 xxxx(省略200字)
我们可以将这些回答填入相应的占位符中,形成一个提示:T(Q=q, R1=r1, R2=r2)。
然后,调用可爱的 openai 得到回复,从回复中抽取出对应的结果,例如,r1 得分为 5 分,而 r2 则会有更高的得分,并且生成理由:
采用 r1 回复的话你可能被老板开除而 r2 完美地掩饰了你啥也没干的事实,建议亲采用 r2。
这么评估,靠谱吗?
这个 LLMs as evaluator 的框架和模板直觉上,看着都挺合理的,有分也有解释,perfect 嘛!
等等,如果 r1 和 r2 换一下顺序呢?
我们惊讶的发现,在这种情况下,模型竟然会给出截然不一样的分数,并且推荐我用后果比较严重的 r1,甚至也能生成看似合理的解释。
我们在 Vicuna 提供的 80 个 query prompt 上进行了系统性的测评,发现 LLMs,对于候选回复的顺序非常敏感!
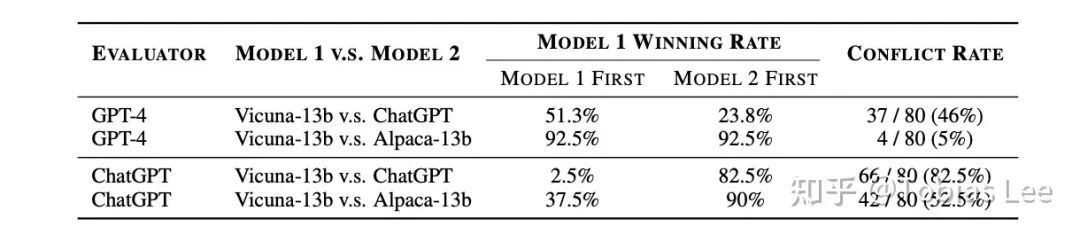
我们发现通过交换两个回答的位置并查询语言模型两次,模型很可能产生相互冲突的评估结果,并且模型会偏向于某个特定位置的回答。上表给出了在Vicuna-13b 对比 ChatGPT和 Vicuna-13b 对比 Alpaca-13b的评估中,当交换两个模型的回复顺序时,GPT-4 给出的评估结果的冲突率分别为46%和5%。相比之下,ChatGPT给出的评估结果显示出更高的冲突率,分别为82.5%和52.5%。总体而言,模型越强大,受到位置偏见的影响越小。
此外,我们还注意到,如果两个模型性能比较接近,即回答质量的差异比较小,LLMs 的评估结果受到答案位置的影响更大;而当分数差异较大时,也就是高下立判的时候,GPT-4的评估结果相对稳定。这也很 make sense,就像卡尼曼的《噪声》一书指出,在顶级的小提琴演奏比赛里,即使是专业的裁判也很难给出一致的结论,可能选手们交换出场顺序,名次就会有很大的变化。GPT-4 在偏差方面,和人类如出一辙。
解决方案
问题找到了,那应该怎么办呢?一个拍脑袋的想法就是,那我交换顺序之后取平均是不是就可以了?
没错,我们也是这么干的!
我们尝试的第一个技巧就是利用两个顺序来降低这个偏差:
平衡位置校准 (Balanced Position Calibration,BPC):通过交换两个答案的位置。为了确定特定答案的最终评分,我们计算其作为第一个回答和第二个回答时的平均分数。这种平均化过程有助于确保更平衡的评估,并减少评分过程中位置偏差的影响。
第二个,我们注意到, 这个模板让模型先给结论再给解释,根据自回归语言模型的特点,结论无法被解释很好地支撑,此外,受到 self- consistency 的启发,我们还引入了采样路径上的 ensemble,即让模型多次 decode,生成更多的证据链 (evidence chain) 来校准预测:
多证据校准(Multiple Evidence Calibration, MEC):让模型先生成解释,然后给出评分。这样,评分可以通过更多的支持证据进行校准。此外,模型不仅生成一条证据,而是采样多个证据链,并将平均分数作为最终评分。
实验结果
为验证我们的方案有效性,我们请三组标注员苦逼的作者从帮助性、相关性、准确性和详细程度评估 Vicuna-13b 和 ChatGPT回复的质量,并且用三组标注员的众数作为最终的结果,来检验不同评测方法和人类评估的相关度:
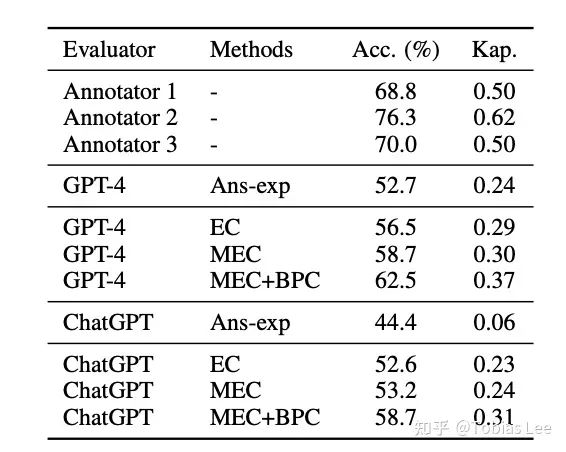
和人类评估质量一致性的结果
从上面可以看出:
GPT-4整体优于 ChatGPT,越大越好,你永远可以相信 GPT-4 !
两种校准策略显著提高评估器与人工标注的一致性,特别对比较弱的 ChatGPT准确性提高14.3%,kappa相关系数增加0.25,这俩技巧MEC和BPC策略简单有效。
细粒度分析结果
我们进一步对不同子类别的 query 性能进行了分析:
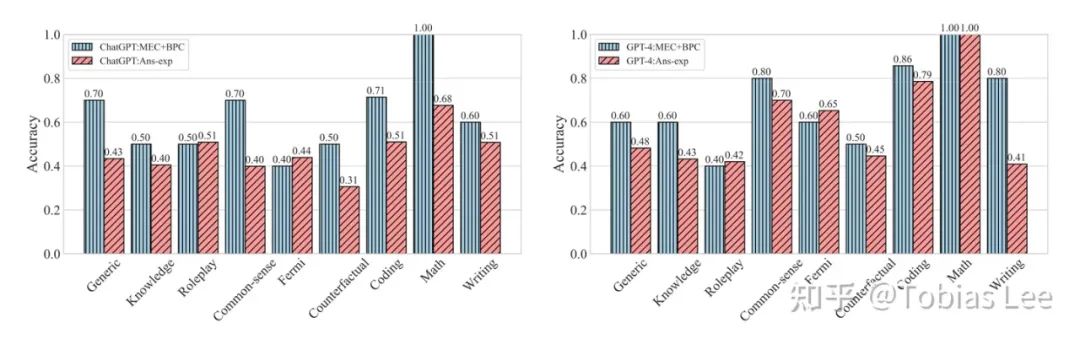
可以发现:
在某些复杂任务(如常识、编码和数学)中,GPT-4的表现明显优于ChatGPT,凸显了GPT-4作为一个更公平的评估器的优势;
我们提出的MEC+BPC策略在评估ChatGPT在复杂任务上的表现方面取得了显著的改进。不过因为整体的 case 比较少,某些类别的 case 多做对一个可能准确率就提升 33% 了,所以请谨慎看待这里的提升。
多次采样效果会更好吗?
MEC 里很重要的一个参数是采样 k 条证据链,那么,是不是钞能力能解决一切呢(k 越大越好)?请看下图:
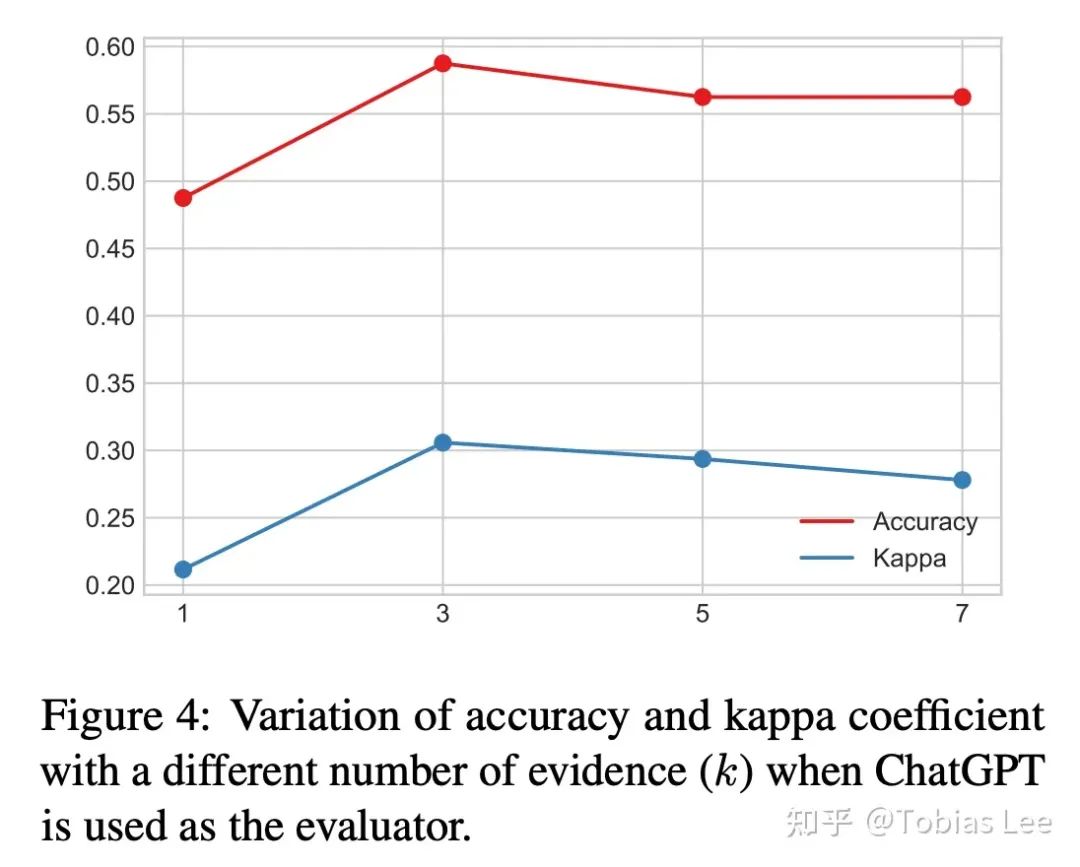
k=3 的时候效果最好,越大反倒是会带来性能的下降,这一点也和 self-consistency 的分析基本一致,这种性能-开销的 trade-off 基本也普遍存在。
结语
用大语言模型做裁判来评估模型的时候要谨慎对待其给出的结果,特别是模型性能比较接近的时候,多次平均(order、evidence chain)可能是一个直接且有效的稳定结果方案。但是有没有更好的替代呢,也期待未来在这方面的更加深入的探究!
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)


















 605
605

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









