







什么是主成分分析?
主成分分析(Principal Component Analysis, PCA)是一种统计方法,用于降维和探索数据中的结构和特征。PCA通过将高维数据投影到较低维度空间,提取数据中最重要的特征,同时尽可能保留原始数据的变异性。以下是PCA的详细介绍:
目的和应用
降维:在保留数据主要信息的前提下,减少数据的维度,简化数据结构。
数据压缩:减少数据的存储需求。
特征提取:识别和提取数据中的主要特征。
去噪:通过保留主要成分,减少噪声对数据分析的影响。
可视化:将高维数据投影到二维或三维空间,以便进行可视化分析。
2. 基本原理
PCA的基本思想是通过线性变换将数据投影到新的坐标系,使得数据的方差最大化。具体步骤如下:
2.1 数据中心化
将数据每一维度的均值减去,使数据中心化,即均值为零。
2.2 计算协方差矩阵
计算数据的协方差矩阵,描述各个维度之间的线性关系。
2.3 特征值分解
对协方差矩阵进行特征值分解,得到特征值和特征向量。
2.4 选择主成分
选择最大的 \( k \) 个特征值对应的特征向量,作为新的坐标系。这些特征向量称为主成分。
2.5 数据变换
将原始数据投影到选定的主成分上,得到降维后的数据。
3. 步骤示例
假设我们有一个二维数据集,我们希望将其降维到一维。具体步骤如下:
3.1 数据中心化
假设数据集 \( X \) 的均值是 \( \mu \),将每个数据点减去均值:
3.2 计算协方差矩阵
3.3 特征值分解
计算协方差矩阵 \( C \) 的特征值和特征向量。
3.4 选择主成分
选择最大的特征值对应的特征向量 \( u \) 作为主成分方向。
3.5 数据变换
将原始数据投影到主成分方向上,得到一维数据:
4. 示例代码
% 数据生成
X = randn(100, 2); % 生成100个二维数据点
% 数据中心化
X = X - mean(X);
% 计算协方差矩阵
C = cov(X);
% 特征值分解
[V, E] = eig(C);
% 选择主成分
[emax, emax_ind] = max(diag(E));
u = V(:, emax_ind);
% 数据变换
z = X * u;
% 绘图
figure;
scatter(X(:,1), X(:,2));
hold on;
scatter(z * u(1), z * u(2));
legend('原始数据', '降维后的数据');
title('PCA降维示例');
以下是一个简单的示例代码,展示如何使用PCA对二维数据进行降维:
5. 总结
主成分分析是一种强大的工具,广泛应用于数据降维、特征提取、数据压缩和可视化。通过将高维数据投影到较低维度空间,PCA能够揭示数据的内在结构,同时保留尽可能多的信息。
3. 本文设计的代码
部分代码
clc;
clear;
close all;
% Generate Date
W = randn(1000, 2);
A = rand(2, 2);
X = W*A;
% Covariance Matrix
C = cov(X);
% Find PC1
[V, E] = eig(C);
[emax, emax_ind] = max(diag(E));
u = V(:, emax_ind);
% Transform Data
z = X*u;
% Decode Data
Y = z*u';
% Plot Results
figure;
scatter(X(:,1), X(:,2));
hold on;
scatter(Y(:,1), Y(:,2));
代码运行效果
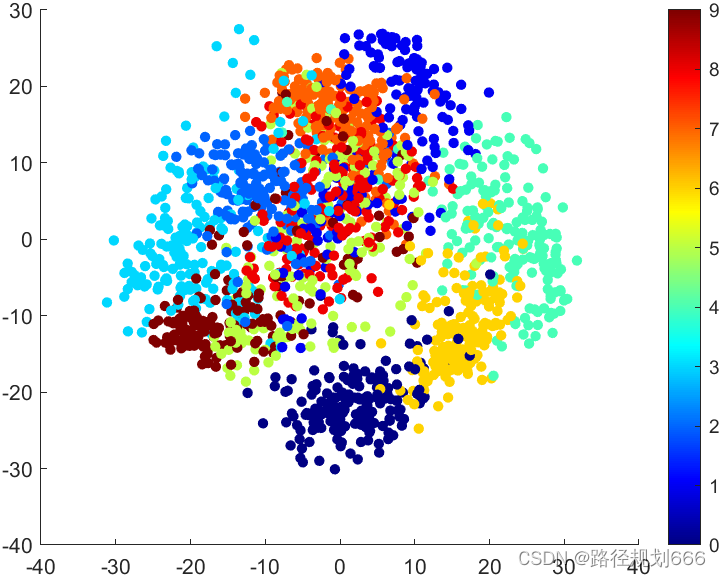
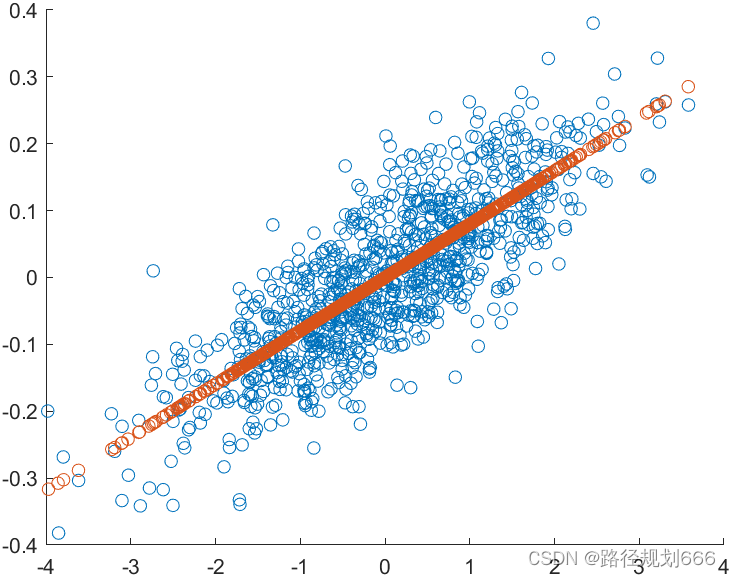 4. 其他几类运用PCA实现降维效果
4. 其他几类运用PCA实现降维效果

 4. 代码获取链接
4. 代码获取链接















 13万+
13万+











 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









