






LLM-Rec:基于提示大语言模型的个性化推荐
1. 基本信息

论文题目:LLM-Rec: Personalized Recommendation via Prompting Large Language Models
作者:Hanjia Lyu, Song Jiang, Hanqing Zeng, Yinglong Xia, Jiebo Luo
机构:University of Rochester, University of California Los Angeles, Meta AI, University of Rochester
2. 摘要
本文研究了通过输入增强来提高大语言模型个性化内容推荐性能的各种提示策略。提出的方法LLM-Rec包括四种不同的提示策略:1)基本提示 2)推荐驱动提示 3)参与指导提示 4)推荐驱动+参与指导提示。实验结果表明,将原始内容描述与LLM使用这些提示策略生成的增强输入文本相结合,可以提高推荐性能。这一发现强调了在大语言模型中融入多样化的提示和输入增强技术以提高个性化内容推荐能力的重要性。
3. 介绍
本文研究了利用大语言模型(LLM)进行输入增强的提示策略,以提高个性化内容推荐。
之前的研究更多关注直接利用LLM作为推荐模型。本文从不同的角度出发,探索用于增强输入文本的提示策略,以发挥LLM的潜力。
本文的主要贡献是提出了LLM-Rec提示,它包含基本提示、推荐驱动提示、参与指导提示以及推荐驱动与参与指导组合提示等策略。这些策略旨在增强LLM生成的输入文本,提高内容推荐的准确性和相关性。
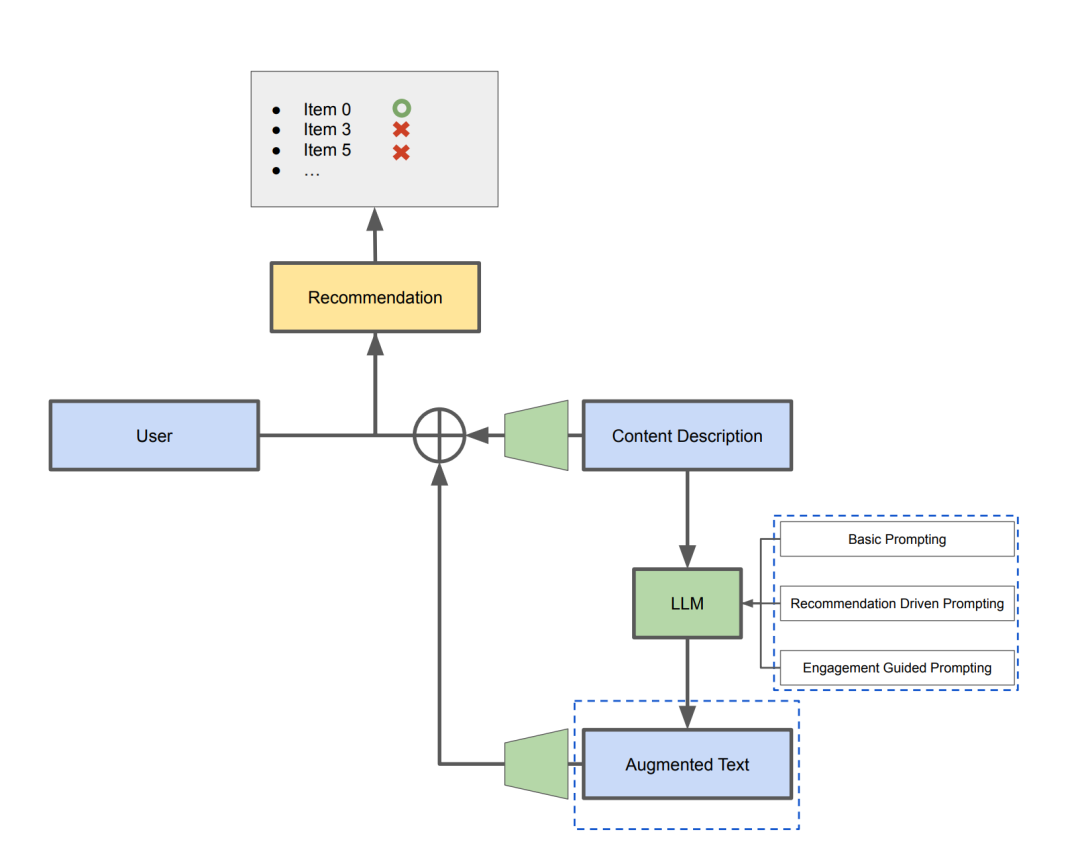
4. 方法
本文提出了四种提示策略:
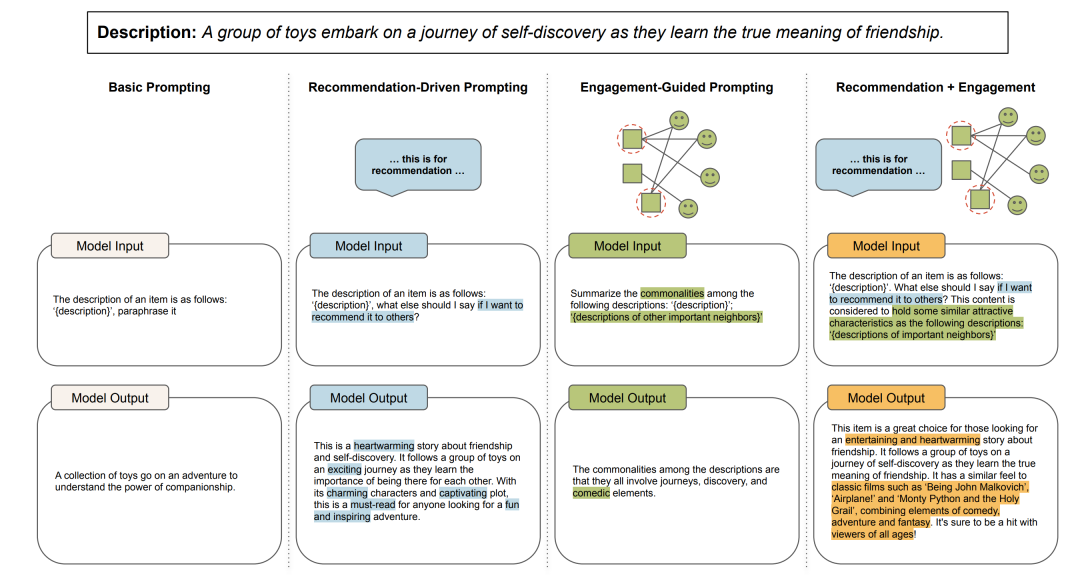
基本提示:包含三种基本提示, , ,分别指示LLM进行原始内容描述的释义、摘要和归纳。
推荐驱动提示:在基本提示的基础上加入推荐驱动指示,得到, , 。明确生成的内容描述用于内容推荐,引导LLM聚焦在关键特征上。
参与指导提示:,结合目标项目及其重要邻居项目的内容描述,利用用户参与指导LLM生成与用户偏好更符的内容。
推荐驱动与参与指导组合提示:,融合推荐驱动和参与指导提示的优点。

5. 实验发现
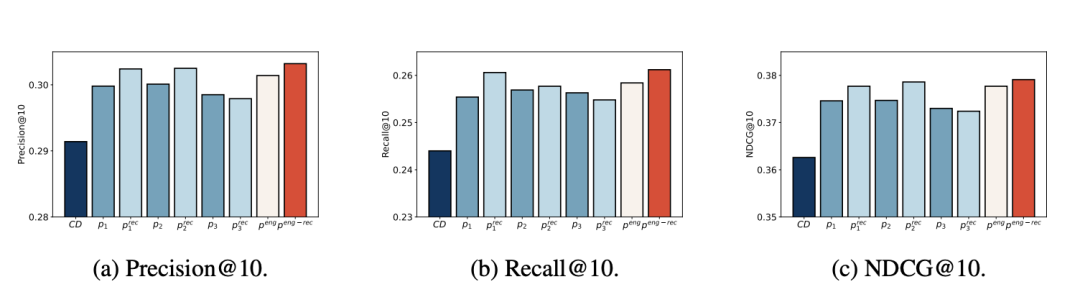
实验结果表明,除了基准外,其他方法中LLM生成的增强文本与原始内容描述的组合都可以提高推荐性能。
推荐驱动提示主要增强了面向推荐的文本生成。
相比基本提示,的推荐性能有所提升,表明参与指导提示让LLM生成的内容更符合用户偏好。
的推荐性能最好,表明推荐驱动和参与指导提示的组合作用。
6. 结论
本文介绍了LLM-Rec提示策略,利用大语言模型进行输入增强,以提高个性化内容推荐。通过对LLM-Rec四种变体的全面实验,观察到增强输入文本与原始内容描述的组合可显著提高推荐性能。这些发现强调了使用LLM和策略化提示技术来提高个性化内容推荐的准确性和相关性的潜力。本文的研究凸显了创新方法对利用LLM进行内容推荐的重要性,并展示了输入增强在改进推荐性能方面的价值。随着个性化内容推荐在各个领域继续发挥关键作用,研究为有效运用LLM提供提供了洞见,以提供增强的推荐体验。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



















 1060
1060

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









