






Towards Efficient and Effective Unlearning of Large Language Models for Recommendation
arXiv preprint arXiv:2403.03536, 2024.Wang H, Lin J, Chen B, et al.
目录
Towards Efficient and Effective Unlearning of Large Language Models for Recommendation
摘要
大型语言模型( Large Language Models,LLMs )的显著进步催生了一个很有前景的研究方向,即利用LLMs作为推荐器( LLMs as Recommenders,LLMRec )。LLMRec的功效源于LLMs所固有的开放世界知识和推理能力。LLMRec基于用户交互数据,通过指令调优获得推荐能力。然而,为了保护用户隐私和优化效用,LLMRec有意遗忘特定的用户数据也是至关重要的,这通常被称为推荐Unlearning。在LLMs时代,推荐Unlearning对LLMRec提出了新的挑战,主要表现在推荐Unlearning的低效性和无效性。现有的Unlearning方法需要在LLMRec中更新数十亿个参数,成本高、耗时长。此外,在Unlearning过程中,它们总是对模型效用产生影响。为此,我们提出了E2URec,这是第一个针对LLMRec的Efficient和Effective Unlearning方法。我们提出的E2URec仅通过更新少量额外的LoRA参数来提高Unlearning效率,并通过使用教师-学生框架来提高Unlearning效率,其中我们维护了多个教师网络来指导Unlearning过程。大量实验表明,在两个真实数据集上,E2URec的性能优于当前最先进的基线。具体来说,E2URec可以在不影响推荐性能的前提下高效地遗忘特定数据。
一、本文贡献:
1、据我们所知,我们是第一个研究LLMRec的Unlearning问题的人。我们提出的E2URec在效率和有效性方面都优于现有的方法。
2、为了提高效率,我们提出在原始的LLM中添加一个轻量级的低秩适应( LoRA )模块。在Unlearning时仅更新LoRA参数,而LLM的参数被冻结;
3、在有效性方面,我们设计了一个新颖的遗忘教师和一个记忆教师来指导Unlearning的模型,使Unlearning的模型能够分别忘记数据和保持推荐性能;
4、在两个真实的公共数据集上的大量实验表明,与现有的基线相比,我们提出的E2URec在LLMRec的推荐Unlearning方面具有优越性。
二、E2URec
1、 LLMRec ( LLMs作为推荐系统)旨在利用LLM来预测新项目是否会被用户点击。在这里,点击表示积极的互动,可以被购买或点赞等行为所取代。
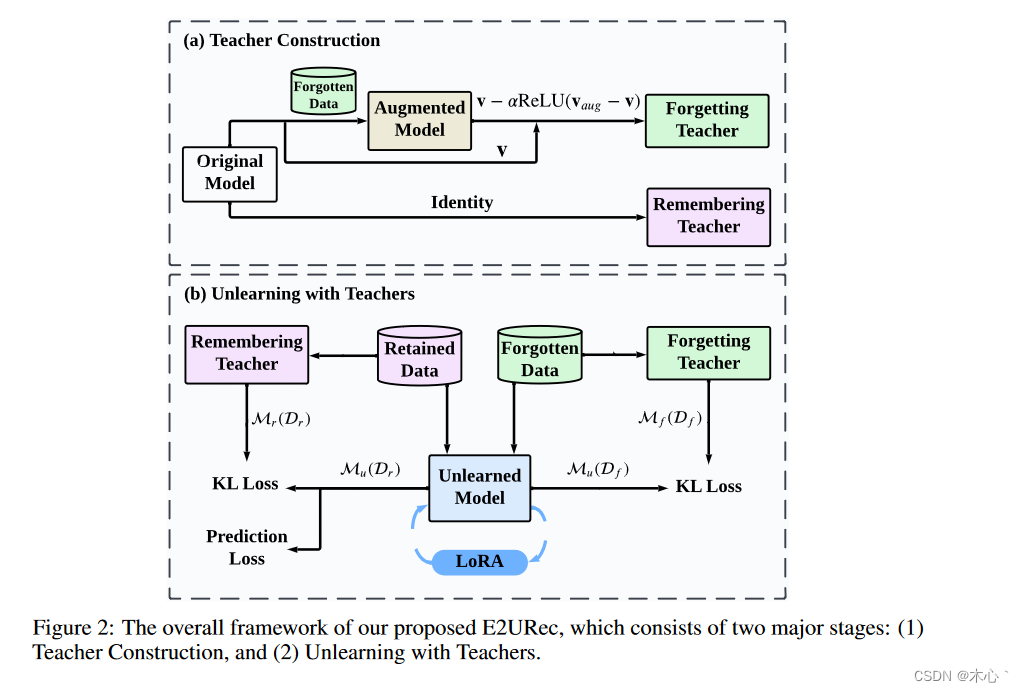
2、提出在LLM中插入轻量级LoRA模块,如图2 ( b )所示。LoRA模块在LLM的原始参数中添加了成对的秩分解权重矩阵,同时只引入了少量的参数。
将Unlearning的模型建模为:
![]()
其中φ是LLM的参数,θ是LoRA的参数。在Unlearning过程中,我们只需要更新θ,而φ保持不变。这大大降低了计算资源和时间。
3、Remembering Teacher\Forgetting Teacher Unlearning
我们的目标是通过使用两名教师来实现忘记学习,如图2 ( b )所示。为了遗忘知识,我们更新Unlearning的模型Mu,使其在被遗忘的数据Df上产生类似于遗忘教师Mf的分布。同时,为了保持推荐性能,我们更新Unlearning的模型Mu,使其在保留的数据Dr上产生类似于记忆教师Mr的分布。整个过程可以表述为:

其中KL ( · )是教师和Unlearning模型的输出概率分布之间的KL散度。
4、Forgetting teacher
使用一种近似的方法来设计Forgetting teacher。
如图2 ( a )所示,我们首先在遗忘数据Df上微调一个增广模型。对Df进行额外训练的增广模型将输出与Df更相关的logits。因此,增广模型与原模型的logit之差代表了与遗忘数据Df相关的信息。我们将增广模型和原模型的对数值分别记为vaug和v,因此两者之差为vaug - v。将这个差值从原模型的logits中减去就可以得到logits vf,从而排除了Df信息。
5、Remembering teacher
单纯的遗忘会损害模型的推荐性能。为了保留原始的推荐能力,我们鼓励Unlearning的模型在保留数据上"靠近"Remembering teacher。我们选择原始模型作为记忆教师Mr,因为它具有最好的推荐性能。
三、实验
1、数据集:MovieLen - 1M ( ML-1M )和GoodReads ( GD )
2、与E2URec进行比较:(1)原始模型;(2)Retrain;(3)SISA;(4)RecEraser;(5)NegGrad:在保留数据和遗忘数据上对原始模型进行微调,否定后者的梯度。(6)Bad-T:对原始模型进行微调,使其在遗忘数据上作为随机初始化的模型,同时保持在保留数据上的性能。
3、评价指标
1 )测试集上的AUC、ACC和LogLoss ( LL ):衡量Unlearning模型的推荐性能。
2 )遗忘数据上的JS - Divergence ( JSD )和L2范数:Unlearning和Retrain模型输出之间的JSD和L2范数衡量了Unlearning的有效性。度量值越小,Unlearning性能越好。
3 )Unlearning时间和可训练参数个数( # Params ):衡量Unlearning方法的效率。
4、结果分析
我们在表1和表2中列出了比较结果。从结果中我们观察到:
1 )我们的Unlearning方法E2URec能够更好地保持推荐性能。与其他Unlearning方法相比,E2URec在两个数据集上获得了更好的AUC、ACC和Log Loss。
2 ) E2URec在两个数据集上都取得了最小的JSD和L2范数,达到了最好的Unlearning效果。这表明我们的Unlearning模型在遗忘数据上的预测分布与重新训练的模型紧密吻合。
3 )与其他方法相比,E2URec具有更高的Unlearning效率。E2URec由于只更新轻量级LoRA参数而不是所有模型参数,因此具有最低的时间成本和# Params。

5、消融实验
在表3中," w / o LFGT "和" w / o LREM "分别代表去除LFGT和LREM。我们观察到去除LF GT会显著增加JSD,表明LFGT是遗忘数据的主要因素。去除LREM会导致AUC的显著下降,这表明LREM对于保持推荐性能至关重要。















 2716
2716











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









