






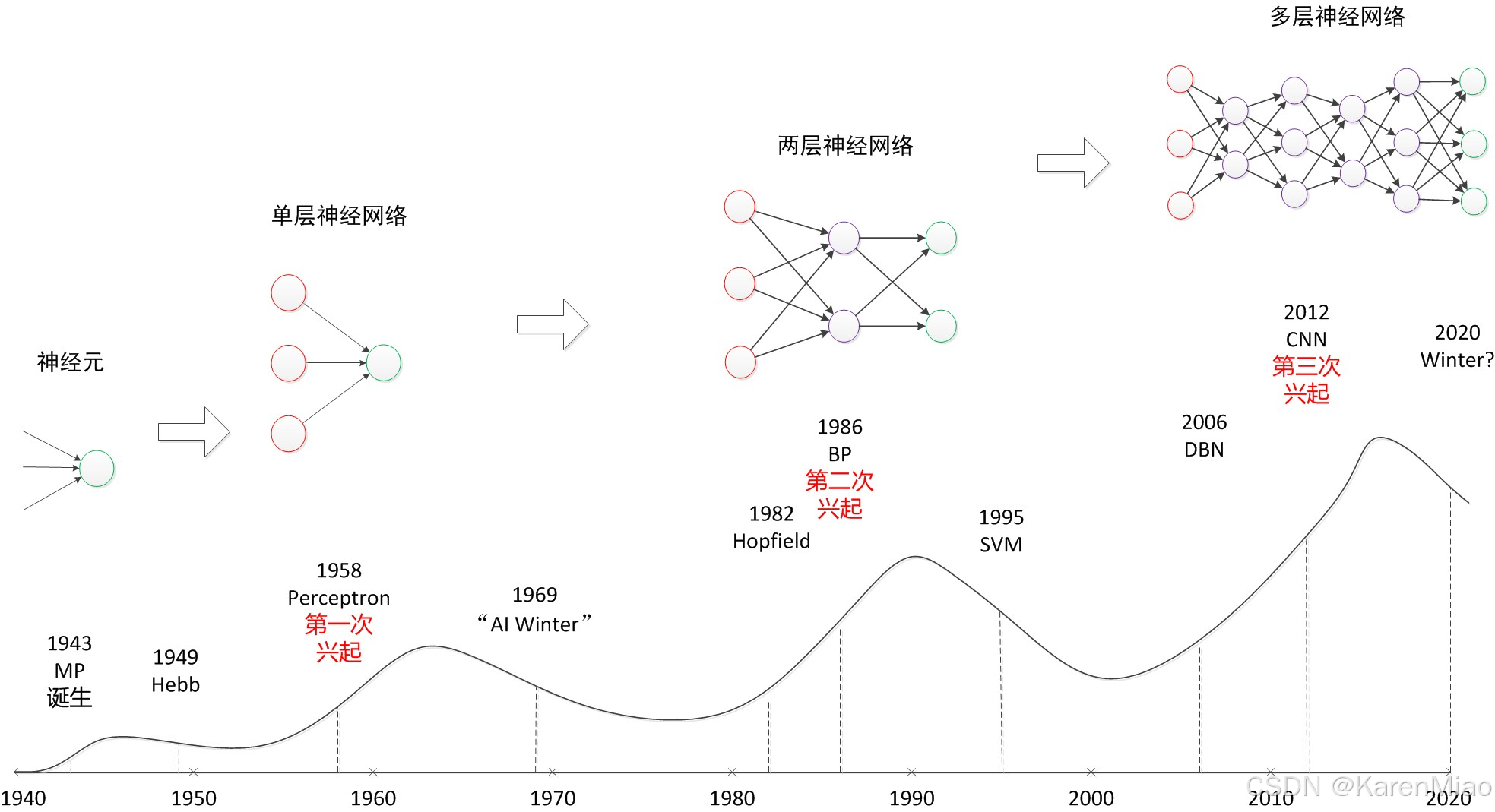
历史进程
神经网络的概念可追溯到上世纪40年代,当时被认为是一种模拟大脑神经元网络的计算系统。
1940年代,麦卡洛克(McCulloch)和沃尔特·皮茨(Walter Pitts)率先提出了受人类大脑和生物神经网络启发的人工神经网络。
1951年,马文·明斯基(Marvin Minsky)和同学一起建造了世界上第一台神经网络计算机,并将其命名为SNARC(Stochastic Neural Analog Reinforcement Calculator),目的在于学习如何穿过迷宫。SNARC系统标志着第一个计算机化的人工神经网络。

1958年,弗兰克·罗森布拉特(Frank Rosenblatt)与美国海军等政府部门合作,开发了一种基于神经网络概念的感知机。当时,《纽约时报》和《纽约客》都浓墨重彩地报道了这件事。美国军方大力资助了神经网络的研究,并认为神经网络比“原子弹工程”更重要。这段时间直到1969年才结束,这个时期可以看作神经网络的第一次高潮。

1960年代,多层结构的发现开启了新的可能性,导致了前馈神经网络和反向传播的发展。
前馈神经网络是一种人工神经网络,信息从输入层通过隐藏层传递到输出层,没有任何循环或反馈连接。
反向传播是一种神经网络的训练算法,它通过网络计算和分配误差梯度,从而在学习过程中有效地调整网络的权重。
1962年,弗兰克·罗森布拉特在1962年引入"反向传播误差校正"一词。但真正的实现是由保罗·韦尔博斯(Paul Werbos)完成的,他在1974年描述了误差反向传播*。
误差反向传播是一种在神经网络中用来调整神经元连接权重的方法,通过从输出层向输入层传播误差,使网络能够学习和改进预测。
1960年代,马文·明斯基(Marvin Minsky)和西摩·派普特(Seymour Papert)证明了感知机在解决某些类型问题上的局限性,他们认为单层神经网络无法处理“异或”电路,其次,当时的计算机缺乏足够的计算能力,满足不了大型神经网络长时间运行的需求。导致神经网络研究资助的减少。神经网络研究经历了进展与挫折。
1969年,马文·明斯基(Marvin Minsky)和西摩·派普特(Seymour Papert)证明了感知机在解决某些类型问题上的局限性,他们认为单层神经网络无法处理“异或”电路,其次,当时的计算机缺乏足够的计算能力,满足不了大型神经网络长时间运行的需求。神经网络和深度学习技术的研究因此迅速陷入了低谷,70年代则成为了“人工智能的寒冬”。
1979年,福岛邦彦(Kunihiko Fukushima)引入了卷积神经网络CNN,如Neocognitron,通过分层多层架构识别视觉模式。后来,CNN和反向传播的结合对深度学习产生了重大影响。

卷积神经网络是一种深度学习模型,专门设计用于处理和分析视觉数据,利用专门的卷积层进行特征提取和空间层次结构。
1982年,正在读研究生的杰弗里·辛顿(Geoffrey Hinton)(2014年加入谷歌的人工智能专家)和佛大学神经生物学博士特里·谢伊诺斯基(Terry Sejnowski)在一场研讨会上相识,随后几年,从并行分布处理方法起步,他们创造了新的多层神经网络“玻尔兹曼网络”。这项研究也证明,明斯基的《感知机》一书中所做的预言,即感知机无法被推广至多层网络,是完全错误的。
(实际上,在进入80年代后,《感知机》一书提到的两大问题都已得到解决。一方面,摩尔定律的应验使计算机处理能力飞速提升,计算能力不再成为制约神经网络的因素。另一方面,反向传播算法的提出解决了关于“异或”电路实现的难题。 然而,明斯基仍不看好神经网络和深度学习技术。2007年,在新书《情感机器》出版的不久后,《Discover》杂志的苏珊·克鲁格林斯基(Susan Kruglinski)对明斯基进行了采访,他再次重申了自己的观点。)
1986年,戴维·拉姆哈特(David Rumelhart)、杰弗里·辛顿(Geoffrey Hinton)和罗纳德·威廉姆斯(Ronald Williams)在1986年发表了具有影响力的论文《通过反向传播误差学习表示》,神经网络的应用得以推广。
1970年代末和1980年代初,人工智能与机器学习分道扬镳(不用担心,它们后来会重新联合)。
- 人工智能专注于符号推理,而缺乏学习能力;
- 机器学习则更专注于从数据中进行统计学习。
1980年代末至1990年代,新算法、方法和方法的探索与发现以令人眼花缭乱的速度推进。80年代末,一名叫Dean Pomerleau的CMU研究人员用神经网络构建了一辆可以上路的自动驾驶汽车。LeCun在上世纪90年代用这项技术构建了一个可以识别手写数字的系统,之后被银行应用。
- 1989年,杨立昆(Yann LeCun)在贝尔实验室展示了反向传播的实际应用,将卷积神经网络与反向传播相结合,用于识别手写数字。这是第一个端到端训练的神经网络在现实世界中的应用。
- 统计语言模型(SLM)取得了显著进展。SLM估计词串的可能性或概率,并在自动语音识别、机器翻译和亚洲语言文本输入等应用中发挥重要作用。
- 计算能力的增加和新ML算法的使用,主要集中于统计模型,推动了自然语言处理(NLP)的发展。
- 支持向量机(SVM)由弗拉基米尔·瓦普尼克(Vladimir Vapnik)及其在AT&T贝尔实验室的同事们开发,因其处理高维数据和非线性决策边界的能力而在分类任务中广受欢迎。SVM对比神经网络的优势:无需调参、高效、全局最优解。
- 贝叶斯网络在1990年代作为一种概率推理和决策的图形模型获得了广泛关注。研究人员关注网络结构和参数的学习以及高效推理算法的开发。
- 集成方法,包括袋装和提升等技术,在1990年代流行起来。这些方法旨在通过结合多个模型来提高预测性能。
- 长短期记忆(LSTM)是一种用于语音识别的深度学习技术,由于尔根·施米德胡伯(Jürgen Schmidhuber)和塞普·霍赫赖特(Sepp Hochreiter)在1997年描述。LSTM能够学习需要记住数千步以前发生事件的任务,这对语音处理至关重要。
由于计算力和可用数据的缺乏,神经网络再次进入寒冬。
当时,神经网络规模小、不稳定且不可靠,训练时间长。基于以上种种理由,SVM迅速打败了神经网络算法成为主流。神经网络的研究再次陷入了冰河期。当时,只要你的论文中包含神经网络相关的字眼,非常容易被会议和期刊拒收,研究界那时对神经网络的不待见可想而知。
1999年,图形处理单元(GPU)得到了发展,深度学习取得了重大进展。GPU在十年内将计算速度提高了1000倍,使神经网络能够与支持向量机竞争。

- 大数据的出现(大数据需要满足三个核心属性:体量、速度和多样性)通过提供来自社交媒体和传感器等多种来源的海量数据集,改变了格局。ML算法利用这些数据集进行训练,从而发现复杂模式并提高预测准确性。
- 数据存储和处理技术的进步,如Hadoop和Spark等,促进了大规模数据集的高效处理和分析。这些发展导致了深度学习算法的出现,这些算法能够从大规模数据中学习,并提供高度准确的预测。
2000年代至2018年:NLMs、Word3Vec、注意力机制、以及首个预训练语言模型
- 神经语言模型(NLMs)引入了一种新的表示和理解语言的方法,摆脱了传统的统计方法。
词嵌入是单词的密集向量表示,捕获了语义和句法关系,使机器能够理解和推理自然语言处理任务中的语言。
与将单词视为离散单元的统计模型不同,神经模型将单词编码为高维空间中的向量。相似的单词在此空间中彼此靠近,使得模型能够从一个单词推广到类似的单词。这是一个非常重要的进步!
Bengio等人的神经概率语言模型(2003年)是神经语言模型的先驱之一。它引入了学习分布式单词表示和单词序列的概率函数的概念,这在当时是一个开创性的想法。该模型为更先进的神经语言模型的发展铺平了道路。
- Word2vec 架构彻底改变了捕捉单词之间语义和句法关系的方法,它通过在密集向量空间中表示单词而不是稀疏高维空间中表示单词,解决了统计模型面临的维度问题。
- 注意力机制。尽管以前关注机制通常与循环网络一起使用,但2017年发表的研究论文《注意力就是你需要的一切》引入了Transformer架构,它完全依赖于一个关注机制来捕获输入和输出之间的全局依赖关系。由于LLMs的出现,这篇论文可能成为最为人熟知的之一。这种机制在捕捉文本中的长距离依赖关系方面特别有效。与传统模型(如RNN和LSTM)不同,它们在处理更长序列时表现出色,Transformer在直接关注任何位置的输入上擅长,无论其与当前位置的距离有多远。因此,Transformer可以处理更大的文本序列,并捕获跨越广泛间隙的依赖关系。
序列到序列(seq2seq)模型中的注意力机制帮助模型在生成连贯输出时关注输入序列(单词、数字等)的重要部分。通常用于机器翻译、文本生成、问答等领域。
Transformer模型的另一个显著优势是其可并行化性。与RNN和LSTM中的顺序处理不同,Transformer可以同时处理序列中的所有位置,利用现代硬件的计算效率,例如针对并行计算进行优化的GPU。
此外,Transformer模型引入了位置编码技术,一种传达序列中单词相对位置信息的技术。这弥补了Transformer由于其并行性质而缺乏固有顺序理解的缺陷,与RNN和LSTM不同。
Transformer模型为随后的NLP模型奠定了基础,包括BERT、GPT-2、GPT-3和其他现代语言模型。这些模型进一步发展和扩展了Transformer架构,显著提高了各种任务的性能。Transformer模型和注意力机制在NLP中的影响是无法估量的。
- 预训练模型是NLP领域的重大发展。它们是深度学习和大规模数据集可用性的结果。
ELMo(来自语言模型的嵌入)是早期尝试之一,旨在捕捉上下文感知的单词表示。 ELMo不依赖于固定的单词表示,而是预先训练了一个双向LSTM(biLSTM)网络。然后,biLSTM网络被针对特定的下游任务进行微调。
另一个重要的预训练模型是BERT,它建立在可并行化的Transformer架构和自注意机制之上。BERT通过对大规模未标记语料库使用特殊设计的任务进行预训练,进一步推动了预训练双向语言模型的概念。由此产生的上下文感知的单词表示已被证明是高度有效的通用语义特征,极大地提升了NLP任务的性能。
ELMo和BERT的成功激发了**“预训练和微调”**学习范式的进一步研究和发展。这种方法彻底改变了NLP,提供了强大的预训练模型,可以根据不同的应用进行定制和微调。出现了许多关于预训练语言模型(PLMs)的研究,引入了不同的架构,如GPT-2和BART,以及改进的预训练策略。
2011年左右,谷歌启动了Google Brain项目,而最初的项目负责人吴恩达是深度学习领域的专家。利用来自YouTube的上千万数字图像,谷歌的神经网络进行了自我训练,而学习效果超过了此前所有项目。由于YouTube上大量关于猫咪的影像,这一系统甚至自己学会了识别小猫。科学家将这种机制形容为大脑视觉皮层控制论的“表亲”。这一实验采用了1.6万颗处理器构成的神经网络集群,但与人脑的数十亿个神经元相比,这只是九牛一毛。
神经网络的发展背后的外在原因可以被总结为:更强的计算性能,更多的数据,以及更好的训练方法。只有满足这些条件时,神经网络的函数拟合能力才能得以体现。
关键人物
2018年图灵奖获得者:
- Geoff Hinton:多伦多大学计算机系教授,深度学习之父,深度学习开山鼻祖,BP算法创始人,目前加入Google搞Google Braih.
- Yann Lecun:Facebook任人工智能研究室主任,Hinton的博士后,创立CNN.
- Yoshua Bengio:在蒙特利尔大学潜心学术界,Michael Jordon的博士后,主要贡献attention以及GAN,当前学习DL有力的工具PyLearn2和Theano都是出自他的实验室.

图片从左到右分别为:Yann LeCun, Geoffrey Hinton, Yoshua Bengio, Andrew Ng
其他超级大牛
- Andrew Ng(吴恩达):Stanford计算机副教授& Al Lab主任,师从Michael Jordon并且是其“得意门生”,Google Brain之父
- Michael Jordon: UC Berkey的统计学和ML的双料教授,一手开创统计机器学习这个领域.
- Jurgen Schmidhuber:RNN, LSTM之父
- 李飞飞:斯坦福Al lab主任,领导谷歌AI中国中心,计算机视觉领域的著名专家,创立全球最大的图像识别数据库:Caltech 1017||mageNet


















 567
567

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









