







作者 | 九河之间
整理 | NewBeeNLP
https://zhuanlan.zhihu.com/p/4544607237
业界的超长序列建模方式,大都围绕着 两阶段GSU + ESU进行: 要么设计一套高效的GSU检索,要么围绕着GSU/ESU两阶段的目标一致性。序列长度也从起初的 千级别 发展到 万级别 ,甚至十万级别( 动辄就是LifeLong )。 试问长序列建模的下一步,往哪里走? 随着序列长度越来越长,计算复杂度Flops和工程挑战越来越大(Roi貌似变低了),收益 的临界点/边界收益点在哪里 ?
通过对 抖音/阿里/美团/微信/快手 近两年的调研发现 ,GSU的检索条件 大都围绕着Target及其Sideinfo展开,很少采用 用户侧、场景侧的信息作为检索条件,也缺乏对超长+超宽组合的全面认知和深入探索 。
首先,我们先回顾进两年各大厂的经典方案;之后探讨长序列建模的未来趋势。
1.微信视频-3层Attention级联跨域长序列建模[1] KDD'24
1.1 概要
Title : Cross-Domain LifeLong Sequential Modeling for Online Click-Through Rate Prediction
简介 :针对跨域LSM--①第一层采用内积,保证跨域信息相关 + 减少后面计算量;②第二层ID + sideinfo,引入足够多的辅助信息,计算更精准;③第三层 MHA,多头学习不同的表征空间
长度 :千级别(2千), 微信短视频和直播推荐
1.2 模型
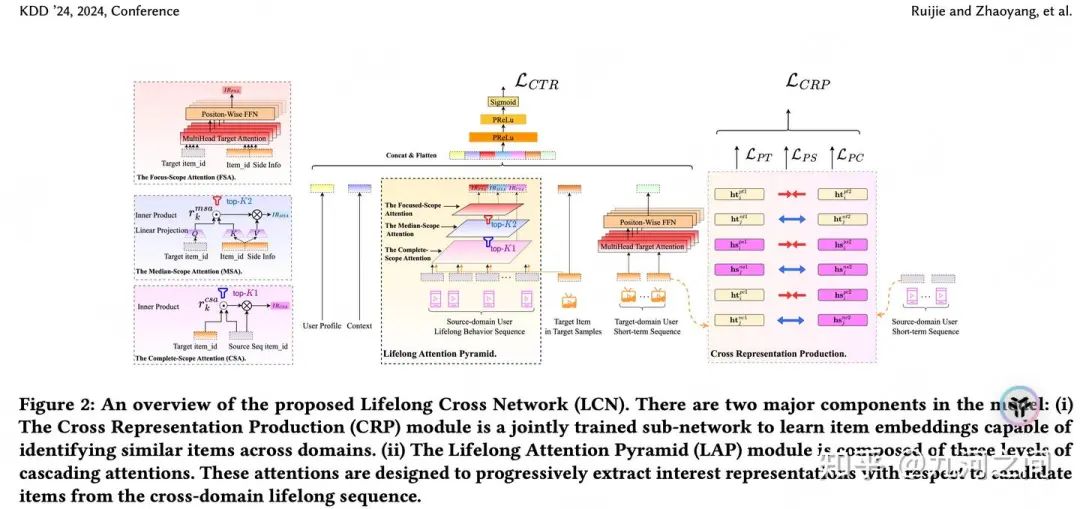
模型简介 :腾讯在kdd2024上发表了一遍关于跨域终身序列建模(模型名为LCN)的论文, 其主要是从源域(用户行为丰富,比如微信视频,数万个用户行为)中 提取 与 目标域(用户行为稀疏,比如微信直播,数百个用户行为) 相关的用户兴趣,以此捕捉目标域的用户兴趣 。其结构分为两部分:Cross Representation Production ( CRP-跨域表征对齐 )和 Lifelong Attention Pyramid ( LAP-分层Attention )。CPR是一个联合训练的子网络(构造对比学习loss,辅助训练),其目标是通过跨域连接item学习item embedding,以此增强从源域中的终身序列识别出与target item最相关的item的表达能力。LAP利用三个级联注意力层从长序列中逐级提取与目标item最相关的子序列,从而精准捕捉用户的兴趣。来自 feng:ctr预估-跨域终身序列建模(kdd2024腾讯)[2]
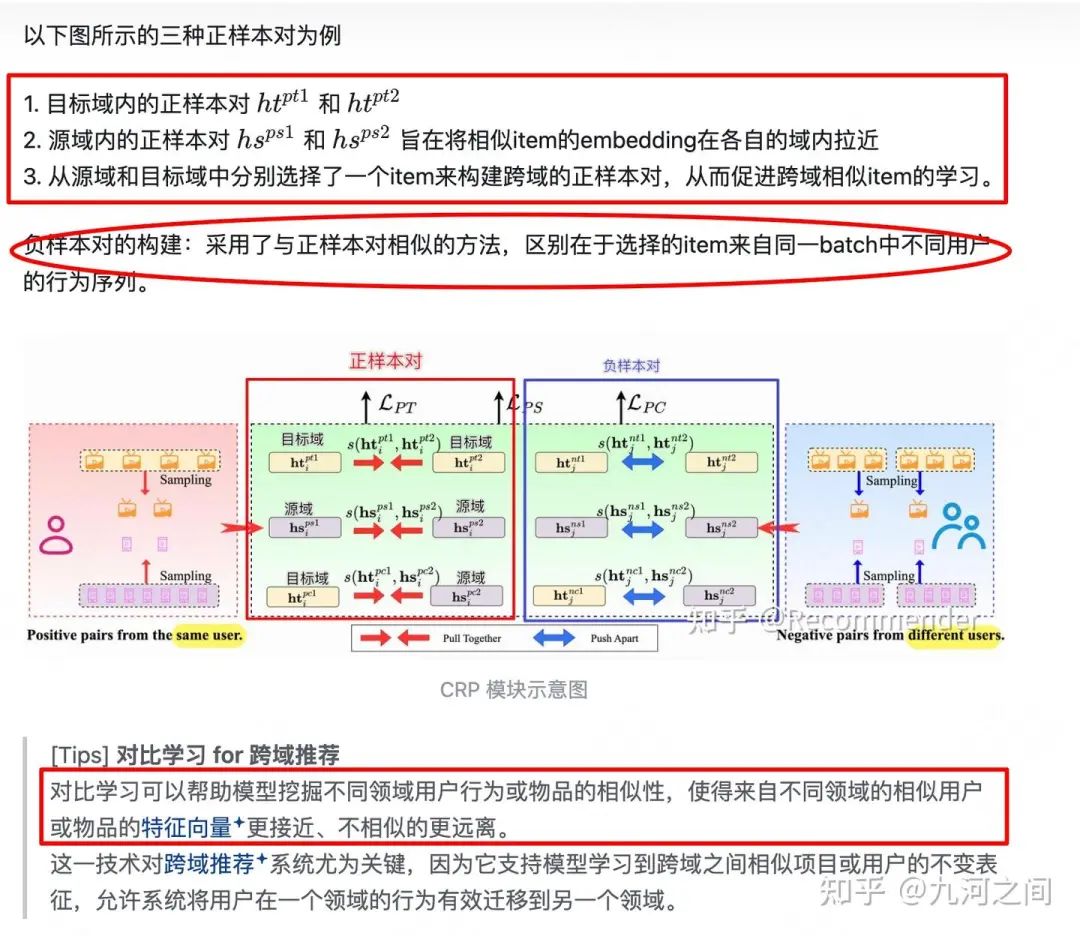
① GSU 的作用是筛选终身序列并识别与候选item最相关的item。它的有效性在很大程度上取决于所使用的item embedding的质量。以前的方法重复使用在模型训练期间学习的item embedding,这些embedding被证明在训练数据的分布中表现良好。但是, 当候选item和序列item属于不同域时,必须开发embedding来弥合源域和目标域之间的差距 。鉴于模型主要在目标域数据上训练,实现这一点并非易事。为了解决这个问题,作者提出了CRP结构,主要是利用对比学习的思想,构造源域和目标域的短期用户行为的正例、负例配对,以此增强跨域item之间关系的学习。
② 对比学习正样本对 和 负样本对的选取 (灵感来资源, 同一段较短时间内,用户的兴趣是一致的 ) Recommender:KDD 2024 - LCN:用于CTR预测的跨域长序列建模[3]
2.抖音视频-Trinity[4]:多兴趣/长期兴趣/长尾兴趣 KDD'24[5]
2.1 概要
Title : Trinity: Syncretizing Multi-/Long-tail/Long-term Interests All in One
简介 : 整合 推荐领域三大经典问题( 多兴趣/长期兴趣/长尾兴趣- 小众兴趣),且三者关联紧密,即这三者不是孤立的,而是你中有我我中有你的关系。举例说明,一个用户6个月前看了很多游戏和脱口秀视频,上个月看了跳舞和健身主题的视频,现在看了一些经济领域论文研究的视频。所以,① 游戏、脱口秀、舞蹈、健身、论文研究 都是用户的多种兴趣。② 游戏、脱口秀、舞蹈、健身 是用户的长期兴趣,虽然也可能被系统偶然的遗忘,但如果提供出来,用户依然会感兴趣。③论文研究 对于用户来说,是长尾兴趣(小众兴趣),因为对于绝大多数人来说是很难被吸引的。

长度 :千级别(2千5百),抖音 短视频和直播推荐 水哥:抖音兴趣建模新突破——Trinity:多兴趣/长期兴趣/长尾兴趣三位一体[6]
2.2 模型

3.美团广告-DGIN[7] 全生命周期用户行为DeepGroup兴趣
3.1 概要
Title : Deep Group Interest Network on Full Lifelong User Behaviors for CTR Prediction
简介 :① GSU的TopK方式 会导致信息的丢失(50个汉堡和50个可乐问题)-> 通过 GroupByItemID避免TopK丢失信息问题;② 单独使用用户life-long的点击行为,无法建模完整的用户兴趣-> 点后行为,多行为
长度 :万级别(10000), 美团本地生活 + 多行为
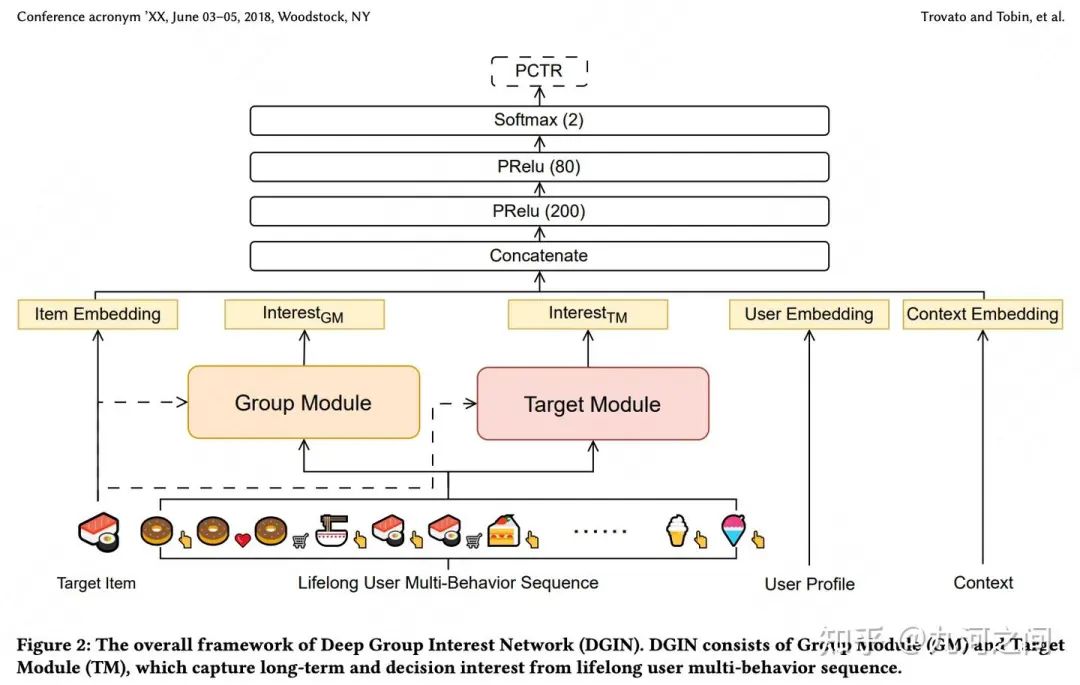
3.2 模型

4.美团外卖-基于上下文的快速推荐策略(简称CoFARS) WWW'24
4.1 概要
Title : Context-based Fast Recommendation Strategy for Long User Behavior Sequence in Meituan Waimai
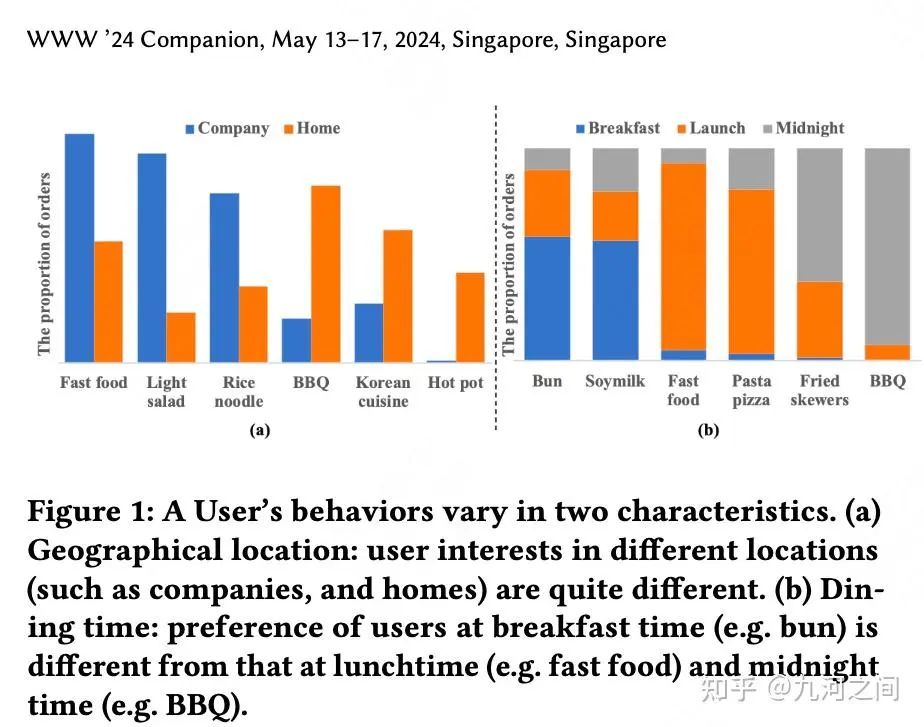
简介 :①序列推荐逐渐引入上下文Sideinfo信息,在美团外卖(或其它及时配送服务)业务中, 地理位置、就餐时间、天气以及假期 等诸多上下文特征对用户偏好产生了重大影响;②在某特定上下文中,用户偏好更准确地通过跨越地点属性(如类别、价格)的概率分布来体现
长度 :千级别(4千4百)过去3年的行为, 美团外卖长序列+场景Sideinfo
4.2 模型

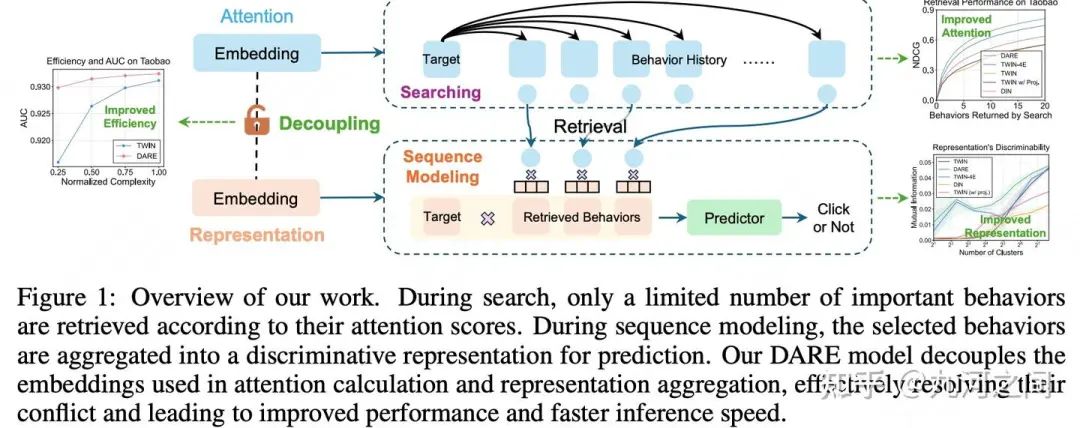
5.腾讯-GSU/ESU 解耦Embedding表示 Arxiv'2024
5.1 概要
Title : Long-Sequence Recommendation Models Need Decoupled Embeddings
简介 :① 解耦嵌入 是 指将Item的嵌入向量分解为多个部分 ,每个部分负责捕捉不同的特征或行为模式。可以有效地处理长序列数据。② GSU和ESU使用不同维度大小的embedding
长度 :百级别,数据集只有Taobao+TianMao的公开数据集, 偏研究?
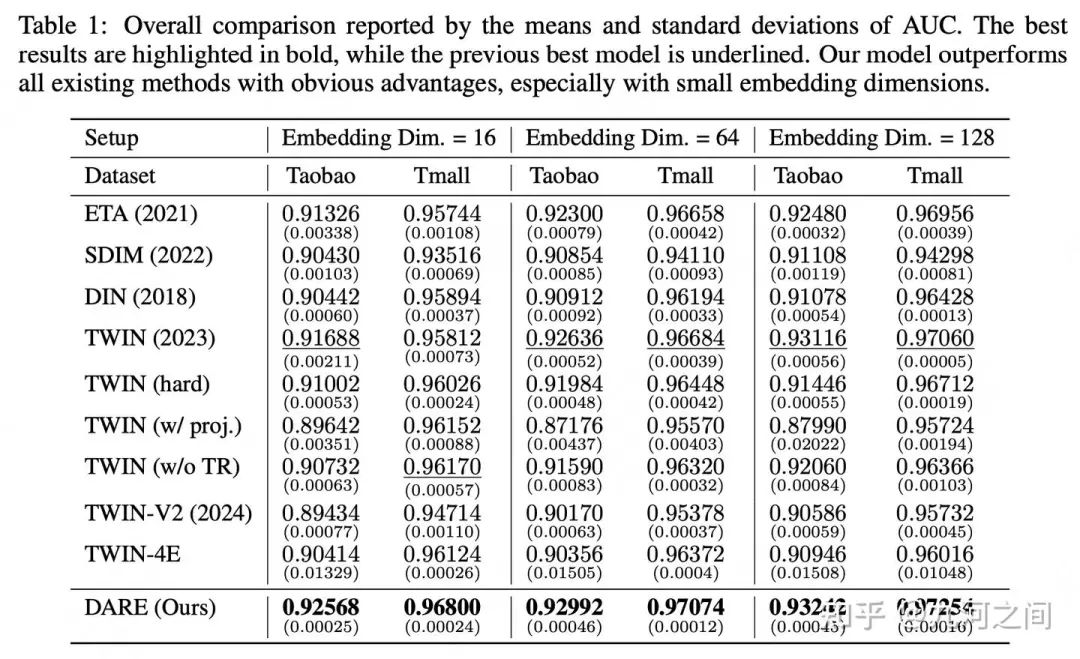
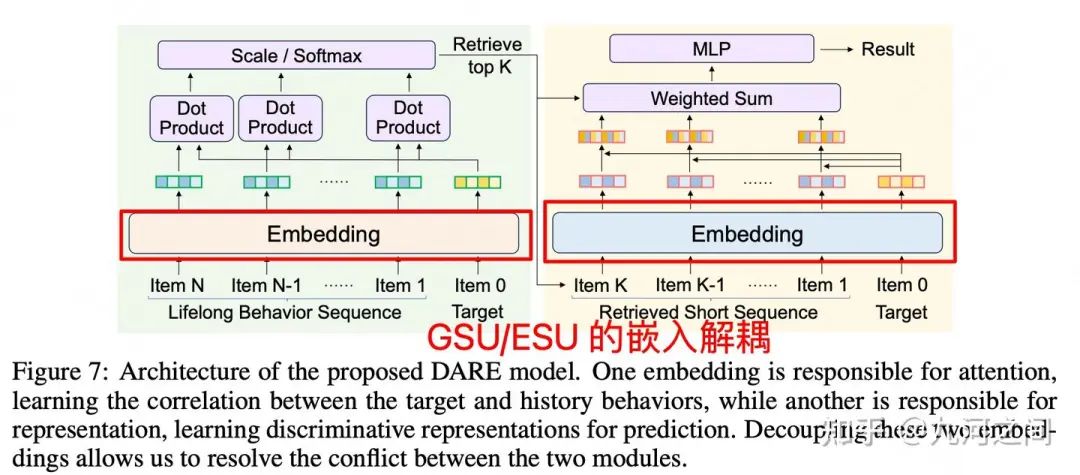
5.2 模型
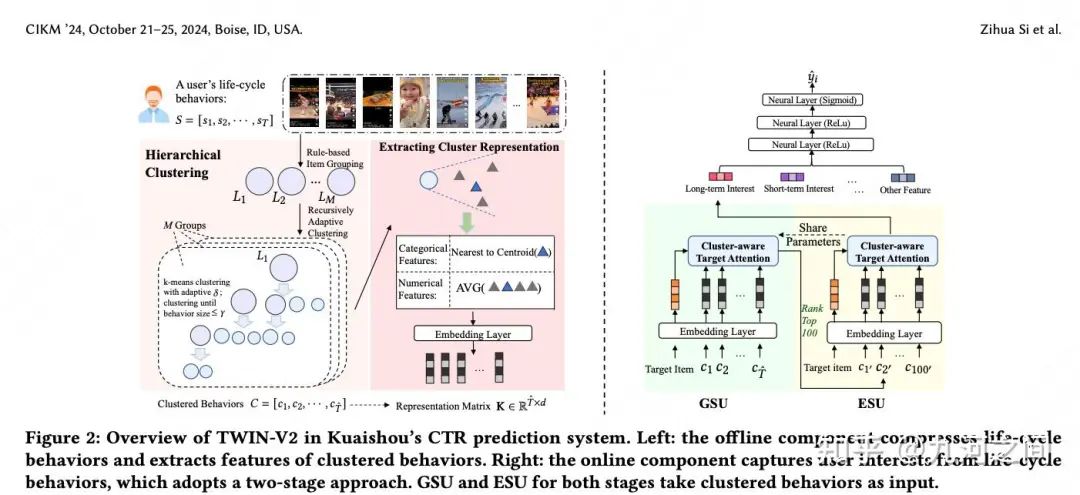
6.快手- TWIN/TWIN-2 KDD'23/CIKM'24
6.1 概要
Title : TWo-stage Interest Network for Lifelong User Behavior[8]Modeling in CTR / Scaling Ultra-Long User Behavior Sequence[9] Modeling for Enhanced CTR Prediction at Kuaishou
简介 :① 解决ESU和GSU存在一致性问题 。这里的一致性是说, GSU和ESU在序列Item与Target Item的相似计算方式上不一样, 从而导致GSU检索的top-k相似Item并不是ESU真正认为是相似的;② 首先是对用户life cycle的长序列基于简单规则方式(比如短视频播放完成率)做初步的分组, 再对每个分组内的Item做 层次聚类 。
长度 :万级/十万级, 快手商业化推荐 + TWIN-2多个Sideinfo整合
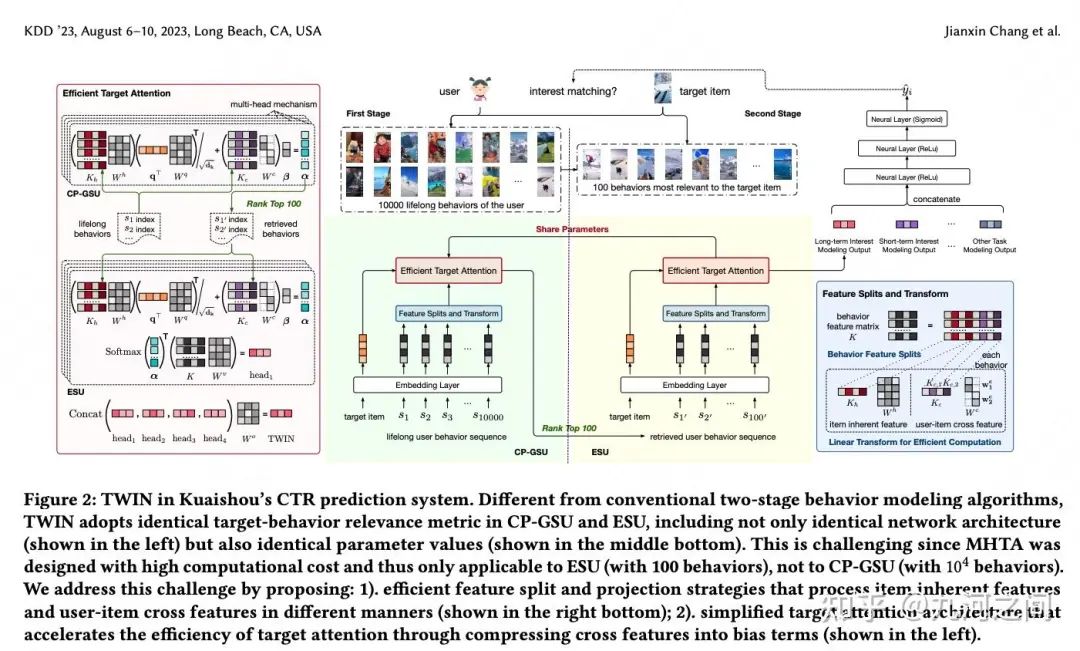
6.2 模型
在快手的短视频推荐场景, 即使是TWIN这种能覆盖10^5长度行为序列长度的GSU策略, 对于很多用户而言, 可能也只是不那么长时间(如3个月)的行为序列, 如果拉长时间到3年, 作者发现95%的用户的用户行为序列长度都是超过10^5量级的。
7.阿里SIM/ETA --早期经典范式 CIKM'20 / 21?
7.1 概要
Title : Search-based User Interest Modeling with Lifelong Sequential Behavior Data for Click-Through Rate Prediction / End-to-End User Behavior Retrieval in Click-Through RatePrediction Model
简介 :① SIM的长序列建模方案, 首次提出GSU泛搜索+ESU精准排序两阶段,但是 这两个阶段之间存 在一定的Gap : 1)基于Hard Search方法 两阶段的目标不一致 : Hard Search使用类目ID相同进行检索, 与CTR预估任务关系不那么直接;2)基于Soft Search方法两阶段模型的 更新频率不一 , CTR预估一般是在线学习方式持续更新的, 而Soft Search的embedding索引是离线(如天级/小时级)更新的。② ETA在GSU引入SimHash(一种局部敏感哈希(LSH)算法),实现端到端建模。
长度 :万级/十万级,阿里妈妈
7.2 模型
①离线训练时 , ETA会通过SimHash算法(事先随机选择m个hash函数),为打分商品和用户历史行为长序列生成Hash签名, 使用Int64来存储二进制签名, 通过汉明距离从中调选出top-k个Item, 用于后续的Target Attention计算, 这个过程是一个End-to-End的。
②在线推理时 , 会预先计算SimHash签名, 节省计算过程。在构建模型索引时, 通过Offline2Online的方式对Item表预计算, 并存储在Embedding lookup table中, 把生成签名的过程转化为在内存查表,大大减少计算复杂度。
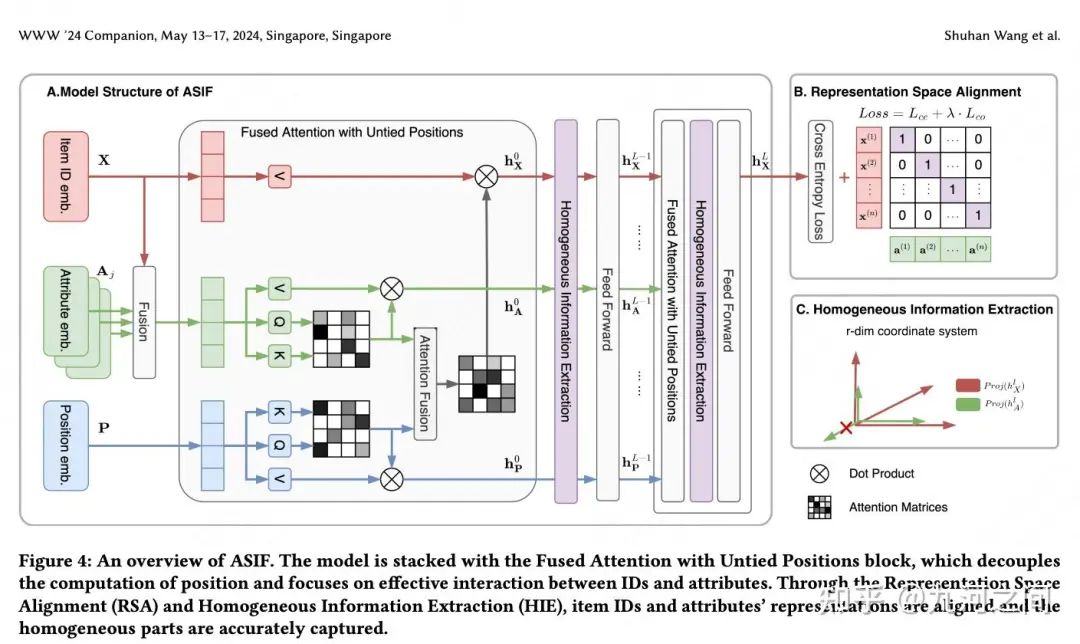
8.蚂蚁ASIF-序列推荐的对齐Side Info融合方法 WWW'24
8.1 概要
Title : Aligned Side Information Fusion Method for Sequential Recommendation[10]
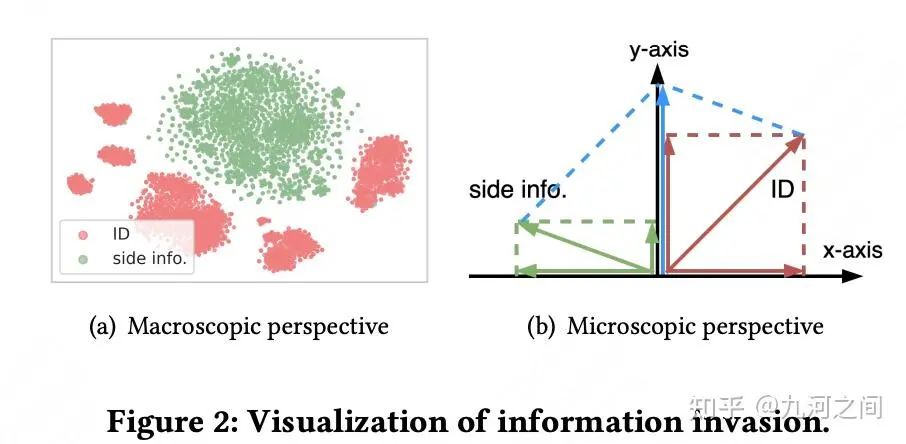
简介 :① Early Fusion: 将ID与Side Info在注意力计算之前融合, 但这种方式可能会干扰ID的学习(即 信息入侵 )从而带来负向影响。代表方法是SASRecF。② Late Fusion: 将ID与Side Info单独进行注意力计算, 在后期对两者的注意力做融合, 但这种方式缺少了ID和Side Info的有效交叉。代表方法有FDSA。③ Hybrid Fusion: Side Info仅参与到Attention Score的计算, 即只在Q和K中融合Side Info, V还是只使用ID, 在引入ID和Side Info交叉的同时, 也规避信息入侵风险。代表方法有NOVA, 但这类方法也存在一些缺点。
宽度 :如何 把Sideinfo加入Item_ID中 -- 蚂蚁支付宝会员场景(广告)。 ASIF的模型结构其实就是FDSA+NOVA+DIF 。position和ID弱相关所以单独建模,其他sideinfo正常交叉。

8.2 模型
表示对齐: 表示空间对齐(RSA)和同质信息提取(HIE) 。RSA方法在序列内的交互粒度上对成对的ID和属性使用对比目标,以确保它们的语义一致性。尽管这一操作使两个分布更接近,但仍无法避免异质部分的存在。因此,HIE对ID和侧信息进行正交分解,提取同质部分,从而避免信息入侵。
详细解读猫的薛定谔:www‘24「蚂蚁」序列sideinfo|Aligned Side Information Fusion Method for Sequential Recommendation[11]
8.3 宽的由来
简介 : 当ID频繁变化时,这种局限性就变得明显 。 但是像类别和品牌这样的属性提供了用户长期偏好的更稳定表示 。因此,我们的目标是将侧信息纳入推荐模型中以提升性能。
摆事实 :已有研究表明, 早期融合 可能不会总是提高性能,反而可能损害ID的表示,导致一种被称为信息入侵的现象[11]。另一方面, 晚期融合缺乏 ID和侧信息之间的交互,从而丢失了一些先验信息。因此,最近出现了一些混合融合方法。它们通过在注意力分数计算中纳入侧信息来避免信息入侵,并探索注意力相关性的有趣结构。
现有的混合融合缺点 :①ID和属性之间的 相关性有强/弱之分 ;②第二个缺点是 说ID和sideinfo的emb分布是不一样 的,直接丢弃或者直接融合都是不合理的,从最终表示中完全排除辅助信息以防止信息入侵的方法可能会无意中 丢弃辅助信息 本身中的关键信息。州懂:WWW'24 | 蚂蚁ASIF:序列推荐的对齐Side Info融合方法[12]
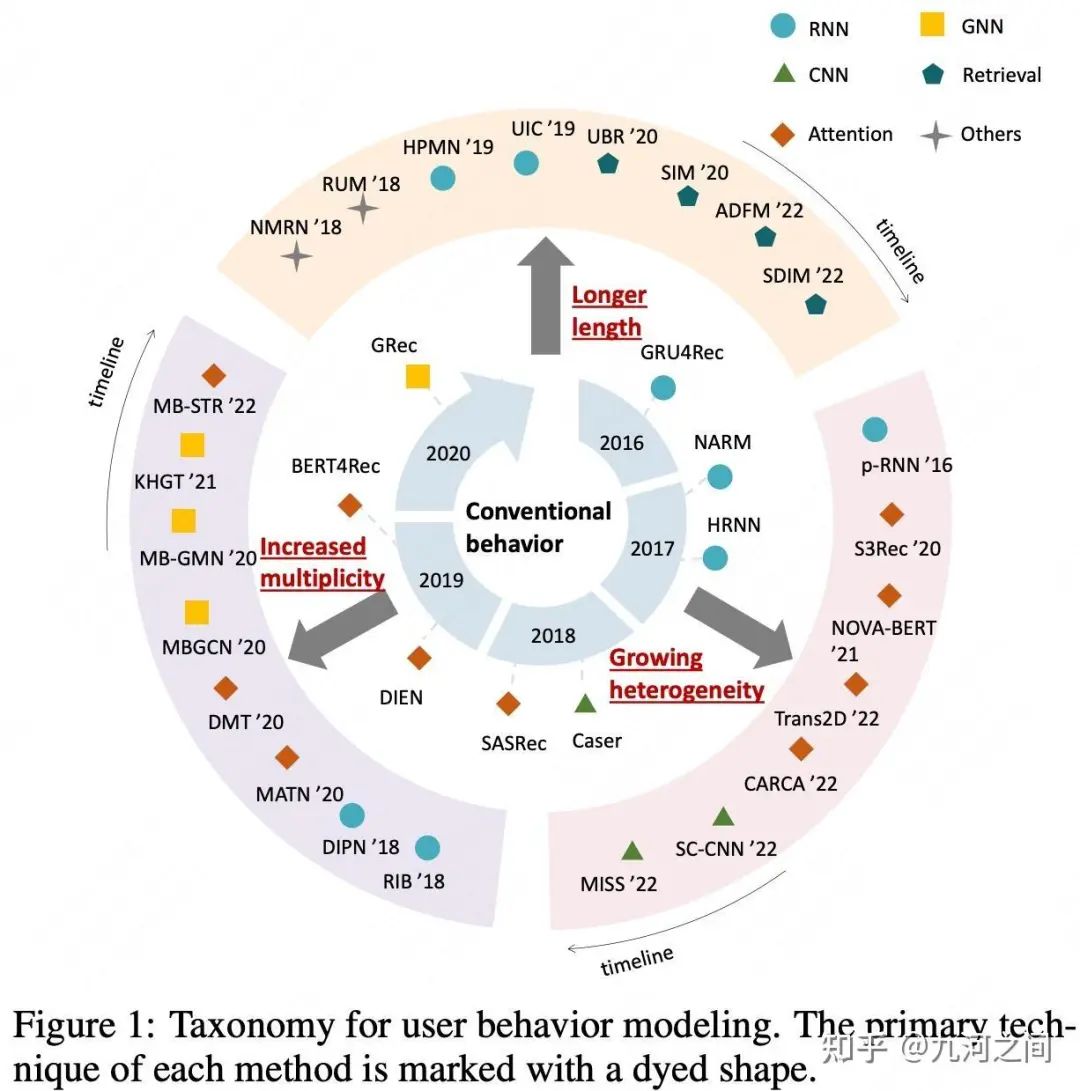
9.综述Survey-用户行为序列建模
9.1 概要
Title : A Survey on User Behavior Modeling in Recommender Systems
简介 :①对现有的UserBehaviorModel研究工作进行了系统的分类,可分为 Long长序列UBM、多行为类型UBM和带辅助信息(Sideinfo)UBM等方向 ② 在每个方向上,对代表性模型及其优缺点进行了全面的讨论与展望。
长度 :华为诺亚方舟团队 + UBM“长宽多”综述,非常不错的一篇综述,能够让我们系统性的认知UBM,详见 九河之间:推荐系统中用户行为建模综述|A Survey on User Behavior Modeling in Recommender Systems|华为[13]
9.2 模型
10.路在何方(更新中)
10.1 为什么做超长
业界为什么做(工业+学术)
我们为什么要做
超长可以做周期性建模、兴趣随时间演化、长尾兴趣建模、长短期兴趣/多兴趣等 ,特别是在DAU高的平台上更重要一些,1%的用户量级也非常大,值得去投入, 另一方面来说DAU高了说明主体优化的挺好,那剩下的目标不也就是优化这些边边角角 !!!
10.2 超长面临的核心问题
贴合业务的高效的检索模块GSU。
回顾了一篇UBM“长宽多”综述,非常不错的一篇综述,能够让我们系统性的认知UBM,详见 九河之间:推荐系统中用户行为建模综述|A Survey on User Behavior Modeling in Recommender Systems|华为[14]。
欢迎 各位拍砖~~~
10.3 长期VS短期
Title : 阿里/快手均发力-用户长期和短期兴趣建模 |CIKM|WWW(含AutoMLP/TWIN)
简介 : 阿里和快手同时发力用户长短期兴趣建模 , 而且Idea如出一辙, 可能意味着一种新信号--长短期兴趣建模对个性化推荐系统尤为重要:① 阿里CIKM2022年10月份,应用在 搜索场景 :短期兴趣的提取含有Query、和最近的触发行为;长期兴趣 采用短期兴趣做Target对用户长期行为序列进行提取而来 。② 快手WWW2022年4月份发表,应用在 推荐Feed流场景 :短期兴趣采用最近的触发作为Query;长期兴趣采用另外一种Query。
长期兴趣VS短期兴趣:用户的长期兴趣和短期兴趣,一个是 稳定的多兴趣 ,一个是 及时的瞬时兴趣, 两者如何关联交互是一个非常值得探讨的问题~ 详细的请见九河之间:阿里/快手均发力-用户长期和短期兴趣建模 |CIKM|WWW(含AutoMLP/TWIN)[15]
10.4为什么加Sideinfo
第一问,业界为什么要加入sideinfo,业界加入sideinfo有什么增量信息吗?① sideInfo具有泛化/抽象能力,比如Tag/Keywords,甚至文本name/品论。② 丰富的上下文信息 ,天气/热点事件/节假日/优惠等,比如同样的点击行为,不同的上下文信息,可能代表不同的意图。
第二问,怎么加入Sideinfo,加多少个辅助信息?
欢迎 各位拍砖~~~
一起交流
想和你一起学习进步!『NewBeeNLP』目前已经建立了多个不同方向交流群(机器学习 / 深度学习 / 自然语言处理 / 搜索推荐 / 图网络 / 面试交流 / 等),名额有限,赶紧添加下方微信加入一起讨论交流吧!(注意一定o要备注信息才能通过)

本文参考资料
[1]
3层Attention级联跨域长序列建模: https://arxiv.org/pdf/2312.06424
[2]feng:ctr预估-跨域终身序列建模(kdd2024腾讯): https://zhuanlan.zhihu.com/p/713282082
[3]Recommender:KDD 2024 - LCN:用于CTR预测的跨域长序列建模: https://zhuanlan.zhihu.com/p/5305958478
[4]Trinity: https://zhuanlan.zhihu.com/p/681751105
[5]多兴趣/长期兴趣/长尾兴趣 KDD'24: https://arxiv.org/pdf/2402.02842
[6]水哥:抖音兴趣建模新突破——Trinity:多兴趣/长期兴趣/长尾兴趣三位一体: https://zhuanlan.zhihu.com/p/681751105
[7]DGIN: https://arxiv.org/pdf/2311.10764
[8]Lifelong User Behavior: https://arxiv.org/pdf/2302.02352
[9]Ultra-Long User Behavior Sequence: https://arxiv.org/pdf/2407.16357v2
[10]Aligned Side Information Fusion Method for Sequential Recommendation: https://dl.acm.org/doi/pdf/10.1145/3589335.3648308
[11]猫的薛定谔:www‘24「蚂蚁」序列sideinfo|Aligned Side Information Fusion Method for Sequential Recommendation: https://zhuanlan.zhihu.com/p/698104193
[12]州懂:WWW'24 | 蚂蚁ASIF:序列推荐的对齐Side Info融合方法: https://zhuanlan.zhihu.com/p/747379148
[13]九河之间:推荐系统中用户行为建模综述|A Survey on User Behavior Modeling in Recommender Systems|华为: https://zhuanlan.zhihu.com/p/617751027
[14]九河之间:推荐系统中用户行为建模综述|A Survey on User Behavior Modeling in Recommender Systems|华为: https://zhuanlan.zhihu.com/p/617751027
[15]九河之间:阿里/快手均发力-用户长期和短期兴趣建模 |CIKM|WWW(含AutoMLP/TWIN): https://zhuanlan.zhihu.com/p/613110137


















 826
826

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









