







01
研究动机
1.1 研究背景
深度学习开启了人工智能的新时代。在这个属于深度神经网络的“镀金年代”中,深度学习模型在众多任务中攻城略地,狂飙突进。然而猛然间人们却发现,只需要对输入样本进行微小扰动(对抗攻击),其输出结果就会发生灾难性的错误。这意料之外的脆弱性仿佛漂浮在晴朗天空一角的乌云,为这个时代投下了令人不安的阴影。

图一:对抗样本。在原图中添加很小的扰动即可操纵模型输出。
面对对抗攻击带来的威胁,一个简单粗暴的思路首先被想到:将对抗样本引入训练过程,通过训练提升神经网络的对抗鲁棒性。这可以说是深度学习时代的典型解法:不需要知道模型为什么出现问题,只需要将出现错误的样本引入训练,依靠模型强大的拟合能力“记住”这些错误。然而这个试图暴力破解的方法却仿佛一拳打在了棉花上:那些引入训练的对抗样本确实得以解决,然而更多的对抗样本种类却如幽灵般浮现。而对抗训练得到的模型在不同种类的对抗样本之间的泛化性却几乎没有。暴力破解、“一力降十会”在对抗样本面前变得苍白无力。
直到这时,也许我们才能真正体会对抗样本投下的阴影中所透出的寒意。它不是在现有方法论的基础上小修小补所能够解决的,它是对基于统计观察的“数据驱动”这一深度学习的底层逻辑的挑战。
1.2 方法动机
暴力破解的失败强迫我们静下心来,让我们的头脑冷却下来重新审视对抗样本,它已经被深度学习所创造的“辉煌”冲击的有些过热了。此时我们不得不正视一个现实,我们不理解对抗样本,我们不明白它为什么会存在,不理解它为什么会让强大的模型崩溃。再进一步我们还会发现,阻碍我们理解对抗样本的最大绊脚石是我们不理解这些我们创造的深度模型,我们不明白它们为什么正确、为什么错误。它是记住了训练样本吗?还是发现了某种数据分布中的规律?在很长时间里我们似乎忘记了这也是一个问题,忘记了这些问题才是科学和炼金术的区别。也就是说,对抗样本问题和模型可解释性问题天然相关,两者或许就是一枚硬币的两面。
在本篇文章中,我们采用因果推断作为工具,试图解释对抗样本使模型发生错误的原因。将神经网络给出的结果归因于输入图像的某些子区域,即究竟是哪些区域的变化导致了模型发生错误。
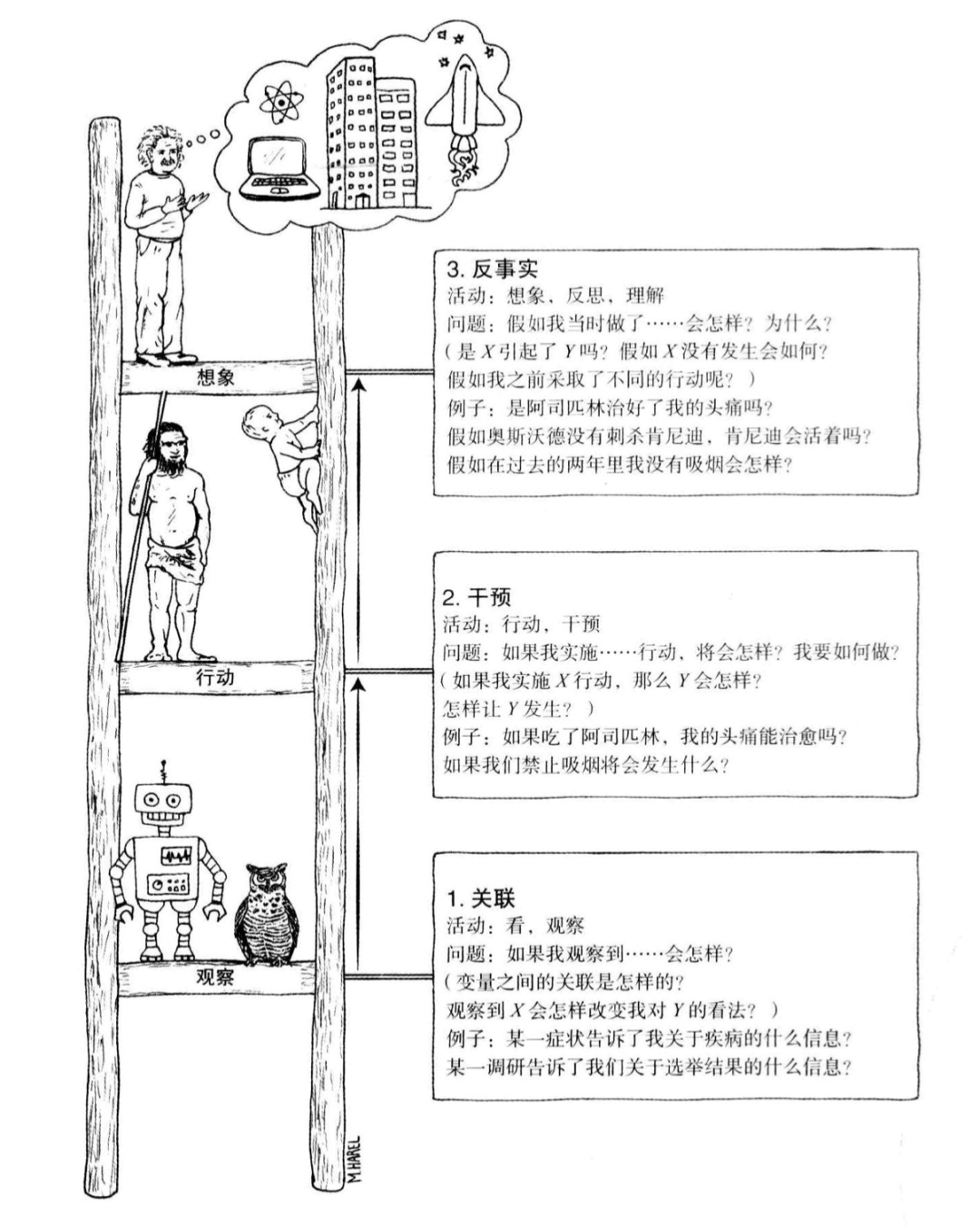
图二:因果之梯
因果推断是一种有别于统计观察的方法论。在较为传统的统计学派“频率派”眼中,所谓的因果、先验都只是人类头脑中的一种感觉,并不是真正的客观现实,是对自然发生的事物的一种很可能是歪曲的认识,只有观察到的数据本身才是唯一可靠的、绝对客观的。这种观点曾长期占据统计学的主流。
而统计学的“异端”则是贝叶斯学派,贝叶斯将概率区分为先验和后验,通过先验概率对观察到的数据进行“纠偏”得到后验概率。从而将人类的主观认识引入进来。这在频率派眼中简直“大逆不道”,纯粹客观的观察怎容主观先验玷污?然而因果推断还要走得更远,在因果的观点中,变量之间不再是平等的相关关系,而是不平等的因果关系。
如果我们将变量关系描述为一张图(graph)的话,变量是节点而变量之间的关系则是边,那么在统计的世界中这是一张无向图,而在因果的世界中,这张图一变而成为有向图,变量之间的关系是不平等的,有向图的边所链接的变量之间就区分成了因和果。而谁是因,谁是果,就成了我们引入的最大的先验,因为我们可以从纯粹的观察中发现两个变量之间是否存在边,却无法得到边的方向。
以上两种观点,即不应引入先验和可以引入先验究竟谁对谁错其实并没有定论,两者代表了两种世界观、两种方法论。但需要指出的是,因果的方法天然适合人类理解,也天然适合解释模型的行为。
深度学习的大厦基本上是建立在统计的方法论基础上的,训练模型就是是“观察”大量数据得到相关关系的过程。在面对对抗样本对其底层逻辑的挑战时,本文诉诸于因果的方法论,从解释对抗样本入手,跳出深度学习的“五行之外”看深度学习和对抗样本。
02
对抗样本的因果效应估计
2.1 建立因果图
首先是建立因果模型,即将我们对于这个问题的先验认识形式化地表达出来。本文采用因果图(Causal Graph)的形式,这是一种常用的因果模型的表现形式。在这个图中,节点表示变量,有向的边表示变量之间的因果关系,箭头的方向是从因指向果。
本文建立的因果图如图三所示。其中y为模型的输出,x’1 ... x’n表示对抗样本的n个子区域,x1 ... xn表示添加对抗扰动之前的原始样本的n个子区域,A表示对抗攻击方法,另外有两个隐含变量也表示在图中,即Z和R,这两个隐含变量表示了原始样本的因,其中Z表示与任务标签相关的因,R则表示与任务标签无关的因,例如在分类任务中,Z就代表了样本的真实类别,而R则代表与分类任务无关的背景、噪声等等因素的总和。
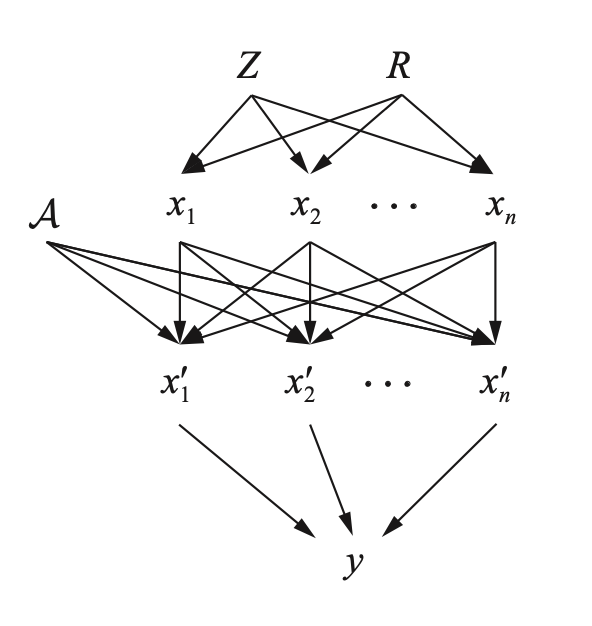
图三:对抗样本的因果图
2.2 基于干预的因果效应估计
在上述因果图中,只有对抗样本x’1 ... x’n、模型输出y是可见的,其余变量均不可见。当我们试图估计对抗样本的某个子区域x'i对与模型输出y的因果效应时,我们会发现,不可见的变量对两者而言是混杂因子,即如果在统计时不加以控制,就不能正确地得到两者之间的因果效应。而这些混杂因子却都因为不可见而无法控制。此时,我们发现单纯的“观察”已经无法实现我们的目标了。
因此我们采用“干预”的方法来估计x'i与模型输出y的因果效应。我们人为地创造出一个反事实样本,在这个样本中x'i被去除,该反事实样本同样可以通过模型得到输出yi,此时我们比较原本的输出y与yi就可以有效地估计x'i对于y的平均因果效应,如图四所示。
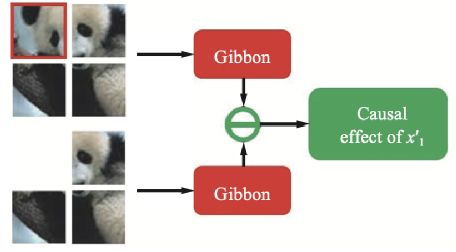
图四:基于干预的平均因果效应估计
这一简单直接的想法却有一个前提,那就是我们真的能够在完全不影响其他子区域的条件下去除图像中的某个子区域。卷积神经网络(CNNs)显然做不到这一点,其输入必须是规则的矩形数据。幸运的是,从自然语言处理领域发展而来的Vision Transformer(ViT)为我们提供了趁手的工具。由于自然语言数据没有固定的长度,Transformer必须要能够处理不定长的输入,由此,ViT同样可以处理不定长的token,即图像子区域。
2.3 可视化
上述方法估计得到的因果效应可以通过可视化直观的表达出来,如图五所示。
通过观察对抗样本的因果效应,我们至少可以发现以下几个现象:
1. 与干净样本相比,对抗样本中对输出具有正向因果效应的子区域更加稀疏;
2. 与干净样本相比,对抗样本的因果效应连续性更差,相邻的子区域很可能具有完全相反的因果效应,一个有利于增强当前输出,另一个有利于削弱当前输出;
3. 对抗样本中具有正向因果效应的子区域通常分布在原本就纹理丰富的区域,而非干净的背景等区域,这说明对抗样本往往对已有的图像内容加以修改而非无中生有。
相关的定量统计体现在Table 1中。其中mS为平均稀疏性度量,mTV则为平均连续性度量,具体计算方法可以参考我们的原文。

图五:(a)CIFAR-10因果效应可视化。(b)ImageNet因果效应可视化。
03
基于因果效应的对抗防御
3.1 对抗样本检测
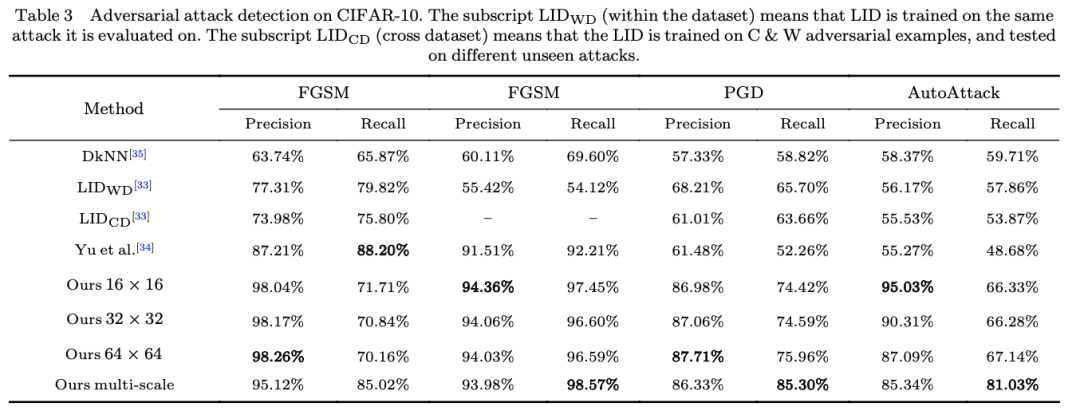
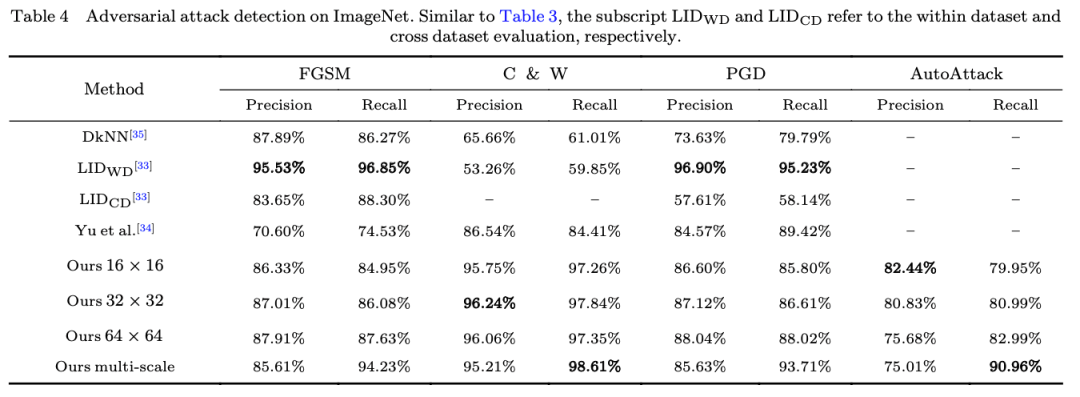
在对对抗样本的因果效应进行了一定程度的分析之后,我们不难在此基础上提出应对对抗样本的方法。我们不需要对识别模型进行任何改动,不需要大费周章地将对抗样本引入训练过程。基于上述关于对抗样本正向因果效益稀疏性的现象,我们将样本的所有子区域分为几个小组,分别送给识别模型进行处理,最终将得到的几个结果与全图送入识别模型得到的结果进行比较,如果与全图的结果出现明显差异,则拒绝处理。
这一十分简单的策略就已经超越了很多现有的方法,如Table3和Table4所示。这就是深入地认识带来的优雅。更多的实验分析包括关于Adaptive attack的实验可以参考原文。
3.2 对抗样本识别
最近,物理世界的对抗攻击逐渐引起了人们的重视。对一般的对抗样本不同,物理世界的对抗攻击样本往往不对扰动的大小进行限制,而是对图像的某些子区域进行大幅修改。这类攻击方法不仅大大降低了对抗攻击的成本,也给现实生活中的人工智能系统带来了真实的威胁,如图六所示。

图六:基于子区域的物理对抗攻击
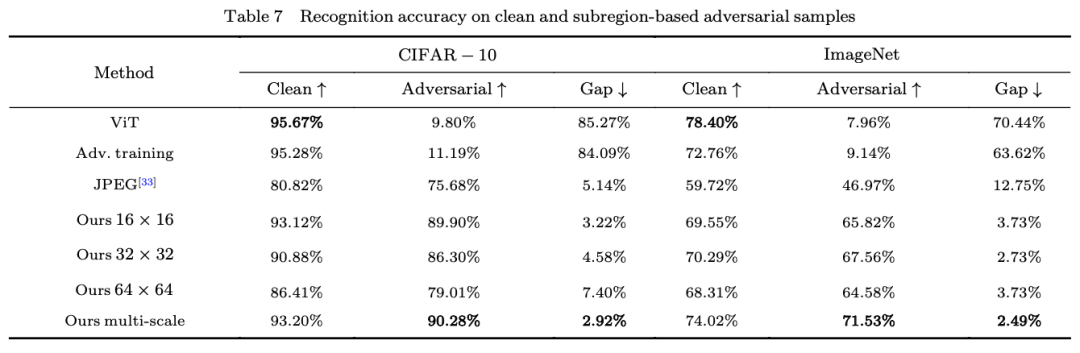
我们基于上述分析,提出一种简单有效的对抗样本识别方法。仍然将样本的所有子区域分为几个小组,分别送给识别模型进行处理,最终将得到的几个结果进行投票。实验证明这一简单的策略能够有效提升模型应对物理对抗攻击的能力。
04
总结
所谓“反者道之动”,深度学习发展到今天,已经在统计观察的道路上走向极致,前所未有的大数据,前所未有的大模型,让统计机器学习获得了巨大的能量。但那些来源于统计本身的问题,最终将把我们推向其反面去寻求答案。本文只是对对抗样本的一次粗浅的研究,但其带来的启发却值得研究者们深思。

















 898
898

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









