







⛄一、海洋捕食者算法(MPA)简介
1 海洋捕食者算法(MPA)定义
海洋捕食者算法(MPA)是一种自然启发式的优化算法,它遵循在最佳觅食策略中自然支配的规则,并且在海洋生态系统中遇到捕食者与猎物之间的速率策略。
2 海洋捕食者算法(MPA)流程
(1) 初始化精英矩阵(Elite)和猎物矩阵(Prey)
猎物矩阵(Prey) 矩阵每一个元素 Xij 的初始化方法:
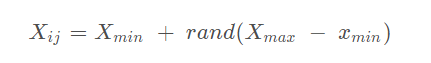
最终得到的Prey矩阵:

其中,n是种群的规模,d是每个维度的位置(问题的解的维度)。
对每一个Prey个体Xi = [Xi,1, Xi,2, …, Xi,d], 计算其适应度, 然后使用适应度最优的个体 XI 复制n份构成Elite矩阵

其中n是种群的规模,d是每个维度的位置(问题的解的维度),Elite的维度与Prey的维度相同。
(2)接着我们开始进行优化。在优化的过程中,具有三个步骤。
步骤一:
当迭代次数小于最大迭代次数的三分之一的时候
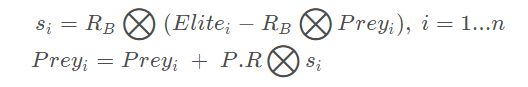
其中,RB 是采用布朗随机游走产生的随机数组成的向量,维度是 d(问题的求解规模,下同)。si 代表移动的步长。 P是一个常数,等于0.5。R是一个0到1之间的均匀分布的随机数组成的向量,维度是 d。
RB相当于一般化的高斯分布(Normal Gaussian distribution)。每一个元素 RBi 可以通过下列表达式来计算:
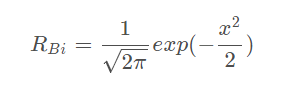
步骤二:
当迭代次数大于最大迭代次数的三分之一而小于其三分之二时,种群分两部分进行操作。
前半部分种群跟新规则如下:
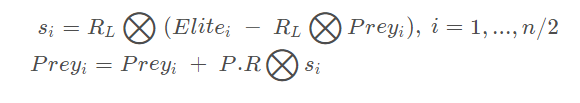
其中, RL 是 Levy 分布组成的出来的一个向量,维度是 d。P是一个常数,等于0.5。R是一个0到1之间的均匀分布的随机数组成的向量,维度是 d。
RL 的每一项元素 RLi 可以由下列式子计算得来:
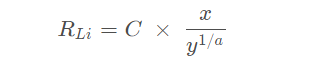
其中,C 和 α是一个常数,分别等于0.05和1.5。
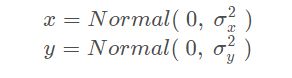
在上面的表达式中
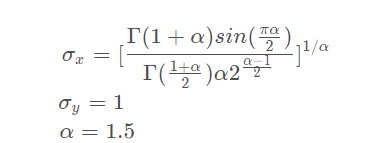
后半部分种群跟新规则如下:
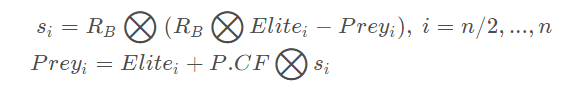
这里RB 是采用布朗随机游走产生的随机数组成的向量,维度是 d。P是常数,等于0.5。CF是步长si 的自适应参数(下同), 定义为
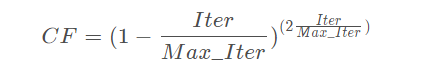
其中, Iter是迭代次数,Max_Iter是最大迭代次数。
步骤三:
当迭代次数大于最大迭代次数的三分之二时,进入第三个阶段,此时种群更新规则如下:
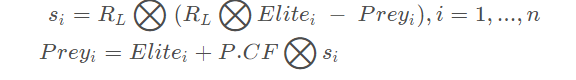
(3) 解决涡流形成和FADS效应(Eddy formation and FADs’ effect)
此操作的作用是让算法在迭代过程中尽可能跳出局部最优解,已达到更好的寻优精度。
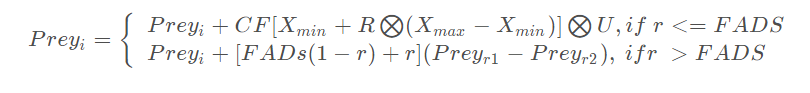
其中r是一个随机数, FADS是一个影响优化过程的常数,等于0.2。r1和r2是Prey两个随机下标, 1 ≤ r1,r2 ≤ n。 U是一个包含0和1的二进制向量,维度是d。U的每一个元素 Ui 定义为
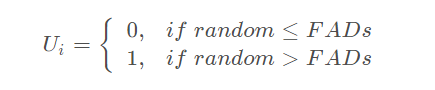
其中random是一个0到1的随机数,FADs等于0.2。
(4) 海洋记忆(Marine memory)
这一步骤进行对Elite(精英)矩阵的更新。
针对每一个Prey矩阵中的个体Preyi ,计算其适应度,若适应度由于Elite矩阵矩阵中相应的位置的适应度时,则将该个体替代原来精英矩阵中相应的个体。然后在计算整个精英矩阵中最优个体的适应度,若符合要求,则算法结束,否则继续迭代。
算法的流程图总结出来如下:

⛄二、BP神经网络简介
1 BP神经网络概述
BP(Back Propagation)神经网络是1986年由Rumelhart和McCelland为首的科研小组提出,参见他们发表在Nature上的论文 Learning representations by back-propagating errors 。
BP神经网络是一种按误差逆传播算法训练的多层前馈网络,是目前应用最广泛的神经网络模型之一。BP网络能学习和存贮大量的 输入-输出模式映射关系,而无需事前揭示描述这种映射关系的数学方程。它的学习规则是使用最速下降法,通过反向传播来不断 调整网络的权值和阈值,使网络的误差平方和最小。
2 BP算法的基本思想
上一次我们说到,多层感知器在如何获取隐层的权值的问题上遇到了瓶颈。既然我们无法直接得到隐层的权值,能否先通过输出层得到输出结果和期望输出的误差来间接调整隐层的权值呢?BP算法就是采用这样的思想设计出来的算法,它的基本思想是,学习过程由信号的正向传播与误差的反向传播两个过程组成。
正向传播时,输入样本从输入层传入,经各隐层逐层处理后,传向输出层。若输出层的实际输出与期望的输出(教师信号)不符,则转入误差的反向传播阶段。
反向传播时,将输出以某种形式通过隐层向输入层逐层反传,并将误差分摊给各层的所有单元,从而获得各层单元的误差信号,此误差信号即作为修正各单元权值的依据。这两个过程的具体流程会在后文介绍。
BP算法的信号流向图如下图所示
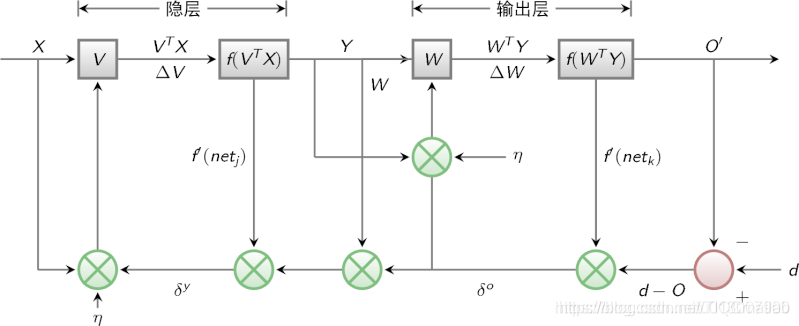
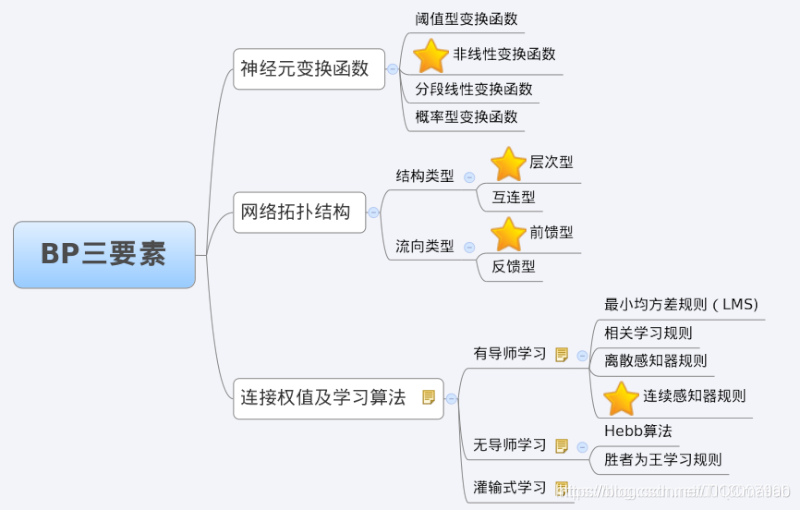
3 BP网络特性分析——BP三要素
我们分析一个ANN时,通常都是从它的三要素入手,即
1)网络拓扑结构;
2)传递函数;
3)学习算法。
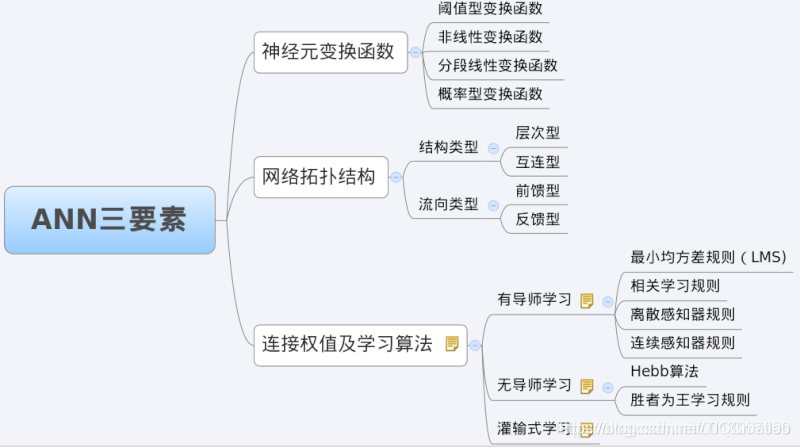
每一个要素的特性加起来就决定了这个ANN的功能特性。所以,我们也从这三要素入手对BP网络的研究。
3.1 BP网络的拓扑结构
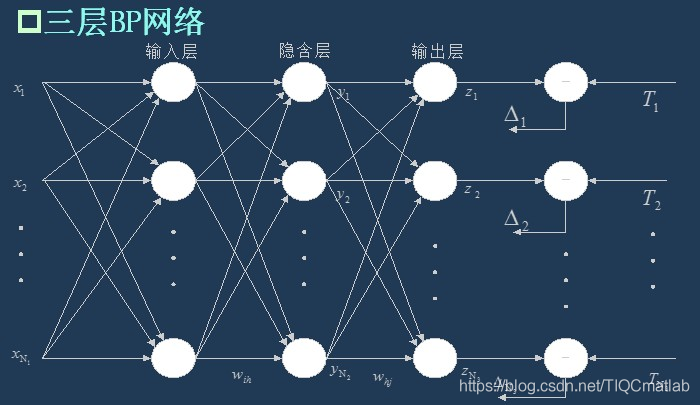
上一次已经说了,BP网络实际上就是多层感知器,因此它的拓扑结构和多层感知器的拓扑结构相同。由于单隐层(三层)感知器已经能够解决简单的非线性问题,因此应用最为普遍。三层感知器的拓扑结构如下图所示。
一个最简单的三层BP:
3.2 BP网络的传递函数
BP网络采用的传递函数是非线性变换函数——Sigmoid函数(又称S函数)。其特点是函数本身及其导数都是连续的,因而在处理上十分方便。为什么要选择这个函数,等下在介绍BP网络的学习算法的时候会进行进一步的介绍。
单极性S型函数曲线如下图所示。
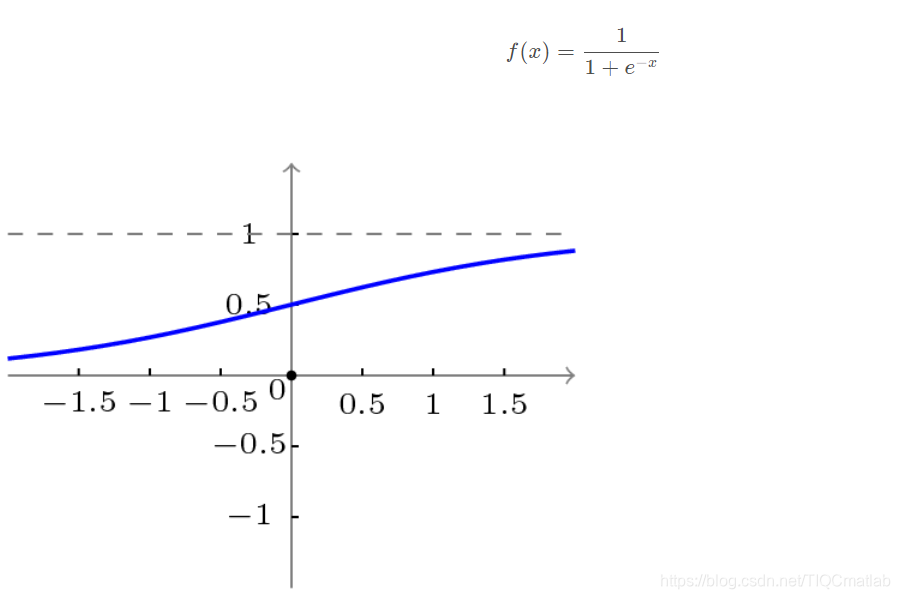
双极性S型函数曲线如下图所示。
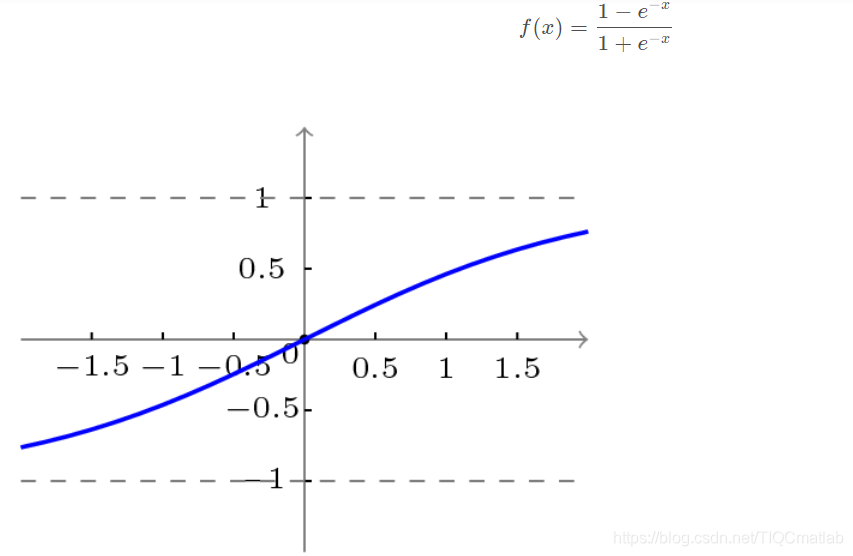
3.3 BP网络的学习算法
BP网络的学习算法就是BP算法,又叫 δ 算法(在ANN的学习过程中我们会发现不少具有多个名称的术语), 以三层感知器为例,当网络输出与期望输出不等时,存在输出误差 E ,定义如下



下面我们会介绍BP网络的学习训练的具体过程。
4 BP网络的训练分解
训练一个BP神经网络,实际上就是调整网络的权重和偏置这两个参数,BP神经网络的训练过程分两部分:
前向传输,逐层波浪式的传递输出值;
逆向反馈,反向逐层调整权重和偏置;
我们先来看前向传输。
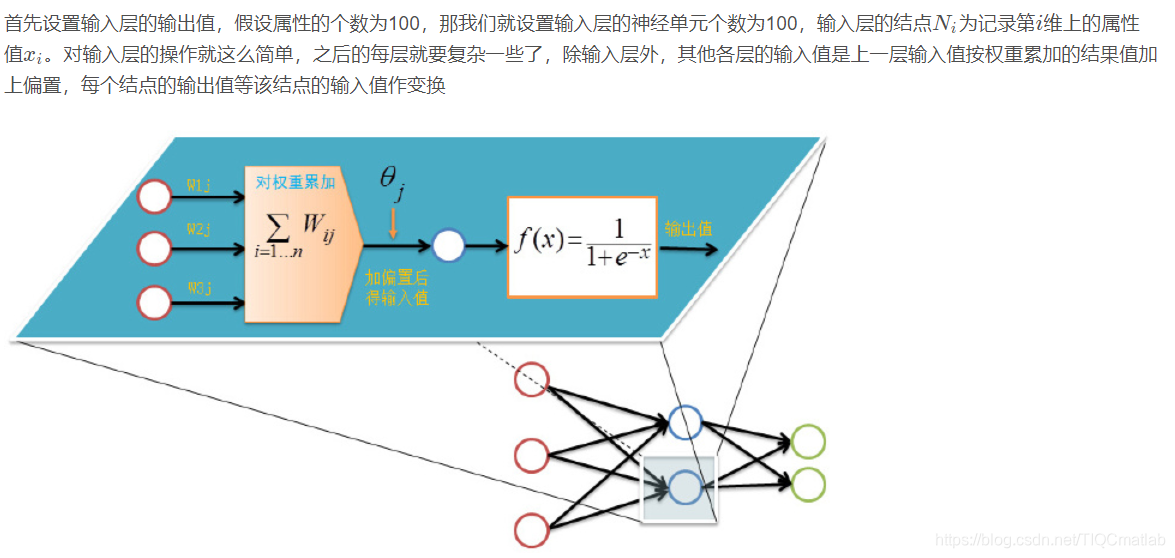
前向传输(Feed-Forward前向反馈)
在训练网络之前,我们需要随机初始化权重和偏置,对每一个权重取[ − 1 , 1 ] [-1,1][−1,1]的一个随机实数,每一个偏置取[ 0 , 1 ] [0,1][0,1]的一个随机实数,之后就开始进行前向传输。
神经网络的训练是由多趟迭代完成的,每一趟迭代都使用训练集的所有记录,而每一次训练网络只使用一条记录,抽象的描述如下:
while 终止条件未满足:
for record:dataset:
trainModel(record)

4.1 逆向反馈(Backpropagation)


4.2 训练终止条件
每一轮训练都使用数据集的所有记录,但什么时候停止,停止条件有下面两种:
设置最大迭代次数,比如使用数据集迭代100次后停止训练
计算训练集在网络上的预测准确率,达到一定门限值后停止训练
5 BP网络运行的具体流程
5.1 网络结构
输入层有n nn个神经元,隐含层有p pp个神经元,输出层有q qq个神经元。
5.2 变量定义


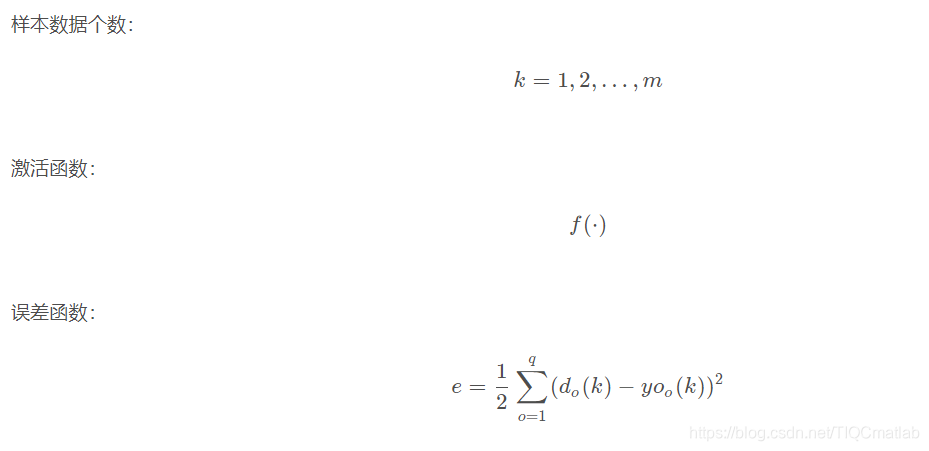


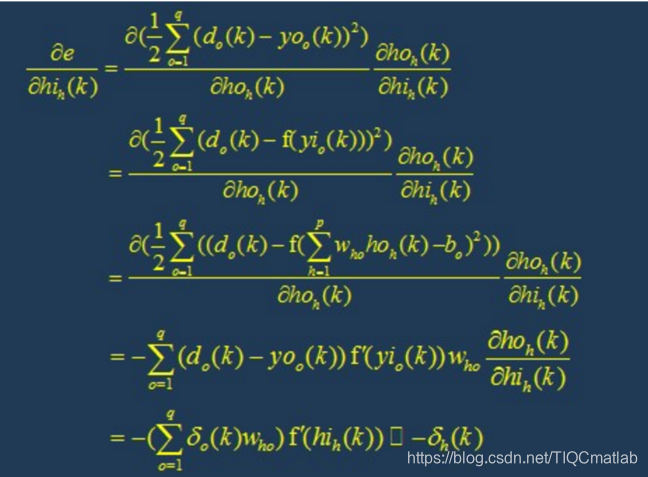


第九步:判断模型合理性
判断网络误差是否满足要求。
当误差达到预设精度或者学习次数大于设计的最大次数,则结束算法。
否则,选取下一个学习样本以及对应的输出期望,返回第三部,进入下一轮学习。
6 BP网络的设计
在进行BP网络的设计是,一般应从网络的层数、每层中的神经元个数和激活函数、初始值以及学习速率等几个方面来进行考虑,下面是一些选取的原则。
6.1 网络的层数
理论已经证明,具有偏差和至少一个S型隐层加上一个线性输出层的网络,能够逼近任何有理函数,增加层数可以进一步降低误差,提高精度,但同时也是网络 复杂化。另外不能用仅具有非线性激活函数的单层网络来解决问题,因为能用单层网络解决的问题,用自适应线性网络也一定能解决,而且自适应线性网络的 运算速度更快,而对于只能用非线性函数解决的问题,单层精度又不够高,也只有增加层数才能达到期望的结果。
6.2 隐层神经元的个数
网络训练精度的提高,可以通过采用一个隐含层,而增加其神经元个数的方法来获得,这在结构实现上要比增加网络层数简单得多。一般而言,我们用精度和 训练网络的时间来恒量一个神经网络设计的好坏:
(1)神经元数太少时,网络不能很好的学习,训练迭代的次数也比较多,训练精度也不高。
(2)神经元数太多时,网络的功能越强大,精确度也更高,训练迭代的次数也大,可能会出现过拟合(over fitting)现象。
由此,我们得到神经网络隐层神经元个数的选取原则是:在能够解决问题的前提下,再加上一两个神经元,以加快误差下降速度即可。
6.3 初始权值的选取
一般初始权值是取值在(−1,1)之间的随机数。另外威得罗等人在分析了两层网络是如何对一个函数进行训练后,提出选择初始权值量级为s√r的策略, 其中r为输入个数,s为第一层神经元个数。
6.4 学习速率
学习速率一般选取为0.01−0.8,大的学习速率可能导致系统的不稳定,但小的学习速率导致收敛太慢,需要较长的训练时间。对于较复杂的网络, 在误差曲面的不同位置可能需要不同的学习速率,为了减少寻找学习速率的训练次数及时间,比较合适的方法是采用变化的自适应学习速率,使网络在 不同的阶段设置不同大小的学习速率。
6.5 期望误差的选取
在设计网络的过程中,期望误差值也应当通过对比训练后确定一个合适的值,这个合适的值是相对于所需要的隐层节点数来确定的。一般情况下,可以同时对两个不同 的期望误差值的网络进行训练,最后通过综合因素来确定其中一个网络。
7 BP网络的局限性
BP网络具有以下的几个问题:
(1)需要较长的训练时间:这主要是由于学习速率太小所造成的,可采用变化的或自适应的学习速率来加以改进。
(2)完全不能训练:这主要表现在网络的麻痹上,通常为了避免这种情况的产生,一是选取较小的初始权值,而是采用较小的学习速率。
(3)局部最小值:这里采用的梯度下降法可能收敛到局部最小值,采用多层网络或较多的神经元,有可能得到更好的结果。
8 BP网络的改进
P算法改进的主要目标是加快训练速度,避免陷入局部极小值等,常见的改进方法有带动量因子算法、自适应学习速率、变化的学习速率以及作用函数后缩法等。 动量因子法的基本思想是在反向传播的基础上,在每一个权值的变化上加上一项正比于前次权值变化的值,并根据反向传播法来产生新的权值变化。而自适应学习 速率的方法则是针对一些特定的问题的。改变学习速率的方法的原则是,若连续几次迭代中,若目标函数对某个权倒数的符号相同,则这个权的学习速率增加, 反之若符号相反则减小它的学习速率。而作用函数后缩法则是将作用函数进行平移,即加上一个常数。
⛄三、代码说明
⛄四、参数设置及运行结果
MPA-BP模型参数:MPA最大迭代次数为200,种群规模50,FADs效应系数=0.2,常量P=0.5;BP隐含层数为输入维数的2倍-1,隐含层传递函数、输出层传递函数、训练函数分别采用tansig、purelin、traingdx,设定期望误差为0.0001,最大训练轮回均设置为1000次,数据采用[-1,1]进行归一化处理。
**BP模型参数:**为在公平条件下对比验证MPA-BP模型,BP参数设置同MPA-BP模型。
**预测结果:**MPA-BP模型平均相对百分比误差(MAPE)4.14%;BP模型平均相对百分比误差(MAPE)18.3%,精度提高77.4%



五⛄、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]李代华,崔东文.基于PCA-MPA-ANFIS模型的年径流预测研究[J].水电能源科学,2020,38(7):24-29.
[2]胡顺强, 崔东文.基于海洋捕食者算法优化的长短期记忆神经网络径流预测[J].中国农村水利水电 2021, (2) 78-82.
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除















 2264
2264











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









