







 1、分类算法-决策树、随机森林H的专业术语称之为信息熵,单位为比特。 公式:2、决策树的划分依据之一-信息增益特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:3、sklearn决策树API:class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)决策树分类器crit...
1、分类算法-决策树、随机森林H的专业术语称之为信息熵,单位为比特。 公式:2、决策树的划分依据之一-信息增益特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:3、sklearn决策树API:class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)决策树分类器crit...
1、分类算法-决策树、随机森林
H的专业术语称之为信息熵,单位为比特。 公式: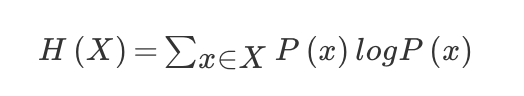
2、决策树的划分依据之一-信息增益
特征A对训练数据集D的信息增益g(D,A),定义为集合D的信息熵H(D)与特征A给定条件下D的信息条件熵H(D|A)之差,即公式为:
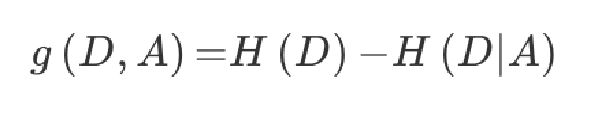
3、sklearn决策树API:class sklearn.tree.DecisionTreeClassifier(criterion=’gini’, max_depth=None,random_state=None)
决策树分类器
criterion:默认是’gini’系数,也可以选择信息增益的熵’entropy’
max_depth:树的深度大小
random_state:随机数种子
method:
decision_path:返回决策树的路径
4、sklearn.tree.export_graphviz() 该函数能够导出DOT格式 tree.export_graphviz(estimator,out_file='tree.dot’,feature_names=[‘’,’’])
5、集成学习方法-随机森林
集成学习通过建立几个模型组合的来解决单一预测问题。它的工作原理是生成多个分类器/模型,各自独立地学习和作出预测。这些预测最后结合成单预测,因此优于任何一个单分类的做
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 12万+
12万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









