








国际人工智能顶级会议NeurIPS 2020(Conference on Neural Information Processing Systems, 神经信息处理系统大会)在12月6日至12日举行。本届会议无论是论文投稿数量还是接受率都创下了历史记录。
随着卷积神经网络的广泛使用和在视觉类应用的巨大成功,如何克服计算和存储资源限制将卷积神经网络部署到智能手机和穿戴设备等端侧设备的模型轻量化技术越发重要。本文将对华为诺亚方舟实验室入选NeurIPS 2020的模型轻量化技术工作进行介绍,涵盖了剪枝、结构蒸馏以及量化等几个方向,并且放出对应MindSpore首发端侧模型获取链接↓
https://www.mindspore.cn/resources/hub
SCOP:Scientific Control for Reliable Neural Network Pruning
现有的剪枝方法基于各种假设条件近似估计神经网络节点对整体网络的重要性然后进行节点剪枝,往往存在结果不可靠而导致网络精度下降。
华为诺亚方舟实验室和北京大学联合提出了一种科学控制机制最小化剪枝节点对网络输出的影响。采用这种剪枝方法,能够实现ImageNet数据集上仅损失ResNet101网络0.01%的top-1准确率,模型参数量和计算量分别减少57.8%和60.2%,显著优于SOTA方法[1]。
原理
对于剪枝方法,最重要的过程是评估卷积神经网络节点的重要性,在尽量不影响预训练网络性能的前提下删除不重要的网络节点。一种典型的节点重要性评估假设是权重Norms越小节点重要性低进而被剪掉[2][3]。
考虑到输入数据,有的剪枝方法评估网络节点和最终损失函数之间的关系并用泰勒展开进行近似,保留与最终损失函数关系更密切的节点[4]。但是这些方法都会不可避免的引入大量潜在影响因子,最终影响剪枝过程,例如不同信道之间的相互依赖可能误导基于权重Norms的方法,因为一些不含重要信息的节点权重Norms很大,基于输入数据的方法的权重重要性对数据很敏感,剪枝结果不稳定。

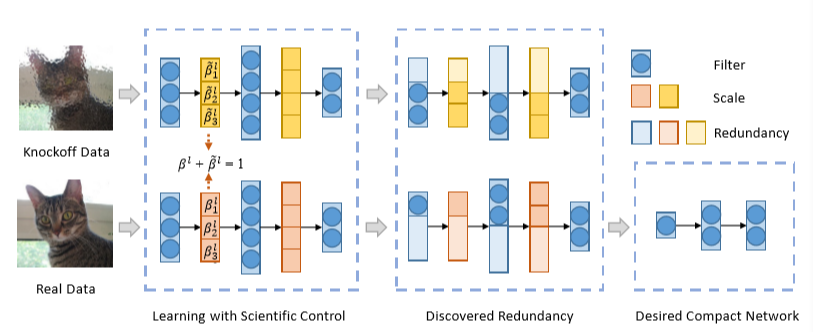
图1.1. 科学控制下的剪枝流程[1]
结果
将本文提出的SCOP在公开数据集ImageNet上进行实验,对ResNet系列网络预训练模型进行剪枝验证了SCOP的有效性,实验结果如下表1.1。
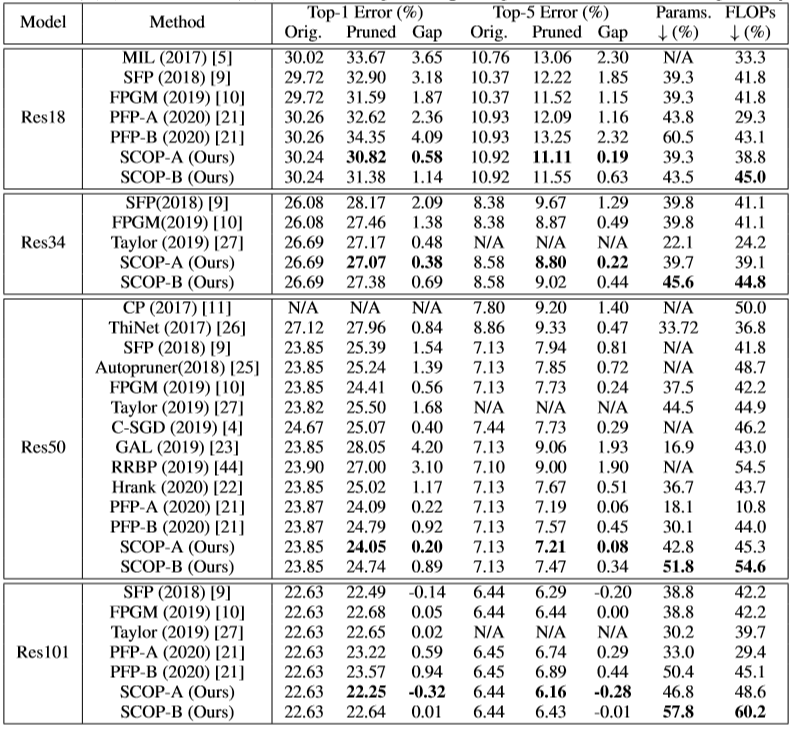
表1.1. SCOP在ImageNet数据集实验结果[1]
相比于现有SOTA剪枝方法GAL[5]和PFP[6],SCOP方法得到的剪枝后网络无论是网络精度还是模型大小即参数量减少比例都表现出很大的优势。
使用SCOP算法在Oxford-IIIT Pet数据集对ResNet50网络剪枝的网络resnet-0.65x_v1.0_oxford_pets已基于MindSpore首发,可分别从MindSpore modelzoo 和Hub获取训练代码和模型。
论文链接:
https://proceedings.neurips.cc/paper/2020/file/7bcdf75ad237b8e02e301f4091fb6bc8-Paper.pdf
代码链接:
https://gitee.com/mindspore/mindspore/tree/master/model_zoo/research/cv/resnet50_adv_pruning
模型链接:
https://www.mindspore.cn/resources/hub/details?noah-cvlab/gpu/1.0/resnet-0.65x_v1.0_oxford_pets
Residual Distillation: Towards Portable Deep Neural Networks without Shortcuts
ResNet通过引入残差连接,使得我们可以有效地训练几十到上百层的网络结构。但与此同时,也不可避免的引入了额外的计算消耗。
比如当进行在线推理时,ResNet50中的残差占据了特征图整体内存消耗的大约40%,因为之前网络层的特征结果无法被释放,直到后续的残差计算结束。
华为诺亚方舟实验室提出了一种新的CNN模型训练方法—基于残差蒸馏的联合训练框架Joint-training framework based on Residual Distillation(JointRD),希望在训练的时候引入残差连接保证训练效果,但在部署时去掉残差提升推理速度。通过在ImageNet/CIFAR10/CIFAR100等数据上的实验表明,利用JointRD训练得到的没有残差连接的plainCNN能够达到和ResNet相同精度的同时,性能提升1.4倍,内存消耗降低1.25倍。预训练plain-CNN在MIT 67和Caltech 101的fine-tuning结果也证明了特征的迁移泛化性。
联合训练框架介绍
主要动机
CNN模型当中引入残差连接的主要动机是避免梯度消失及降低优化难度,在最近的多篇研究中已经证明了残差连接在训练过程中对梯度的影响。因此我们认为没有残差的plain-CNN模型表现差是因为优化方法差而非模型本身的表达能力的限制。
通过在mobile NPU上对比去掉残差的plain-CNN 50和保留残差的ResNet50内存消耗和时延,我们发现去掉残差后内存消耗降低19%,时延降低30%。
基于以上结论,我们提出了一种可能的解决方案,利用ResNet为plain CNN的训练过程提供更好的梯度。因此我们提出了JointRD (Joint-training framework based on Residual Distillation),在这个框架中我们通过将plain CNN中的一个stage同时连接到它之后的stage和ResNet之后的stage达成上述训练目标。
具体方案
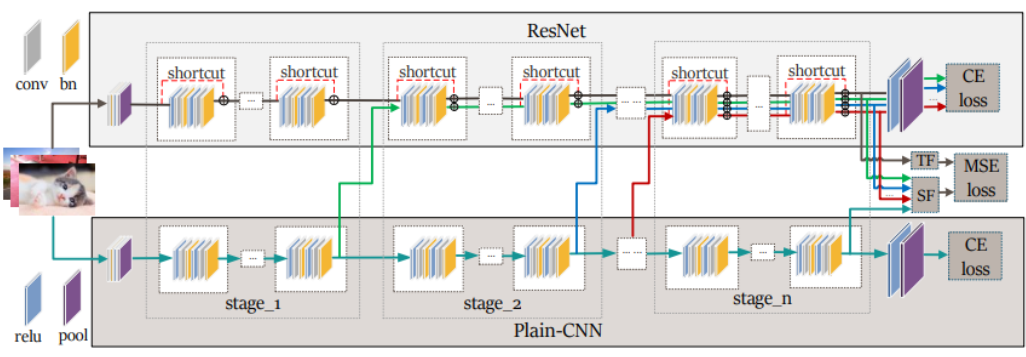
图2.1. 联合训练框架[7]

实验结果
通过三种规模的网络plain-CNN18, plain-CNN34, plain-CNN50在CIFAR-10和CIFAR-100上的实验证明了联合训练方法JointRD有效性。如表2.1所示,JointRD可以将Plain-CNN训练达到和对应的ResNet相同的精度。同时我们还对比了单纯训练plain-CNN(见"Naive"列)以及只使用KD (MSE) loss和plain-CNN的交叉熵loss(见"KD (MSE) +Dirac"列)。
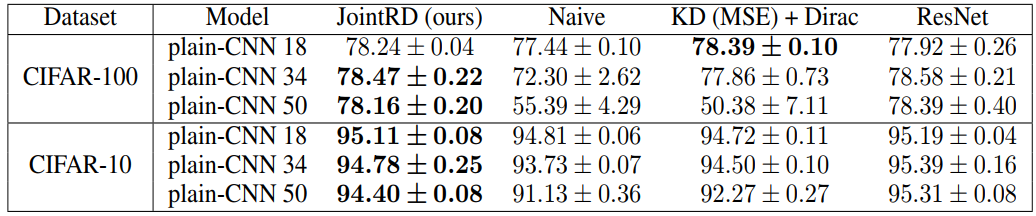
表2.1. 基于CIFAR-10/CIFAR-100的Benchmark结果[7]
在表2.2中,我们对比了利用JointRD训练得到的plain-CNN50,利用剪枝方法[9]剪枝40%后的ResNet50,以及ResNet50本身的精度、时延和内存消耗。可以看出在plain-CNN50在各个维度均优于直接剪枝(实验细节请参考论文原文[7])。

表2.2. 对比基于ImageNet剪枝和plain-CNN的轻量网络[7]
目前由JointRD训练得到的plain-CNN18/ plain-CNN34/plain-CNN50 MindSpore端侧模型均已上线MindSpore Hub,感兴趣的可以下载体验。
论文链接:
https://proceedings.neurips.cc/paper/2020/file/657b96f0592803e25a4f07166fff289a-Paper.pdf
Plain-CNN18模型链接:
https://www.mindspore.cn/resources/hub/details?noah-cvlab/gpu/1.0/plain-CNN-resnet18_v1.0_cifar_10
Plain-CNN34模型链接:
https://www.mindspore.cn/resources/hub/details?noah-cvlab/gpu/1.0/plain-CNN-resnet34_v1.0_cifar10
Plain-CNN50模型链接:
https://www.mindspore.cn/resources/hub/details?noah-cvlab/gpu/1.0/plain-CNN-resnet50_v1.0_cifar10
Searching for Low-Bit Weights in Quantized Neural Networks
神经网络量化因为可以减少计算消耗和内存占用,在模型部署特别是端侧设备部署中被广泛应用,例如相较于传统的32-bit模型网络,二值化网络可以直接将模型压缩32倍,同时如果采用二值运算可以大大降低计算复杂度(如XNORNet 可以达到57倍加速[10])。
传统的量化方法通常不是直接可导的,而是通过近似梯度进行训练,这增加了量化网络的优化难度以及量化网络和原始网络间的精度差距。相较于全精度(32-bit 浮点数)权值,低比特权值只有很小的数值空间,如4-bit量化只有2^4=16种可能的量化取值。
因此,我们提出了一种全新的可导的量化方法Searching for Low-Bit Weights (SLB),将权值量化转变为可能量化取值的搜索。具体来讲就是将每个权值表示成所有可能取值空间的概率分布,在训练过程中优化这个概率分布,在推理过程中选取概率最大的值作为量化后的值。在图像分类和超分任务的多个benchmark上的实验证明,通过SLB方法量化后的网络性能超越已有SOTA结果。
方法介绍
传统量化方法


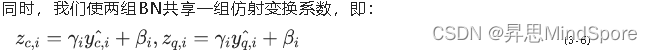
通过这种方式,SBN消除了BN层统计的量化偏差。
实验结果
表3.1和表3.2比较了我们的方法和其他SOTA量化方法BNN, XNORNet, DoReFa, DSQ, SQ, and LQ-Net在VGG-Small和ResNet20两个不同模型上的效果。如表中结果所示,W/A分别表示weight和activation的量化位宽,在不同量化位宽下,我们的方法都超越了其他SOTA方法。具体的实验细节请参考论文原文[12]。
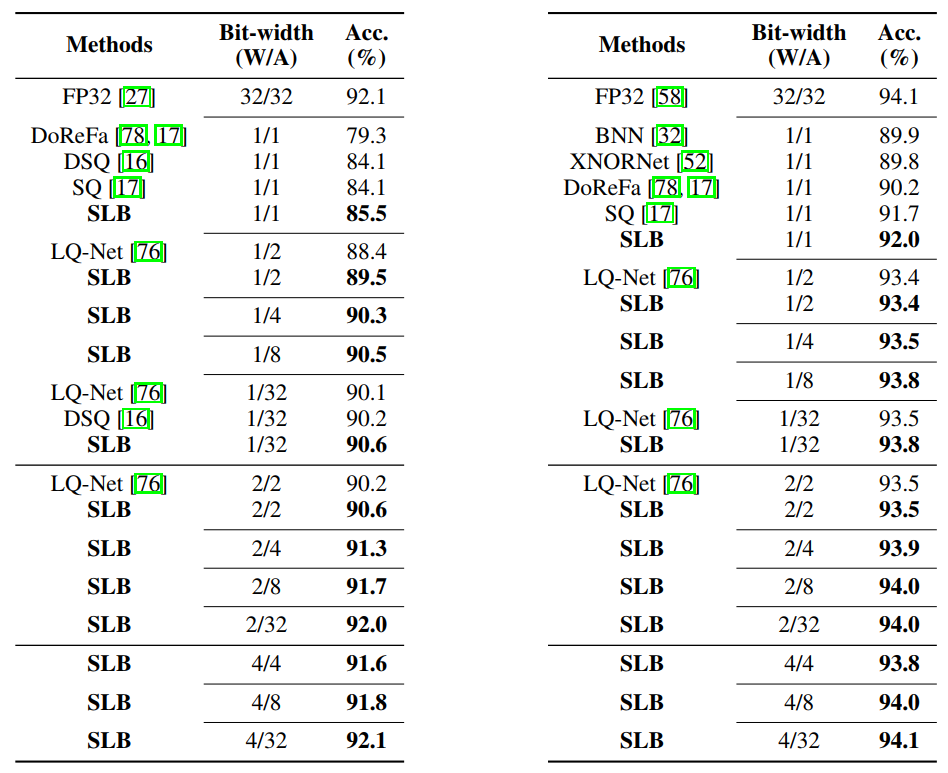
表3.1.ResNet20在CIFAR-10上的结果[12] 表3.2.VGG-Small在CIFAR10上的结果[12]
VGG-Small在CIFAR10上基于2-bit weight和2-bit activation的量化端侧模型目前已在MindSpore Hub开源首发,感兴趣的可以下载体验。
论文链接:
https://proceedings.neurips.cc/paper/2020/file/2a084e55c87b1ebcdaad1f62fdbbac8e-Paper.pdf
模型链接:
https://www.mindspore.cn/resources/hub/details?noah-cvlab/gpu/1.0/VGG-Small-low%20bit_cifar10
参考文献
[1] Yehui Tang,Yunhe Wang,Yixing Xu,Dacheng Tao, Chunjing Xu,Chao Xu,Chang Xu. SCOP:Scientific Control for Reliable Neural Network Pruning. In 34th Conference on Neural Information Processing Systems (NeurIPS 2020), 2020.
[2] Hao Li, Asim Kadav, Igor Durdanovic, Hanan Samet, and Hans Peter Graf. Pruning filters for efficient convnets. In 5th International Conference on Learning Representations, ICLR 2017, Toulon, France, April 24-26, 2017, Conference Track Proceedings. OpenReview.net, 2017.
[3] Yang He, Guoliang Kang, Xuanyi Dong, Yanwei Fu, and Yi Yang. Soft filter pruning for accelerating deep convolutional neural networks. In Proceedings of the 27th International Joint Conference on Artificial Intelligence, pages 2234–2240, 2018.
[4] Pavlo Molchanov, Arun Mallya, Stephen Tyree, Iuri Frosio, and Jan Kautz. Importance estimation for neural network pruning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 11264–11272, 2019.
[5] Shaohui Lin, Rongrong Ji, Chenqian Yan, Baochang Zhang, Liujuan Cao, Qixiang Ye, Feiyue Huang, and David Doermann. Towards optimal structured cnn pruning via generative adversarial learning. In Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition, pages 2790–2799, 2019.
[6] Lucas Liebenwein, Cenk Baykal, Harry Lang, Dan Feldman, and Daniela Rus. Provable filter pruning for efficient neural networks. In International Conference on Learning Representations, 2020.
[7] Guilin Li, Junlei Zhang, Yunhe Wang, Chuanjian Liu, Matthias Tan, Yunfeng Lin, Wei Zhang, Jiashi Feng, Tong Zhang. Residual Distillation: Towards Portable Deep Neural Networks without Shortcuts. Accepted by NeurIPS 2020
[8] Sergey Zagoruyko and Nikos Komodakis. Diracnets: Training very deep neural networks
without skip-connections. arXiv preprint arXiv:1706.00388, 2017.
[9] Zhuang Liu, Jianguo Li, Zhiqiang Shen, Gao Huang, Shoumeng Yan, and Changshui Zhang.
Learning efficient convolutional networks through network slimming. In Proceedings of the
IEEE International Conference on Computer Vision, pages 2736–2744, 2017.
[10] Mohammad Rastegari, Vicente Ordonez, Joseph Redmon, and Ali Farhadi. Xnor-net: Imagenet classification using binary convolutional neural networks. ECCV, 2016
[11] Matthieu Courbariaux, Yoshua Bengio, and Jean-Pierre David. Binaryconnect: training deep neural networks with binary weights during propagations. NeurIPS, 2015
[12] Zhaohui Yang, Yunhe Wang, Kai Han, Chunjing Xu, Chao Xu, Dacheng Tao, Chang Xu. Searching for Low-Bit Weights in Quantized Neural Networks. Accepted by NeurIPS 2020.

















 620
620

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









