







⛄一、运行结果


✅博主简介:热爱科研的Matlab仿真开发者,修心和技术同步精进,Matlab项目合作可私信。
🍎个人主页:海神之光
🏆代码获取方式:
海神之光Matlab王者学习之路—代码获取方式
⛳️座右铭:行百里者,半于九十。
更多Matlab仿真内容点击👇
Matlab图像处理(进阶版)
路径规划(Matlab)
神经网络预测与分类(Matlab)
优化求解(Matlab)
语音处理(Matlab)
信号处理(Matlab)
车间调度(Matlab)
⛄二、DBN算法简介
DBN是深度学习方法中的一种常用模型,是一种融合了深度学习与特征学习的神经网络。DBN网络结构是由若干层受限玻尔兹曼机(Restricted Boltzmann Machine,RBM)和一层BP组成的一种深层神经网络。DBN结构如图2所示。


图2 DBN结构示意图
DBN训练过程由预训练和微调构成,数据首先由输入层输入到网络结构中,生成一个向量V,通过权重值W传给隐藏层得到H,单独无监督训练每一层RBM网络,确保特征向量映射到不同特征空间,最后由BP网络接收RBM的输出特征向量作为它的输入特征向量,反向传播网络自顶向下将错误信息传播给每一层RBM,微调整个DBN网络,进行有监督的训练,最终得到网络中的权重以及偏置。
1 受限玻尔兹曼机
RBM是1986年由Smolensky提出的一种可通过输入数据集学习概率分布的随机生成神经网络。RBM模型是包含一种可观察变量(v)和单层隐藏变量(h)的无向概率图,RBM只有两层神经元,它是一个二分图,两层间的单元相互连接,层内的任何单元之间不存在连接。RBM结构见图3。

图3 RBM结构示意图
RBM是一种基于能量的模型,任何两个连接的神经元之间都有一个权重W来表示连接权重Wij, Wij表示可观察变量单元i和隐藏变量单元j之间的权重,观察层与隐藏层分别用v和h来表示,则连接权重与偏差决定的观察层变量v和隐藏层变量h的联合配置能量如下:
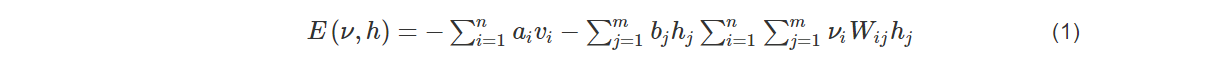
其中ai是可观察层单元的偏置,bj是隐藏层单元的偏置,Wij为可观察层单元与隐藏层单元之间的连接权重,基于能量函数的可观察层和隐藏层可以得到概率分布:
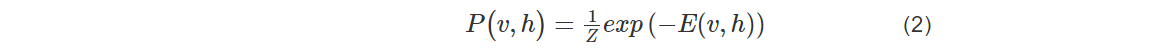
其中Z为配分函数的归一化常数,即所有参数下的能量之和,该函数累加所有可观察向量和隐藏向量的可能组合。
RBM中的每层中的神经元只存在两种状态0或1,给定任意层中的各神经元的状态,可以得到可观察层神经元和隐藏层神经元的状态概率如下:
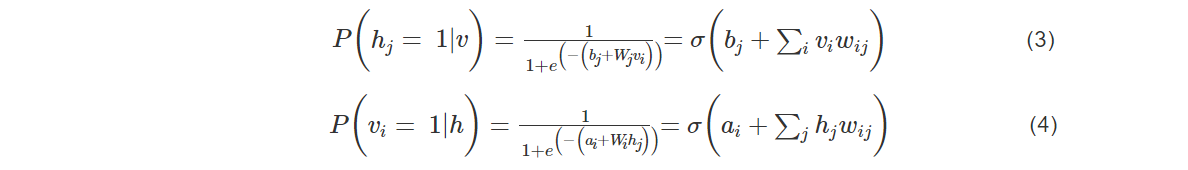
根据Hinton在2002年提出的对比散度,可知参数的变化规则如下:
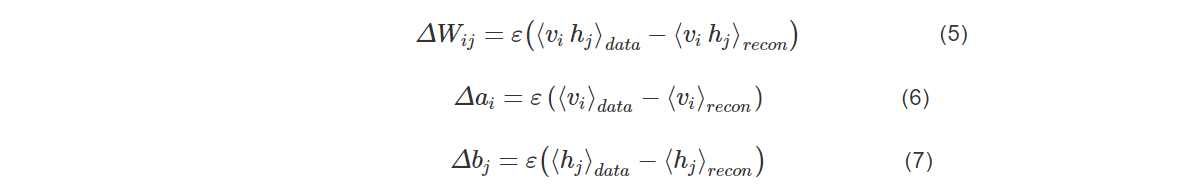
其中,ε是学习率,⟨⋅⟩data表示训练原始数据集的模型定义的分布,⟨⋅⟩recon表示一步重构后模型定义的分布。
⛄三、部分源代码
tic;
clear all
close all
format compact
format long
%% 1.数据加载
fprintf(1,‘加载数据 \n’);
load(‘drivFace600’);%其中1-173为1类,174-343为2类 344-510为3类 511-600为4类,各选择20%作为测试集
%第一类173组
[i1 i2]=sort(rand(173,1));
train(1:139,:)=input(i2(1:139)😅; train_label(1:139,1)=output(i2(1:139),1);
test(1:34,:)=input(i2(140:173)😅; test_label(1:34,1)=output(i2(140:173),1);
%第二类有170组
[i1 i2]=sort(rand(170,1));
train(140:275,:)=input(173+i2(1:136)😅; train_label(140:275,1)=output(173+i2(1:136),1);
test(35:68,:)=input(173+i2(137:170)😅; test_label(35:68,1)=output(173+i2(137:170),1);
%第三类有167
[i1 i2]=sort(rand(167,1));
train(276:408,:)=input(343+i2(1:133)😅; train_label(276:408,1)=output(343+i2(1:133),1);
test(69:102,:)=input(343+i2(134:167)😅; test_label(69:102,1)=output(343+i2(134:167),1);
%第4类有90
[i1 i2]=sort(rand(90,1));
train(409:480,:)=input(510+i2(1:72)😅; train_label(409:480,1)=output(510+i2(1:72),1);
test(103:120,:)=input(510+i2(73:90)😅; test_label(103:120,1)=output(510+i2(73:90),1);
clear i1 i2 input output
%%打乱顺序
k=rand(480,1);[m n]=sort(k);
train=train(n(1:480)😅;train_label=train_label(n(1:480)😅;
k=rand(120,1);[m n]=sort(k);
test=test(n(1:120)😅;test_label=test_label(n(1:120)😅;
clear k m n
%no_dims = round(intrinsic_dim(train, ‘MLE’)); %round四舍五入
%disp(['MLE estimate of intrinsic dimensionality: ’ num2str(no_dims)]);
numcases=48;%每块数据集的样本个数
numdims=size(train,2);%单个样本的大小
numbatches=10; %%原则上每块的样本个数要大于分块数
% 训练数据
x=train;%将数据转换成DBN的数据格式
for i=1:numbatches
train1=x((i-1)numcases+1:inumcases,:);
batchdata(:,:,i)=train1;
end%将分好的10组数据都放在batchdata中
% rbm参数
maxepoch=20;%训练rbm的次数
numhid=500; numpen=200; numpen2=100;%dbn隐含层的节点数
disp(‘构建一个3层的置信网络’);
clear i
%% 2.训练RBM
fprintf(1,‘Pretraining Layer 1 with RBM: %d-%d \n’,numdims,numhid);%256-200
restart=1;
rbm;%使用cd-k训练rbm,注意此rbm的可视层不是二值的,而隐含层是二值的
vishid1=vishid;hidrecbiases=hidbiases;
fprintf(1,‘\nPretraining Layer 2 with RBM: %d-%d \n’,numhid,numpen);%200-100
batchdata=batchposhidprobs;%将第一个RBM的隐含层的输出作为第二个RBM 的输入
numhid=numpen;%将numpen的值赋给numhid,作为第二个rbm隐含层的节点数
restart=1;
rbm;
hidpen=vishid; penrecbiases=hidbiases; hidgenbiases=visbiases;
fprintf(1,‘\nPretraining Layer 3 with RBM: %d-%d \n’,numpen,numpen2);%200-100
batchdata=batchposhidprobs;%显然,将第二哥RBM的输出作为第三个RBM的输入
numhid=numpen2;%第三个隐含层的节点数
restart=1;
rbm;
hidpen2=vishid; penrecbiases2=hidbiases; hidgenbiases2=visbiases;
function per_accuracy_crossvalindation= pso_fitnessnew(xx,batchdata,train,train_label)
maxepoch=20;%训练rbm的次数
%% 训练第1层RBM
numhid=xx(1,1);
restart=1;
rbm1;%使用cd-k训练rbm,注意此rbm的可视层不是二值的,而隐含层是二值的
vishid1=vishid;hidrecbiases=hidbiases;
%% 训练第2层RBM
batchdata=batchposhidprobs;%将第一个RBM的隐含层的输出作为第二个RBM 的输入
numhid=xx(1,2);%将numpen的值赋给numhid,作为第二个rbm隐含层的节点数
restart=1;
rbm1;
hidpen=vishid; penrecbiases=hidbiases; hidgenbiases=visbiases;
%% 训练第3层RBM
batchdata=batchposhidprobs;%显然,将第二个RBM的输出作为第三个RBM的输入
numhid=xx(1,3);%第三个隐含层的节点数
restart=1;
rbm1;
hidpen2=vishid; penrecbiases2=hidbiases; hidgenbiases2=visbiases;
%% 训练第4层RBM
batchdata=batchposhidprobs;%显然,将第二哥RBM的输出作为第三个RBM的输入
numhid=xx(1,4);%第三个隐含层的节点数
restart=1;
rbm1;
hidpen3=vishid; penrecbiases3=hidbiases; hidgenbiases3=visbiases;
%% 训练极限学习机
% 训练集特征输出
w1=[vishid1; hidrecbiases];
w2=[hidpen; penrecbiases];
w3=[hidpen2; penrecbiases2];
w4=[hidpen3; penrecbiases3];
digitdata = [train ones(size(train,1),1)];%x表示train数据集
w1probs = 1./(1 + exp(-digitdataw1));%
w1probs = [w1probs ones(size(train,1),1)];%
w2probs = 1./(1 + exp(-w1probsw2));%
w2probs = [w2probs ones(size(train,1),1)];%
w3probs = 1./(1 + exp(-w2probsw3)); %
w3probs = [w3probs ones(size(train,1),1)];%
w4probs = 1./(1 + exp(-w3probsw4)); %
H_dbn = w4probs; %%第4个rbm的实际输出值,也是elm的隐含层输出值H
%% 交叉验证
indices = crossvalind(‘Kfold’,size(H_dbn,1),10);%对训练数据进行10折编码
%[Train, Test] = crossvalind(‘HoldOut’, N, P) % 将原始数据随机分为两组,一组做为训练集,一组做为验证集
%[Train, Test] = crossvalind(‘LeaveMOut’, N, M) %留M法交叉验证,默认M为1,留一法交叉验证
sum_accuracy = 0;
for i = 1:10
%%
cross_test = (indices == i); %每次循选取一个fold作为测试集
cross_train = ~cross_test; %取corss_test的补集作为训练集,即剩下9个fold
%%
P_train = H_dbn(cross_train,:)‘;
P_test= H_dbn(cross_test,:)’;
T_train= train_label(cross_train,:)‘;
T_test=train_label(cross_test,:)’;
% 训练ELM
lamda=0.001; %% 正则化系数在0.0007-0.00037之间时,一个一个试出来的
H1=P_train+1/lamda;% 加入regularization factor
T =T_train; %训练集标签
T1=ind2vec(T); %做分类需要先将T转换成向量索引
OutputWeight=pinv(H1’) *T1’;
Y=(H1’ * OutputWeight)';
temp_Y=zeros(1,size(Y,2));
for n=1:size(Y,2)
[max_Y,index]=max(Y(:,n));
temp_Y(n)=index;
end
Y_train=temp_Y;
%Y_train=vec2ind(temp_Y1);
H2=P_test+1/lamda;
T_cross=(H2’ * OutputWeight)'; % TY: the actual output of the testing data
temp_Y=zeros(1,size(T_cross,2));
for n=1:size(T_cross,2)
[max_Y,index]=max(T_cross(:,n));
temp_Y(n)=index;
end
TY1=temp_Y;
% 加载输出
TV=T_test;
sum_accuracy=sum_accuracy+sum(TV==TY1) / length(TV);
end
per_accuracy_crossvalindation=sum_accuracy/10;%利用交叉验证的平均精度做适应度函数
%========================================================
%=交叉验证结束========
end
⛄四、matlab版本及参考文献
1 matlab版本
2014a
2 参考文献
[1]陆文星,戴一茹,李克卿.基于自适应惯性权重优化后的粒子群算法优化误差反向传播神经网络和深度置信网络(DBN-APSOBP)组合模型的短期旅游需求预测研究[J].科技促进发展. 2020,16(05)
3 备注
简介此部分摘自互联网,仅供参考,若侵权,联系删除
🍅 仿真咨询
1 各类智能优化算法改进及应用
生产调度、经济调度、装配线调度、充电优化、车间调度、发车优化、水库调度、三维装箱、物流选址、货位优化、公交排班优化、充电桩布局优化、车间布局优化、集装箱船配载优化、水泵组合优化、解医疗资源分配优化、设施布局优化、可视域基站和无人机选址优化
2 机器学习和深度学习方面
卷积神经网络(CNN)、LSTM、支持向量机(SVM)、最小二乘支持向量机(LSSVM)、极限学习机(ELM)、核极限学习机(KELM)、BP、RBF、宽度学习、DBN、RF、RBF、DELM、XGBOOST、TCN实现风电预测、光伏预测、电池寿命预测、辐射源识别、交通流预测、负荷预测、股价预测、PM2.5浓度预测、电池健康状态预测、水体光学参数反演、NLOS信号识别、地铁停车精准预测、变压器故障诊断
3 图像处理方面
图像识别、图像分割、图像检测、图像隐藏、图像配准、图像拼接、图像融合、图像增强、图像压缩感知
4 路径规划方面
旅行商问题(TSP)、车辆路径问题(VRP、MVRP、CVRP、VRPTW等)、无人机三维路径规划、无人机协同、无人机编队、机器人路径规划、栅格地图路径规划、多式联运运输问题、车辆协同无人机路径规划、天线线性阵列分布优化、车间布局优化
5 无人机应用方面
无人机路径规划、无人机控制、无人机编队、无人机协同、无人机任务分配
6 无线传感器定位及布局方面
传感器部署优化、通信协议优化、路由优化、目标定位优化、Dv-Hop定位优化、Leach协议优化、WSN覆盖优化、组播优化、RSSI定位优化
7 信号处理方面
信号识别、信号加密、信号去噪、信号增强、雷达信号处理、信号水印嵌入提取、肌电信号、脑电信号、信号配时优化
8 电力系统方面
微电网优化、无功优化、配电网重构、储能配置
9 元胞自动机方面
交通流 人群疏散 病毒扩散 晶体生长
10 雷达方面
卡尔曼滤波跟踪、航迹关联、航迹融合















 180
180











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









