







看完了sparse coding,开始看ICA模型,本来ng的教程上面就只有一个简短的介绍,怎奈自己有强迫症,爱钻牛角尖,于是乎就搜索了一些ICA的介绍文章(都是从百度文库中搜来的),看完之后感觉这个略懂一二,遂写文以记之,一为加深印象,二为分享交流。
一:引言
ICA IndependentComponent Analysis 又名独立分量分析。
ICA是20世纪90年代发展起来的一种新的信号处理技术,它是从多维统计数据中找出隐含因子或分量的方法。从线性变换和线性空间角度,源信号为相互独立的非高斯信号,可以看作线性空间的基信号,而观测信号则为源信号的线性组合,ICA就是在源信号和线性变换均不可知的情况下,从观测的混合信号中估计出数据空间的基本结构或者说源信号。
二:ICA模型介绍
2.1.Blind Signal Separation, BSS问题
BSS问题,即盲信号分离问题,是信号处理中一个传统而又极具挑战性的课题。BSS是指仅从观测的混合信号(通常是多个传感器的输出)中恢复独立的源信号,这里的“盲”是指:1.源信号是不可观测的;2.混合系统是事先未知的。在科学研究和工程应用中,很多观测信号都可以假设成是不可见的源信号的混合。所谓的“鸡尾酒会”问题就是一个典型的例子,简单说就是当很多人(作为不同的声音源)同时在一个房间里说话时,声音信号由一组麦克风记录下来,这样每个麦克风记录的信号是所有人声音的一个混合,也就是通常所说的观测信号。问题是:如何只从这组观测信号中提取每个说话者的声音信号,即源信号。如果混合系统是已知的,则以上问题就退化成简单的求混合矩阵的逆矩阵。但是在更多的情况下,人们无法获取有关混合系统的先验知识,这就要求人们从观测信号来推断这个混合矩阵,实现盲源分离。
经典的鸡尾酒宴会问题(cocktail party problem)。假设在party中有n个人,他们可以同时说话,我们也在房间中一些角落里共放置了n个声音接收器用来记录声音。宴会后,从n个麦克风中得到一组数据Xi(Xi1,Xi2,……Xin)i=1,2……m,i表示采样的时间顺序,也就是说共得到了m组采样,每一组采样都是n维的。我们的目标是单单从这m组采样数据中分辨出每个人说话的信号。

问题总结:
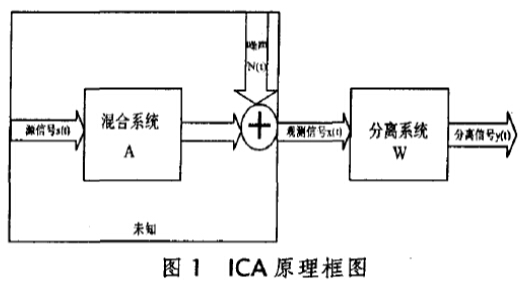
ICA的目的是对任何t,根据已知X(t)的在A未知的情况下求未知的S(t),ICA的思路是设置一个n*n维反混合阵W,经过变换后得到n维输出列向量Y(t)=[y1(t),y2(t),……y3(t)],即有 :
Y(t)=W*X(t)=W*A*S(t)
基本独立分量分析的线性模型还有一些假设;例如1,信号源之间相互统计独立;2,信号源中最多有一个是高斯分布;3,观测信号的数目和信号源的数目相等等。完整假设请参看文末的参考文献。
三:模型转化
通过上面的分析可知,已知混合信号X,来寻找分离矩阵W,然后计算WX来找到Y,即原始信号S的估计值。
在模型中我们假设各个信号S间是相互独立的,所以我么求解得到的Y的分量间也是相互独立的,所以在未知A,W,只有观测数据X的情况下,我们通过度量Y各个分量间的独立性,来评判求解结果的好坏。Y的各分量独立性越好,说明Y越接近S的真实值,此时的分离矩阵W也越好。
这样盲源分离问题就变成了,一个优化问题,已知数据X,随机初始化一个分离矩阵W;通过变换WX的到Y,要求Y各个分量间相互独立;通过度量Y分量间的独立性,来寻找最好的分解矩阵W。如图所示

ICA算法分为两个部分,1优化判据;2,寻优算法
这里先说一下这个简略介绍的寻优算法,其实有时寻找目标函数最优值的算法,例如经典的梯度下降算法等,由于这里重点介绍ICA模型,所以寻优算法简略提一下。
下面就来介绍ICA的精髓部分,就是优化判据,就是判断结果好不好的依据,那么在ICA中,根据我们的介绍我们的判据就是Y各个“分量间相互独立性”。那么如何度量Y变量之间的相互独立性呢?
度量变量之间的相互独立性,这里分为两种方法,一种是通过统计中特征值来度量,例如四阶中心距,峭度(kurt)等,一种是通过信息论中熵的概念来度量。
在详细介绍度量之前先介绍一些相关的引理,先吃一些饭前的辅餐,然后再来消化后面的饕餮大餐。
四:基础知识介绍
4.1 概率论基本知识
线性变换下两个pdf(probability density function,概率密度函数)之间的关系
设X为n维随机向量,其pdf为p(X)。线性变换Y=WX,W为满秩n*n维矩阵。这样,Y也是n维随机向量,其pdf为p(Y)。这两个随机向量的pdf之间满足下列关系:
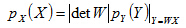

其中是的行列式,注意下式成立:
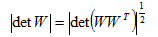
非线性变换下两个pdf之间的关系,若Y=g(X),其中g(.)为非线性变换函数。需要计算g函数的雅克比矩阵来变换p(X)和p(Y)之间的关系,在此不详述。
4.2 统计知识
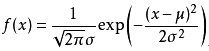
4.3 矩
对于单个随机变量x,所谓矩是描述随机变量性质的一种统计量,它是一系列依赖于概率密度函数的描述性的离散参数。
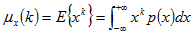
式中,Ux(K)表示第阶k(原点)矩。很显然,一阶矩Ux(1)=E{x}=Mx是x的均值。而x的中心矩则是用来描述对均值Mx而言的分布特性的一系列参数。
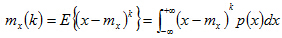
当均值为零时,k阶中心矩和k阶原点矩是等价的。对实际的样本数据而言矩的估计方法非常简单,所以具有很高的实用性。二阶中心矩是指方差,反映了信号的能量;三阶中心矩度量了概率密度函数关于均值处的不对称程度。具有对称分布的概率密度函数其三阶中心矩为零。四阶中心矩被用来度量概率分布的峭度。通常简记为。
4.4信息论知识
4.4.1 熵
信息论中,熵通常是用来衡量信源发出每一个消息的平均不确定度,概率愈小的消息带来的信息量愈大,熵也就愈大。连续情况下,对于一个随机变量x,如果它的密度函数为p(x),则x的熵定义为:
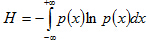
用数学期望的形式来表示则为H=E{ln(1/p)}=-E{ln(p)}。值得指出的是,在所有的连续概率密度函数中,如果均值Ux和方差sigma^2都取已知的固定值,则使熵达到最大值的将是高斯分布,此时的最大熵为H=0,5+log(2,sqrt(2*pi*sigma)) (比特)。
可以把定义推广到随机矢量的联合微分熵:
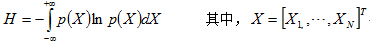
为将熵应用在ICA算法中,下面考虑可逆的线性变换对联合熵的影响。对于具有联合密度函数px(X)的n维随机变量X=[X1,X2..Xn],以及一个非奇异矩阵W,得到联合密度函数py(Y)的n维随机变量Y=[Y1,Y2..Yn]。由概率论可知:
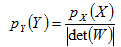
根据熵的定义,于是可得:
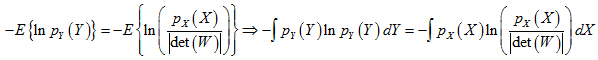
进一步写成:
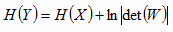
上式意味着可逆的线性变换对随机矢量联合熵的影响是增加了一个常数项,如果这个线性变换是一个正交变换,满足det(W)=1,则有:
H(Y)=H(X)
所以得到一个更加重要的结论是:多维分布经过坐标系的旋转后联合微分熵保持不变.
4.4.3 相对熵
假设对同一个随机矢量X,有两种可能形式的概率分布p(x)和q(x)。为了衡量这两个分布之间的距离,定义相对熵(或称作“Kullback-Leibler距离”,是一个与“交叉熵”,“信息散度”和“判别信息量”的概念密切相关的量)。连续情况下的相对熵定义为:
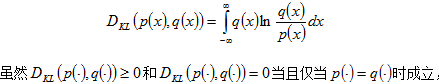
4.4.4 负熵(高斯分布熵和其他分布熵的相对熵)
概率论中的中心极限定理这一经典理论告诉我们:在一定条件下,多个独立分布的和的分布趋向于高斯分布。将该理论应用到ICA问题里可以得出这样的结论:观测信号是多个独立源信号的线性组合,所以其高斯性比源信号的高斯性强,换句话说,源信号的非高斯性比观测信号的非高斯性要强。粗略地讲就是,非高斯性愈强就愈独立。这就启示我们将非高斯性作为ICA的一个判据。除了峭度可以用来表征非高斯性外,负熵是度量非高斯性的一个更加稳健的判据。
在定义负熵之前先给出信息论中的一个结论,即所谓的熵极大定理:在所有具有相同协方差矩阵的分布中,高斯分布的熵最大,简单运用K-L散度的性质便可以证明这个定理(详细见参考文献)。在一定的限制条件下,可以找到一个特定的分布具有最大的信息熵。而上述定理中的这个特定的分布恰好是高斯分布。
负熵的概念因此产生。负熵定义为:
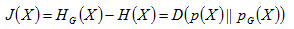
pG(x)和p(x)具有相同协方差阵的高斯概率密度函数。有负熵的定义可以得出,负熵J(x)>=0,当且仅当p(x)也为高斯分布时,J(x)=0.
负熵的一个重要性质是:对于可逆的线性变换保持不变。显然,与熵对于正交变换(det(W)=1)保持不变相比负熵需要的条件更加宽松。该性质使得可以将边缘J(Yi)负熵作为代价函数,然后寻找线性变换W使其最大化。这就导致了ICA算法中负熵判据的有效性。
4.5互传信息量
互信息(Mutual Information,简称MI)是用来度量随机变量之间独立性的基本准则,互信息可以表示成K-L散度的形式。多个随机变量之间的互信息定义为其联合概率密度函数与各边缘密度函数乘积之间的K-L散度,即:
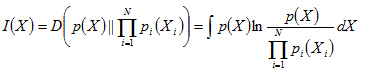
将上式右边继续展开:
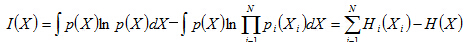
由于K-L散度的非负性可知:
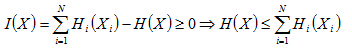
容易看出,当X=[X1,X2....Xn]的各个分量相互独立时,即有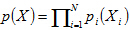
得出一个重要结论:I(x)>=0,当且仅当各个分量相互独立时等号成立。进一步观察,各分量边缘熵的和总是大于或等于所有分量的联合熵,而多出的那部分恰好是各分量的互信息。那么互信息可以描述为由于各个分量之间的相互依赖关系带来的信息的冗余。
参考文献:
1 言简意赅的ppt:http://wenku.baidu.com/view/8fa7f71b6bd97f192279e9aa.html















 1873
1873

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









