






粒子群优化(PSO)算法
一种启发式优化算法,灵感来源于鸟群或鱼群等群体智能行为的模拟。PSO算法最早由Kennedy和Eberhart于1995年提出,通常用于解决搜索空间连续、高维的优化问题。
PSO算法模拟了鸟群中鸟类搜索食物的行为。在PSO算法中,候选解称为粒子,每个粒子通过搜索空间中移动来寻找最优解。每个粒子都有自己的位置和速度,同时记录了自己历史搜索到的最佳位置。粒子之间通过分享信息来引导搜索,即根据自身经验和群体经验调整自己的位置和速度。具体来说,PSO算法包括以下主要步骤:
1. 初始化粒子群:
随机生成一定数量的粒子,并初始化它们的位置和速度。
2. 计算适应度:
根据问题定义的适应度函数计算每个粒子的适应度,即目标函数值。
3. 更新粒子的速度和位置:
根据自身历史最优位置和群体历史最优位置,调整粒子的速度和位置。
4. 更新历史最优位置:
更新每个粒子的历史最优位置,以便在后续迭代中引导搜索。
5. 终止条件判断:
判断是否满足停止条件,如达到最大迭代次数或适应度达到一定阈值。
6. 返回最优解:
返回历史最优位置对应的解作为优化结果。
PSO算法的优点包括易于实现、收敛速度快、适用于连续优化问题等。然而,PSO算法也存在局部最优解问题和对参数的敏感性等缺点。因此,在实际应用中,需要根据具体问题进行参数调整和适应度函数设计来提高算法性能。PSO算法在优化问题、神经网络训练、数据挖掘等领域有着广泛的应用。
PSO代码
%%
clc
clear
close all
tic
%% 地图
G=[0 0 0 0 0 0 1 1 1 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 1 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 1 1 0 0 0 0 0 1 1 1 1 0 0;
0 0 0 0 0 0 0 0 0 0 0 1 0 0 1 1 1 1 0 0;
0 1 1 1 0 0 0 1 1 0 0 0 0 1 0 0 0 0 0 0;
0 1 1 1 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0;
0 1 1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0 0;
1 0 0 0 0 0 0 1 1 1 1 0 0 0 1 0 0 0 0 0;
1 1 1 0 0 0 0 1 1 1 1 0 0 0 1 0 0 0 0 0;
1 1 1 0 0 0 0 1 1 1 1 0 0 0 1 0 0 0 0 0;
1 1 1 0 0 0 0 1 1 1 1 0 0 0 0 0 1 1 1 0;
1 0 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0;
1 1 0 0 0 0 0 0 0 0 0 0 0 0 0 1 1 1 1 0;
1 1 0 0 0 0 1 1 0 0 0 1 0 0 0 0 0 0 0 0;
0 0 0 0 0 0 1 1 0 1 1 1 0 0 0 0 0 1 1 0;
0 0 0 1 1 0 0 0 0 0 0 0 0 0 0 0 0 1 1 0;
0 0 0 1 1 0 0 0 0 0 1 1 0 0 1 0 0 0 0 0;
0 0 0 0 0 0 0 0 0 0 1 1 0 0 0 0 0 0 0 0;];
num = size(G,1);
for i=1:num/2
for j=1:num
m=G(i,j);
n=G(num+1-i,j);
G(i,j)=n;
G(num+1-i,j)=m;
end
end
%%
S = [1 1];
E = [num num];
G0 = G;
G = G0(S(1):E(1),S(2):E(2));
[Xmax,dimensions] = size(G); X_min = 1;
dimensions = dimensions - 2;
%% 参数设置
max_gen = 100; % 最大迭代次数
num_polution = 50; % 种群数量
fobj=@(x)fitness(x,G);
[Best_score,Best_pos,PSO_curve]=PSO(num_polution,max_gen,X_min,Xmax,dimensions,fobj,G);
%结果分析
Best_pos = round(Best_pos);
disp(['PSO算法寻优得到的最短路径是:',num2str(Best_score)])
route = [S(1) Best_pos E(1)];
path_PSO=generateContinuousRoute(route,G);
path_PSO=GenerateSmoothPath(path_PSO,G);
path_PSO=GenerateSmoothPath(path_PSO,G);
%[Best_score,Best_pos,DE_curve]=DE(num_polution,max_gen,X_min,Xmax,dimensions,fobj,G);
%% 画寻优曲线
figure(1)
plot(PSO_curve,'b-*')
legend('PSO')
title('复杂路径下算法的收敛曲线')
set(gcf,'color','w')
%% 画路径
figure(2)
for i=1:num/2
for j=1:num
m=G(i,j);
n=G(num+1-i,j);
G(i,j)=n;
G(num+1-i,j)=m;
end
end
n=num;
for i=1:num
for j=1:num
if G(i,j)==1
x1=j-1;y1=n-i;
x2=j;y2=n-i;
x3=j;y3=n-i+1;
x4=j-1;y4=n-i+1;
p=fill([x1,x2,x3,x4],[y1,y2,y3,y4],[0.8,0.6,0.9]);
p.LineStyle='none';
hold on
else
x1=j-1;y1=n-i;
x2=j;y2=n-i;
x3=j;y3=n-i+1;
x4=j-1;y4=n-i+1;
p=fill([x1,x2,x3,x4],[y1,y2,y3,y4],[1,1,1]);
p.LineStyle='none';
hold on
end
end
end
hold on
hPSO = drawPath(path_PSO, 'b');
legend([ hPSO], {'PSO'});
set(gcf,'color','w')代码解释
这段代码是一个路径规划的程序,使用了粒子群优化(PSO)算法来寻找地图中两个特定点之间的最短路径。首先定义了一个地图矩阵G,其中包含了障碍物和路径的信息。然后根据定义的起点S和终点E,对地图进行切割,限定搜索范围。接着设置了算法参数,如最大迭代次数和种群数量,并调用PSO算法进行路径规划优化。
在代码中进行了PSO算法的迭代优化,并输出了最优路径的长度。最后画出了算法收敛曲线和地图上的最优路径。路径在地图上以蓝色线条表示,以及在地图上将地图的值1和0用不同颜色的矩形块表示出来。
整体来说,这段代码通过PSO算法寻找地图中两点之间的最短路径,并可视化展示在地图上。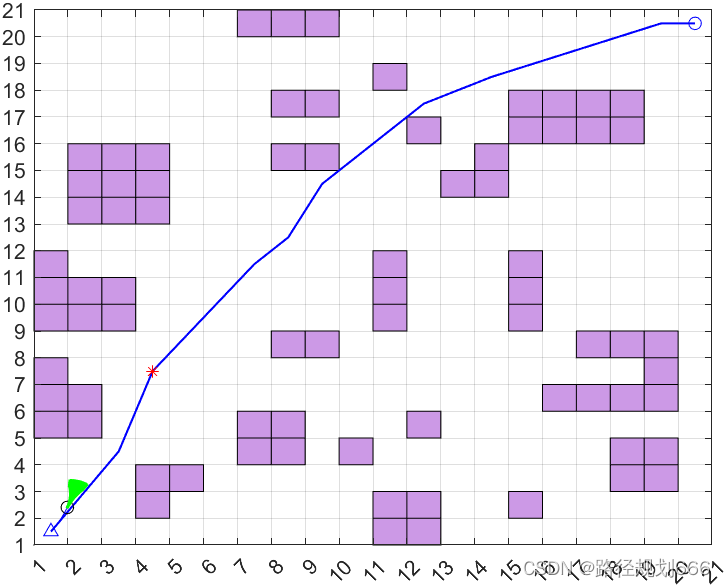
融合DWA
动态窗口法(Dynamic Window Approach,DWA)算法是一种用于移动机器人路径规划的算法,旨在通过考虑机器人动力学约束和环境障碍物来生成安全而高效的路径。DWA算法通常用于移动机器人导航和避障任务中,特别适用于运动速度较快或需要实时响应的情况。
DWA算法的核心思想是通过从当前机器人状态开始,在速度和角速度空间中搜索一个“动态窗口”,在该窗口内选择最优的速度和角速度组合,以使机器人在下一个时间步移动到最佳位置。具体来说,DWA算法包括以下主要步骤:
1. 获取当前状态:获取机器人当前位置、速度和角度等状态信息。
2. 确定速度窗口:根据机器人的动力学约束,限定速度和角速度的范围,形成一个速度窗口。
3. 评估轨迹:在速度窗口内搜索可能的速度和角速度组合,计算每个组合对应的轨迹,并根据一定的评估方法(如安全距离、目标方向等)对轨迹进行评价。
4. 选择最优轨迹:从评估后的轨迹中选择一个最优轨迹,即最符合评价标准的轨迹,作为机器人下一个时间步的移动路径。
5. 更新机器人状态:根据选择的最优轨迹,更新机器人的位置、速度和角度等状态信息。
6. 重复上述步骤:在每个时间步重复执行上述步骤,以实现实时响应和动态路径规划。
DWA算法结合了速度规划和避障方法,可以在复杂环境中生成可行的、安全的路径规划。它具有实时性强、适应性好、易于实现等优点,适用于移动机器人导航、避障、路径跟踪等场景。然而,DWA算法也存在路径局部优化、动态环境处理等挑战,需要根据具体应用场景进行参数调整和优化。
简单DWA算法代码
% 定义机器人动力学参数
max_linear_velocity = 1; % 最大线速度
max_angular_velocity = 1; % 最大角速度
max_acceleration = 0.1; % 最大加速度
max_angular_acceleration = 0.1; % 最大角加速度
% 定义目标位置
goal_position = [10, 10];
% 定义机器人初始位置和状态
robot_position = [0, 0];
robot_velocity = [0, 0];
robot_orientation = 0;
% 定义评价函数
function cost = evaluate_trajectory(trajectory, goal_position)
% 根据轨迹和目标位置计算成本,可以根据具体情况定义
cost = norm(trajectory(end, :) - goal_position);
end
% 主循环
while true
% 生成速度窗口
linear_velocities = linspace(0, max_linear_velocity, 10);
angular_velocities = linspace(-max_angular_velocity, max_angular_velocity, 10);
% 遍历速度窗口
best_trajectory = [];
best_cost = inf;
for linear_vel = linear_velocities
for angular_vel = angular_velocities
% 模拟机器人运动轨迹
sim_trajectory = simulate_trajectory(robot_position, robot_velocity, robot_orientation, linear_vel, angular_vel);
% 评估轨迹
cost = evaluate_trajectory(sim_trajectory, goal_position);
% 更新最优轨迹
if cost < best_cost
best_trajectory = sim_trajectory;
best_cost = cost;
end
end
end
% 更新机器人状态
robot_position = best_trajectory(end, :);
robot_velocity = (best_trajectory(end, :) - best_trajectory(end-1, :)) / dt; % 假设dt为时间步长
robot_orientation = atan2(robot_velocity(2), robot_velocity(1));
% 判断是否到达目标
if norm(robot_position - goal_position) < 0.1
disp('达到目标位置!');
break;
end
end
% 模拟机器人运动轨迹函数
function trajectory = simulate_trajectory(position, velocity, orientation, linear_vel, angular_vel)
% 模拟机器人从当前位置开始以指定速度和角速度运动的轨迹
% 这里只是一个简单的示例,实际情况下可能需要考虑更多的因素
dt = 0.1; % 时间步长
trajectory = [];
for t = 1:10
position = position + velocity * dt;
orientation = orientation + angular_vel * dt;
trajectory = [trajectory; position];
end
end使用的DWA代码
function a = DWA(Obs_Closed,Obs_d_j,Area_MAX,Goal,Line_path,path_node,Start0,s_du,Kinematic,evalParam)
figure
num_obc=size(Obs_Closed,1); % 计算障碍物的数量
num_path=size(path_node,1);
xTarget=path_node(num_path,1);
yTarget=path_node(num_path,2);
%
% num_odL=size(Obst_d_d_line,1);
% Obst_d_line=[];
xm=path_node(1,1);
ym=path_node(1,2);
% 初始位置坐标
%angle_S=pi;
angle_node=sn_angle(path_node(1,1),path_node(1,2),path_node(2,1),path_node(2,2));
du_flog=1;
du_max=angle_node+pi/18;
du_min=angle_node-pi/18;
%zhuangjiao_node=angle_S-angle_node;
x=[xm ym s_du 0 0]';% 机器人的初期状态 x=[x(m),y(m),yaw(Rad),v(m/s),w(rad/s)]
xt_yu=[xm ym];
%G_goal=path_node(num_path,:);% 目标点位置 [x(m),y(m)]
obstacle=Obs_Closed;
Obs_dong=Obs_d_j ;
obstacleR=0.8;% 静态障碍物 冲突判定用的障碍物半径
R_dong_obs=0.8; % 动态障碍物 冲突判定用的障碍物半径
global dt; % 全局变量
dt=0.1;% 时间[s]
% 机器人运动学模型
% [ 最高速度[m/s], 最高旋转速度[rad/s], 加速度[m/ss], 旋转加速度[rad/ss], 速度分辨率[m/s], 转速分辨率[rad/s] ]
%
% Kinematic=[2.0, toRadian(40.0), 0.5, toRadian(120.0), 0.01, toRadian(1)];
% %Kinematic=[1, toRadian(20.0), 0.3, toRadian(60), 0.01, toRadian(1)];
% % 评价函数参数 [heading,dist,velocity,predictDT][方位角偏差系数, 障碍物距离系数, 当前速度大小系数, 动态障碍物距离系数,预测是时间 ]
% evalParam=[0.2, 0.1, 0.3, 0.4, 3.0];%0.3 0.1 0.1 [0.05, 0.2, 0.1, 3.0] [0.2, 0.5, 0.3, 3.0]
MAX_X=Area_MAX(1,1);
MAX_Y=Area_MAX(1,2);
% 模拟区域范围 [xmin xmax ymin ymax]
% 模拟实验的结果
result.x=[];
goal=path_node(2,:);
tic;
% movcount=0;
% Main loop
for i=1:5000
dang_node=[x(1,1) x(2,1)];
dis_ng=distance(dang_node(1,1),dang_node(1,2),xTarget,yTarget);
dis_x_du=distance(xt_yu(1,1),xt_yu(1,2),goal(1,1),goal(1,2));
if num_path==2||dis_ng<0.5
Ggoal=[xTarget yTarget];
else
Ggoal=Target_node(dang_node,path_node,Obs_dong,xTarget,yTarget,goal,dis_x_du);
end
goal=Ggoal;
% obstacle=OBSTACLE(Obs_Closed,Obs_dong,path_node);
if (s_du>du_max||s_du<du_min)&&du_flog==1
[u,traj]=DynamicWindowApproach_du(x,Kinematic,goal,evalParam,obstacle,obstacleR,Obs_dong,R_dong_obs);
x=f(x,u);% 机器人移动到下一个时刻
result.x=[result.x; x'];
if angle_node>=(17/18)*pi
if x(3)>=du_min %x(3)==angle_node
du_flog=0;
end
elseif angle_node<=(-17/18)*pi
if x(3)<=du_max %x(3)==angle_node
du_flog=0;
end
else
if x(3)<=du_max&&x(3)>=du_min %x(3)==angle_node
du_flog=0;
end
end
else
[u,traj,xt_yu]=DynamicWindowApproach(x,Kinematic,goal,evalParam,obstacle,obstacleR,Obs_dong,R_dong_obs);
% u = [ 速度 转速 ] traj=[ 3s内的所有状态轨迹 ]
x=f(x,u);% 机器人移动到下一个时刻
result.x=[result.x; x'];
end
% 模拟结果的保存
% 是否到达目的地
%if norm(x(1:2)-G_goal')<0.2
if dis_ng<0.2
disp('Arrive Goal!!');break;
end
%====Animation====
hold off;
%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% 画图
for i_obs=1:1:num_obc
x_obs=Obs_Closed(i_obs,1);
y_obs=Obs_Closed(i_obs,2);
fill([x_obs,x_obs+1,x_obs+1,x_obs],[y_obs,y_obs,y_obs+1,y_obs+1],'k');hold on;
end
plot( Line_path(:,1)+.5, Line_path(:,2)+.5,'b:','linewidth',1);
plot(Start0(1,1)+.5,Start0(1,2)+.5,'b^');
plot(Goal(1,1)+.5,Goal(1,2)+.5,'bo');
% dong_num=size(Obs_d_j,1);
% for i_d=1:1:dong_num
% x_do=Obs_d_j(i_d,1);
% y_do=Obs_d_j(i_d,2);
% fill([x_do,x_do+1,x_do+1,x_do],[y_do,y_do,y_do+1,y_do+1],[0.8 0.8 0.8]);
% end
% fill([7.2,7.8,7.8,7.2],[10.2,10.2,10.8,10.8],[0.8 0.8 0.8]);hold on;
% %%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%%
% fill([7.2,7.8,7.8,7.2],[7.2,7.2,7.8,7.8],[0.8 0.8 0.8]);hold on;
ArrowLength=0.5;%
% 机器人
quiver(x(1)+0.5, x(2)+0.5, ArrowLength*cos(x(3)), ArrowLength*sin(x(3)),'ok');hold on;
% x=[x(m),y(m),yaw(Rad),v(m/s),w(rad/s)]
plot(result.x(:,1)+0.5, result.x(:,2)+0.5,'-b');hold on;
plot(goal(1)+0.5,goal(2)+0.5,'*r');hold on;代码解析
这段MATLAB代码是一个用于路径规划的函数`DWA`,其中使用了动态窗口方法(Dynamic Window Approach)来规划机器人的运动轨迹。该函数包括对机器人、目标点、障碍物、运动学模型、评价函数等参数的定义,以及循环迭代来实现机器人导航路径的规划。
在函数中,主要包括设置初始位置、目标点位置、障碍物信息、运动学模型参数、评价函数参数等,并在循环中不断调用动态窗口方法来生成机器人的下一步运动控制输入,同时更新机器人状态并验证是否到达目标点。在循环过程中还包括对机器人轨迹和动画的绘制。
如果需要更详细的解释或帮助,欢迎进一步提出具体问题或需求。
代码结果
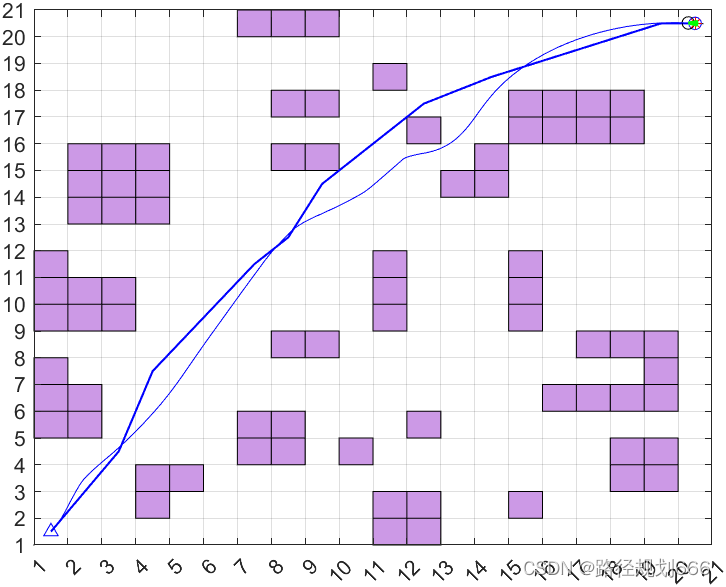
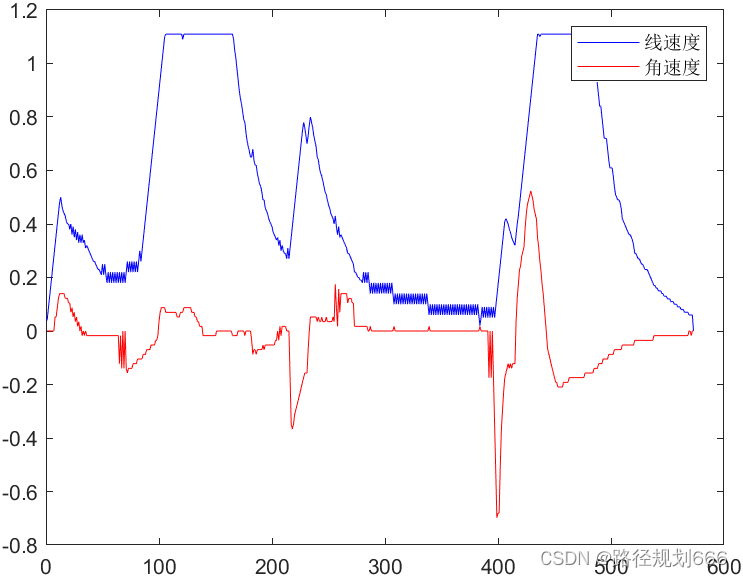
结论
通过组合使用PSO算法(Particle Swarm Optimization)和DWA算法(Dynamic Window Approach)可以实现全局路径规划和局部路径规划的有效结合,以及在机器人导航过程中取得良好的路径规划效果。
PSO算法通过模拟鸟群的行为,利用粒子群的搜索机制来全局优化机器人的导航路径,找到最优的路径方案以达到目标点。它能够有效地搜索解空间,并且具有较强的全局寻优能力,能够克服局部最优的问题。
DWA算法则在机器人运动过程中实时地根据机器人周围环境的动态窗口来进行局部路径规划,考虑到机器人的运动学特性和动态障碍物的影响,保证机器人在局部环境中快速、安全地规划出可行的轨迹。
因此,组合使用PSO算法和DWA算法,PSO算法负责全局路径规划,DWA算法负责局部路径规划,可以充分发挥两者的优势,实现高效的机器人导航路径规划。这种组合方法能够对复杂的导航环境做出合理的路径规划,并且在动态环境下能够及时调整机器人的轨迹,使其能够安全、快速地到达目标点。

















 753
753

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









