






Open-Sora 2.0是潞晨科技推出的全新开源SOTA视频生成模型,相比传统高性能视频生成模型大幅降低了训练成本。Open-Sora 2.0基于3D自编码器 、3D全注意力机制和MMDiT架构,结合高效的并行训练方案和高压缩比自编码器,显著提升训练效率和推理速度。
MindSpore团队现已完成对Open-Sora 2.0的适配,并将其开源至MindSpore ONE仓库,本文将要给大家详细介绍,如何基于昇思MindSpore和单机Atlas 800T A2,完整实现Open-Sora 2.0视频生成流程。
-
MindSpore ONE开源代码仓链接:https://github.com/mindspore-lab/mindone/tree/master/examples/opensora_hpcai
01效果展示

02模型介绍
1、Open-Sora 2.0 的主要功能
-
高质量视频生成:生成 720p 分辨率、24 FPS 的流畅视频,支持多种场景和风格,从自然光到复杂动态场景都能表现出色。
-
动作幅度可控:根据用户需求调整视频中人物或物体的动作幅度,实现更细腻、精准的动态表现。
-
文本到视频(T2V)生成:支持用文本描述直接生成对应的视频内容,满足创意视频制作和内容生成的需求。
-
图像到视频(I2V)生成:结合开源图像模型,基于图像生成视频,进一步提升生成效果和多样性。
2、Open-Sora 2.0 的技术原理
-
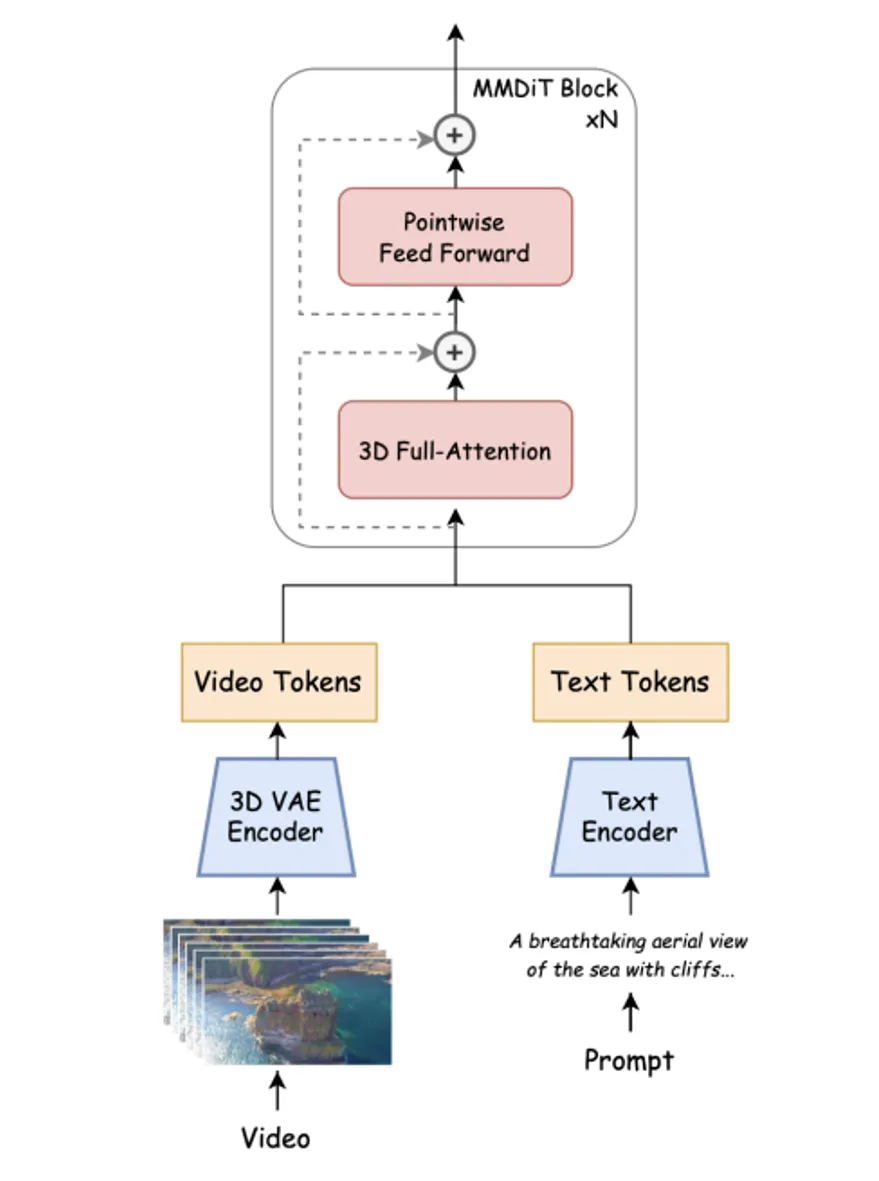
模型架构:基于三维自编码器高效处理视频数据,捕捉时间维度上的动态信息。引入全注意力机制,提升视频生成的时空一致性。结合多模态扩散(MMDIT)架构,更精准地捕捉文本与视频内容的关联。
-
高压缩比自编码器:基于 4×32×32 的高压缩比自编码器,显著降低推理成本。
-
高效训练方法:基于多阶段、多层次的数据筛选机制,确保高质量数据输入,提升训练效率。优先在低分辨率下训练,学习关键动态特征,逐步提升分辨率,大幅降低计算开销。优先训练图生视频任务,用图像特征引导视频生成,加速模型收敛。
-
模型初始化与蒸馏:借助开源图生视频模型 FLUX 进行初始化,降低训练成本。基于蒸馏的优化策略提升自编码器特征空间的表达能力,减少训练所需数据量和时间。
Open-Sora diffusion transformer架构图如下:
在代码实现上,关键的处理包括VAE模块对图片/视频的高比例压缩。Open-Sora 2.0借鉴了hunyuan_vae模块,核心压缩代码如下:
def spatial_tiled_encode(self, x: ms.tensor, return_moments: bool = False) -> DiagonalGaussianDistribution:
r"""Encode a batch of images/videos using a tiled encoder.
....
for j in range(0, x.shape[-1], overlap_size):
tile = x[:, :, :, i : i + self.tile_sample_min_size, j : j + self.tile_sample_min_size]
tile = self.encoder(tile) # hunyuan_vae对图片/视频进行高比例压缩
tile = self.quant_conv(tile)
row.append(tile)
...
posterior = DiagonalGaussianDistribution(moments)
return posterior通过该高压缩比视频自编码器,视频生成成本将大幅降低,推理加速效果显著。
03 快速上手
1、环境准备
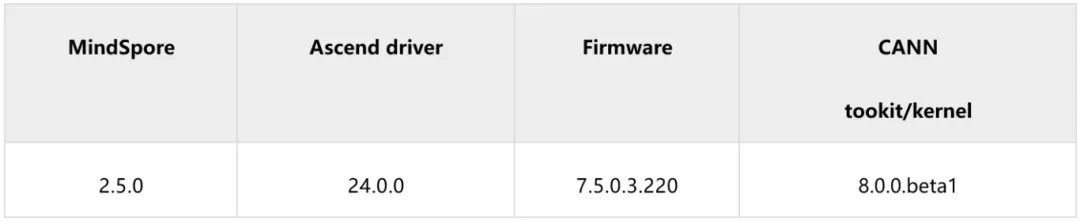
- CANN下载:https://www.hiascend.com/developer/download/community/result?cann=8.0.0.beta1
- MindSpore下载:https://www.mindspore.cn/install
2、安装依赖
git clone https://github.com/mindspore-lab/mindone
cd mindone/examples/opensora_hpcai
pip install -r requirements.txt3、模型下载
| 模型 | 下载链接 | 说明 |
| hpcai-tech/Open-Sora-v2 | https://huggingface.co/hpcai-tech/Open-Sora-v2 | Open-Sora 2.0权重,包括模型核心权重、VAE权重和text encoder权重 |
| hpcai-tech/Open-Sora-v2-Video-DC-AE | https://huggingface.co/hpcai-tech/Open-Sora-v2-Video-DC-AE | Open-Sora 2.0 DC-AE编码器权重 |
从 Hugging Face 下载所需的模型,可以参考如下命令:
huggingface-cli download hpcai-tech/Open-Sora-v2 --local-dir ./ckpts4、运行推理
生成text embedding,包括真实的prompts和negative prompts。
TRANSFORMERS_OFFLINE=1 python scripts/v2.0/text_embedding.py --model.from_pretrained=openai/clip-vit-large-patch14 --model.max_length=77 --prompts_file=FILE_WITH_PROMPTS --output_path=assets/texts/clip
TRANSFORMERS_OFFLINE=1 python scripts/v2.0/text_embedding.py --model.from_pretrained=DeepFlo开始推理
python scripts/v2.0/inference_v2.py
--config=configs/opensora-v2-0/inference/256px.yaml
--text_emb.t5_dir=FOLDER_WITH_T5_PROMPTS
--text_emb.neg_t5_dir=FOLDER_WITH_T5_NEG_PROMPTS
--text_emb.clip_dir=FOLDER_WITH_CLIP_PROMPTS
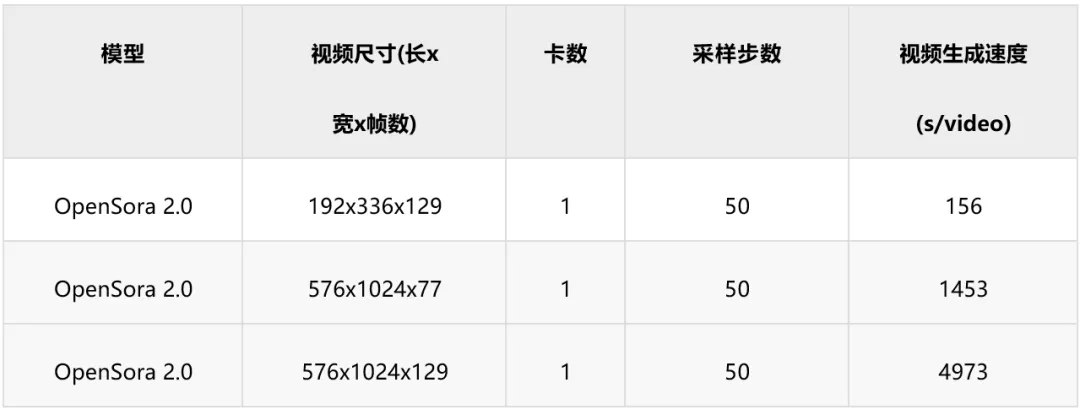
--text_emb.neg_clip_dir=FOLDER_WITH_CLIP_NEG_PROMPTS04 性能实测
基于Atlas 800T A2和MindSpore2.5.0的性能测试结果如下:
05 马上体验
魔乐社区也已完成Open-Sora 2.0,欢迎体验:https://modelers.cn/spaces/MindSpore-Lab/Sora_hpcai_2.0

















 895
895

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









