







 本文介绍了结构光深度测距技术,与普通双目测距的区别在于结构光通过编码光源提供匹配点,降低匹配难度。结构光编码的关键包括码字设计、识别和噪声处理,其中伪随机序列作为编码手段,具有周期性和窗口特性。激光散斑技术是另一种方法,利用散斑的随机性和位置变化获取物体信息。这种方法不需要特制感光芯片,但激光器寿命短,易受阳光干扰。
本文介绍了结构光深度测距技术,与普通双目测距的区别在于结构光通过编码光源提供匹配点,降低匹配难度。结构光编码的关键包括码字设计、识别和噪声处理,其中伪随机序列作为编码手段,具有周期性和窗口特性。激光散斑技术是另一种方法,利用散斑的随机性和位置变化获取物体信息。这种方法不需要特制感光芯片,但激光器寿命短,易受阳光干扰。
原文:
http://blog.sina.com.cn/s/blog_80ce3a550100wg5j.html
http://blog.csdn.net/u013360881/article/details/51395427
网上资源:
http://eia.udg.es/~qsalvi/recerca.html
结构光编码:
在3D 的深度获取上,最为常见的方法是类似于双目匹配获取深度的方法,双目匹配完全基于图像处理技术,通过寻找两个图像中的相同的特征点得到匹配点,从而得到深度值;完全基于图像匹配的方法有很大的困难,匹配的精度和正确性很难保证;因此出现了结构光技术用来解决匹配问题。
同普通的双目测距相比:
普通的双目测距中,光源是环境光或者白光这种没有经过编码的光源,图像识别完全取决于被拍摄的物体本身的特征点,因此匹配一直是双目的一个难点;而结构光测距的不同在于对投射光源进行了编码或者说是特征化。这样,拍摄的是被编码的光源投影到物体上被物体表面的深度调制过的图像,因为结构光光源带有很多特征点或者编码,因此提供了很多的匹配角点或者直接的码字,可以很方便的进行特征点的匹配,换句话说结构光主动提供了很多特征点进行匹配或者直接提供码字,而不再需要使用被摄物体本身具有的特征点,因此可以提供更好的匹配结果。
匹配上的差别:
双目使用的是物体本身的特征点,而结构光使用的是光源主动提供的特征点或者直接的码字.另外一个差别在于由于拍摄物体多种多样,每一次双目匹配都面对不同的图像,都需要重新提取特征点;而结构光投影的是相同的图案,特征点是固定的,不需要根据场景的变化而有变化,降低了匹配的难度。
根据采样定律,可以认为相机拍摄投影的结构光是一个采样过程,因此必须满足2倍频率的采样要求,这就导致拍摄的图像的分辨率必须高于投影的结构光图像的分辨率(水平,垂直分辨率都是2倍);
结构光测距的理论基础:(从calibration来解释,双目测距的基本原理),参考论文“结构光编码方法综述"
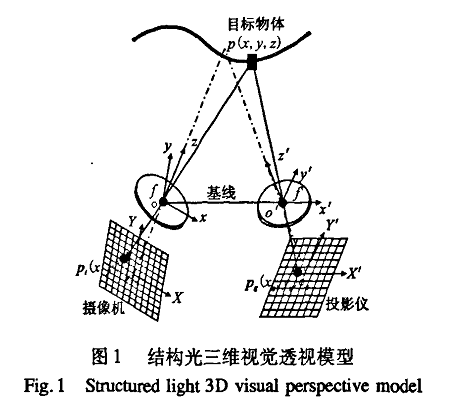
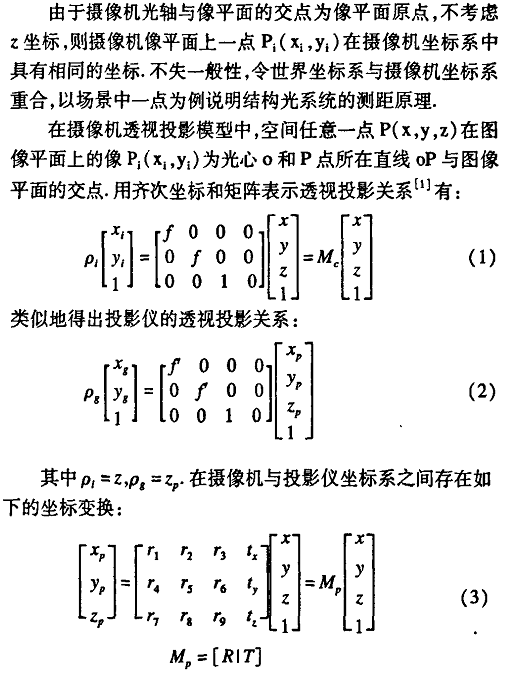

上面假设了摄像机坐标系就是世界坐标系,而相机和物体是完全平行的,也就是说物体在世界坐标系中的x,y坐标和摄像机坐标系中的x,y是一样的,因此不存在R,T的外参数矩阵。在不考虑z的情况下可以简化为上面的内参数和世界坐标系的映射得到像平面坐标系坐标。而结构光投影设备不满足相机的假设,因此投影设备和空间点(x,y,z)之间存在R|T的外参数。已知投影设备和相机的内参数矩阵的情况下,而且外参数通过通用的标定算法预先计算好,那么Z的值可以通过该空间点在投影设备上的映射点(Xg,Yg)和在相机像平面上的映射点(Xi,Yi)计算得到,可见,在这种情况下,标定内外参数和获得空间点在投影设备和相机像平面上的对应点是计算Z的关键。
相机标定已经是一个成熟的领域,有很多方法比如张正友法等,这里不分析。
投影设备和相机像平面的对应点匹配是另外一个关键的步骤。这同双目匹配的原理完全相同。唯一不同的就是结构光测距的方法在进行对应点匹配时比双目匹配的纯图像处理方法提供了更加多的辅助信息。提供什么样的辅助信息来帮助快速而精确的对应点匹配是结构光编码方法的衡量标准。

码字设计和识别是结构光编码的设计要点。另外,由于拍摄的图像本身存在一些噪声,在编码时如何进行设计使得可以进行纠错(和通信中的信道编码类似),通过投影一个预先设计过的图案作为参考图像(编码光源),投影到空间中,使用相机拍摄投影到空间中的图案作为测试图像,这样,同样获得了两幅图像,一幅是预先设计的参考图像,另外一幅是相机的获取图像,同样可以进行图像匹配,这种方法比双目匹配好的地方在于,参考图像不是获取的,而且是经过专门设计的图案,因此特征点是已知的,而且更容易从测试图像中提取;
更加高级的是,可以使用编码结构光的方法,这些设计的图案是经过编码的(可以认为由有限个具有唯一性的子图案的集合组成的投影图像),参考图像中每一个唯一的图像窗口中的图案都是唯一的;通过相机拍摄空间投影的图像,经过处理后,开始在拍摄到的测试图像中寻找各个唯一的编码的图案(pattern识别),找到一个图案ID后,可以直接在参考图像中查表来找到对应(每一个设计过的图案ID在参考图像中的位置都是已经确定的);通过编码结构光的方法,就不需要进行图像的匹配,而是转换成了在测试图像中寻找编码过的具有唯一性的子图案的ID(类似于每一个设计过的子图案作为小的模板,通过这种模块匹配来找到唯一的子图案或者直接就是将ID进行编码隐藏到了测试图像中,通过解码即可得到ID,比如时间序列的gray码编码等).pattern encoding/decoding
总结来说:基于编码结构光的方法中,参考图像是经过预先设计的,由多个不重复的子图案组成;每一个子图案在参考图像中的位置是预先确定的(参考图案的设计包括子图案的设计和子图案在参考图案中的位置ID).可以认为是存在一张参考图案中各个子图案的ID和位置的查找表:
子图案ID
。。。。。
通过投影设备将这个预先设计好的参考图案投影到空间中。使用相机拍摄投影到空间中的参考图案,得到测试图像,在测试图像中找到这些唯一的子图案的ID,得到一个实际的位置,通过ID去查表得到其在参考图案中的位置,这样就完成了图像的匹配。
另外一种更加高级的做法是,这些子图案本身可能就是包含位置的编码,因此直接解码子图案就可以得到位置,连查表都不需要了。

上面就是一个例子,通过时序帧对空间进行划分成不同的区域,测试图像是多幅,通过叠加可以得到二进制编码的空间位置的ID,这里是将空间划分成了32个子区域,每个子区域具有相同的编码,不区分
结构光编码是基于双目测距原理发展而来,但是巧妙的解决了双目匹配中的图像匹配这个难点,因此比单纯的双目匹配更加的有效。
所谓的随机指的相关函数是高斯的,只有自相关时为1,互相关为接近0.
所谓的伪:指的是产生的方法是确定的,也就是这种序列是可以有确定的方法来重复产生的,而且具有周期性,而不像真正的随机序列是无法重复产生而且不具有周期性的。在通信从通常使用LFSR线性反馈移位寄存器来产生伪随机序列:
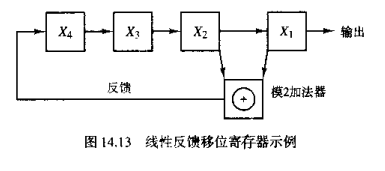
假设初始的状态中(X4,X3,X2,X1)是1000
现在开始移位:X1+X2 = 0, 新移入的为0, 则当前寄存器中的值为0100,输出0
反复进行: 1000,0100,0010,1001,1100,0110,1011,0101,1010,1101,1110,1111,0111,0011,0001,1000。
输出为: 111101011001000 (右边的最先输出)
一维随机码:
周期性: 理论上的最大周期为2^4 = 16, 也就是每一个寄存器都遍历过0和1两个值的数目,排列组合这个例子中的周期=16,经过16次移位后寄存器的值还原为初始值。
窗口特性: 用一个较小的窗口进行滑动,得到的窗口内的序列是唯一的。这是可以推导的,从上面这个例子中可以看到,窗口取4正好就是寄存器在某时刻的值,肯定是唯一的。
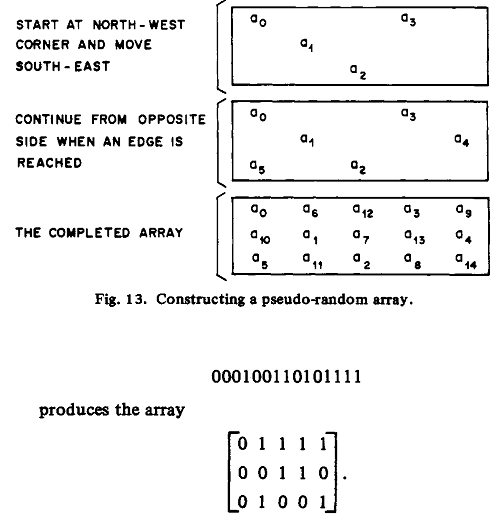
折叠原理: 比如一个1维的伪随机序列,可以在任何位置折叠成高维比如2维的序列仍然是伪随机的。比如周期为3^9 -1=19682的序列可以折叠为26x757=19682的二维伪随机序列。M-ARRAY折叠方法如下:
多元域:
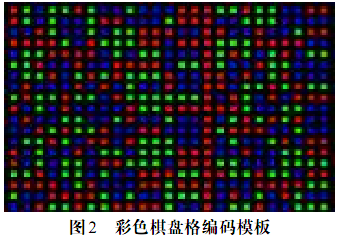
同样的还存在二维伪随机码等:
随机码组成一个KxL的矩阵,window size为vxw,每个window包含的码字只出现一次。同样具有一维伪随机码的各种特点包括窗口特性,周期性等。
在结构光编码中,假设已经知道了伪随机序列的产生方法和值,那么我们就知道了下面的信息:
周期大小,窗口大小,这个已知的伪随机序列就是参考图像或者说是编码模板。在匹配中使用正确的窗口大小在拍摄的图片中进行滑动,对窗口中的图案进行解码,得到该窗口内的伪随机序列的片段,这个片段在已知的编码模板中搜索同样片段进行比较,如果距离为0,那么就得到了匹配点。

可见,这种结构光编码的方法需要预先知道编码模板,并在测试图像中正确的提取到片段信息才能正确。由于伪随机序列具有的窗口特性(窗口内的符号是唯一的),因此比较适合用于结构光编码。
激光散斑:激光在散射体表面的漫反射或通过一个透明散射体(如毛玻璃)时,在散射表面或附近的光场中可以观察到一种无规分布的亮暗斑点,这种斑点称为激光散斑(Laser Speckles)。
激光散斑是由无规散射体被相干光照射产生的,因此是一种随机过程。要研究它必须使用概率统计的方法。通过统计方法的研究,可以认识到散斑的强度分布、对比度和散斑运动规律等特点。最重要的特点就是,这种散斑具有高度的随机性,而且随着距离的不同会出现不同的图案,也就是说,在同一空间中任何两个地方的散斑图案都不相同。只要在空间中打上这样的结构光然后加以记忆就让整个空间都像是被做了标记,然后把一个物体放入这个空间后只需要从物体的散斑图案变化就可以知道这个物体的具体位置。
应用:
用散斑的对比度测量反射表面的粗糙度;
利用散斑的动态情况测量物体运动的速度;
利用散斑进行光学信息处理,甚至利用散斑验光等。
激光在成像领域极具潜力。但“光斑”问题却一直困扰着人们:当传统激光器被用于成像时,由于高空间相干性,会产生大量随机的斑点或颗粒状的图案,严重影响成像效果。一种能够避免这种失真的方法是使用LED光源。但问题是,对高速成像而言,LED光源的亮度并不够。
结构光:首先将结构光投射至物体表面,再使用摄像机接收该物体表面反射的结构光图案,由于接收图案必会因物体的立体型状而发生变形,故可以试图通过该图案在摄像机上的位置和形变程度来计算物体表面的空间信息。普通的结构光方法仍然是部分采用了三角测距原理的深度计算。
与结构光法不同的是,Light Coding的光源称为“激光散斑”,是激光照射到粗糙物体或穿透毛玻璃后随机形成的衍射斑点。这些散斑具有高度的随机性,而且会随着距离的不同而变换图案。也就是说空间中任意两处的散斑图案都是不同的。只要在空间中打上这样的结构光,整个空间就都被做了标记,把一个物体放进这个空间,只要看看物体上面的散斑图案,就可以知道这个物体在什么位置了。当然,在这之前要把整个空间的散斑图案都记录下来,所以要先做一次光源标定。
概括一下,Light Coding与传统的ToF、结构光技术的不同之处在于:
1)和传统的ToF、结构光的光源不同,激光散斑是当激光照射到粗糙物体或穿透毛玻璃后形成的随机衍射斑点;
2)不需要特制的感光芯片,只需要普通的CMOS感光芯片;
3)Light Coding技术不是通过空间几何关系求解的,它的测量精度只和标定时取的参考面的密度有关,参考面越密测量越精确。传统结构光方法采用三角视差测距,基线长度(光源与镜头光心的距离)越长越好。换句话说,不用为了提高精度而将基线拉宽。这其中的奥秘就是“激光散斑原理”。
缺点:
激光器发出的编码光斑容易太阳光淹没掉
结构光方案中的激光器寿命较短,难以满足7*24小时的长时间工作要求,其长时间连续工作很容易损坏。因为单目镜头和激光器需要进行精确的标定,一旦损坏,替换激光器时重新进行两者的标定是非常困难的,所以往往导致整个模块都要一起被换掉















 935
935

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









