







ICA算法的研究可分为基于信息论准则的迭代估计方法和基于统计学的代数方法两大类,从原理上来说,它们都是利用了源信号的独立性和非高斯性。基于信息论的方法研究中,各国学者从最大熵、最小互信息、最大似然和负熵最大化等角度提出了一系列估计算法。如FastICA算法, Infomax算法,最大似然估计算法等。基于统计学的方法主要有二阶累积量、四阶累积量等高阶累积量方法。
一:最大似然估计算法
1.1 目标函数部分
我们假设信号Si有概率密度函数Ps(t),由于我们假定信号源是相互独立的,其实经过白化处理后就变成独立的了;那么在给定时刻的联合分布函数为:
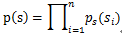
知道了信号源的联合分布Ps(t),再由分解矩阵S=WX,可以得出信号x的联合分布函数。
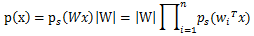
其中|W|为W的行列式。
由于没有先验知识,只知道原信号之间特征独立,且最多有一个是高斯分布,所以我们没有办法确定Ps(t)的分布,所以我们选取一个概率密度函数Ps^(t)来近似估计Ps(t)。
在概率论中我们知道概率密度函数由累积分布函数F(x)(cumulative distribution function,cdf)求导得到。
F(x)要满足两个性质:1,单调递增;2,值域在[0 1]范围
我们发现sigmoid函数的定义域是负无穷到正无穷,值域为0到1,缓慢递增的性质。基于sigmoid函数良好的性质,我们用sigmoid函数来近似估计F(x),通过求导得到Ps^(t)。
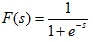
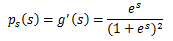
两函数图像如图:

怎么感觉pdf 函数g(s)这么像高斯分布函数呢??这个有点不理解(以后在研究吧)。
如果我们预先知道Ps(t)的分布函数,那就不用假设了;但是在缺失的情况下,sigmoid函数大多数情况下能够起到不错的效果。由于Ps(t)s是个对称函数,所以均值E[s]=0,那么E[x]=E[AS]=0,x的均值也是0。
知道了Ps(t),就剩下W了,在给定训练样本{Xi(Xi1,Xi2,........Xin),i=1,2....m个样本,样本的对数似然估计如下:
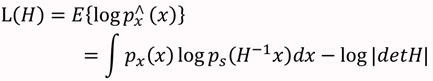
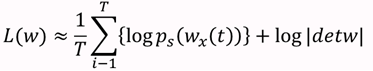
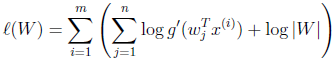
T=m为独立同分布观测数据的样本数。最大化此似然函数就可获得关于参数W 的最佳估计。
1.2 优化部分(梯度下降算法)
接下来就是对W求导了,这里牵涉一个问题是对行列式|W|进行求导的方法,属于矩阵微积分
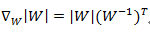
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章
















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









