







 这篇博客详细介绍了如何在Windows环境下利用MMDetection框架训练自定义的VOC数据集。首先,介绍了安装mmdetection的步骤,接着讲解了VOC数据集的目录结构和内容准备。然后,对mmdetection的相关文件进行修改,包括class_names.py、voc.py和配置文件,以适应新的类别和数据集。在训练前,由于遇到CUDA内存不足的问题,博主尝试调整了内存分配但未成功。最后,提供了训练命令。尽管遇到内存问题,该文仍为使用MMDetection训练目标检测模型提供了一步步的指导。
这篇博客详细介绍了如何在Windows环境下利用MMDetection框架训练自定义的VOC数据集。首先,介绍了安装mmdetection的步骤,接着讲解了VOC数据集的目录结构和内容准备。然后,对mmdetection的相关文件进行修改,包括class_names.py、voc.py和配置文件,以适应新的类别和数据集。在训练前,由于遇到CUDA内存不足的问题,博主尝试调整了内存分配但未成功。最后,提供了训练命令。尽管遇到内存问题,该文仍为使用MMDetection训练目标检测模型提供了一步步的指导。
参考链接
安装mmdetection
查看另一篇博客:安装mmdetection(Windows环境下)
VOC数据集准备
mmdetection
├── mmdet
├── tools
├── configs
├── data #手动创建data、VOCdevkit、VOC2007、Annotations、JPEGImages、ImageSets、Main这些文件夹
│ ├── VOCdevkit(数据集名称)
│ │ ├── VOC2007
│ │ │ ├── Annotations #把valid.txt、train.txt对应的xml文件放在这
│ │ │ ├── JPEGImages #把valid.txt、train.txt对应的图片放在这
│ │ │ ├── ImageSets
│ │ │ │ ├── Main
│ │ │ │ │ ├── valid.txt
│ │ │ │ │ ├── train.txt
可查看我的另一篇博客:划分数据集为VOC数据格式
修改相关文件
(1) 修改class_names.py文件
修改路径:mmdetection/mmdet/core/evaluation/class_names.py
修改内容:将voc_classes的返回值改为要训练数据集的类别名称。

(2) 修改voc.py文件
修改路径:mmdetection/mmdet/datasets/voc.py
修改内容:将VOCDataset中的CLASSES改为对应训练数据集的类别集合。

(3) 修改配置文件
配置文件路径:mmdetection/configs
我要使用的是faster_rcnn_hrnetv2p_w40_2x_coco.py,经过层层找上去,最终确定了更改faster_rcnn_r50_fpn_1x_coco.py中对应的model等文件的配置。

(3.1) 更改 models/faster_rcnn_r50_fpn.py 中的 num_classes

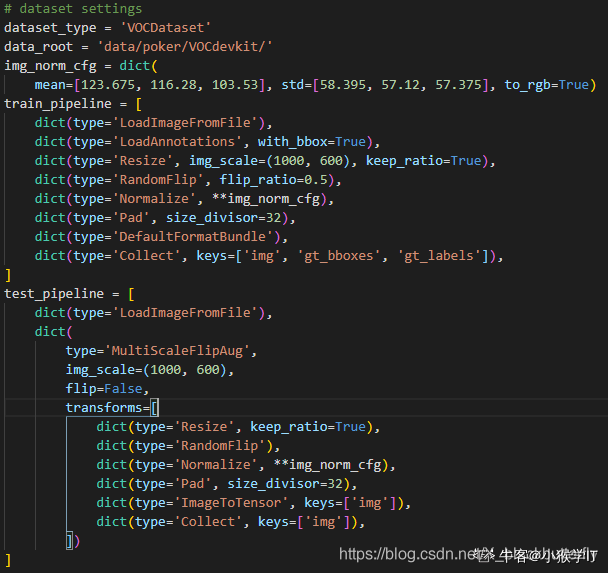
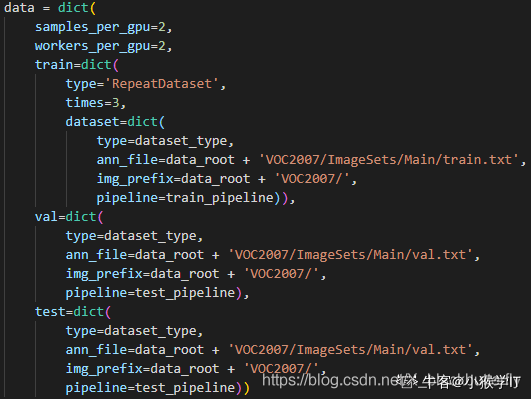
(3.2) 更改 datasets/coco_detection.py 中dataset_type、data_root、img_scale、ann_file、img_prefix变量。(我还改了:workers_per_gpu=0)
❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀❀
接下来的两步我就没跟着改了,只是粘图在这里
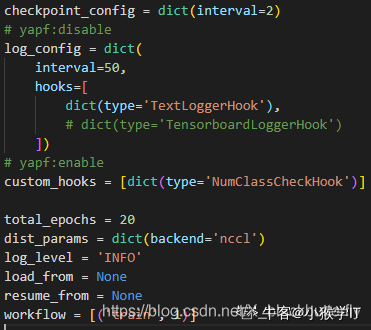
(3.3) schedules中新建schedule_xxx_voc.py设置对应优化器

(3.4) 新建xxx_voc_runtime.py文件设置整体超参
重新编译
修改完后,训练之前需要重新编译,不然会出现“AssertionError: The num_classes (20) in Shared2FCBBoxHead of MMDataParallel does not matches the length of CLASSES 80) in RepeatDataset"的报错。
编译命令如下:
python setup.py install
开始训练
python tools/train.py configs/hrnet/faster_rcnn_hrnetv2p_w40_2x_coco.py
还没有成功,呜呜呜,报显存错误了,尝试过改以下两个位置的大小,可惜失败了。
错误:RuntimeError: CUDA out of memory. Tried to allocate 20.00 MiB (GPU 0; 4.00 GiB total capacity; 2.45 GiB already allocated; 0 bytes free; 2.49 GiB reserved in total by PyTorch)
可能有用的链接:
- RuntimeError:CUDA out of memory.Tried to allocate 20.00MiB.
- 目标检测】RuntimeError:CUDA error:out of memory问题解决方案
- 【mmdetection】使用心得
- 【pytorch】mmdetection 做eval / test时弹出OOM(Out of Memory / CUDA out of memory)的解决过程记录




















 810
810

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











