







 本文详细解读了MMDetection框架的文件目录结构,重点介绍了config和models下的关键组件,包括模型配置文件、各种网络结构和组件的作用,以及目标检测的整体构建流程。
本文详细解读了MMDetection框架的文件目录结构,重点介绍了config和models下的关键组件,包括模型配置文件、各种网络结构和组件的作用,以及目标检测的整体构建流程。
文章目录
前言
本文主要分析mmdet文件目录结构中的mmdet文件,了解mmdetection整体构建流程、思想及其中各部分所完成的主要功能。 (更新中)
一、mmdet文件目录结构
MMDetection作为目标检测工具箱,提供了许多目标检测、实例分割、全景分割等算法及相关组件模块,其中mmdet文件即为其核心组成文件。
文件路径:mmdetection-main/mmdet
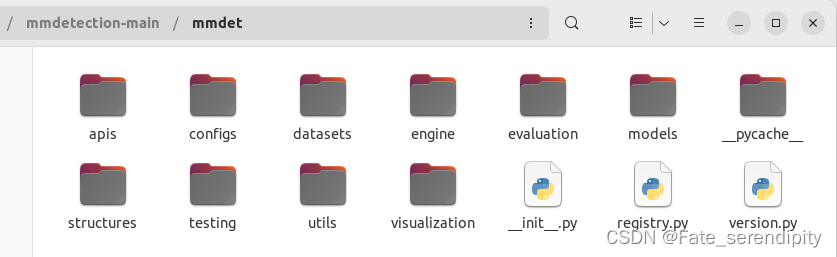
该文件主要由以下几个子文件构成:
| 文件名 | 描述 |
|---|---|
| apis | 提供模型推理的API |
| configs | 模型的配置文件 |
| datasets | 支持用于目标检测、实例分割和全景分割的各种数据集 |
| engine | 运行组件的一部分 |
| evaluation | 评估模型的指标 |
| models | 检测器的不同组件 |
| structures | 提供bbox、mask、DetDataSample等数据结构 |
| testing | 提供模型推理的API |
| visualization | 检测结果的可视化工具 |
下面详细介绍其中的重要文件(已更configs、models)。
1. configs
进入mmdetection-main/mmdet/configs,文件目录结构如下。
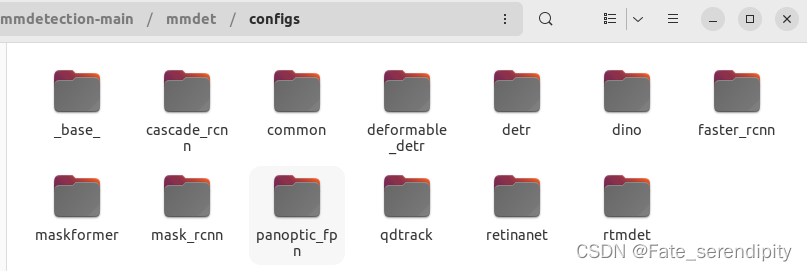 在此文件中,提供了方法的配置参数,每个文件是一个模型的配置文件(文件名为模型名称)。
在此文件中,提供了方法的配置参数,每个文件是一个模型的配置文件(文件名为模型名称)。
在mmdetection-main/mmdet/configs/_base_下,有4个基本组件类型,分别为:datasets(数据集)、model(模型)、schedules(训练策略)以及default_runtime(运行时的默认配置)。可以通过继承_base_下的组件来构建我们的方法。
在configs文件下的文件夹,以方法名来命名,对于里面的每个配置文件,遵循以下样式来命名。
{model}_[model setting]_{backbone}_{neck}_[norm setting]_[misc]_[gpu x batch_per_gpu]_{schedule}_{dataset}
其中:
{model}: 模型种类,例如 faster_rcnn, mask_rcnn 等。
[model setting]: 特定的模型,例如 htc 中的without_semantic, reppoints 中的 moment 等。
{backbone}: 主干网络种类例如 r50 (ResNet-50), x101 (ResNeXt-101) 等。
{neck}: Neck 模型的种类包括 fpn, pafpn, nasfpn, c4 等。
[norm_setting]: 默认使用 bn (Batch Normalization),其他指定可以有 gn (Group Normalization), syncbn (Synchronized Batch Normalization) 等。 gn-head/gn-neck 表示 GN 仅应用于网络的 Head 或 Neck, gn-all 表示 GN 用于整个模型, 例如主干网络、Neck 和 Head。
[misc]: 模型中各式各样的设置/插件,例如 dconv、 gcb、 attention、albu、 mstrain 等。
[gpu x batch_per_gpu]:GPU 数量和每个 GPU 的样本数,默认使用 8x2。
{schedule}: 训练方案,选项是 1x、 2x、 20e 等。1x 和 2x 分别代表 12 epoch 和 24 epoch,20e 在级联模型中使用,表示 20 epoch。对于 1x/2x,初始学习率在第 8/16 和第 11/22 epoch 衰减 10 倍;对于 20e ,初始学习率在第 16 和第 19 epoch 衰减 10 倍。
{dataset}:数据集,例如 coco、 cityscapes、 voc_0712、 wider_face 等。
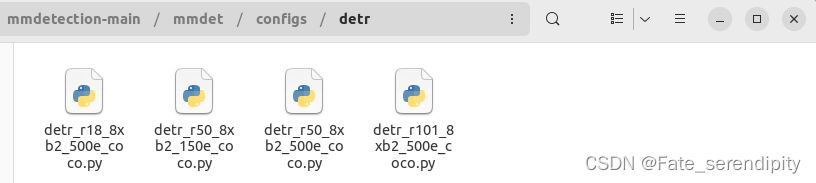
如detr,其中有四个配置文件,他们均为detr模型,采用了不同的主干网络以及训练方案。
2. models
进入mmdetection-main/mmdet/models,可以看到文件目录结构如下图。
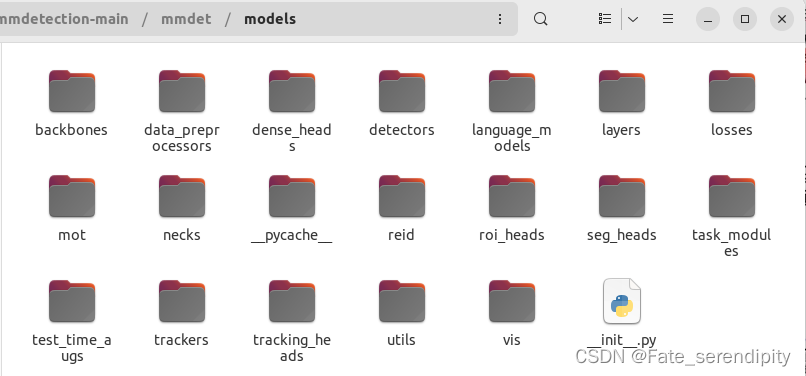
在目前代码中,目标检测算法训练遵循以下流程:
backbone -> neck -> head -> bbox assigner -> bbox sampler -> bbox encoder -> loss
(1)backbone主要用于特征提取,在models/backbones文件下集成了大部分骨架网络:
__all__ = [
'RegNet', 'ResNet', &# 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 3413
3413

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









