






© 作者|张君杰
机构|中国人民大学
研究方向|推荐系统、自然语言处理
引言
现代推荐系统通过在候选空间中检索合适的物品来进行个性化推荐。近年来,随着生成式模型(如GPT系列)的不断发展,研究人员开始尝试将生成式技术引入推荐系统,革新推荐范式。在这一新范式下,推荐被重新建模为序列生成任务,模型通过建模用户的交互信息来生成候选物品的表征。
然而,生成式技术在推荐系统中的应用也面临一些挑战。例如:
物品的表征:相比于现代推荐系统中使用ID来表征物品,生成式方法往往采用多个离散的词元来表征一个物品(如物品的标题文本信息或离散的数字编码等)。这些离散表征的质量直接影响下游任务的性能。
多模态信息的融合:随着大语言模型(如ChatGPT)和多模态大模型(如CLIP)的不断发展,如何利用这些模型中丰富的世界知识,将多模态信息有效融合进生成式推荐系统中,也是一个值得深入探讨的问题。
本文整理了生成式推荐的部分研究进展,希望能引发大家的批评和交流。
论文列表
Enhanced Generative Recommendation via Content and Collaboration Integration
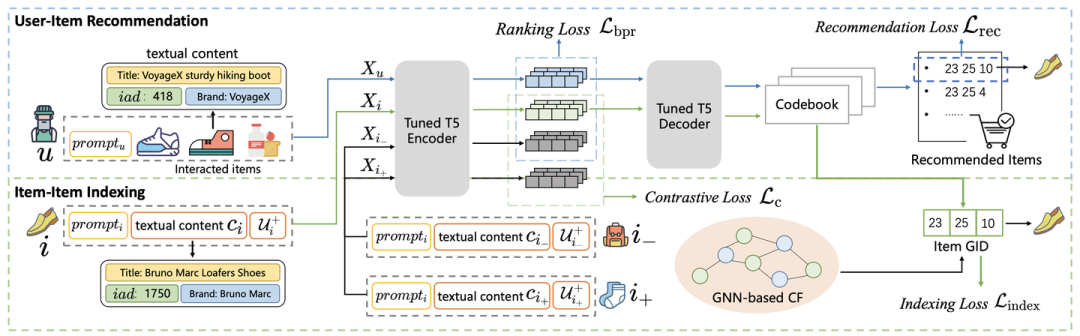
本文提出了一种端到端生成式推荐系统ColaRec,该系统使用基于编码器-解码器的语言模型(T5)来联合建模物品内容信息和用户-物品的协同信号。具体来说,为了学习具有协同信息的物品离散表征,ColaRec首先预训练了LightGCN模型,以编码每个物品的隐向量表征。随后,通过不断对这些隐向量应用k-means聚类算法,将物品进行分级聚类,并将分类类别作为物品的离散编码。
为了对齐物品内容信息和协同信息的语义空间,本文提出了两项学习任务:(1)用户-物品推荐任务。ColaRec要求模型基于用户的历史交互内容信息(如交互物品的标题、品牌等)来预测候选物品的离散编码;(2)物品-物品索引任务。ColaRec进一步要求模型基于物品的内容信息生成对应的离散编码。
通过这些方法,本文有效地融合了协同和内容信息,增强了生成式推荐系统的性能。
Learnable Tokenizer for LLM-based Generative Recommendation
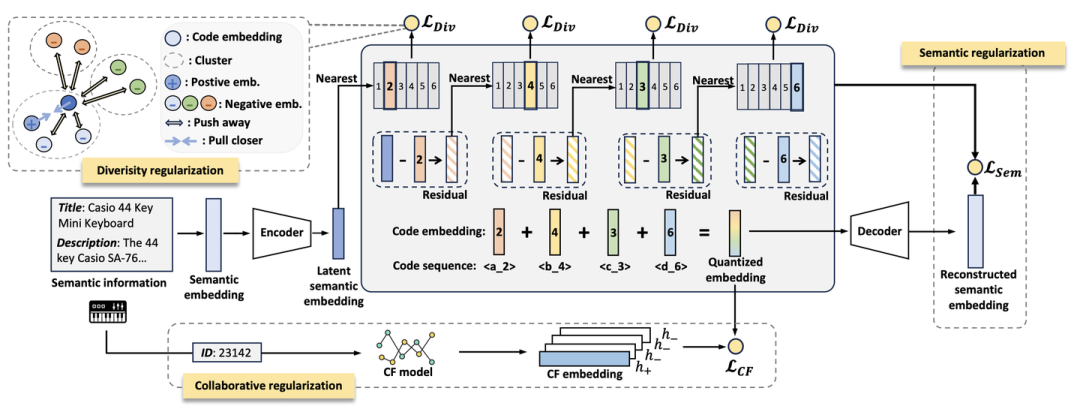
本文指出,将推荐数据转换到大语言模型能理解的语言空间是应用大语言模型辅助推荐的一个关键挑战。为此,本文提出了LETTER,这是一个可学习的分词器,通过整合层次化的语义、协同信号和编码分配的多样性来构建高质量的物品离散编码。具体来说,LETTER首先使用LLaMA2-7B作为语义提取器,来编码物品的文本语义信息。随后,LETTER采用了残差量化变分自编码器(RQ-VAE)来将物品的语义信息编码为固定长度的层次化标识符,其中RQ-VAE通过递归地量化语义残差,使用固定数量的码本来实现从粗粒度到细粒度的层次化语义编码。
为了向离散编码注入协同信息,使得用户行为中具有相似协同信号的物品具有相似的离散表示,LETTER额外训练了协同过滤推荐模型(如SASRec和LightGCN)来获得物品的协同过滤嵌入,并引入了对比学习来对齐RQ-VAE学到的语义量化编码和协同过滤嵌入。此外,作者指出,为了改善模型的生成质量,物品离散表征的分布应当尽量均匀。为此,LETTER对RQ-VAE中每个码本中的嵌入进行聚类,并使用多样性损失来正则化这些嵌入,从而鼓励码本嵌入的多样性。
通过这些方法,LETTER更有效地将推荐物品转换为大语言模型善于处理的格式,从而提高了推荐的准确性和效率。
MMGRec: Multimodal Generative Recommendation with Transformer Model
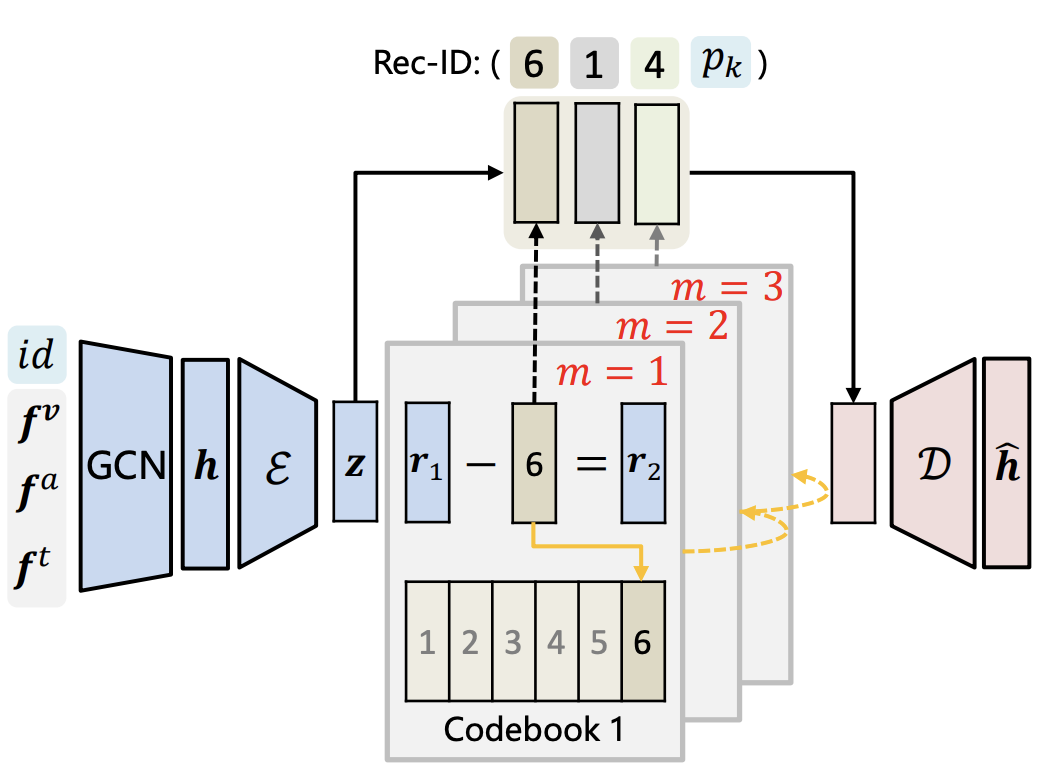
本文指出,传统的推荐系统方法主要依赖于嵌入-检索范式。然而,这种方法存在推理成本高、交互建模不足以及假阴性等问题。为了解决这些问题,本文提出了MMGRec模型,引入生成式范式来构建多模态推荐系统。
在MMGRec模型中,为了学习物品的离散编码,作者首先设计了Graph RQ-VAE模型,该模型融合了多模态信息以及用户-物品协同交互信息。具体来说,Graph RQ-VAE首先对物品的多个模态特征进行建模和拼接,形成物品的初始表征。然后,通过构建用户-物品交互二部图,并利用图卷积网络(GCN)对节点表示进行更新,最终生成物品的表示。
与之前的研究类似,Graph RQ-VAE采用RQ-VAE将学习到的物品表示编码为固定长度的层次化标识符。最后,本文训练了一个基于Transformer的推荐器,根据用户的历史交互序列生成用户偏好物品的离散编码。
Contrastive Quantization based Semantic Code for Generative Recommendation
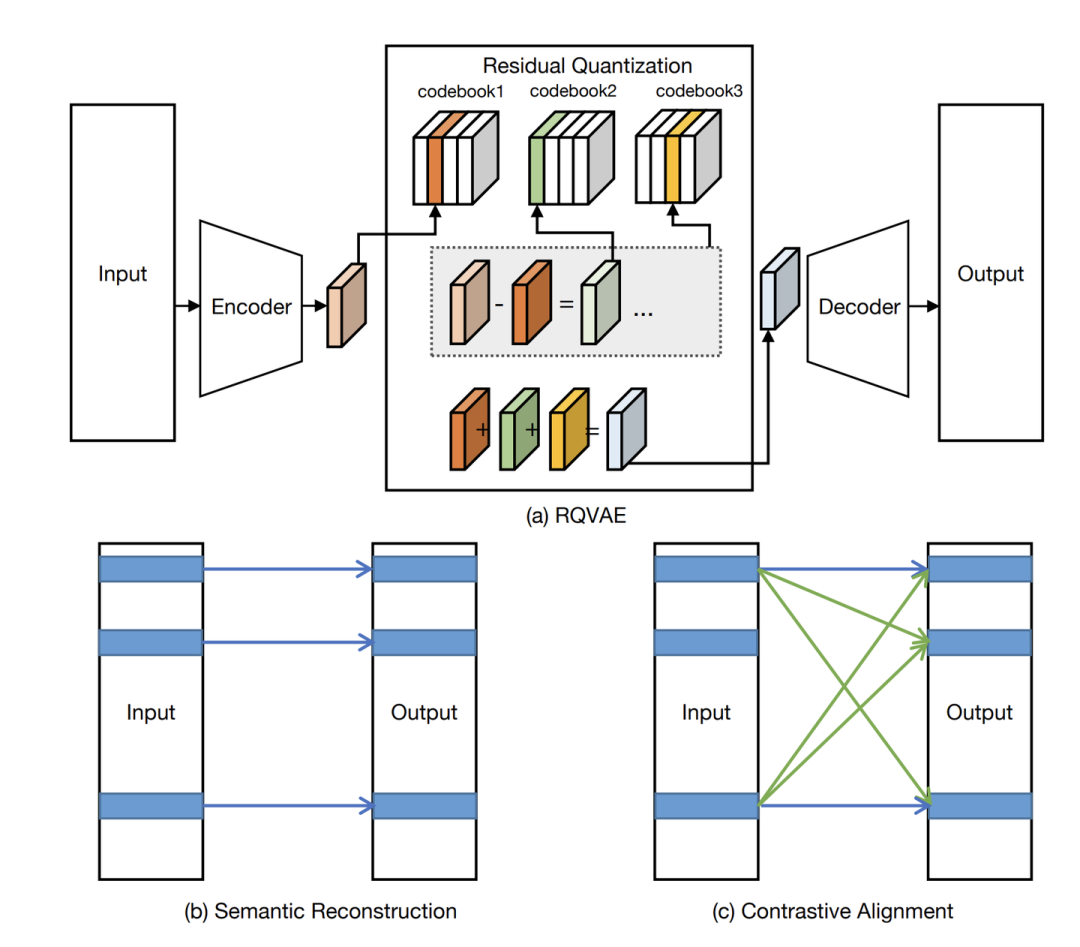
本文指出,现有的生成式推荐方法通常基于物品文本表征的重建量化来获取物品的离散编码,但这些方法未能精确捕捉到推荐系统中不同物品之间的差异性。为此,本文提出了一种新的方法,旨在语义信息的基础上,进一步考虑物品关系来构建物品的离散编码。
首先,本文利用预训练的语言模型来建模物品的文本表示。基于这些文本表示,采用了RQ-VAE方法来生成物品的离散编码。为了进一步学习物品之间的关系,本文提出了一种辅助的对比学习损失。具体而言,RQ-VAE的输入与重建输出作为正样本,并利用批内负采样得到负样本。这种方法使模型能够更有效地学习物品编码之间的差异,提升模型的判别能力。
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)



















 962
962

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









