







梯度下降法算法文档介绍
一、引言
梯度下降法(Gradient Descent, 简称GD)是一种一阶最优化算法,也称为最陡下降法。其核心思想是通过迭代搜索找到函数的局部极小值点。在机器学习中,梯度下降法常用于求解损失函数的最小值,从而确定模型的参数。
二、基本原理
梯度下降法的基本思想是在当前点向函数梯度的反方向(即下降最快的方向)移动一定步长,以达到局部最小值。对于多变量函数,梯度是一个向量,指向函数值增长最快的方向。因此,通过向梯度的反方向移动,可以最快地减小函数值。
三、数学描述
对于函数J(θ),其梯度∇J(θ)是一个向量,表示函数在θ点处沿各方向的变化率。梯度下降法的迭代公式为:
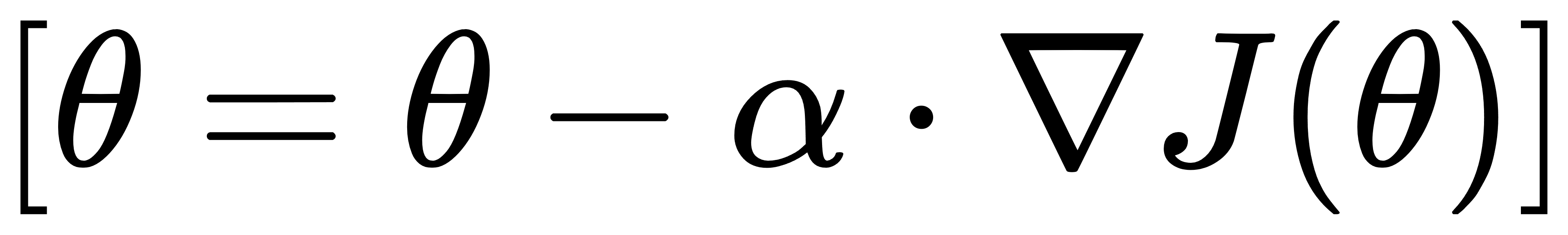
其中,α是学习率(或步长),用于控制每次迭代的步长大小。
四、算法步骤
- 初始化参数:随机初始化模型参数θ和学习率α。
- 计算梯度:计算当前参数下的损失函数梯度∇J(θ)。
- 更新参数:根据迭代公式更新参数θ。
- 判断是否终止:检查是否满足停止条件(如梯度小于某阈值、达到最大迭代次数等)。如果不满足,则返回第2步继续迭代。
五、算法类型
- 批量梯度下降法(Batch Gradient Descent, BGD)
-
- 每次迭代使用全部训练数据计算梯度,然后更新参数。
- 优点:可以得到全局最优解(在凸函数情况下),易于并行计算。
- 缺点:计算量大,内存消耗高,收敛速度慢。
- 随机梯度下降法(Stochastic Gradient Descent, SGD)
-
- 每次迭代随机选取一个样本计算梯度,然后更新参数。
- 优点:计算速度快,内存消耗低,易于跳出局部最优解。
- 缺点:由于随机性,可能导致收敛过程震荡,难以达到全局最优解。
- 小批量梯度下降法(Mini-Batch Gradient Descent, MBGD)
-
- 每次迭代选取一小部分(batch)训练数据计算梯度,然后更新参数。
- 优点:结合了BGD和SGD的优点,既降低了计算量,又保持了较好的收敛性。
- 缺点:batch size的选择对算法性能有较大影响。
六、优缺点分析
优点:
- 能够选择合理的参数更新方向,使损失函数快速下降。
- 实现简单,计算量相对较小(相对于BGD)。
- 易于与其他优化算法结合使用,如动量法、学习率衰减等。
缺点:
- 下降速度较慢,属于一阶收敛算法。
- 依赖梯度信息,如果目标函数不可微,则算法失效。
- 容易陷入局部极小值点,特别是在非凸函数情况下。
- 收敛过程可能不稳定,存在震荡现象(特别是SGD)。
七、应用实例
在机器学习中,梯度下降法广泛应用于各种模型的参数优化中,如线性回归、逻辑回归、神经网络等。通过梯度下降法,可以求解损失函数的最小值,从而得到最优的模型参数。
八、结论
梯度下降法是一种简单而有效的优化算法,在机器学习中具有广泛的应用。然而,其也存在一些局限性,如收敛速度慢、容易陷入局部极小值点等。因此,在实际应用中,需要根据具体问题选择合适的优化算法和参数设置。















 35万+
35万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









