







word2vec是一个无监督算法,广泛用于NLP领域中,但是其整体的向量化思路是可以用与其他序列问题中的。word2vec适合的情况就是对于一个序列的数据,在序列局部数据间存在着很强的关联。文本中邻近的词之间关联很强,一个词语的含义可以由其上下文直接推断出来,所以在文本中应用较广泛。近些年来,一些研究者发现,在线用户行为的时间序列数据同样也可以起到上下文的作用,即当用户浏览并和不同内容进行交互时,当前交互的内容可以由其前后的行为进行向量化表示。因此可以用word vector模型来对商品、内容、广告等进行有效的向量化表示,这个在Airbnb中就已经实现了。
除了上述所说在序列数据上的表现之外,word2vec还有一个很好的特性:其本身的层次分类器或者采样方式实际上对热门item做了很大的惩罚,所以不会像一半的矩阵分解一样,最后算出来语义接近的都是热门词。word2vec的一个非常成功的应用场景是应用在用户app下载序列上,根据用户下载App的顺序,把App看做单词,训练每个App对应的向量,用这个向量计算App之间的相似度,这样能把真正内容相关的App聚合在一起,同时规避热门App的影响,在商品点击序列上也有类似的效果。
用户对于某个物品的相关行为会encode很多与物品相关的属性进去,这些属性是很难用直接的方式去显性衡量的。就比如说,Airbnb中,"architecture,style and feel"这个属性你要怎么定义?而word2vec算法能够有效地抽取出这些隐藏的属性,可以进行比较、分类,因此推荐效果更好。这套方法在Yahoo的广告CTR预估中有9%的提升,在Airbnb的物品CTR预估中有21%的提升。下面举4个具体的应用场景来详细描述:
1.在Spotify和Anghami中的音乐推荐(具体参考博文:https://towardsdatascience.com/using-word2vec-for-music-recommendations-bb9649ac2484)
在音乐推荐中,模型推荐效果对比情况如下:

vector_exp是Spotify自行研发的一个算法,只知道是基于BOW模型,这个目前没有找到相应的文档。word2vec就是Google的那个word2vec,子采样率为5%,RNN用到的是用户的playing track session序列数据,每个层40个节点,使用层次softmax作为最终的输出层,并使用dropout作为正则的一种手段。LDA是定了topic数为400,在Hadoop上执行。这些算法并不都适用于工业界生产,LDA和pLSA效果都不太好,RNN和word2vec考虑了序列的因素。
把word2vec应用在这个场景中有一个假设:用户倾向于听类似的歌曲(users will tend to listen to similar tracks in sequence)。

这里,每首歌即相当于一个单词,一个用户的listening queue作为一个句子,然后用word2vec的思路进行每首歌的词向量的训练。这样就把音乐推荐问题转换成在相似语境下最有可能共现的歌曲。这些训练好的词向量可以用余弦相似度来查找相似歌曲,也可以用来生成音乐品味“music taste”或者说是“listening habit”,很简单,把一个用户所有听过歌曲的向量做平均即可得到music taste的向量,用一个vector来表示一个用户,然后就可以找到该用户的相似用户,或者说用这个平均后的vector找和它距离最近的几个歌曲,推给用户。
2.在Airbnb中的listing推荐(具体参考博文:https://medium.com/airbnb-engineering/listing-embeddings-for-similar-listing-recommendations-and-real-time-personalization-in-search-601172f7603e)
在这个场景中的用户行为数据是一系列的用户点击数据,即用户浏览的listing序列。当用户浏览一个home的时候,用户的下一个行为要么是继续浏览相似的home,要么是返回搜索结果,在浏览相似home的时候,就可以用这个word2vec的方法进行推荐。

我们假设获取到了N个用户的点击session(每个session都以最后用户book某个listing为结尾,这样的话整个模型不仅能提高listing的点击率,还能提高最后的转化率),每个session s = (L1, L2, ..., Ln)∈S是用户在一个session中的点击序列。当时间gap超过30分钟时,开启一个new session。目标是对每个listing用一个32维的浮点数向量进行表示,最终用32维进行表示是对效果和内存占用率的一个tradeoff。内存占用越低,在线实时计算速度越快。示意图如下:
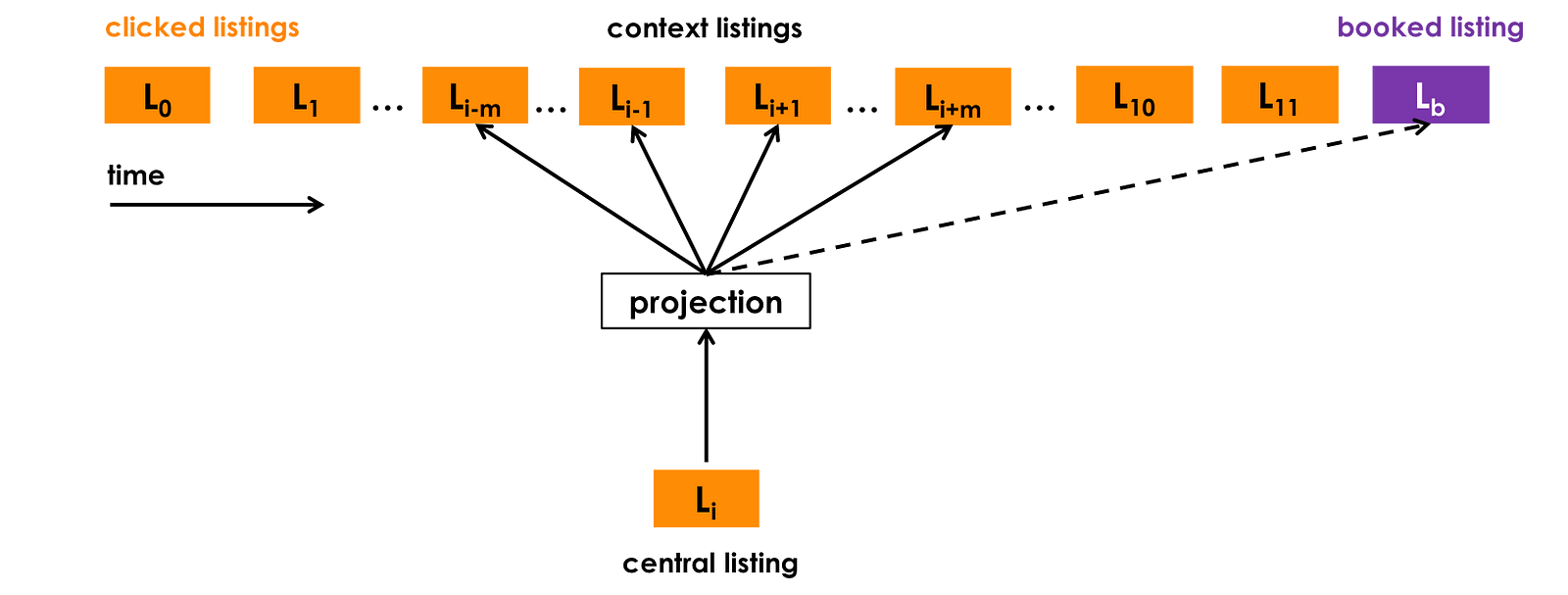
在原始的word2vec训练时,用到了一个小trick——负采样,Airbnb在将这个模型应用到自己的业务场景的时候,把这个负样本的范围进行了限定。比如说一个用户想在Paris租房,那么这个负样本应该是在Paris的负样本,而不要出现New York的负样本。对于推荐中的冷启动问题(每天都有新的listing上线,怎样在没有和这个listing相关的用户行为数据的前提下学习new listing的vector),直接将与该new listing地理位置最近的三个listing的向量做一个平均来作为这个new listing的初始向量。这些向量是用来解决相似listing的问题。在线实时推荐的时候,目标是要尽可能多地给用户推他可能喜欢的listing,尽可能少地推他不喜欢的listing。要完成这个目标,对每个用户使用Kafka实时搜集一下两个短期历史行为信息:
Hc:用户在最近两周内点击的listing id。
Hs:用户在最近两周内skip掉的listing id。这里对被skip掉的listing定义为那些rank很高,但是用户并未点击该listing,而是点击更低位置的listing的那些listing。
然后,每次用户进行搜索的时候,对候选listing集中的每个都计算两个相似度:EmbClickSim,即该listing与Hc的相似度,公式如下:

和EmbSkipSim,即该listing与Hs的相似度,公式如下:
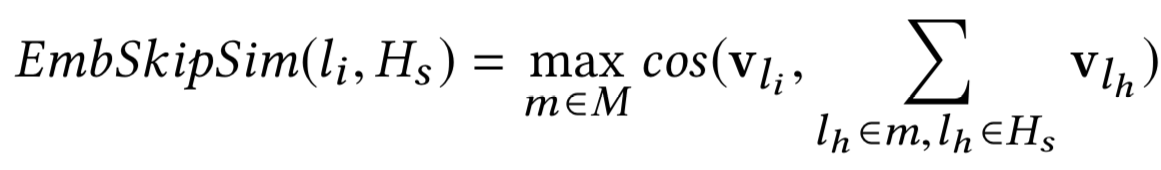
用这两个相似度度量作为排序的一个依据。
3.在Yahoo邮箱中的商品推荐(paper地址:https://arxiv.org/pdf/1606.07154.pdf)
国外的用户有这么个特点:买完东西之后会收到一封邮件。那么我们就可以根据这些邮件来学习商品的特征向量。

在这里,用户的行为数据就是从邮件中抽出来的商品购买序列。涉及到一个假设:购买者经常按序购买相关物品,即同时买一些相关的商品(如camera和lens),或者说买这些东西为了完成某一个任务(如要去郊游的东西)。用户的购买序列同时也会反应出购物者的品味,A和B风格相似,那么购物者买了A的话,很可能也会对B感兴趣。这可能有点诡异,因为在日常生活中,我们买的东西并不一定是相关联的,但是模型终归是由用户的行为数据决定的,如果两个东西是相关的,则会有很多用户会同时购买这两个东西,反之,不相关的两个东西被同时购买的可能性会小很多。
雅虎在用这个模型的时候,有一些创新。在他们的应用场景中,用到了聚类来提升推荐的多样性。在学习完商品的向量之后,把这些向量聚类成各个群,然后根据用户刚刚购买的东西进行推荐,并不推荐和刚购买的东西同一个群的商品,而是识别用户常购买的东西属于哪些别的群,推荐那些群中的商品,这个技巧能够避免给用户推荐相似物品,那些常常是毫无意义的。在别的群中选择物品进行推荐的时候,选择k个和所购物品最相关的商品。
仔细看了一下原paper,主要分以下几个模型:prod2vec、bagged-prod2vec、user2vec,用skip gram来训练每个prod对应的向量,训练原理和过程与NLP中的word2vec没有什么区别。
4.在Yahoo搜索中的搜索广告匹配(paper地址:https://arxiv.org/pdf/1607.01869.pdf)
在这个场景中,目标是同时在相同嵌入空间内学习搜索query和广告向量,以此匹配与用户搜索最相关的广告并展示给客户。方法很简单,训练数据含很多的search session,每个session由用户在该session内的所有输入、相应的点击广告和搜索结果链接构成,每一个word就是由这个三元组构成。用户的行为序列视为文本语料中的一句话。
用户行为日志如下:
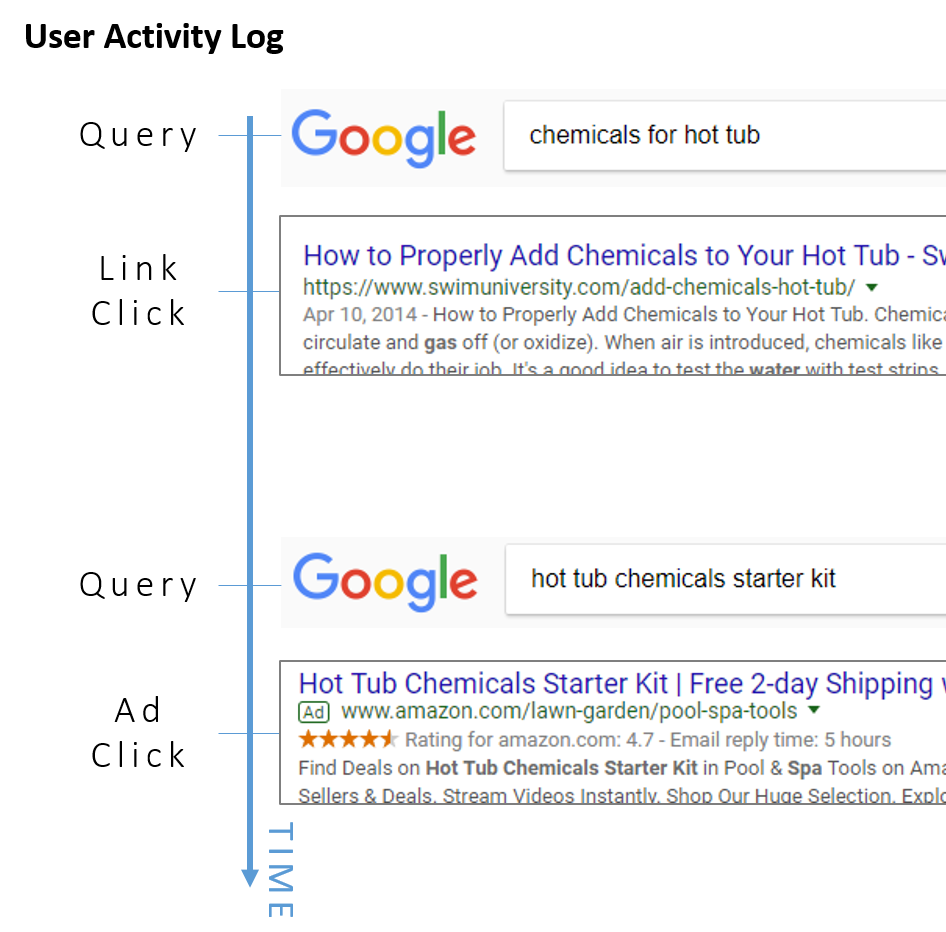
这个算法具体细节后边单开一篇博客详细阐述。















 2390
2390

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









